24 Thu thập dữ liệu web
24.1 Giới thiệu
Chương này giới thiệu cho bạn những kiến thức cơ bản về thu thập dữ liệu web (web scraping) với rvest. Thu thập dữ liệu web là một công cụ rất hữu ích để trích xuất dữ liệu từ các trang web. Một số trang web sẽ cung cấp API, một tập hợp các yêu cầu HTTP có cấu trúc trả về dữ liệu dưới dạng JSON, mà bạn xử lý bằng các kỹ thuật từ Chương 23. Khi có thể, bạn nên sử dụng API1, vì thông thường nó sẽ cung cấp cho bạn dữ liệu đáng tin cậy hơn. Tuy nhiên, thật không may, lập trình với web API nằm ngoài phạm vi của cuốn sách này. Thay vào đó, chúng tôi sẽ dạy về thu thập dữ liệu web (scraping), một kỹ thuật hoạt động bất kể trang web có cung cấp API hay không.
Trong chương này, trước tiên chúng tôi sẽ thảo luận về đạo đức và tính hợp pháp của việc thu thập dữ liệu web trước khi đi sâu vào những kiến thức cơ bản về HTML. Sau đó bạn sẽ học những kiến thức cơ bản về bộ chọn CSS (CSS selectors) để định vị các phần tử cụ thể trên trang, và cách sử dụng các function rvest để lấy dữ liệu từ văn bản và thuộc tính ra khỏi HTML và đưa vào R. Tiếp theo, chúng tôi sẽ thảo luận một số kỹ thuật để tìm ra bộ chọn CSS nào bạn cần cho trang bạn đang thu thập, trước khi kết thúc với một vài nghiên cứu tình huống, và một cuộc thảo luận ngắn về các trang web động (dynamic websites).
24.1.1 Điều kiện tiên quyết
Trong chương này, chúng tôi sẽ tập trung vào các công cụ được cung cấp bởi rvest. rvest là một thành viên của tidyverse, nhưng không phải thành viên cốt lõi nên bạn sẽ cần nạp nó một cách rõ ràng. Chúng tôi cũng sẽ nạp toàn bộ tidyverse vì chúng tôi thấy nó nói chung hữu ích khi làm việc với dữ liệu mà chúng ta đã thu thập.
24.2 Đạo đức và tính hợp pháp của thu thập dữ liệu web
Trước khi bắt đầu thảo luận về mã lệnh bạn cần để thực hiện thu thập dữ liệu web, chúng ta cần nói về việc liệu nó có hợp pháp và đạo đức hay không. Nhìn chung, tình hình khá phức tạp đối với cả hai khía cạnh này.
Tính hợp pháp phụ thuộc nhiều vào nơi bạn sống. Tuy nhiên, như một nguyên tắc chung, nếu dữ liệu là công khai, phi cá nhân, và mang tính thực tế, thì bạn có khả năng ổn2. Ba yếu tố này quan trọng vì chúng liên quan đến điều khoản và điều kiện của trang web, thông tin nhận dạng cá nhân, và bản quyền, như chúng tôi sẽ thảo luận bên dưới.
Nếu dữ liệu không công khai, không phi cá nhân, hoặc không mang tính thực tế, hoặc bạn đang thu thập dữ liệu cụ thể để kiếm tiền từ nó, bạn sẽ cần trao đổi với một luật sư. Trong mọi trường hợp, bạn nên tôn trọng tài nguyên của máy chủ lưu trữ các trang bạn đang thu thập. Quan trọng nhất, điều này có nghĩa là nếu bạn đang thu thập nhiều trang, bạn nên đảm bảo chờ một chút giữa mỗi yêu cầu. Một cách dễ dàng để làm điều này là sử dụng package polite của Dmytro Perepolkin. Nó sẽ tự động tạm dừng giữa các yêu cầu và lưu bộ nhớ đệm kết quả để bạn không bao giờ yêu cầu cùng một trang hai lần.
24.2.1 Điều khoản dịch vụ
Nếu bạn nhìn kỹ, bạn sẽ thấy nhiều trang web bao gồm một liên kết “điều khoản và điều kiện” hoặc “điều khoản dịch vụ” ở đâu đó trên trang, và nếu bạn đọc kỹ trang đó, bạn sẽ thường phát hiện rằng trang web đó cấm cụ thể việc thu thập dữ liệu web. Các trang này có xu hướng là một sự chiếm đoạt pháp lý nơi các công ty đưa ra những tuyên bố rất rộng. Thật lịch sự khi tôn trọng các điều khoản dịch vụ này khi có thể, nhưng hãy tiếp nhận mọi tuyên bố một cách thận trọng.
Các tòa án Hoa Kỳ nhìn chung đã phán quyết rằng chỉ đơn giản đặt điều khoản dịch vụ ở cuối trang web là không đủ để bạn bị ràng buộc bởi chúng, ví dụ, HiQ Labs v. LinkedIn. Nói chung, để bị ràng buộc bởi điều khoản dịch vụ, bạn phải thực hiện một hành động rõ ràng nào đó như tạo tài khoản hoặc đánh dấu vào ô. Đây là lý do tại sao việc dữ liệu có công khai hay không lại quan trọng; nếu bạn không cần tài khoản để truy cập chúng, thì khó có khả năng bạn bị ràng buộc bởi điều khoản dịch vụ. Tuy nhiên, lưu ý rằng tình hình khá khác ở châu Âu, nơi các tòa án đã phán quyết rằng điều khoản dịch vụ có hiệu lực thi hành ngay cả khi bạn không đồng ý một cách rõ ràng.
