13 Số
13.1 Giới thiệu
Vector số (numeric vector) là xương sống của khoa học dữ liệu, và bạn đã sử dụng chúng rất nhiều lần ở phần trước của cuốn sách. Bây giờ là lúc khảo sát một cách có hệ thống những gì bạn có thể làm với chúng trong R, đảm bảo rằng bạn có đủ khả năng xử lý bất kỳ vấn đề nào liên quan đến vector số trong tương lai.
Chúng ta sẽ bắt đầu bằng một vài công cụ để tạo số từ string, sau đó đi sâu hơn một chút vào count(). Tiếp theo, chúng ta sẽ khám phá các phép biến đổi (transformation) số khác nhau phù hợp với mutate(), bao gồm các phép biến đổi tổng quát hơn có thể áp dụng cho các loại vector khác nhưng thường được dùng với vector số. Cuối cùng, chúng ta sẽ đề cập đến các function tóm tắt (summary function) phù hợp với summarize() và chỉ cho bạn cách chúng cũng có thể được sử dụng với mutate().
13.1.1 Điều kiện tiên quyết
Chương này chủ yếu sử dụng các function từ R cơ sở (base R), có sẵn mà không cần tải bất kỳ package nào. Nhưng chúng ta vẫn cần tidyverse vì chúng ta sẽ sử dụng các function R cơ sở bên trong các function tidyverse như mutate() và filter(). Giống như chương trước, chúng ta sẽ dùng các ví dụ thực từ nycflights13, cũng như các ví dụ đơn giản được tạo bằng c() và tribble().
13.2 Tạo số
Trong hầu hết các trường hợp, bạn sẽ nhận được số đã được lưu ở một trong các kiểu số của R: số nguyên (integer) hoặc số thực (double). Tuy nhiên, trong một số trường hợp, bạn sẽ gặp chúng dưới dạng string, có thể vì bạn đã tạo chúng bằng cách xoay (pivot) từ tiêu đề column hoặc vì có gì đó sai trong quá trình nhập dữ liệu.
readr cung cấp hai function hữu ích để phân tích cú pháp string thành số: parse_double() và parse_number(). Sử dụng parse_double() khi bạn có các số đã được viết dưới dạng string:
x <- c("1.2", "5.6", "1e3")
parse_double(x)
#> [1] 1.2 5.6 1000.0Sử dụng parse_number() khi string chứa văn bản không phải số mà bạn muốn bỏ qua. Điều này đặc biệt hữu ích cho dữ liệu tiền tệ và phần trăm:
x <- c("$1,234", "USD 3,513", "59%")
parse_number(x)
#> [1] 1234 3513 5913.3 Đếm
Thật ngạc nhiên là bạn có thể làm được bao nhiêu việc trong khoa học dữ liệu chỉ với phép đếm và một chút số học cơ bản, vì vậy dplyr cố gắng làm cho việc đếm dễ dàng nhất có thể với count(). Function này rất tốt cho việc khám phá nhanh và kiểm tra trong quá trình phân tích:
flights |> count(dest)
#> # A tibble: 105 × 2
#> dest n
#> <chr> <int>
#> 1 ABQ 254
#> 2 ACK 265
#> 3 ALB 439
#> 4 ANC 8
#> 5 ATL 17215
#> 6 AUS 2439
#> # ℹ 99 more rows(Mặc dù có lời khuyên trong Chương 4, chúng ta thường đặt count() trên một dòng đơn vì nó thường được dùng tại console để kiểm tra nhanh xem một phép tính có hoạt động đúng như mong đợi không.)
Nếu bạn muốn xem các giá trị phổ biến nhất, thêm sort = TRUE:
flights |> count(dest, sort = TRUE)
#> # A tibble: 105 × 2
#> dest n
#> <chr> <int>
#> 1 ORD 17283
#> 2 ATL 17215
#> 3 LAX 16174
#> 4 BOS 15508
#> 5 MCO 14082
#> 6 CLT 14064
#> # ℹ 99 more rowsVà hãy nhớ rằng nếu bạn muốn xem tất cả các giá trị, bạn có thể sử dụng |> View() hoặc |> print(n = Inf).
Bạn có thể thực hiện cùng phép tính “bằng tay” với group_by(), summarize() và n(). Điều này hữu ích vì nó cho phép bạn tính các tóm tắt khác cùng lúc:
n() là một function tóm tắt đặc biệt không nhận bất kỳ argument nào mà thay vào đó truy cập thông tin về nhóm “hiện tại”. Điều này có nghĩa là nó chỉ hoạt động bên trong các động từ dplyr:
n()
#> Error in `n()`:
#> ! Must only be used inside data-masking verbs like `mutate()`,
#> `filter()`, and `group_by()`.Có một vài biến thể của n() và count() mà bạn có thể thấy hữu ích:
-
n_distinct(x)đếm số lượng giá trị riêng biệt (duy nhất) của một hoặc nhiều biến. Ví dụ, chúng ta có thể tìm xem điểm đến nào được phục vụ bởi nhiều hãng bay nhất:flights |> group_by(dest) |> summarize(carriers = n_distinct(carrier)) |> arrange(desc(carriers)) #> # A tibble: 105 × 2 #> dest carriers #> <chr> <int> #> 1 ATL 7 #> 2 BOS 7 #> 3 CLT 7 #> 4 ORD 7 #> 5 TPA 7 #> 6 AUS 6 #> # ℹ 99 more rows -
Đếm có trọng số (weighted count) là một phép tổng. Ví dụ bạn có thể “đếm” số dặm mà mỗi máy bay đã bay:
Đếm có trọng số là một vấn đề phổ biến nên
count()có argumentwtthực hiện cùng một việc:flights |> count(tailnum, wt = distance) -
Bạn có thể đếm các missing value bằng cách kết hợp
sum()vàis.na(). Trong tập dữ liệuflights, đây là các chuyến bay đã bị hủy:
13.3.1 Bài tập
- Làm thế nào bạn có thể sử dụng
count()để đếm số row có missing value cho một biến nhất định? - Mở rộng các lệnh gọi
count()sau đây để thay vào đó sử dụnggroup_by(),summarize(), vàarrange():flights |> count(dest, sort = TRUE)flights |> count(tailnum, wt = distance)
13.4 Biến đổi số
Các function biến đổi hoạt động tốt với mutate() vì đầu ra của chúng có cùng độ dài với đầu vào. Phần lớn các function biến đổi đã được tích hợp sẵn trong R cơ sở. Việc liệt kê tất cả chúng là không thực tế nên phần này sẽ trình bày những function hữu ích nhất. Ví dụ, mặc dù R cung cấp tất cả các function lượng giác mà bạn có thể mơ ước, chúng ta không liệt kê chúng ở đây vì chúng hiếm khi cần thiết cho khoa học dữ liệu.
