19 Nối bảng
19.1 Giới thiệu
Rất hiếm khi một phân tích dữ liệu chỉ liên quan đến một data frame duy nhất. Thông thường bạn có nhiều data frame, và bạn phải nối (join) chúng lại với nhau để trả lời các câu hỏi mà bạn quan tâm. Chương này sẽ giới thiệu cho bạn hai loại nối quan trọng:
- Nối biến đổi (mutating join), thêm các biến mới vào một data frame từ các quan sát khớp trong một data frame khác.
- Nối lọc (filtering join), lọc các quan sát từ một data frame dựa trên việc chúng có khớp hay không với một quan sát trong data frame khác.
Chúng ta sẽ bắt đầu bằng việc thảo luận về khóa (key), các biến được sử dụng để kết nối một cặp data frame trong một phép nối. Chúng ta củng cố lý thuyết bằng cách kiểm tra các khóa trong các tập dữ liệu từ package nycflights13, sau đó sử dụng kiến thức đó để bắt đầu nối các data frame lại với nhau. Tiếp theo chúng ta sẽ thảo luận về cách các phép nối hoạt động, tập trung vào tác động của chúng lên các row. Chúng ta sẽ kết thúc với một cuộc thảo luận về nối không đẳng thức (non-equi join), một họ các phép nối cung cấp cách khớp khóa linh hoạt hơn so với quan hệ bằng mặc định.
19.1.1 Điều kiện tiên quyết
Trong chương này, chúng ta sẽ khám phá năm tập dữ liệu liên quan từ nycflights13 sử dụng các function nối từ dplyr.
19.2 Khóa
Để hiểu các phép nối, trước tiên bạn cần hiểu cách hai bảng có thể được kết nối thông qua một cặp khóa, trong mỗi bảng. Trong phần này, bạn sẽ tìm hiểu về hai loại khóa và xem các ví dụ về cả hai trong các tập dữ liệu của package nycflights13. Bạn cũng sẽ học cách kiểm tra rằng các khóa của bạn hợp lệ, và phải làm gì khi bảng của bạn thiếu khóa.
19.2.1 Khóa chính và khóa ngoại
Mỗi phép nối đều liên quan đến một cặp khóa: một khóa chính (primary key) và một khóa ngoại (foreign key). Khóa chính là một biến hoặc tập hợp các biến xác định duy nhất mỗi quan sát. Khi cần nhiều hơn một biến, khóa được gọi là khóa phức hợp (compound key). Ví dụ, trong nycflights13:
-
airlinesghi lại hai phần dữ liệu về mỗi hãng row không: mã hãng vận chuyển và tên đầy đủ. Bạn có thể xác định một hãng row không bằng mã hãng vận chuyển hai chữ cái, làm chocarriertrở thành khóa chính.airlines #> # A tibble: 16 × 2 #> carrier name #> <chr> <chr> #> 1 9E Endeavor Air Inc. #> 2 AA American Airlines Inc. #> 3 AS Alaska Airlines Inc. #> 4 B6 JetBlue Airways #> 5 DL Delta Air Lines Inc. #> 6 EV ExpressJet Airlines Inc. #> # ℹ 10 more rows -
airportsghi lại dữ liệu về mỗi sân bay. Bạn có thể xác định mỗi sân bay bằng mã sân bay ba chữ cái, làm chofaatrở thành khóa chính.airports #> # A tibble: 1,458 × 8 #> faa name lat lon alt tz dst #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> #> 1 04G Lansdowne Airport 41.1 -80.6 1044 -5 A #> 2 06A Moton Field Municipal Airport 32.5 -85.7 264 -6 A #> 3 06C Schaumburg Regional 42.0 -88.1 801 -6 A #> 4 06N Randall Airport 41.4 -74.4 523 -5 A #> 5 09J Jekyll Island Airport 31.1 -81.4 11 -5 A #> 6 0A9 Elizabethton Municipal Airpo… 36.4 -82.2 1593 -5 A #> # ℹ 1,452 more rows #> # ℹ 1 more variable: tzone <chr> -
planesghi lại dữ liệu về mỗi máy bay. Bạn có thể xác định một máy bay bằng số đuôi của nó, làm chotailnumtrở thành khóa chính.planes #> # A tibble: 3,322 × 9 #> tailnum year type manufacturer model engines #> <chr> <int> <chr> <chr> <chr> <int> #> 1 N10156 2004 Fixed wing multi… EMBRAER EMB-145XR 2 #> 2 N102UW 1998 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> 3 N103US 1999 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> 4 N104UW 1999 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> 5 N10575 2002 Fixed wing multi… EMBRAER EMB-145LR 2 #> 6 N105UW 1999 Fixed wing multi… AIRBUS INDUSTR… A320-214 2 #> # ℹ 3,316 more rows #> # ℹ 3 more variables: seats <int>, speed <int>, engine <chr> -
weatherghi lại dữ liệu về thời tiết tại các sân bay xuất phát. Bạn có thể xác định mỗi quan sát bằng tổ hợp vị trí và thời gian, làm chooriginvàtime_hourtrở thành khóa chính phức hợp.weather #> # A tibble: 26,115 × 15 #> origin year month day hour temp dewp humid wind_dir #> <chr> <int> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> #> 1 EWR 2013 1 1 1 39.0 26.1 59.4 270 #> 2 EWR 2013 1 1 2 39.0 27.0 61.6 250 #> 3 EWR 2013 1 1 3 39.0 28.0 64.4 240 #> 4 EWR 2013 1 1 4 39.9 28.0 62.2 250 #> 5 EWR 2013 1 1 5 39.0 28.0 64.4 260 #> 6 EWR 2013 1 1 6 37.9 28.0 67.2 240 #> # ℹ 26,109 more rows #> # ℹ 6 more variables: wind_speed <dbl>, wind_gust <dbl>, …
Khóa ngoại là một biến (hoặc tập hợp các biến) tương ứng với khóa chính trong một bảng khác. Ví dụ:
-
flights$tailnumlà khóa ngoại tương ứng với khóa chínhplanes$tailnum. -
flights$carrierlà khóa ngoại tương ứng với khóa chínhairlines$carrier. -
flights$originlà khóa ngoại tương ứng với khóa chínhairports$faa. -
flights$destlà khóa ngoại tương ứng với khóa chínhairports$faa. -
flights$origin-flights$time_hourlà khóa ngoại phức hợp tương ứng với khóa chính phức hợpweather$origin-weather$time_hour.