24.2.2 Thông tin nhận dạng cá nhân
Ngay cả khi dữ liệu là công khai, bạn nên cực kỳ cẩn thận khi thu thập thông tin nhận dạng cá nhân (personally identifiable information) như tên, địa chỉ email, số điện thoại, ngày sinh, v.v. Châu Âu có những luật đặc biệt nghiêm ngặt về việc thu thập hoặc lưu trữ dữ liệu như vậy (GDPR), và bất kể bạn sống ở đâu, bạn đều có khả năng bước vào một vùng xám về đạo đức. Ví dụ, vào năm 2016, một nhóm nhà nghiên cứu đã thu thập thông tin hồ sơ công khai (ví dụ: tên người dùng, tuổi, giới tính, vị trí, v.v.) của 70.000 người trên trang hẹn hò OkCupid và họ đã công bố dữ liệu này mà không có bất kỳ nỗ lực ẩn danh hóa nào. Mặc dù các nhà nghiên cứu cảm thấy không có gì sai với điều này vì dữ liệu đã là công khai, công trình này đã bị lên án rộng rãi do lo ngại về đạo đức xung quanh khả năng nhận dạng người dùng có thông tin được công bố trong tập dữ liệu. Nếu công việc của bạn liên quan đến việc thu thập thông tin nhận dạng cá nhân, chúng tôi đặc biệt khuyến nghị đọc về nghiên cứu OkCupid3 cũng như các nghiên cứu tương tự có đạo đức nghiên cứu đáng ngờ liên quan đến việc thu thập và phát hành thông tin nhận dạng cá nhân.
24.2.3 Bản quyền
Cuối cùng, bạn cũng cần lo lắng về luật bản quyền. Luật bản quyền rất phức tạp, nhưng đáng để xem qua luật Hoa Kỳ mô tả chính xác những gì được bảo hộ: “[…] các tác phẩm gốc của tác giả được cố định trong bất kỳ phương tiện biểu đạt hữu hình nào, […]”. Sau đó nó tiếp tục mô tả các danh mục cụ thể mà nó áp dụng như tác phẩm văn học, tác phẩm âm nhạc, phim điện ảnh và nhiều hơn nữa. Đáng chú ý là dữ liệu không nằm trong phạm vi bảo hộ bản quyền. Điều này có nghĩa là miễn là bạn giới hạn việc thu thập ở các sự kiện thực tế, bảo hộ bản quyền không áp dụng. (Nhưng lưu ý rằng châu Âu có một quyền “sui generis” riêng biệt bảo hộ database.)
Như một ví dụ ngắn, ở Hoa Kỳ, list nguyên liệu và hướng dẫn không được bảo hộ bản quyền, vì vậy bản quyền không thể được sử dụng để bảo hộ một công thức nấu ăn. Nhưng nếu list công thức đó đi kèm với nội dung văn học mới đáng kể, thì nội dung đó được bảo hộ bản quyền. Đây là lý do tại sao khi bạn tìm kiếm một công thức nấu ăn trên internet luôn có rất nhiều nội dung trước đó.
Nếu bạn cần thu thập nội dung gốc (như văn bản hoặc hình ảnh), bạn vẫn có thể được bảo hộ theo học thuyết sử dụng hợp lý (fair use). Sử dụng hợp lý không phải là một quy tắc cứng nhắc, mà cân nhắc một số yếu tố. Nó có nhiều khả năng áp dụng hơn nếu bạn thu thập dữ liệu cho mục đích nghiên cứu hoặc phi thương mại và nếu bạn giới hạn những gì bạn thu thập chỉ ở mức cần thiết.
24.3 Kiến thức cơ bản về HTML
Để thu thập dữ liệu từ trang web, trước tiên bạn cần hiểu một chút về HTML, ngôn ngữ mô tả các trang web. HTML là viết tắt của HyperText Markup Language và trông giống như thế này:
<html>
<head>
<title>Page title</title>
</head>
<body>
<h1 id='first'>A heading</h1>
<p>Some text & <b>some bold text.</b></p>
<img src='myimg.png' width='100' height='100'>
</body>HTML có một cấu trúc phân cấp được tạo bởi các phần tử (elements) bao gồm một thẻ mở (ví dụ: <tag>), các thuộc tính (attributes) tùy chọn (id='first'), một thẻ đóng4 (như </tag>), và nội dung (contents) (mọi thứ nằm giữa thẻ mở và thẻ đóng).
Vì < và > được sử dụng cho thẻ mở và thẻ đóng, bạn không thể viết chúng trực tiếp. Thay vào đó bạn phải sử dụng các ký tự thoát (escapes) HTML > (lớn hơn) và < (nhỏ hơn). Và vì các ký tự thoát đó sử dụng &, nếu bạn muốn một dấu và (&) theo nghĩa đen, bạn phải thoát nó thành &. Có rất nhiều ký tự thoát HTML khác nhau nhưng bạn không cần phải lo lắng quá nhiều về chúng vì rvest tự động xử lý chúng cho bạn.
Thu thập dữ liệu web khả thi vì hầu hết các trang chứa dữ liệu mà bạn muốn thu thập thường có cấu trúc nhất quán.