13.4.1 Số học và quy tắc tái chế
Chúng ta đã giới thiệu các phép toán cơ bản (+, -, *, /, ^) trong Chương 2 và đã sử dụng chúng rất nhiều kể từ đó. Các function này không cần giải thích nhiều vì chúng thực hiện những gì bạn đã học ở trường. Nhưng chúng ta cần nói ngắn gọn về quy tắc tái chế (recycling rule) xác định điều gì xảy ra khi vế trái và vế phải có độ dài khác nhau. Điều này quan trọng cho các phép toán như flights |> mutate(air_time = air_time / 60) vì có 336.776 số ở bên trái của / nhưng chỉ có một số ở bên phải.
R xử lý độ dài không khớp bằng cách tái chế, hay iterate lại, vector ngắn hơn. Chúng ta có thể thấy điều này hoạt động dễ dàng hơn nếu tạo một số vector bên ngoài data frame:
Thông thường, bạn chỉ muốn tái chế các số đơn lẻ (tức là vector có độ dài 1), nhưng R sẽ tái chế bất kỳ vector nào có độ dài ngắn hơn. Nó thường (nhưng không phải luôn luôn) đưa ra cảnh báo nếu vector dài hơn không phải là bội số của vector ngắn hơn:
Các quy tắc tái chế này cũng được áp dụng cho các phép so sánh logic (==, <, <=, >, >=, !=) và có thể dẫn đến kết quả bất ngờ nếu bạn vô tình sử dụng == thay vì %in% và data frame có số row không may. Ví dụ, hãy xem đoạn mã này cố gắng tìm tất cả các chuyến bay trong tháng Một và tháng Hai:
flights |>
filter(month == c(1, 2))
#> # A tibble: 25,977 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 542 540 2 923 850
#> 3 2013 1 1 554 600 -6 812 837
#> 4 2013 1 1 555 600 -5 913 854
#> 5 2013 1 1 557 600 -3 838 846
#> 6 2013 1 1 558 600 -2 849 851
#> # ℹ 25,971 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Đoạn mã chạy mà không có lỗi, nhưng nó không trả về kết quả bạn muốn. Vì quy tắc tái chế, nó tìm các chuyến bay ở row lẻ khởi hành trong tháng Một và các chuyến bay ở row chẵn khởi hành trong tháng Hai. Và thật không may là không có cảnh báo vì flights có số row chẵn.
Để bảo vệ bạn khỏi loại lỗi thầm lặng này, hầu hết các function tidyverse sử dụng một dạng tái chế chặt chẽ hơn chỉ tái chế các giá trị đơn lẻ. Thật không may, điều đó không giúp ích ở đây, hoặc trong nhiều trường hợp khác, vì phép tính chính được thực hiện bởi function R cơ sở ==, không phải filter().