Các mối quan hệ này được tóm tắt trực quan trong Hình 19.1.
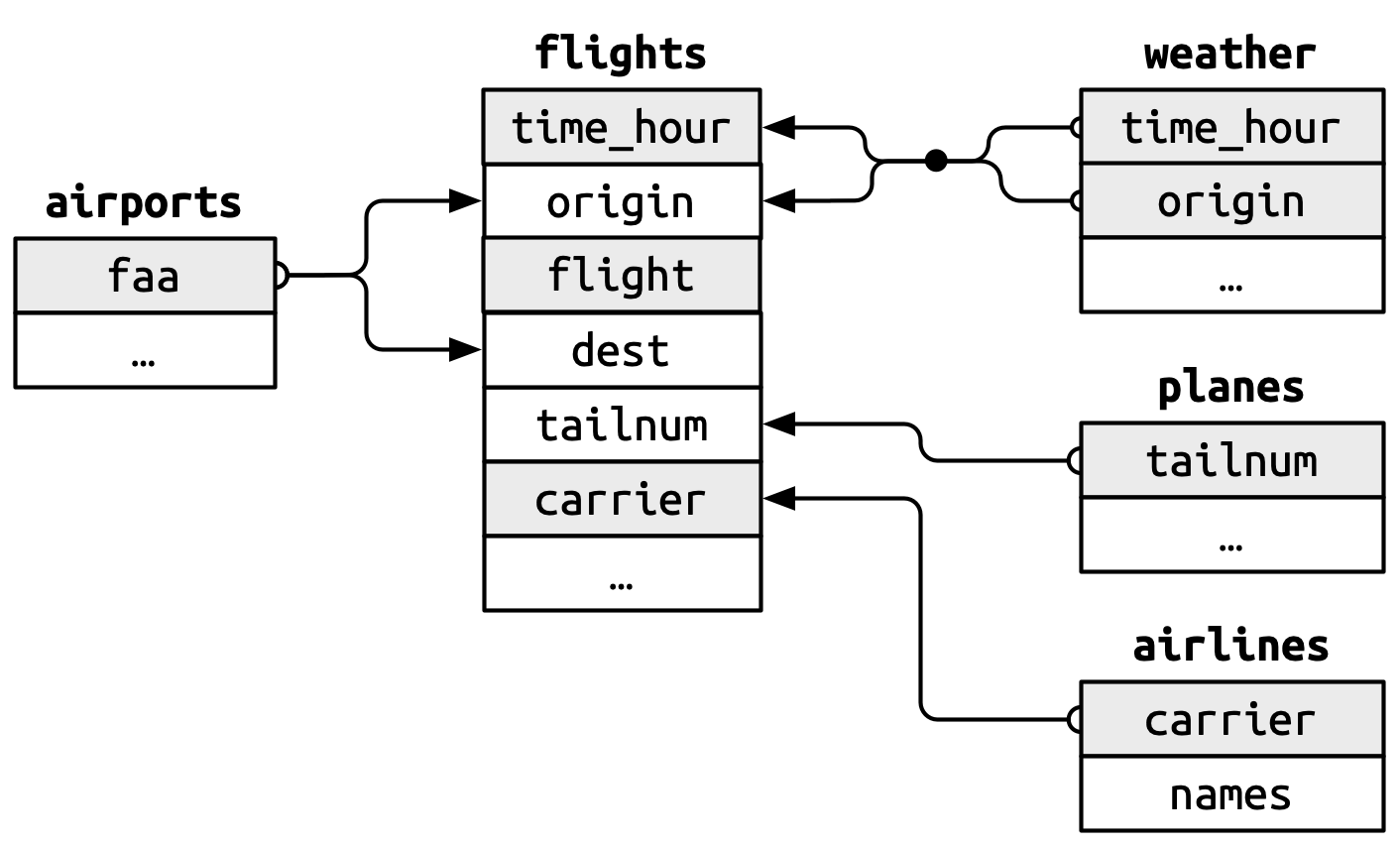
Bạn sẽ nhận thấy một đặc điểm hay trong thiết kế của các khóa này: khóa chính và khóa ngoại hầu như luôn có cùng tên, điều này, như bạn sẽ thấy ngay, sẽ giúp việc nối bảng của bạn dễ dàng hơn nhiều. Cũng đáng lưu ý mối quan hệ ngược lại: hầu hết mọi tên biến được sử dụng trong nhiều bảng đều có cùng ý nghĩa ở mỗi nơi. Chỉ có một ngoại lệ: year có nghĩa là năm khởi hành trong flights và năm sản xuất trong planes. Điều này sẽ trở nên quan trọng khi chúng ta bắt đầu thực sự nối các bảng lại với nhau.