24.3.1 Phần tử
Có hơn 100 phần tử HTML. Một số phần tử quan trọng nhất là:
Mỗi trang HTML phải nằm trong một phần tử
<html>, và nó phải có hai phần tử con:<head>, chứa siêu dữ liệu tài liệu như tiêu đề trang, và<body>, chứa nội dung bạn nhìn thấy trong trình duyệt.Các thẻ khối (block tags) như
<h1>(tiêu đề 1),<section>(phần),<p>(đoạn văn), và<ol>(list có thứ tự) tạo thành cấu trúc tổng thể của trang.Các thẻ nội tuyến (inline tags) như
<b>(in đậm),<i>(in nghiêng), và<a>(liên kết) định dạng văn bản bên trong các thẻ khối.
Nếu bạn gặp một thẻ mà bạn chưa từng thấy trước đây, bạn có thể tìm hiểu nó làm gì bằng cách tìm kiếm trên Google. Một nơi tốt khác để bắt đầu là MDN Web Docs mô tả gần như mọi khía cạnh của lập trình web.
Hầu hết các phần tử có thể có nội dung nằm giữa thẻ mở và thẻ đóng của chúng. Nội dung này có thể là văn bản hoặc nhiều phần tử hơn. Ví dụ, HTML sau chứa một đoạn văn bản, với một từ được in đậm.
<p>
Hi! My <b>name</b> is Hadley.
</p>Phần tử con (children) là các phần tử mà nó chứa, vì vậy phần tử <p> ở trên có một phần tử con, phần tử <b>. Phần tử <b> không có phần tử con, nhưng nó có nội dung (văn bản “name”).
24.3.2 Thuộc tính
Các thẻ có thể có thuộc tính (attributes) được đặt tên trông giống như name1='value1' name2='value2'. Hai trong số các thuộc tính quan trọng nhất là id và class, được sử dụng kết hợp với CSS (Cascading Style Sheets) để kiểm soát giao diện trực quan của trang. Chúng thường hữu ích khi thu thập dữ liệu từ một trang. Thuộc tính cũng được sử dụng để ghi lại đích đến của liên kết (thuộc tính href của phần tử <a>) và nguồn của hình ảnh (thuộc tính src của phần tử <img>).
24.4 Trích xuất dữ liệu
Để bắt đầu thu thập dữ liệu, bạn sẽ cần URL của trang bạn muốn thu thập, mà bạn thường có thể sao chép từ trình duyệt web của mình. Sau đó bạn sẽ cần đọc HTML cho trang đó vào R bằng read_html(). Function này trả về một đối tượng xml_document5 mà sau đó bạn sẽ thao tác bằng các function rvest:
html <- read_html("http://rvest.tidyverse.org/")
html
#> {html_document}
#> <html lang="en">
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n <a href="#container" class="visually-hidden-focusable">Ski ...rvest cũng bao gồm một function cho phép bạn viết HTML trực tiếp trong mã. Chúng tôi sẽ sử dụng điều này nhiều trong chương này khi chúng tôi dạy cách các function rvest khác nhau hoạt động với các ví dụ đơn giản.
html <- minimal_html("
<p>This is a paragraph</p>
<ul>
<li>This is a bulleted list</li>
</ul>
")
html
#> {html_document}
#> <html>
#> [1] <head>\n<meta http-equiv="Content-Type" content="text/html; charset=UT ...
#> [2] <body>\n<p>This is a paragraph</p>\n <ul>\n<li>This is a bulleted lis ...Bây giờ bạn đã có HTML trong R, đã đến lúc trích xuất dữ liệu bạn quan tâm. Đầu tiên bạn sẽ tìm hiểu về các bộ chọn CSS cho phép bạn xác định các phần tử bạn quan tâm và các function rvest mà bạn có thể sử dụng để trích xuất dữ liệu từ chúng. Sau đó chúng tôi sẽ giới thiệu ngắn gọn về bảng HTML, vốn có một số công cụ đặc biệt.
24.4.1 Tìm phần tử
CSS là viết tắt của cascading style sheets, và là một công cụ để định nghĩa kiểu dáng trực quan của các tài liệu HTML. CSS bao gồm một ngôn ngữ thu nhỏ để chọn các phần tử trên trang gọi là bộ chọn CSS (CSS selectors). Bộ chọn CSS định nghĩa các mẫu để định vị các phần tử HTML, và hữu ích cho việc thu thập dữ liệu web vì chúng cung cấp một cách ngắn gọn để mô tả những phần tử nào bạn muốn trích xuất.
Chúng tôi sẽ quay lại bộ chọn CSS chi tiết hơn trong Phần 24.5, nhưng may mắn là bạn có thể đi xa chỉ với ba loại:
pchọn tất cả phần tử<p>..titlechọn tất cả phần tử cóclasslà “title”.#titlechọn phần tử có thuộc tínhidbằng “title”. Thuộc tính id phải là duy nhất trong một tài liệu, nên điều này sẽ chỉ chọn một phần tử duy nhất.
Hãy thử các bộ chọn này với một ví dụ đơn giản:
html <- minimal_html("
<h1>This is a heading</h1>
<p id='first'>This is a paragraph</p>
<p class='important'>This is an important paragraph</p>
")Sử dụng html_elements() để tìm tất cả phần tử khớp với bộ chọn:
html |> html_elements("p")
#> {xml_nodeset (2)}
#> [1] <p id="first">This is a paragraph</p>
#> [2] <p class="important">This is an important paragraph</p>
html |> html_elements(".important")
#> {xml_nodeset (1)}
#> [1] <p class="important">This is an important paragraph</p>
html |> html_elements("#first")
#> {xml_nodeset (1)}
#> [1] <p id="first">This is a paragraph</p>Một function quan trọng khác là html_element() luôn trả về cùng số lượng đầu ra như đầu vào. Nếu bạn áp dụng nó cho toàn bộ tài liệu, nó sẽ cho bạn kết quả khớp đầu tiên:
html |> html_element("p")
#> {html_node}
#> <p id="first">Có một sự khác biệt quan trọng giữa html_element() và html_elements() khi bạn sử dụng một bộ chọn không khớp với bất kỳ phần tử nào. html_elements() trả về một vector có độ dài 0, trong khi html_element() trả về một missing value. Điều này sẽ quan trọng ngay sau đây.