13.4.2 Giá trị nhỏ nhất và lớn nhất
Các function số học hoạt động với các cặp biến. Hai function liên quan chặt chẽ là pmin() và pmax(), khi được cung cấp hai hoặc nhiều biến sẽ trả về giá trị nhỏ nhất hoặc lớn nhất trong mỗi row:
Lưu ý rằng các function này khác với các function tóm tắt min() và max() vốn nhận nhiều quan sát và trả về một giá trị duy nhất. Bạn có thể nhận ra mình đã dùng sai dạng khi tất cả các giá trị nhỏ nhất và tất cả các giá trị lớn nhất đều giống nhau:
13.4.3 Số học modular
Số học modular (modular arithmetic) là tên kỹ thuật cho loại toán bạn đã làm trước khi học về số thập phân, tức là phép chia cho ra một số nguyên và một phần dư. Trong R, %/% thực hiện phép chia lấy phần nguyên và %% tính phần dư:
Số học modular rất tiện cho tập dữ liệu flights, vì chúng ta có thể sử dụng nó để tách biến sched_dep_time thành hour và minute:
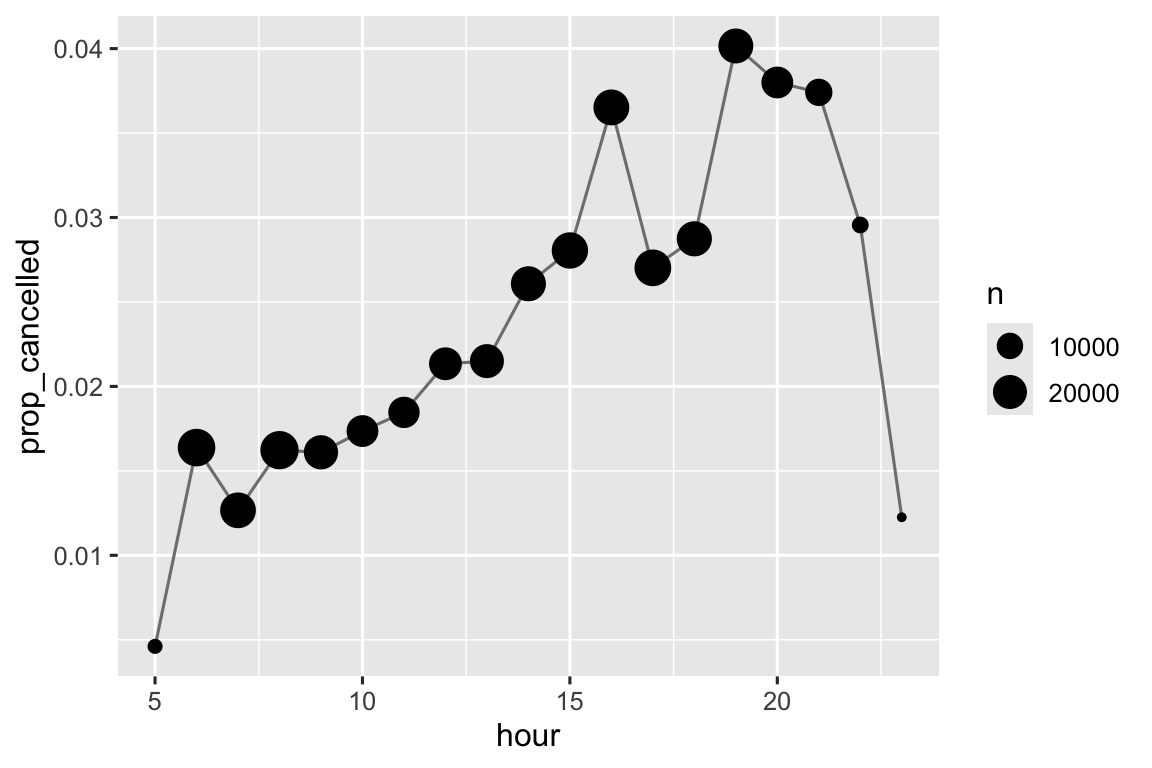
Chúng ta có thể kết hợp điều đó với thủ thuật mean(is.na(x)) từ Phần 12.4 để xem tỷ lệ chuyến bay bị hủy thay đổi như thế nào trong suốt cả ngày. Kết quả được hiển thị trong Hình 13.1.
13.4.4 Logarit
Logarit (logarithm) là một phép biến đổi cực kỳ hữu ích để xử lý dữ liệu trải dài trên nhiều bậc độ lớn và chuyển đổi tăng trưởng function mũ thành tăng trưởng tuyến tính. Trong R, bạn có thể chọn ba loại logarit: log() (logarit tự nhiên, cơ số e), log2() (cơ số 2), và log10() (cơ số 10). Chúng tôi khuyên dùng log2() hoặc log10(). log2() dễ diễn giải vì chênh lệch 1 trên thang logarit tương ứng với gấp đôi trên thang gốc và chênh lệch -1 tương ứng với giảm một nửa; trong khi log10() dễ chuyển ngược vì (ví dụ) 3 là 10^3 = 1000. Nghịch đảo của log() là exp(); để tính nghịch đảo của log2() hoặc log10() bạn sẽ cần dùng 2^ hoặc 10^.
13.4.5 Làm tròn
Sử dụng round(x) để làm tròn một số đến số nguyên gần nhất:
round(123.456)
#> [1] 123Bạn có thể kiểm soát độ chính xác của việc làm tròn với argument thứ hai, digits. round(x, digits) làm tròn đến 10^-n gần nhất nên digits = 2 sẽ làm tròn đến 0,01 gần nhất. Định nghĩa này hữu ích vì nó ngụ ý round(x, -3) sẽ làm tròn đến row nghìn gần nhất, và đúng là vậy:
Có một điều kỳ lạ với round() thoạt nhìn có vẻ ngạc nhiên:
round() sử dụng phương pháp gọi là “làm tròn nửa về số chẵn” (round half to even) hay làm tròn kiểu ngân row (Banker’s rounding): nếu một số nằm giữa hai số nguyên, nó sẽ được làm tròn đến số nguyên chẵn. Đây là một chiến lược tốt vì nó giữ cho việc làm tròn không bị thiên lệch: một nửa của tất cả các số 0,5 được làm tròn lên, và nửa còn lại được làm tròn xuống.
round() đi kèm với floor() luôn làm tròn xuống và ceiling() luôn làm tròn lên:
Các function này không có argument digits, vì vậy bạn có thể thu nhỏ, làm tròn, rồi phóng to lại:
Bạn có thể sử dụng cùng kỹ thuật nếu muốn round() đến bội số của một số khác:
13.4.6 Chia số thành các khoảng
Sử dụng cut()1 để phân chia (hay còn gọi là phân nhóm) một vector số thành các nhóm rời rạc:
Các điểm chia không cần phải cách đều nhau:
Bạn có thể tùy chọn cung cấp labels của riêng mình. Lưu ý rằng số labels nên ít hơn breaks một đơn vị.