19.2.2 Kiểm tra khóa chính
Bây giờ chúng ta đã xác định được các khóa chính trong mỗi bảng, việc xác minh rằng chúng thực sự xác định duy nhất mỗi quan sát là một thực hành tốt. Một cách để làm điều đó là count() các khóa chính và tìm các mục có n lớn hơn một. Điều này cho thấy planes và weather đều ổn:
Bạn cũng nên kiểm tra missing value (missing value) trong các khóa chính — nếu một giá trị bị khuyết thì nó không thể xác định một quan sát!
planes |>
filter(is.na(tailnum))
#> # A tibble: 0 × 9
#> # ℹ 9 variables: tailnum <chr>, year <int>, type <chr>, manufacturer <chr>,
#> # model <chr>, engines <int>, seats <int>, speed <int>, engine <chr>
weather |>
filter(is.na(time_hour) | is.na(origin))
#> # A tibble: 0 × 15
#> # ℹ 15 variables: origin <chr>, year <int>, month <int>, day <int>,
#> # hour <int>, temp <dbl>, dewp <dbl>, humid <dbl>, wind_dir <dbl>, …19.2.3 Khóa thay thế
Cho đến giờ chúng ta chưa nói về khóa chính cho flights. Điều đó không quá quan trọng ở đây, vì không có data frame nào sử dụng nó làm khóa ngoại, nhưng vẫn hữu ích để xem xét vì sẽ dễ làm việc với các quan sát hơn nếu chúng ta có cách nào đó để mô tả chúng cho người khác.
Sau một chút suy nghĩ và thử nghiệm, chúng tôi xác định rằng có ba biến cùng nhau xác định duy nhất mỗi chuyến bay:
Việc không có giá trị trùng iterate có tự động làm cho time_hour-carrier-flight trở thành khóa chính không? Đó chắc chắn là một khởi đầu tốt, nhưng nó không đảm bảo điều đó. Ví dụ, liệu độ cao và vĩ độ có phải là khóa chính tốt cho airports không?
Xác định một sân bay bằng độ cao và vĩ độ rõ ràng là một ý tưởng tồi, và nói chung không thể chỉ từ dữ liệu mà biết được liệu một tổ hợp biến có tạo thành một khóa chính tốt hay không. Nhưng đối với các chuyến bay, tổ hợp time_hour, carrier, và flight có vẻ hợp lý vì sẽ rất khó hiểu nếu một hãng row không và hành khách của họ có nhiều chuyến bay cùng số hiệu bay trên không cùng một lúc.
Tuy nhiên, chúng ta có thể sẽ tốt hơn nếu tạo một khóa thay thế (surrogate key) số đơn giản sử dụng số thứ tự row:
flights2 <- flights |>
mutate(id = row_number(), .before = 1)
flights2
#> # A tibble: 336,776 × 20
#> id year month day dep_time sched_dep_time dep_delay arr_time
#> <int> <int> <int> <int> <int> <int> <dbl> <int>
#> 1 1 2013 1 1 517 515 2 830
#> 2 2 2013 1 1 533 529 4 850
#> 3 3 2013 1 1 542 540 2 923
#> 4 4 2013 1 1 544 545 -1 1004
#> 5 5 2013 1 1 554 600 -6 812
#> 6 6 2013 1 1 554 558 -4 740
#> # ℹ 336,770 more rows
#> # ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>, …Khóa thay thế có thể đặc biệt hữu ích khi giao tiếp với người khác: nói với ai đó hãy xem chuyến bay 2001 dễ hơn nhiều so với nói hãy xem UA430 khởi hành lúc 9 giờ sáng ngày 2013-01-03.
19.2.4 Bài tập
Chúng ta quên vẽ mối quan hệ giữa
weathervàairportstrong Hình 19.1. Mối quan hệ đó là gì và nó nên xuất hiện như thế nào trong sơ đồ?weatherchỉ chứa thông tin cho ba sân bay xuất phát ở NYC. Nếu nó chứa bản ghi thời tiết cho tất cả các sân bay ở Mỹ, nó sẽ tạo thêm kết nối nào đếnflights?Các biến
year,month,day,hour, vàorigingần như tạo thành một khóa phức hợp choweather, nhưng có một giờ có các quan sát trùng iterate. Bạn có thể tìm ra điều gì đặc biệt về giờ đó không?Chúng ta biết rằng một số ngày trong năm là đặc biệt và ít người bay hơn bình thường (ví dụ, đêm Giáng sinh và ngày Giáng sinh). Bạn có thể biểu diễn dữ liệu đó dưới dạng data frame như thế nào? Khóa chính sẽ là gì? Nó sẽ kết nối với các data frame hiện có như thế nào?
Vẽ một sơ đồ minh họa các kết nối giữa các data frame
Batting,People, vàSalariestrong package Lahman. Vẽ một sơ đồ khác cho thấy mối quan hệ giữaPeople,Managers,AwardsManagers. Bạn sẽ mô tả mối quan hệ giữa các data frameBatting,Pitching, vàFieldingnhư thế nào?
19.3 Nối cơ bản
Bây giờ bạn đã hiểu cách các data frame được kết nối thông qua khóa, chúng ta có thể bắt đầu sử dụng các phép nối để hiểu rõ hơn tập dữ liệu flights. dplyr cung cấp sáu function nối: left_join(), inner_join(), right_join(), full_join(), semi_join(), và anti_join(). Tất cả đều có cùng giao diện: chúng nhận một cặp data frame (x và y) và trả về một data frame. Thứ tự của các row và column trong kết quả đầu ra chủ yếu được xác định bởi x.
Trong phần này, bạn sẽ học cách sử dụng một phép nối biến đổi, left_join(), và hai phép nối lọc, semi_join() và anti_join(). Trong phần tiếp theo, bạn sẽ học chính xác cách các function này hoạt động, và về các function còn lại inner_join(), right_join() và full_join().