html |> html_elements("b")
#> {xml_nodeset (0)}
html |> html_element("b")
#> {xml_missing}
#> <NA>24.4.2 Lựa chọn lồng nhau
Trong hầu hết các trường hợp, bạn sẽ sử dụng html_elements() và html_element() cùng nhau, thường sử dụng html_elements() để xác định các phần tử sẽ trở thành các quan sát (observations) rồi sử dụng html_element() để tìm các phần tử sẽ trở thành các biến (variables). Hãy xem điều này trong thực tế bằng một ví dụ đơn giản. Ở đây chúng ta có một list không có thứ tự (<ul>) trong đó mỗi mục list (<li>) chứa một số thông tin về bốn nhân vật từ StarWars:
html <- minimal_html("
<ul>
<li><b>C-3PO</b> is a <i>droid</i> that weighs <span class='weight'>167 kg</span></li>
<li><b>R4-P17</b> is a <i>droid</i></li>
<li><b>R2-D2</b> is a <i>droid</i> that weighs <span class='weight'>96 kg</span></li>
<li><b>Yoda</b> weighs <span class='weight'>66 kg</span></li>
</ul>
")Chúng ta có thể sử dụng html_elements() để tạo một vector trong đó mỗi phần tử tương ứng với một nhân vật khác nhau:
characters <- html |> html_elements("li")
characters
#> {xml_nodeset (4)}
#> [1] <li>\n<b>C-3PO</b> is a <i>droid</i> that weighs <span class="weight"> ...
#> [2] <li>\n<b>R4-P17</b> is a <i>droid</i>\n</li>
#> [3] <li>\n<b>R2-D2</b> is a <i>droid</i> that weighs <span class="weight"> ...
#> [4] <li>\n<b>Yoda</b> weighs <span class="weight">66 kg</span>\n</li>Để trích xuất tên của mỗi nhân vật, chúng ta sử dụng html_element(), vì khi áp dụng cho đầu ra của html_elements(), nó đảm bảo trả về một phản hồi cho mỗi phần tử:
characters |> html_element("b")
#> {xml_nodeset (4)}
#> [1] <b>C-3PO</b>
#> [2] <b>R4-P17</b>
#> [3] <b>R2-D2</b>
#> [4] <b>Yoda</b>Sự khác biệt giữa html_element() và html_elements() không quan trọng đối với tên, nhưng nó quan trọng đối với cân nặng. Chúng ta muốn lấy một giá trị cân nặng cho mỗi nhân vật, ngay cả khi không có <span> cân nặng. Đó là điều mà html_element() làm:
characters |> html_element(".weight")
#> {xml_nodeset (4)}
#> [1] <span class="weight">167 kg</span>
#> [2] NA
#> [3] <span class="weight">96 kg</span>
#> [4] <span class="weight">66 kg</span>html_elements() tìm tất cả <span> cân nặng là phần tử con của characters. Chỉ có ba cái, nên chúng ta mất kết nối giữa tên và cân nặng:
characters |> html_elements(".weight")
#> {xml_nodeset (3)}
#> [1] <span class="weight">167 kg</span>
#> [2] <span class="weight">96 kg</span>
#> [3] <span class="weight">66 kg</span>Bây giờ bạn đã chọn được các phần tử quan tâm, bạn sẽ cần trích xuất dữ liệu, từ nội dung văn bản hoặc một số thuộc tính.
24.4.3 Văn bản và thuộc tính
html_text2()6 trích xuất nội dung văn bản thuần túy của một phần tử HTML:
characters |>
html_element("b") |>
html_text2()
#> [1] "C-3PO" "R4-P17" "R2-D2" "Yoda"
characters |>
html_element(".weight") |>
html_text2()
#> [1] "167 kg" NA "96 kg" "66 kg"Lưu ý rằng mọi ký tự thoát sẽ được xử lý tự động; bạn sẽ chỉ thấy các ký tự thoát HTML trong mã nguồn HTML, không phải trong dữ liệu được rvest trả về.
html_attr() trích xuất dữ liệu từ các thuộc tính:
html <- minimal_html("
<p><a href='https://en.wikipedia.org/wiki/Cat'>cats</a></p>
<p><a href='https://en.wikipedia.org/wiki/Dog'>dogs</a></p>
")
html |>
html_elements("p") |>
html_element("a") |>
html_attr("href")
#> [1] "https://en.wikipedia.org/wiki/Cat" "https://en.wikipedia.org/wiki/Dog"html_attr() luôn trả về một string, vì vậy nếu bạn đang trích xuất số hoặc ngày tháng, bạn sẽ cần thực hiện một số xử lý hậu kỳ.
24.4.4 Bảng
Nếu bạn may mắn, dữ liệu của bạn sẽ đã được lưu trữ sẵn trong một bảng HTML, và chỉ là vấn đề đọc nó từ bảng đó. Thường rất dễ nhận ra một bảng trong trình duyệt của bạn: nó sẽ có cấu trúc hình chữ nhật gồm các row và column, và bạn có thể sao chép và dán nó vào một công cụ như Excel.