Bất kỳ giá trị nào nằm ngoài phạm vi của các điểm chia sẽ trở thành NA:
Xem tài liệu hướng dẫn để biết các argument hữu ích khác như right và include.lowest, kiểm soát xem các khoảng là [a, b) hay (a, b] và khoảng thấp nhất có nên là [a, b] hay không.
13.4.7 Tổng tích lũy và tổng hợp trượt
R cơ sở cung cấp cumsum(), cumprod(), cummin(), cummax() cho các phép tính tích lũy (cumulative) của tổng, tích, giá trị nhỏ nhất và lớn nhất. dplyr cung cấp cummean() cho trung bình tích lũy. Tổng tích lũy là function hay gặp nhất trong thực tế:
x <- 1:10
cumsum(x)
#> [1] 1 3 6 10 15 21 28 36 45 55Nếu bạn cần các phép tổng hợp trượt (rolling aggregate) phức tạp hơn, hãy thử package slider.
13.4.8 Bài tập
Giải thích bằng lời mỗi dòng của đoạn mã được sử dụng để tạo Hình 13.1.
R cung cấp những function lượng giác nào? Hãy đoán một số tên và tra cứu tài liệu hướng dẫn. Chúng sử dụng độ hay radian?
-
Hiện tại
dep_timevàsched_dep_timetrông tiện lợi nhưng khó tính toán vì chúng không thực sự là các số liên tục. Bạn có thể thấy vấn đề cơ bản bằng cách chạy đoạn mã dưới đây: có một khoảng trống giữa mỗi giờ.flights |> filter(month == 1, day == 1) |> ggplot(aes(x = sched_dep_time, y = dep_delay)) + geom_point()Chuyển đổi chúng thành biểu diễn thời gian chính xác hơn (giờ phân số hoặc phút kể từ nửa đêm).
Làm tròn
dep_timevàarr_timeđến bội số năm phút gần nhất.
13.5 Biến đổi tổng quát
Các phần sau mô tả một số phép biến đổi tổng quát thường được sử dụng với vector số, nhưng cũng có thể áp dụng cho tất cả các loại column khác.
13.5.1 Xếp hạng
dplyr cung cấp một số function xếp hạng (ranking function) lấy cảm hứng từ SQL, nhưng bạn nên luôn bắt đầu với dplyr::min_rank(). Nó sử dụng phương pháp điển hình để xử lý các giá trị bằng nhau, ví dụ: thứ 1, thứ 2, thứ 2, thứ 4.
Lưu ý rằng các giá trị nhỏ nhất được xếp hạng thấp nhất; sử dụng desc(x) để cho các giá trị lớn nhất hạng nhỏ nhất:
Nếu min_rank() không đáp ứng nhu cầu của bạn, hãy xem các biến thể dplyr::row_number(), dplyr::dense_rank(), dplyr::percent_rank(), và dplyr::cume_dist(). Xem tài liệu hướng dẫn để biết chi tiết.
df <- tibble(x = x)
df |>
mutate(
row_number = row_number(x),
dense_rank = dense_rank(x),
percent_rank = percent_rank(x),
cume_dist = cume_dist(x)
)
#> # A tibble: 6 × 5
#> x row_number dense_rank percent_rank cume_dist
#> <dbl> <int> <int> <dbl> <dbl>
#> 1 1 1 1 0 0.2
#> 2 5 2 2 0.25 0.6
#> 3 5 3 2 0.25 0.6
#> 4 17 4 3 0.75 0.8
#> 5 22 5 4 1 1
#> 6 NA NA NA NA NABạn có thể đạt được nhiều kết quả tương tự bằng cách chọn argument ties.method phù hợp cho function rank() của R cơ sở; bạn có thể cũng muốn đặt na.last = "keep" để giữ NA dưới dạng NA.
row_number() cũng có thể được sử dụng mà không có argument nào khi ở bên trong một động từ dplyr. Trong trường hợp này, nó sẽ cho số thứ tự của row “hiện tại”. Khi kết hợp với %% hoặc %/%, đây là một công cụ hữu ích để chia dữ liệu thành các nhóm có kích thước tương tự:
df <- tibble(id = 1:10)
df |>
mutate(
row0 = row_number() - 1,
three_groups = row0 %% 3,
three_in_each_group = row0 %/% 3
)
#> # A tibble: 10 × 4
#> id row0 three_groups three_in_each_group
#> <int> <dbl> <dbl> <dbl>
#> 1 1 0 0 0
#> 2 2 1 1 0
#> 3 3 2 2 0
#> 4 4 3 0 1
#> 5 5 4 1 1
#> 6 6 5 2 1
#> # ℹ 4 more rows13.5.2 Độ lệch
dplyr::lead() và dplyr::lag() cho phép bạn tham chiếu đến các giá trị ngay trước hoặc ngay sau giá trị “hiện tại”. Chúng trả về một vector có cùng độ dài với đầu vào, được đệm bằng NA ở đầu hoặc cuối:
-
x - lag(x)cho bạn hiệu giữa giá trị hiện tại và giá trị trước đó.x - lag(x) #> [1] NA 3 6 0 8 16 -
x == lag(x)cho bạn biết khi nào giá trị hiện tại thay đổi.x == lag(x) #> [1] NA FALSE FALSE TRUE FALSE FALSE
Bạn có thể dịch chuyển nhiều hơn một vị trí bằng cách sử dụng argument thứ hai, n.