19.3.1 Nối biến đổi
Một nối biến đổi cho phép bạn kết hợp các biến từ hai data frame: nó trước tiên khớp các quan sát theo khóa của chúng, sau đó sao chép các biến từ data frame này sang data frame kia. Giống như mutate(), các function nối thêm biến vào bên phải, nên nếu tập dữ liệu của bạn có nhiều biến, bạn sẽ không thấy các biến mới. Cho các ví dụ này, chúng ta sẽ tạo ra một tập dữ liệu hẹp hơn chỉ với sáu biến để dễ quan sát hơn1:
flights2 <- flights |>
select(year, time_hour, origin, dest, tailnum, carrier)
flights2
#> # A tibble: 336,776 × 6
#> year time_hour origin dest tailnum carrier
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rowsCó bốn loại nối biến đổi, nhưng có một loại bạn sẽ dùng hầu như mọi lúc: left_join(). Nó đặc biệt vì đầu ra sẽ luôn có cùng số row với x, data frame mà bạn đang nối vào2. Công dụng chính của left_join() là bổ sung thêm siêu dữ liệu (metadata). Ví dụ, chúng ta có thể sử dụng left_join() để thêm tên đầy đủ của hãng row không vào dữ liệu flights2:
flights2 |>
left_join(airlines)
#> Joining with `by = join_by(carrier)`
#> # A tibble: 336,776 × 7
#> year time_hour origin dest tailnum carrier name
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air Lines In…
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air Lines In…
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Airlines I…
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Airways
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air Lines Inc.
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air Lines In…
#> # ℹ 336,770 more rowsHoặc chúng ta có thể tìm nhiệt độ và tốc độ gió khi mỗi máy bay khởi hành:
flights2 |>
left_join(weather |> select(origin, time_hour, temp, wind_speed))
#> Joining with `by = join_by(time_hour, origin)`
#> # A tibble: 336,776 × 8
#> year time_hour origin dest tailnum carrier temp wind_speed
#> <int> <dttm> <chr> <chr> <chr> <chr> <dbl> <dbl>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 39.0 12.7
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 39.9 15.0
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 39.0 15.0
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 39.0 15.0
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 39.9 16.1
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 39.0 12.7
#> # ℹ 336,770 more rowsHoặc kích cỡ máy bay đang bay là gì:
flights2 |>
left_join(planes |> select(tailnum, type, engines, seats))
#> Joining with `by = join_by(tailnum)`
#> # A tibble: 336,776 × 9
#> year time_hour origin dest tailnum carrier type
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Fixed wing multi en…
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA Fixed wing multi en…
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA Fixed wing multi en…
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 Fixed wing multi en…
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Fixed wing multi en…
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Fixed wing multi en…
#> # ℹ 336,770 more rows
#> # ℹ 2 more variables: engines <int>, seats <int>Khi left_join() không tìm thấy khớp cho một row trong x, nó điền missing value vào các biến mới. Ví dụ, không có thông tin về máy bay với số đuôi N3ALAA nên type, engines, và seats sẽ bị khuyết:
flights2 |>
filter(tailnum == "N3ALAA") |>
left_join(planes |> select(tailnum, type, engines, seats))
#> Joining with `by = join_by(tailnum)`
#> # A tibble: 63 × 9
#> year time_hour origin dest tailnum carrier type engines seats
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr> <int> <int>
#> 1 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 2 2013 2013-01-02 18:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 3 2013 2013-01-03 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 4 2013 2013-01-07 19:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 5 2013 2013-01-08 17:00:00 JFK ORD N3ALAA AA <NA> NA NA
#> 6 2013 2013-01-16 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> # ℹ 57 more rowsChúng ta sẽ quay lại vấn đề này vài lần trong phần còn lại của chương.
19.3.2 Chỉ định khóa nối
Theo mặc định, left_join() sẽ sử dụng tất cả các biến xuất hiện trong cả hai data frame làm khóa nối, gọi là phép nối tự nhiên (natural join). Đây là một phương pháp heuristic hữu ích, nhưng không phải lúc nào cũng hoạt động. Ví dụ, điều gì xảy ra nếu chúng ta thử nối flights2 với tập dữ liệu planes đầy đủ?
flights2 |>
left_join(planes)
#> Joining with `by = join_by(year, tailnum)`
#> # A tibble: 336,776 × 13
#> year time_hour origin dest tailnum carrier type manufacturer
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA <NA> <NA>
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA <NA> <NA>
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA <NA> <NA>
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 <NA> <NA>
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL <NA> <NA>
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA <NA> <NA>
#> # ℹ 336,770 more rows
#> # ℹ 5 more variables: model <chr>, engines <int>, seats <int>, …Chúng ta nhận được rất nhiều khớp bị thiếu vì phép nối đang cố sử dụng tailnum và year làm khóa phức hợp. Cả flights và planes đều có column year nhưng chúng có nghĩa khác nhau: flights$year là năm chuyến bay diễn ra và planes$year là năm máy bay được sản xuất. Chúng ta chỉ muốn nối theo tailnum nên cần cung cấp đặc tả rõ ràng với join_by():
flights2 |>
left_join(planes, join_by(tailnum))
#> # A tibble: 336,776 × 14
#> year.x time_hour origin dest tailnum carrier year.y
#> <int> <dttm> <chr> <chr> <chr> <chr> <int>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 1999
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 1998
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 1990
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 2012
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 1991
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 2012
#> # ℹ 336,770 more rows
#> # ℹ 7 more variables: type <chr>, manufacturer <chr>, model <chr>, …Lưu ý rằng các biến year được phân biệt trong đầu ra bằng hậu tố (year.x và year.y), cho bạn biết biến đến từ argument x hay y. Bạn có thể ghi đè hậu tố mặc định bằng argument suffix.
join_by(tailnum) là viết tắt của join_by(tailnum == tailnum). Điều quan trọng là phải biết về dạng đầy đủ hơn này vì hai lý do. Thứ nhất, nó mô tả mối quan hệ giữa hai bảng: các khóa phải bằng nhau. Đó là lý do tại sao loại nối này thường được gọi là nối đẳng thức (equi join). Bạn sẽ tìm hiểu về nối không đẳng thức trong Phần 19.5.