Bảng HTML được xây dựng từ bốn phần tử chính: <table>, <tr> (hàng bảng), <th> (tiêu đề bảng), và <td> (dữ liệu bảng). Đây là một bảng HTML đơn giản với hai column và ba row:
html <- minimal_html("
<table class='mytable'>
<tr><th>x</th> <th>y</th></tr>
<tr><td>1.5</td> <td>2.7</td></tr>
<tr><td>4.9</td> <td>1.3</td></tr>
<tr><td>7.2</td> <td>8.1</td></tr>
</table>
")rvest cung cấp một function biết cách đọc loại dữ liệu này: html_table(). Nó trả về một list chứa một tibble cho mỗi bảng tìm thấy trên trang. Sử dụng html_element() để xác định bảng bạn muốn trích xuất:
html |>
html_element(".mytable") |>
html_table()
#> # A tibble: 3 × 2
#> x y
#> <dbl> <dbl>
#> 1 1.5 2.7
#> 2 4.9 1.3
#> 3 7.2 8.1Lưu ý rằng x và y đã được tự động chuyển đổi thành số. Việc chuyển đổi tự động này không phải lúc nào cũng hoạt động, vì vậy trong các tình huống phức tạp hơn, bạn có thể muốn tắt nó bằng convert = FALSE và sau đó tự thực hiện chuyển đổi.
24.5 Tìm bộ chọn phù hợp
Tìm ra bộ chọn bạn cần cho dữ liệu của mình thường là phần khó nhất của vấn đề. Bạn sẽ thường cần thử nghiệm để tìm một bộ chọn vừa cụ thể (tức là nó không chọn những thứ bạn không quan tâm) vừa nhạy (tức là nó chọn mọi thứ bạn quan tâm). Nhiều lần thử và sai là một phần bình thường của quá trình! Có hai công cụ chính có sẵn để giúp bạn trong quá trình này: SelectorGadget và công cụ nhà phát triển của trình duyệt.
SelectorGadget là một bookmarklet javascript tự động tạo bộ chọn CSS dựa trên các ví dụ tích cực và tiêu cực mà bạn cung cấp. Nó không phải lúc nào cũng hoạt động, nhưng khi nó hoạt động, nó thật kỳ diệu! Bạn có thể tìm hiểu cách cài đặt và sử dụng SelectorGadget bằng cách đọc https://rvest.tidyverse.org/articles/selectorgadget.html hoặc xem video của Mine tại https://www.youtube.com/watch?v=PetWV5g1Xsc.
Mọi trình duyệt hiện đại đều đi kèm với một bộ công cụ dành cho nhà phát triển, nhưng chúng tôi khuyên dùng Chrome, ngay cả khi nó không phải trình duyệt thường dùng của bạn: công cụ nhà phát triển web của nó thuộc loại tốt nhất và có sẵn ngay lập tức. Nhấp chuột phải vào một phần tử trên trang và nhấp Inspect. Thao tác này sẽ mở một chế độ xem có thể mở rộng của toàn bộ trang HTML, tập trung vào phần tử mà bạn vừa nhấp. Bạn có thể sử dụng điều này để khám phá trang và có ý tưởng về những bộ chọn nào có thể hoạt động. Hãy đặc biệt chú ý đến các thuộc tính class và id, vì chúng thường được sử dụng để tạo cấu trúc trực quan của trang, và do đó là công cụ tốt để trích xuất dữ liệu bạn đang tìm kiếm.
Bên trong chế độ xem Elements, bạn cũng có thể nhấp chuột phải vào một phần tử và chọn Copy as Selector để tạo một bộ chọn sẽ xác định duy nhất phần tử bạn quan tâm.
Nếu SelectorGadget hoặc Chrome DevTools đã tạo một bộ chọn CSS mà bạn không hiểu, hãy thử Selectors Explained để dịch bộ chọn CSS sang tiếng Anh thuần. Nếu bạn thấy mình làm điều này thường xuyên, bạn có thể muốn tìm hiểu thêm về bộ chọn CSS nói chung. Chúng tôi khuyên bắt đầu với hướng dẫn thú vị CSS dinner và sau đó tham khảo MDN web docs.
24.6 Kết hợp tất cả lại
Hãy kết hợp tất cả lại để thu thập dữ liệu từ một số trang web. Có một rủi ro là các ví dụ này có thể không còn hoạt động khi bạn chạy chúng — đó là thách thức cơ bản của thu thập dữ liệu web; nếu cấu trúc của trang thay đổi, thì bạn sẽ phải thay đổi mã thu thập dữ liệu của mình.
24.6.1 StarWars
rvest bao gồm một ví dụ rất đơn giản trong vignette("starwars"). Đây là một trang đơn giản với HTML tối thiểu nên đây là nơi tốt để bắt đầu. Tôi khuyến khích bạn điều hướng đến trang đó ngay bây giờ và sử dụng “Inspect Element” để kiểm tra một trong các tiêu đề là tên của một bộ phim Star Wars. Sử dụng bàn phím hoặc chuột để khám phá hệ thống phân cấp của HTML và xem liệu bạn có thể nắm được cấu trúc chung được sử dụng bởi mỗi bộ phim hay không.