13.5.3 Định danh liên tiếp
Đôi khi bạn muốn bắt đầu một nhóm mới mỗi khi một sự kiện nào đó xảy ra. Ví dụ, khi bạn đang xem dữ liệu trang web, thường sẽ muốn chia các sự kiện thành các phiên (session), trong đó bạn bắt đầu một phiên mới sau khoảng cách hơn x phút kể từ hoạt động cuối cùng. Ví dụ, hãy tưởng tượng bạn có thời điểm ai đó truy cập trang web:
Và bạn đã tính thời gian giữa mỗi sự kiện, và xác định xem có khoảng trống đủ lớn không:
Nhưng làm thế nào để chuyển từ vector logic đó thành thứ gì đó mà chúng ta có thể group_by()? cumsum(), từ Phần 13.4.7, giải cứu vì khoảng trống, tức has_gap là TRUE, sẽ tăng group lên một (Phần 12.4.2):
Một cách tiếp cận khác để tạo biến nhóm là consecutive_id(), bắt đầu một nhóm mới mỗi khi một trong các argument của nó thay đổi. Ví dụ, lấy cảm hứng từ câu hỏi stackoverflow này, hãy tưởng tượng bạn có một data frame với nhiều giá trị iterate lại:
Nếu bạn muốn giữ row đầu tiên từ mỗi nhóm x iterate lại, bạn có thể sử dụng group_by(), consecutive_id(), và slice_head():
df |>
group_by(id = consecutive_id(x)) |>
slice_head(n = 1)
#> # A tibble: 7 × 3
#> # Groups: id [7]
#> x y id
#> <chr> <dbl> <int>
#> 1 a 1 1
#> 2 b 2 2
#> 3 c 4 3
#> 4 d 3 4
#> 5 e 9 5
#> 6 a 4 6
#> # ℹ 1 more row13.5.4 Bài tập
Tìm 10 chuyến bay bị trễ nhiều nhất bằng một function xếp hạng. Bạn muốn xử lý các giá trị bằng nhau như thế nào? Đọc kỹ tài liệu hướng dẫn cho
min_rank().Máy bay nào (
tailnum) có hồ sơ đúng giờ tệ nhất?Bạn nên bay vào thời điểm nào trong ngày nếu muốn tránh trễ nhiều nhất có thể?
flights |> group_by(dest) |> filter(row_number() < 4)làm gì?flights |> group_by(dest) |> filter(row_number(dep_delay) < 4)làm gì?Với mỗi điểm đến, tính tổng số phút trễ. Với mỗi chuyến bay, tính tỷ lệ trễ so với tổng số trễ của điểm đến.
-
Độ trễ thường có tương quan theo thời gian: ngay cả khi vấn đề gây ra độ trễ ban đầu đã được giải quyết, các chuyến bay sau vẫn bị trễ để cho phép các chuyến bay trước khởi hành. Sử dụng
lag(), khám phá mối quan hệ giữa độ trễ trung bình của chuyến bay trong một giờ với độ trễ trung bình của giờ trước đó. Xem xét từng điểm đến. Bạn có thể tìm các chuyến bay nhanh đáng ngờ (tức là các chuyến bay có thể là lỗi nhập dữ liệu) không? Tính thời gian bay của một chuyến bay so với chuyến bay ngắn nhất đến điểm đến đó. Chuyến bay nào bị trễ nhiều nhất trên không?
Tìm tất cả các điểm đến được phục vụ bởi ít nhất hai hãng bay. Sử dụng các điểm đến đó để xếp hạng tương đối các hãng bay dựa trên hiệu suất của chúng cho cùng một điểm đến.
13.6 Tóm tắt số liệu
Chỉ với phép đếm, trung bình và tổng mà chúng ta đã giới thiệu, bạn có thể đi được rất xa, nhưng R cung cấp nhiều function tóm tắt hữu ích khác. Đây là một số function bạn có thể thấy hữu ích.
13.6.1 Trung tâm
Cho đến nay, chúng ta chủ yếu sử dụng mean() để tóm tắt trung tâm của một vector giá trị. Như chúng ta đã thấy trong Phần 3.6, vì trung bình (mean) là tổng chia cho số lượng, nó nhạy cảm với chỉ một vài giá trị cao hoặc thấp bất thường. Một lựa chọn thay thế là sử dụng median(), tìm giá trị nằm ở “giữa” vector, tức là 50% giá trị nằm trên nó và 50% nằm dưới nó. Tùy thuộc vào hình dạng phân phối (distribution) của biến bạn quan tâm, trung bình hoặc trung vị (median) có thể là thước đo trung tâm tốt hơn. Ví dụ, với phân phối đối xứng chúng ta thường báo cáo trung bình, trong khi với phân phối lệch chúng ta thường báo cáo trung vị.