Thứ hai, đó là cách bạn chỉ định các khóa nối khác nhau trong mỗi bảng. Ví dụ, có hai cách để nối bảng flight2 và airports: theo dest hoặc origin:
flights2 |>
left_join(airports, join_by(dest == faa))
#> # A tibble: 336,776 × 13
#> year time_hour origin dest tailnum carrier name
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA George Bush Interco…
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA George Bush Interco…
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA Miami Intl
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 <NA>
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Hartsfield Jackson …
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Chicago Ohare Intl
#> # ℹ 336,770 more rows
#> # ℹ 6 more variables: lat <dbl>, lon <dbl>, alt <dbl>, tz <dbl>, …
flights2 |>
left_join(airports, join_by(origin == faa))
#> # A tibble: 336,776 × 13
#> year time_hour origin dest tailnum carrier name
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA Newark Liberty Intl
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA La Guardia
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA John F Kennedy Intl
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 John F Kennedy Intl
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL La Guardia
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA Newark Liberty Intl
#> # ℹ 336,770 more rows
#> # ℹ 6 more variables: lat <dbl>, lon <dbl>, alt <dbl>, tz <dbl>, …Trong code cũ hơn, bạn có thể thấy một cách khác để chỉ định khóa nối, sử dụng một vector ký tự:
-
by = "x"tương ứng vớijoin_by(x). -
by = c("a" = "x")tương ứng vớijoin_by(a == x).
Giờ đây khi đã có join_by(), chúng tôi ưu tiên sử dụng nó vì nó cung cấp đặc tả rõ ràng và linh hoạt hơn.
inner_join(), right_join(), full_join() có cùng giao diện với left_join(). Sự khác biệt là những row nào chúng giữ lại: nối trái giữ tất cả các row trong x, nối phải giữ tất cả các row trong y, nối đầy đủ giữ tất cả các row trong x hoặc y, và nối trong chỉ giữ các row xuất hiện trong cả x và y. Chúng ta sẽ quay lại chi tiết hơn ở phần sau.
19.3.3 Nối lọc
Như bạn có thể đoán, hành động chính của một nối lọc là lọc các row. Có hai loại: nối bán phần (semi-join) và nối phản (anti-join). Nối bán phần giữ tất cả các row trong x có khớp trong y. Ví dụ, chúng ta có thể sử dụng nối bán phần để lọc tập dữ liệu airports chỉ hiển thị các sân bay xuất phát:
airports |>
semi_join(flights2, join_by(faa == origin))
#> # A tibble: 3 × 8
#> faa name lat lon alt tz dst tzone
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 EWR Newark Liberty Intl 40.7 -74.2 18 -5 A America/New_York
#> 2 JFK John F Kennedy Intl 40.6 -73.8 13 -5 A America/New_York
#> 3 LGA La Guardia 40.8 -73.9 22 -5 A America/New_YorkHoặc chỉ các điểm đến:
airports |>
semi_join(flights2, join_by(faa == dest))
#> # A tibble: 101 × 8
#> faa name lat lon alt tz dst tzone
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 ABQ Albuquerque Internati… 35.0 -107. 5355 -7 A America/Denver
#> 2 ACK Nantucket Mem 41.3 -70.1 48 -5 A America/New_Yo…
#> 3 ALB Albany Intl 42.7 -73.8 285 -5 A America/New_Yo…
#> 4 ANC Ted Stevens Anchorage… 61.2 -150. 152 -9 A America/Anchor…
#> 5 ATL Hartsfield Jackson At… 33.6 -84.4 1026 -5 A America/New_Yo…
#> 6 AUS Austin Bergstrom Intl 30.2 -97.7 542 -6 A America/Chicago
#> # ℹ 95 more rowsNối phản thì ngược lại: chúng trả về tất cả các row trong x không có khớp trong y. Chúng hữu ích để tìm missing value ngầm (implicit) trong dữ liệu, theme của Phần 18.3. Giá trị khuyết ngầm không hiển thị dưới dạng NA mà chỉ tồn tại như một sự vắng mặt. Ví dụ, chúng ta có thể tìm các row bị thiếu trong airports bằng cách tìm các chuyến bay không có sân bay đích khớp:
Hoặc chúng ta có thể tìm tailnum nào bị thiếu trong planes:
19.3.4 Bài tập
Tìm 48 giờ (trong suốt cả năm) có độ trễ tệ nhất. Đối chiếu với dữ liệu
weather. Bạn có thể thấy quy luật nào không?-
Hãy tưởng tượng bạn đã tìm 10 điểm đến phổ biến nhất bằng đoạn code này:
Bạn có thể tìm tất cả chuyến bay đến các điểm đến đó bằng cách nào?
Mỗi chuyến bay khởi hành có dữ liệu thời tiết tương ứng cho giờ đó không?
Các số đuôi không có bản ghi khớp trong
planescó điểm gì chung? (Gợi ý: một biến giải thích ~90% vấn đề.)Thêm một column vào
planesliệt kê mọicarrierđã bay máy bay đó. Bạn có thể mong đợi rằng có một mối quan hệ ngầm giữa máy bay và hãng row không, vì mỗi máy bay được bay bởi một hãng duy nhất. Xác nhận hoặc bác bỏ giả thuyết này bằng các công cụ bạn đã học trong các chương trước.Thêm vĩ độ và kinh độ của sân bay xuất phát và sân bay đích vào
flights. Đổi tên các column trước hay sau phép nối dễ hơn?-
Tính độ trễ trung bình theo điểm đến, sau đó nối với data frame
airportsđể bạn có thể hiển thị phân bố không gian của các độ trễ. Đây là một cách dễ dàng để vẽ bản đồ nước Mỹ:airports |> semi_join(flights, join_by(faa == dest)) |> ggplot(aes(x = lon, y = lat)) + borders("state") + geom_point() + coord_quickmap()Bạn có thể muốn sử dụng
sizehoặccolorcủa các điểm để hiển thị độ trễ trung bình cho mỗi sân bay. Điều gì đã xảy ra vào ngày 13 tháng 6 năm 2013? Vẽ bản đồ các độ trễ, và sau đó sử dụng Google để đối chiếu với thời tiết.