Bạn sẽ có thể thấy rằng mỗi bộ phim có một cấu trúc chung trông như thế này:
<section>
<h2 data-id="1">The Phantom Menace</h2>
<p>Released: 1999-05-19</p>
<p>Director: <span class="director">George Lucas</span></p>
<div class="crawl">
<p>...</p>
<p>...</p>
<p>...</p>
</div>
</section>Mục tiêu của chúng ta là biến dữ liệu này thành một data frame 7 row với các biến title, year, director, và intro. Chúng ta sẽ bắt đầu bằng cách đọc HTML và trích xuất tất cả các phần tử <section>:
url <- "https://rvest.tidyverse.org/articles/starwars.html"
html <- read_html(url)
section <- html |> html_elements("section")
section
#> {xml_nodeset (7)}
#> [1] <section><h2 data-id="1">\nThe Phantom Menace\n</h2>\n<p>\nReleased: 1 ...
#> [2] <section><h2 data-id="2">\nAttack of the Clones\n</h2>\n<p>\nReleased: ...
#> [3] <section><h2 data-id="3">\nRevenge of the Sith\n</h2>\n<p>\nReleased: ...
#> [4] <section><h2 data-id="4">\nA New Hope\n</h2>\n<p>\nReleased: 1977-05-2 ...
#> [5] <section><h2 data-id="5">\nThe Empire Strikes Back\n</h2>\n<p>\nReleas ...
#> [6] <section><h2 data-id="6">\nReturn of the Jedi\n</h2>\n<p>\nReleased: 1 ...
#> [7] <section><h2 data-id="7">\nThe Force Awakens\n</h2>\n<p>\nReleased: 20 ...Điều này truy xuất bảy phần tử tương ứng với bảy bộ phim tìm thấy trên trang đó, cho thấy rằng sử dụng section làm bộ chọn là tốt. Trích xuất các phần tử riêng lẻ khá đơn giản vì dữ liệu luôn nằm trong văn bản. Chỉ là vấn đề tìm đúng bộ chọn:
section |> html_element("h2") |> html_text2()
#> [1] "The Phantom Menace" "Attack of the Clones"
#> [3] "Revenge of the Sith" "A New Hope"
#> [5] "The Empire Strikes Back" "Return of the Jedi"
#> [7] "The Force Awakens"
section |> html_element(".director") |> html_text2()
#> [1] "George Lucas" "George Lucas" "George Lucas"
#> [4] "George Lucas" "Irvin Kershner" "Richard Marquand"
#> [7] "J. J. Abrams"Khi chúng ta đã làm điều đó cho mỗi thành phần, chúng ta có thể gói tất cả kết quả vào một tibble:
tibble(
title = section |>
html_element("h2") |>
html_text2(),
released = section |>
html_element("p") |>
html_text2() |>
str_remove("Released: ") |>
parse_date(),
director = section |>
html_element(".director") |>
html_text2(),
intro = section |>
html_element(".crawl") |>
html_text2()
)
#> # A tibble: 7 × 4
#> title released director intro
#> <chr> <date> <chr> <chr>
#> 1 The Phantom Menace 1999-05-19 George Lucas "Turmoil has engulfed …
#> 2 Attack of the Clones 2002-05-16 George Lucas "There is unrest in th…
#> 3 Revenge of the Sith 2005-05-19 George Lucas "War! The Republic is …
#> 4 A New Hope 1977-05-25 George Lucas "It is a period of civ…
#> 5 The Empire Strikes Back 1980-05-17 Irvin Kershner "It is a dark time for…
#> 6 Return of the Jedi 1983-05-25 Richard Marquand "Luke Skywalker has re…