Hình 13.2 so sánh trung bình với trung vị của độ trễ khởi hành (tính bằng phút) cho mỗi điểm đến. Trung vị trễ luôn nhỏ hơn trung bình trễ vì các chuyến bay đôi khi khởi hành trễ nhiều giờ, nhưng không bao giờ khởi hành sớm nhiều giờ.
flights |>
group_by(year, month, day) |>
summarize(
mean = mean(dep_delay, na.rm = TRUE),
median = median(dep_delay, na.rm = TRUE),
n = n(),
.groups = "drop"
) |>
ggplot(aes(x = mean, y = median)) +
geom_abline(slope = 1, intercept = 0, color = "white", linewidth = 2) +
geom_point()![Tất cả các điểm nằm dưới đường 45°, nghĩa là trung vị trễ luôn nhỏ hơn trung bình trễ. Hầu hết các điểm tập trung trong một vùng dày đặc với trung bình [0, 20] và trung vị [-5, 5]. Khi trung bình trễ tăng, độ phân tán của trung vị cũng tăng. Có hai điểm ngoại lai với trung bình ~60, trung vị ~30, và trung bình ~85, trung vị ~55.](numbers_files/figure-html/fig-mean-vs-median-1.png)
Bạn cũng có thể thắc mắc về yếu vị (mode), hay giá trị phổ biến nhất. Đây là một thống kê tóm tắt chỉ hoạt động tốt cho các trường hợp rất đơn giản (đó là lý do bạn có thể đã học về nó ở trường phổ thông), nhưng nó không hoạt động tốt cho nhiều tập dữ liệu thực. Nếu dữ liệu là rời rạc, có thể có nhiều giá trị phổ biến nhất, và nếu dữ liệu là liên tục, có thể không có giá trị phổ biến nhất vì mỗi giá trị hơi khác nhau một chút. Vì những lý do này, yếu vị ít được các nhà thống kê sử dụng và không có function tính yếu vị trong R cơ sở2.
13.6.2 Giá trị nhỏ nhất, lớn nhất, và phân vị
Nếu bạn quan tâm đến các vị trí khác ngoài trung tâm thì sao? min() và max() sẽ cho bạn giá trị lớn nhất và nhỏ nhất. Một công cụ mạnh mẽ khác là quantile() đây là dạng tổng quát của trung vị: quantile(x, 0.25) sẽ tìm giá trị của x lớn hơn 25% các giá trị, quantile(x, 0.5) tương đương với trung vị, và quantile(x, 0.95) sẽ tìm giá trị lớn hơn 95% các giá trị.
Với tập dữ liệu flights, bạn có thể muốn xem phân vị (quantile) 95% của độ trễ thay vì giá trị lớn nhất, vì nó sẽ bỏ qua 5% chuyến bay trễ nhất vốn có thể khá cực đoan.
flights |>
group_by(year, month, day) |>
summarize(
max = max(dep_delay, na.rm = TRUE),
q95 = quantile(dep_delay, 0.95, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day max q95
#> <int> <int> <int> <dbl> <dbl>
#> 1 2013 1 1 853 70.1
#> 2 2013 1 2 379 85
#> 3 2013 1 3 291 68
#> 4 2013 1 4 288 60
#> 5 2013 1 5 327 41
#> 6 2013 1 6 202 51
#> # ℹ 359 more rows13.6.3 Độ phân tán
Đôi khi bạn không quan tâm lắm đến vị trí phần lớn dữ liệu nằm ở đâu, mà quan tâm đến dữ liệu phân tán như thế nào. Hai thống kê tóm tắt thường dùng là độ lệch chuẩn (standard deviation), sd(x), và khoảng tứ phân vị (inter-quartile range), IQR(). Chúng ta sẽ không giải thích sd() ở đây vì bạn có lẽ đã quen thuộc với nó, nhưng IQR() có thể là mới — nó là quantile(x, 0.75) - quantile(x, 0.25) và cho bạn khoảng chứa 50% dữ liệu ở giữa.
Chúng ta có thể dùng điều này để phát hiện một điểm kỳ lạ nhỏ trong dữ liệu flights. Bạn có thể kỳ vọng rằng độ phân tán của khoảng cách giữa điểm xuất phát và điểm đến bằng không, vì sân bay luôn ở cùng một chỗ. Nhưng đoạn mã dưới đây tiết lộ một điểm bất thường trong dữ liệu cho sân bay EGE:
13.6.4 Phân phối
Đáng nhớ rằng tất cả các thống kê tóm tắt mô tả ở trên là cách rút gọn phân phối xuống một con số duy nhất. Điều này có nghĩa là chúng về cơ bản mang tính rút gọn, và nếu bạn chọn sai thống kê tóm tắt, bạn có thể dễ dàng bỏ lỡ những khác biệt quan trọng giữa các nhóm. Đó là lý do tại sao luôn nên visualization phân phối trước khi quyết định chọn thống kê tóm tắt.
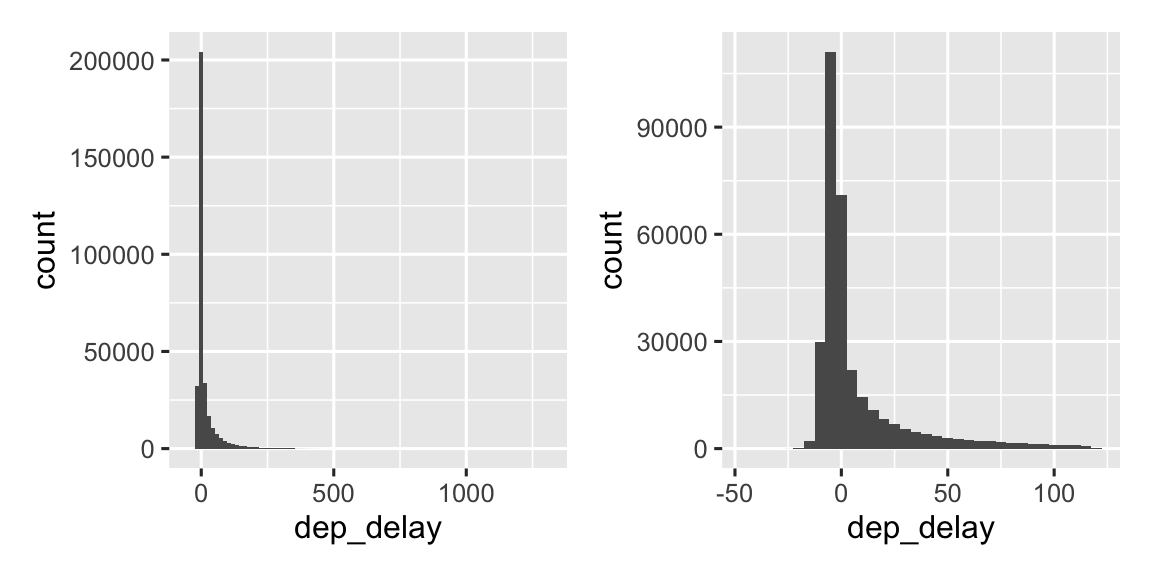
Hình 13.3 cho thấy phân phối tổng thể của độ trễ khởi hành. Phân phối lệch đến mức chúng ta phải phóng to để thấy phần lớn dữ liệu. Điều này gợi ý rằng trung bình khó có thể là thống kê tóm tắt tốt và chúng ta có thể nên dùng trung vị thay thế.