19.4 Phép nối hoạt động như thế nào?
Bây giờ bạn đã sử dụng phép nối vài lần, đã đến lúc tìm hiểu thêm về cách chúng hoạt động, tập trung vào cách mỗi row trong x khớp với các row trong y. Chúng ta sẽ bắt đầu bằng cách giới thiệu một biểu diễn trực quan của các phép nối, sử dụng các tibble đơn giản được định nghĩa bên dưới và hiển thị trong Hình 19.2. Trong các ví dụ này, chúng ta sẽ sử dụng một khóa đơn gọi là key và một column giá trị đơn (val_x và val_y), nhưng các ý tưởng đều khái quát hóa được cho nhiều khóa và nhiều giá trị.
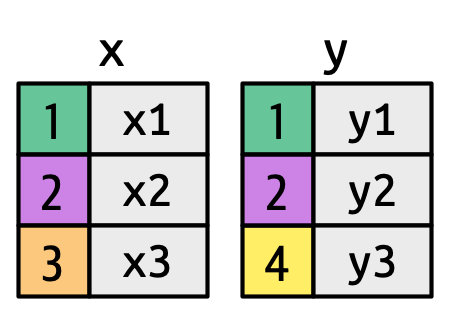
key được tô màu mapping màu nền theo giá trị khóa. Các column màu xám biểu diễn các column “giá trị” được mang theo.
Hình 19.3 giới thiệu nền tảng cho biểu diễn trực quan của chúng ta. Nó cho thấy tất cả các khớp tiềm năng giữa x và y dưới dạng giao điểm giữa các đường vẽ từ mỗi row của x và mỗi row của y. Các row và column trong đầu ra chủ yếu được xác định bởi x, nên bảng x nằm ngang và căn chỉnh với đầu ra.
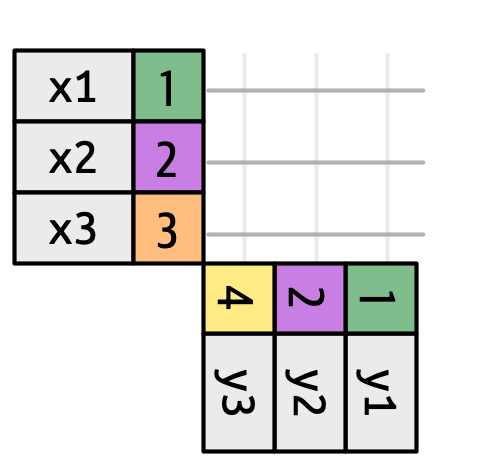
Để mô tả một loại nối cụ thể, chúng ta đánh dấu các khớp bằng chấm tròn. Các khớp xác định các row trong đầu ra, một data frame mới chứa khóa, các giá trị x, và các giá trị y. Ví dụ, Hình 19.4 hiển thị một nối trong (inner join), trong đó các row được giữ lại nếu và chỉ nếu các khóa bằng nhau.
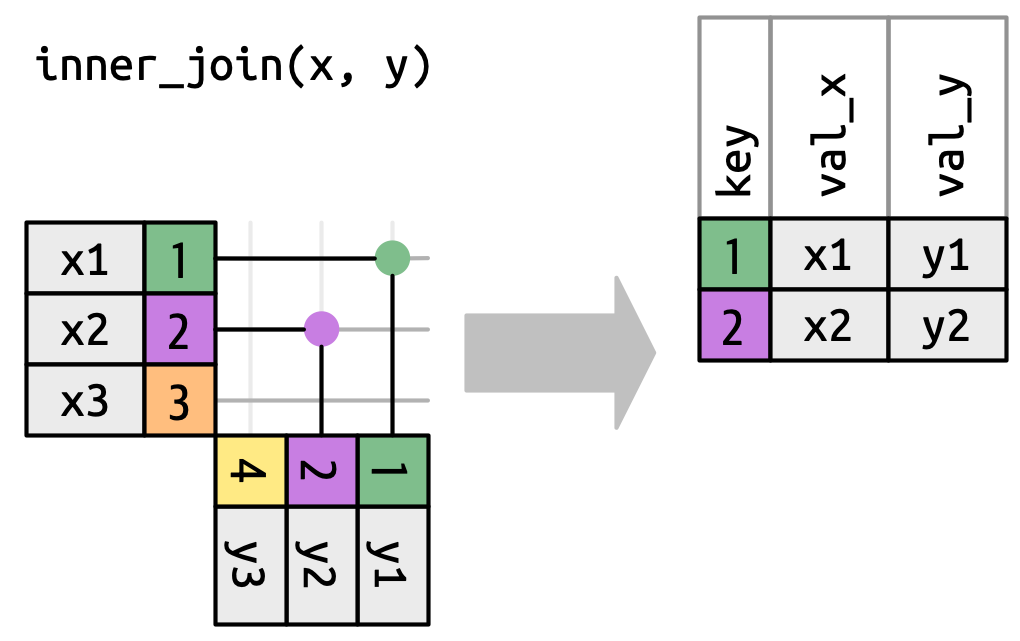
x với row trong y có cùng giá trị key. Mỗi khớp trở thành một row trong đầu ra.