#> # ℹ 1 more rowChúng tôi đã xử lý thêm một chút cho released để có được một biến dễ sử dụng hơn trong phân tích sau này.
24.6.2 Các phim row đầu IMDB
Cho nhiệm vụ tiếp theo, chúng ta sẽ xử lý một thứ khó hơn một chút, trích xuất 250 phim row đầu từ database phim internet (IMDb). Vào thời điểm chúng tôi viết chương này, trang trông giống như Hình 24.1.
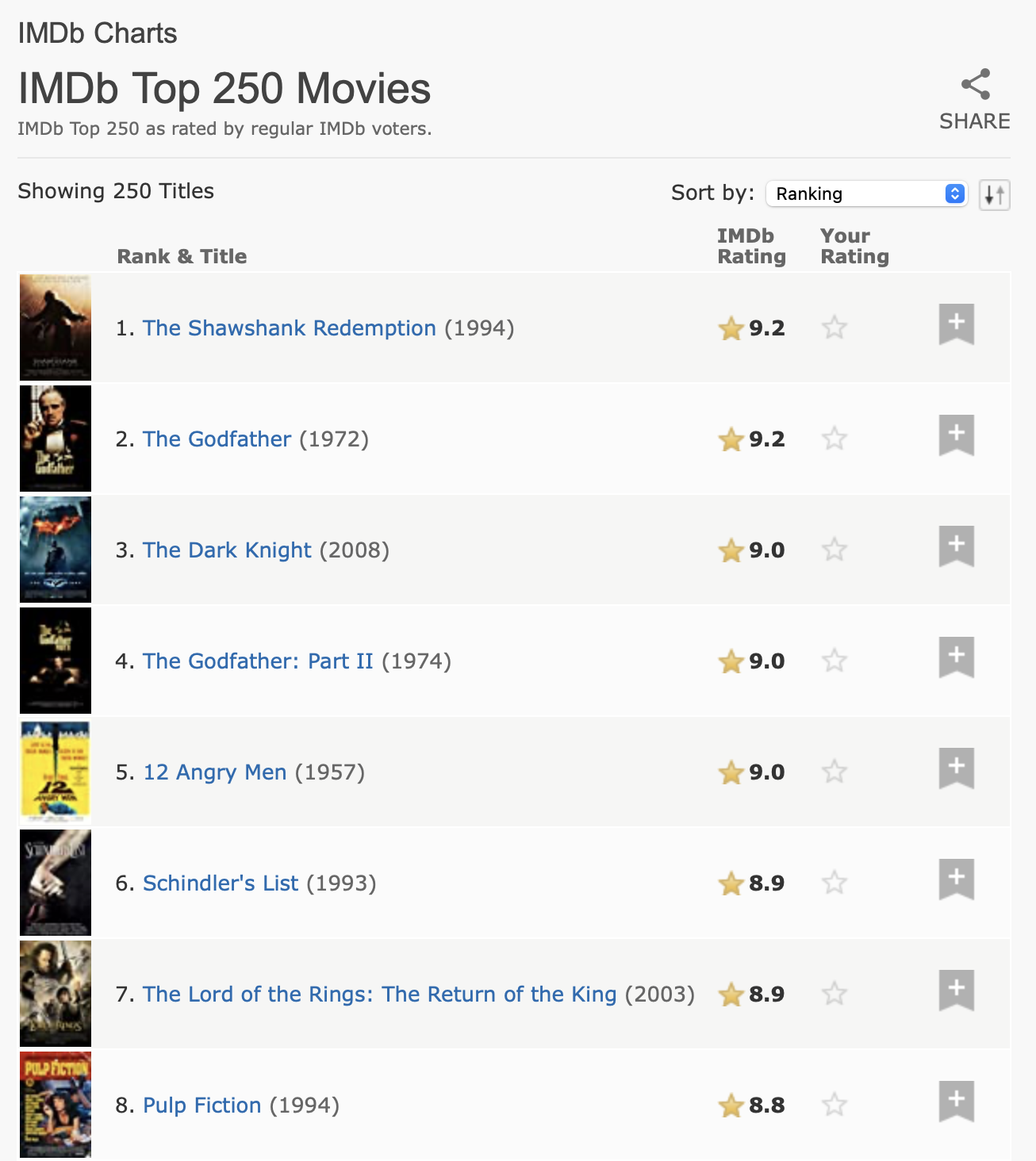
Dữ liệu này có cấu trúc dạng bảng rõ ràng nên đáng để bắt đầu với html_table():
url <- "https://web.archive.org/web/20220201012049/https://www.imdb.com/chart/top/"
html <- read_html(url)
table <- html |>
html_element("table") |>
html_table()
table
#> # A tibble: 250 × 5
#> `` `Rank & Title` `IMDb Rating` `Your Rating` ``
#> <lgl> <chr> <dbl> <chr> <lgl>
#> 1 NA "1.\n The Shawshank Redempt… 9.2 "12345678910\n… NA
#> 2 NA "2.\n The Godfather\n … 9.1 "12345678910\n… NA
#> 3 NA "3.\n The Godfather: Part I… 9 "12345678910\n… NA
#> 4 NA "4.\n The Dark Knight\n … 9 "12345678910\n… NA
#> 5 NA "5.\n 12 Angry Men\n … 8.9 "12345678910\n… NA
#> 6 NA "6.\n Schindler's List\n … 8.9 "12345678910\n… NA
#> # ℹ 244 more rowsKết quả này bao gồm một vài column trống, nhưng nhìn chung làm tốt việc nắm bắt thông tin từ bảng. Tuy nhiên, chúng ta cần thực hiện thêm một số xử lý để làm cho nó dễ sử dụng hơn. Đầu tiên, chúng ta sẽ đổi tên các column để dễ làm việc hơn, và loại bỏ khoảng trắng thừa trong thứ hạng và tiêu đề. Chúng ta sẽ làm điều này với select() (thay vì rename()) để thực hiện việc đổi tên và chọn chỉ hai column này trong một bước. Sau đó chúng ta sẽ loại bỏ các dòng mới và khoảng trắng thừa, và sau đó áp dụng separate_wider_regex() (từ Phần 15.3.4) để tách tiêu đề, năm, và thứ hạng vào các biến riêng.
ratings <- table |>
select(
rank_title_year = `Rank & Title`,
rating = `IMDb Rating`
) |>
mutate(
rank_title_year = str_replace_all(rank_title_year, "\n +", " ")
) |>
separate_wider_regex(
rank_title_year,
patterns = c(
rank = "\\d+", "\\. ",
title = ".+", " +\\(",
year = "\\d+", "\\)"
)
)
ratings
#> # A tibble: 250 × 4
#> rank title year rating
#> <chr> <chr> <chr> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2
#> 2 2 The Godfather 1972 9.1
#> 3 3 The Godfather: Part II 1974 9
#> 4 4 The Dark Knight 2008 9
#> 5 5 12 Angry Men 1957 8.9
#> 6 6 Schindler's List 1993 8.9
#> # ℹ 244 more rowsNgay cả trong trường hợp này khi hầu hết dữ liệu đến từ các ô bảng, vẫn đáng để xem HTML thô. Nếu bạn làm vậy, bạn sẽ phát hiện rằng chúng ta có thể thêm một chút dữ liệu bổ sung bằng cách sử dụng một trong các thuộc tính. Đây là một trong những lý do đáng để dành một chút thời gian khám phá mã nguồn của trang; bạn có thể tìm thấy dữ liệu bổ sung, hoặc có thể tìm thấy một cách phân tích dễ hơn một chút.