Cũng nên kiểm tra xem phân phối của các nhóm con có giống với toàn thể không. Trong biểu đồ sau, 365 đa giác tần suất (frequency polygon) của dep_delay, mỗi cái cho một ngày, được chồng lên nhau. Các phân phối dường như tuân theo một mẫu hình chung, gợi ý rằng việc sử dụng cùng một thống kê tóm tắt cho mỗi ngày là hợp lý.
flights |>
filter(dep_delay < 120) |>
ggplot(aes(x = dep_delay, group = interaction(day, month))) +
geom_freqpoly(binwidth = 5, alpha = 1/5)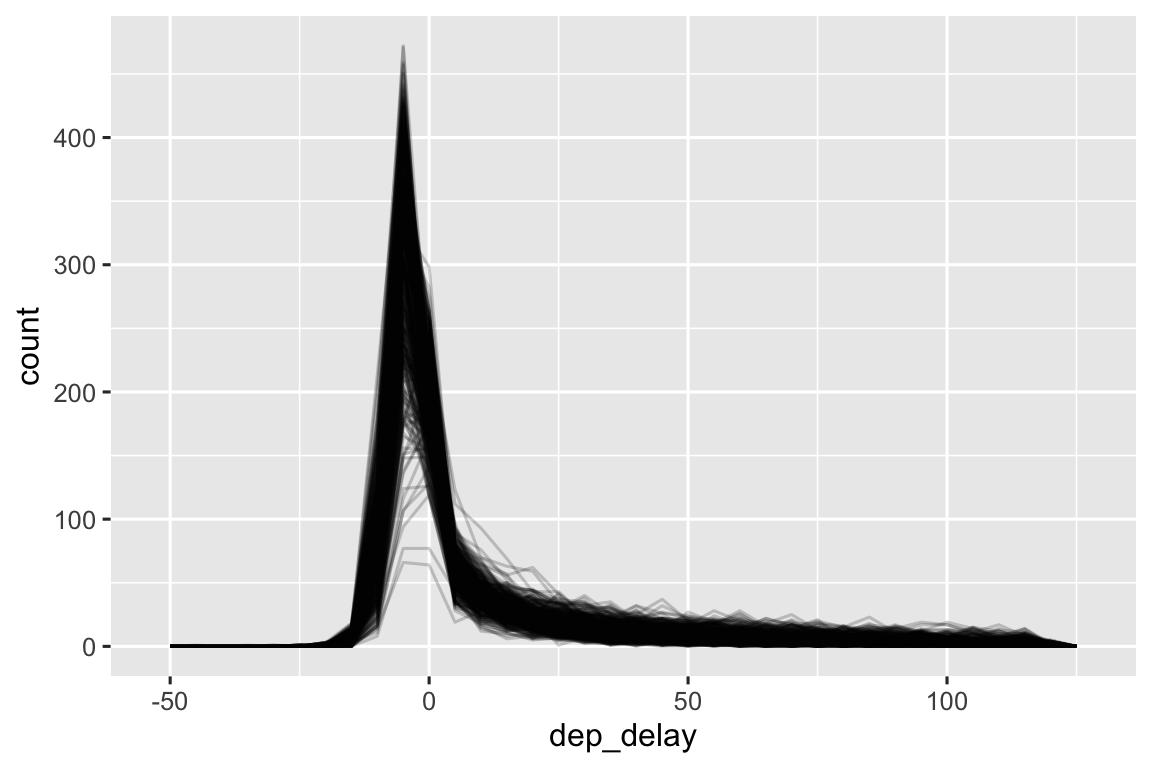
Đừng ngại khám phá các thống kê tóm tắt tùy chỉnh của riêng bạn được thiết kế đặc biệt cho dữ liệu mà bạn đang làm việc. Trong trường hợp này, điều đó có thể có nghĩa là tóm tắt riêng các chuyến bay khởi hành sớm so với các chuyến bay khởi hành muộn, hoặc vì các giá trị bị lệch nặng, bạn có thể thử phép biến đổi logarit. Cuối cùng, đừng quên những gì bạn đã học trong Phần 3.6: mỗi khi tạo các thống kê tóm tắt số, nên bao gồm số lượng quan sát trong mỗi nhóm.