Chúng ta có thể áp dụng các nguyên tắc tương tự để giải thích các nối ngoài (outer join), giữ các quan sát xuất hiện trong ít nhất một data frame. Các phép nối này hoạt động bằng cách thêm một quan sát “ảo” bổ sung vào mỗi data frame. Quan sát này có một khóa khớp nếu không có khóa nào khác khớp, và các giá trị được điền bằng NA. Có ba loại nối ngoài:
-
Một nối trái (left join) giữ tất cả các quan sát trong
x, Hình 19.5. Mỗi row củaxđược bảo toàn trong đầu ra vì nó có thể quay về khớp với một rowNAtrongy.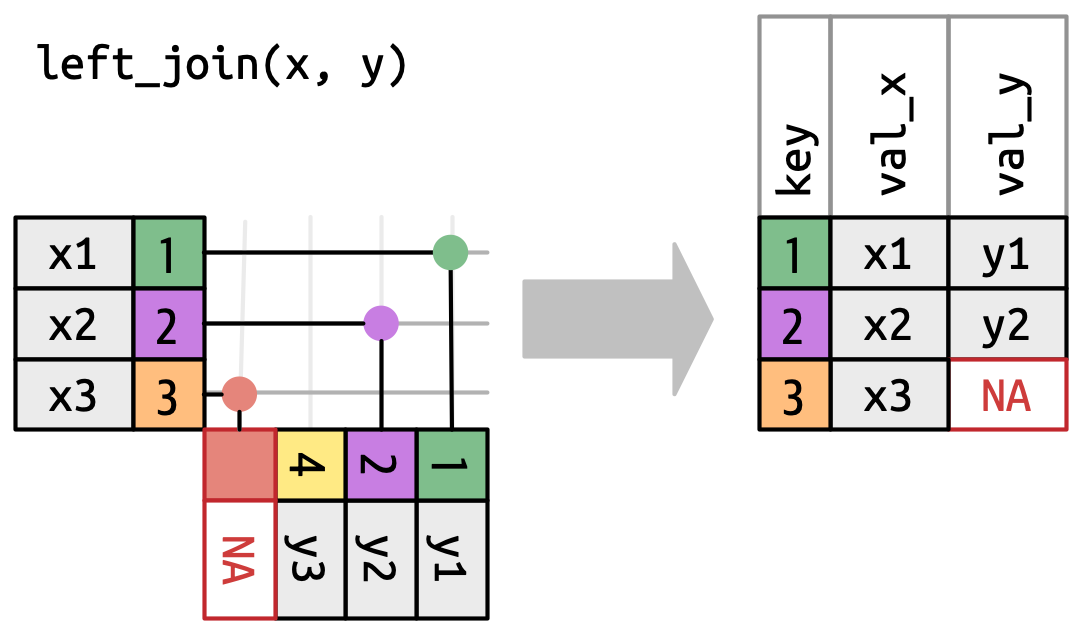
Hình 19.5: Biểu diễn trực quan của nối trái, trong đó mỗi row trong xđều xuất hiện trong đầu ra. -
Một nối phải (right join) giữ tất cả các quan sát trong
y, Hình 19.6. Mỗi row củayđược bảo toàn trong đầu ra vì nó có thể quay về khớp với một rowNAtrongx. Đầu ra vẫn khớp vớixnhiều nhất có thể; các row thừa từyđược thêm vào cuối.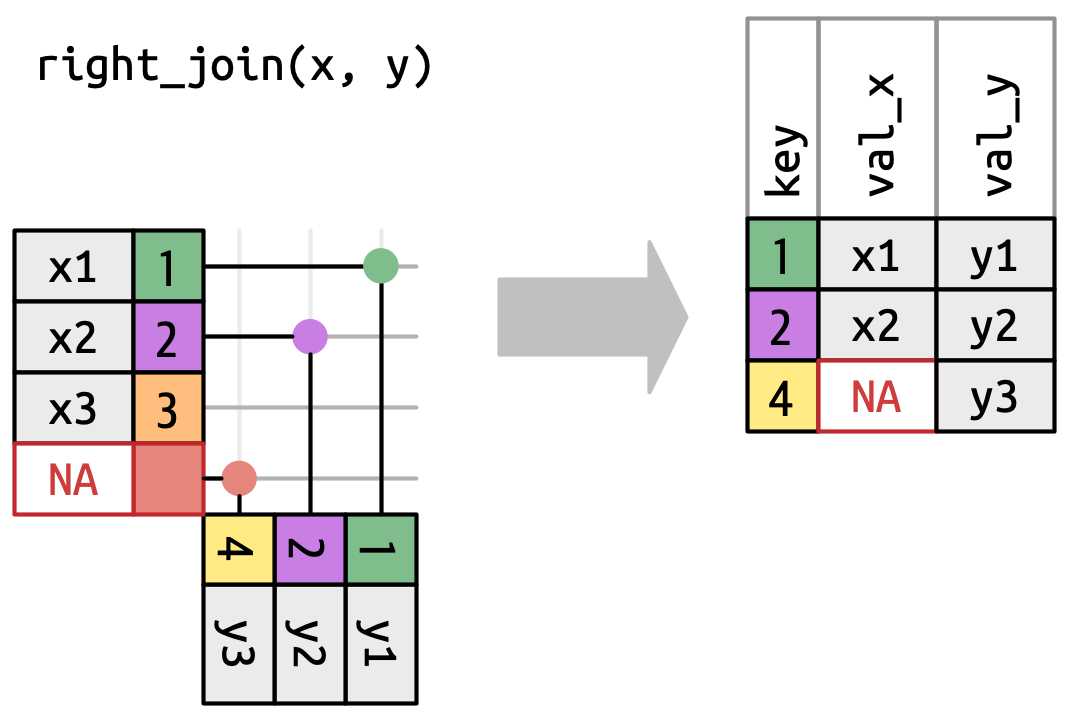
Hình 19.6: Biểu diễn trực quan của nối phải, trong đó mỗi row của yđều xuất hiện trong đầu ra. -
Một nối đầy đủ (full join) giữ tất cả các quan sát xuất hiện trong