html |>
html_elements("td strong") |>
head() |>
html_attr("title")
#> [1] "9.2 based on 2,536,415 user ratings"
#> [2] "9.1 based on 1,745,675 user ratings"
#> [3] "9.0 based on 1,211,032 user ratings"
#> [4] "9.0 based on 2,486,931 user ratings"
#> [5] "8.9 based on 749,563 user ratings"
#> [6] "8.9 based on 1,295,705 user ratings"Chúng ta có thể kết hợp điều này với dữ liệu dạng bảng và một lần nữa áp dụng separate_wider_regex() để trích xuất phần dữ liệu chúng ta quan tâm:
ratings |>
mutate(
rating_n = html |> html_elements("td strong") |> html_attr("title")
) |>
separate_wider_regex(
rating_n,
patterns = c(
"[0-9.]+ based on ",
number = "[0-9,]+",
" user ratings"
)
) |>
mutate(
number = parse_number(number)
)
#> # A tibble: 250 × 5
#> rank title year rating number
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 1 The Shawshank Redemption 1994 9.2 2536415
#> 2 2 The Godfather 1972 9.1 1745675
#> 3 3 The Godfather: Part II 1974 9 1211032
#> 4 4 The Dark Knight 2008 9 2486931
#> 5 5 12 Angry Men 1957 8.9 749563
#> 6 6 Schindler's List 1993 8.9 1295705
#> # ℹ 244 more rows24.7 Trang web động
Cho đến nay chúng tôi đã tập trung vào các trang web nơi html_elements() trả về những gì bạn thấy trong trình duyệt và đã thảo luận cách phân tích những gì nó trả về và cách tổ chức thông tin đó thành các data frame gọn gàng. Tuy nhiên, thỉnh thoảng bạn sẽ gặp một trang web nơi html_elements() và các function liên quan không trả về bất kỳ thứ gì giống với những gì bạn thấy trong trình duyệt. Trong nhiều trường hợp, đó là vì bạn đang cố thu thập dữ liệu từ một trang web tạo nội dung trang một cách động bằng javascript. Điều này hiện không hoạt động với rvest, vì rvest tải HTML thô và không chạy bất kỳ javascript nào.
Vẫn có thể thu thập dữ liệu từ các loại trang web này, nhưng rvest cần sử dụng một workflow tốn kém hơn: mô phỏng đầy đủ trình duyệt web bao gồm chạy tất cả javascript. Chức năng này chưa có sẵn tại thời điểm viết, nhưng đây là điều chúng tôi đang tích cực phát triển và có thể sẵn sàng khi bạn đọc đến đây. Nó sử dụng package chromote thực sự chạy trình duyệt Chrome ở chế độ nền, và cung cấp cho bạn các công cụ bổ sung để tương tác với trang web, giống như một người gõ văn bản và nhấp vào các nút. Hãy kiểm tra trang web rvest để biết thêm chi tiết.
24.8 Tóm tắt
Trong chương này, bạn đã tìm hiểu về lý do nên, lý do không nên, và cách thu thập dữ liệu từ các trang web. Đầu tiên, bạn đã tìm hiểu về những kiến thức cơ bản của HTML và sử dụng bộ chọn CSS để tham chiếu đến các phần tử cụ thể, sau đó bạn đã tìm hiểu về việc sử dụng package rvest để lấy dữ liệu ra khỏi HTML và đưa vào R. Sau đó chúng tôi đã minh họa thu thập dữ liệu web với hai nghiên cứu tình huống: một script đơn giản hơn về thu thập dữ liệu phim StarWars từ trang web của package rvest và một script phức tạp hơn về thu thập 250 phim row đầu từ IMDB.
Các chi tiết kỹ thuật của việc thu thập dữ liệu từ web có thể phức tạp, đặc biệt khi xử lý các trang web, tuy nhiên các cân nhắc pháp lý và đạo đức có thể còn phức tạp hơn. Điều quan trọng là bạn phải tự tìm hiểu về cả hai điều này trước khi bắt đầu thu thập dữ liệu.
Điều này đưa chúng ta đến cuối phần nhập dữ liệu của cuốn sách, nơi bạn đã học các kỹ thuật để lấy dữ liệu từ nơi nó tồn tại (spreadsheet, database, tệp JSON, và trang web) vào dạng gọn gàng trong R. Bây giờ đã đến lúc hướng tầm nhìn sang một theme mới: tận dụng tối đa R như một ngôn ngữ lập trình.
Và nhiều API phổ biến đã có các package CRAN bao bọc sẵn, nên hãy bắt đầu bằng việc tìm hiểu một chút trước!↩︎
Rõ ràng là chúng tôi không phải luật sư, và đây không phải lời khuyên pháp lý. Nhưng đây là tóm tắt tốt nhất mà chúng tôi có thể đưa ra sau khi đọc rất nhiều về theme này.↩︎
Một ví dụ về bài viết về nghiên cứu OkCupid được đăng trên Wired, https://www.wired.com/2016/05/okcupid-study-reveals-perils-big-data-science.↩︎
Một số thẻ (bao gồm
<p>và<li>) không yêu cầu thẻ đóng, nhưng chúng tôi nghĩ tốt nhất nên bao gồm chúng vì nó giúp nhìn cấu trúc của HTML dễ dàng hơn một chút.↩︎Lớp này đến từ package xml2. xml2 là một package cấp thấp mà rvest xây dựng dựa trên.↩︎
rvest cũng cung cấp
html_text()nhưng bạn hầu như luôn nên sử dụnghtml_text2()vì nó chuyển đổi HTML lồng nhau thành văn bản tốt hơn.↩︎