13.6.5 Vị trí
Có một loại thống kê tóm tắt cuối cùng hữu ích cho vector số, nhưng cũng hoạt động với mọi loại giá trị khác: trích xuất giá trị tại một vị trí cụ thể: first(x), last(x), và nth(x, n).
Ví dụ, chúng ta có thể tìm chuyến bay đầu tiên, thứ năm và cuối cùng khởi hành mỗi ngày:
flights |>
group_by(year, month, day) |>
summarize(
first_dep = first(dep_time, na_rm = TRUE),
fifth_dep = nth(dep_time, 5, na_rm = TRUE),
last_dep = last(dep_time, na_rm = TRUE)
)
#> `summarise()` has regrouped the output.
#> ℹ Summaries were computed grouped by year, month, and day.
#> ℹ Output is grouped by year and month.
#> ℹ Use `summarise(.groups = "drop_last")` to silence this message.
#> ℹ Use `summarise(.by = c(year, month, day))` for per-operation grouping
#> (`?dplyr::dplyr_by`) instead.
#> # A tibble: 365 × 6
#> # Groups: year, month [12]
#> year month day first_dep fifth_dep last_dep
#> <int> <int> <int> <int> <int> <int>
#> 1 2013 1 1 517 554 2356
#> 2 2013 1 2 42 535 2354
#> 3 2013 1 3 32 520 2349
#> 4 2013 1 4 25 531 2358
#> 5 2013 1 5 14 534 2357
#> 6 2013 1 6 16 555 2355
#> # ℹ 359 more rows(Lưu ý: Vì các function dplyr sử dụng _ để phân tách các thành phần của tên function và argument, các function này sử dụng na_rm thay vì na.rm.)
Nếu bạn đã quen với [, mà chúng ta sẽ quay lại trong Phần 27.2, bạn có thể thắc mắc liệu có bao giờ cần các function này không. Có ba lý do: argument default cho phép bạn cung cấp giá trị mặc định nếu vị trí chỉ định không tồn tại, argument order_by cho phép bạn ghi đè cục bộ thứ tự các row, và argument na_rm cho phép bạn loại bỏ các missing value.
Trích xuất giá trị tại các vị trí bổ sung cho việc lọc theo xếp hạng. Lọc cho bạn tất cả các biến, với mỗi quan sát trên một row riêng:
flights |>
group_by(year, month, day) |>
mutate(r = min_rank(sched_dep_time)) |>
filter(r %in% c(1, max(r)))
#> # A tibble: 1,195 × 20
#> # Groups: year, month, day [365]
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 2353 2359 -6 425 445
#> 3 2013 1 1 2353 2359 -6 418 442
#> 4 2013 1 1 2356 2359 -3 425 437
#> 5 2013 1 2 42 2359 43 518 442
#> 6 2013 1 2 458 500 -2 703 650
#> # ℹ 1,189 more rows
#> # ℹ 12 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …
13.6.6 Với mutate()
Như tên gọi gợi ý, các function tóm tắt thường được ghép đôi với summarize(). Tuy nhiên, nhờ quy tắc tái chế mà chúng ta đã thảo luận trong Phần 13.4.1, chúng cũng có thể được ghép hữu ích với mutate(), đặc biệt khi bạn muốn thực hiện một dạng chuẩn hóa theo nhóm nào đó. Ví dụ:
-
x / sum(x)tính tỷ lệ so với tổng. -
(x - mean(x)) / sd(x)tính điểm Z (chuẩn hóa về trung bình 0 và độ lệch chuẩn 1). -
(x - min(x)) / (max(x) - min(x))chuẩn hóa về khoảng [0, 1]. -
x / first(x)tính chỉ số dựa trên quan sát đầu tiên.
13.6.7 Bài tập
Nghĩ ra ít nhất 5 cách khác nhau để đánh giá đặc tính trễ điển hình của một nhóm chuyến bay. Khi nào
mean()hữu ích? Khi nàomedian()hữu ích? Khi nào bạn có thể muốn sử dụng thứ khác? Bạn nên dùng độ trễ đến hay độ trễ khởi hành? Tại sao bạn có thể muốn sử dụng dữ liệu từplanes?Điểm đến nào cho thấy sự biến thiên lớn nhất về tốc độ bay?
Tạo một biểu đồ để khám phá thêm câu chuyện của EGE. Bạn có thể tìm bằng chứng nào cho thấy sân bay đã thay đổi vị trí không? Bạn có thể tìm biến nào khác có thể giải thích sự khác biệt không?
13.7 Tổng kết
Bạn đã quen thuộc với nhiều công cụ để làm việc với số, và sau khi đọc chương này bạn giờ đã biết cách sử dụng chúng trong R. Bạn cũng đã học được một số phép biến đổi tổng quát hữu ích thường được, nhưng không chỉ, áp dụng cho vector số như xếp hạng và độ lệch. Cuối cùng, bạn đã đi qua một số thống kê tóm tắt số và thảo luận về một vài thách thức thống kê mà bạn nên cân nhắc.
Trong hai chương tiếp theo, chúng ta sẽ đi sâu vào làm việc với string bằng package stringr. Chuỗi ký tự là một theme lớn nên chúng được dành hai chương, một về nền tảng của string và một về regular expression.
ggplot2 cung cấp một số function hỗ trợ cho các trường hợp phổ biến trong
cut_interval(),cut_number(), vàcut_width(). ggplot2 là một nơi kỳ lạ để các function này tồn tại, nhưng chúng hữu ích như một phần của việc tính toán biểu đồ tần suất và được viết trước khi bất kỳ phần nào khác của tidyverse ra đời.↩︎