xhoặcy, Hình 19.7. Mỗi row củaxvàyđều có trong đầu ra vì cảxvàyđều có một rowNAdự phòng. Một lần nữa, đầu ra bắt đầu với tất cả các row từx, tiếp theo là các rowychưa khớp còn lại.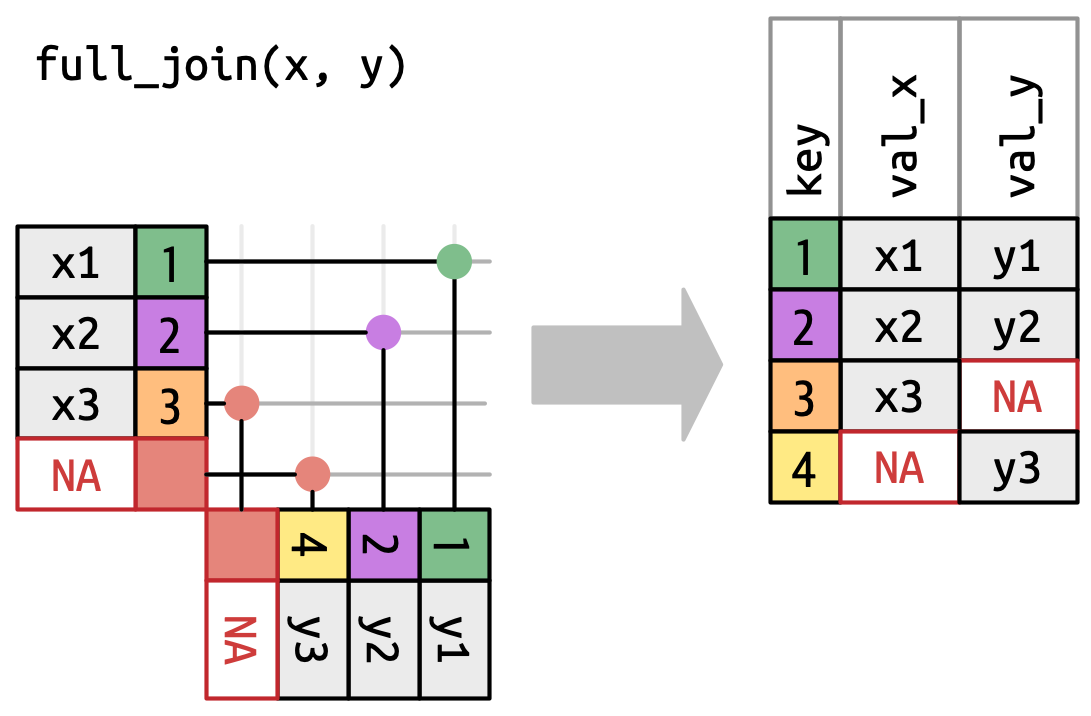
Hình 19.7: Biểu diễn trực quan của nối đầy đủ, trong đó mỗi row trong xvàyđều xuất hiện trong đầu ra.
Một cách khác để thể hiện sự khác biệt giữa các loại nối ngoài là bằng biểu đồ Venn, như trong Hình 19.8. Tuy nhiên, đây không phải là một biểu diễn tuyệt vời vì dù nó có thể giúp bạn nhớ những row nào được giữ lại, nhưng nó không minh họa được điều gì đang xảy ra với các column.
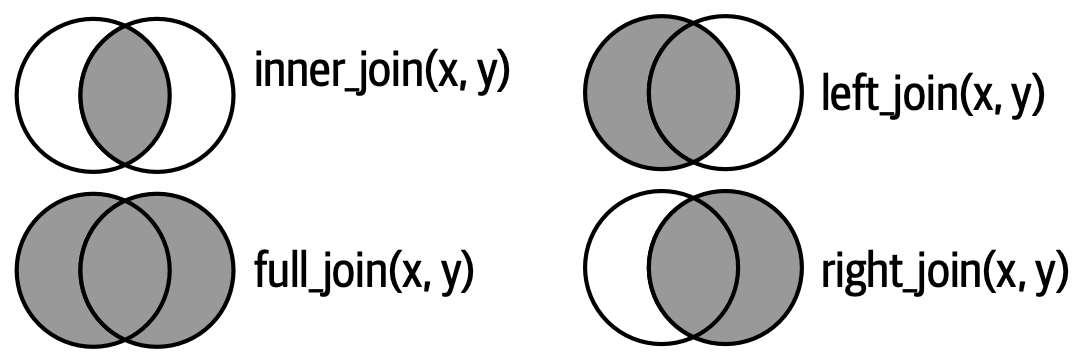
Các phép nối được trình bày ở đây là cái gọi là nối đẳng thức, trong đó các row khớp nếu các khóa bằng nhau. Nối đẳng thức là loại nối phổ biến nhất, nên chúng ta thường bỏ qua tiền tố đẳng thức, và chỉ nói “nối trong” thay vì “nối đẳng thức trong”. Chúng ta sẽ quay lại nối không đẳng thức trong Phần 19.5.
19.4.1 Khớp hàng
Cho đến giờ chúng ta đã khám phá điều gì xảy ra khi một row trong x khớp với không hoặc một row trong y. Điều gì xảy ra nếu nó khớp với nhiều hơn một row? Để hiểu chuyện gì đang xảy ra, trước tiên hãy thu hẹp tập trung vào inner_join() và sau đó vẽ một hình minh họa, Hình 19.9.
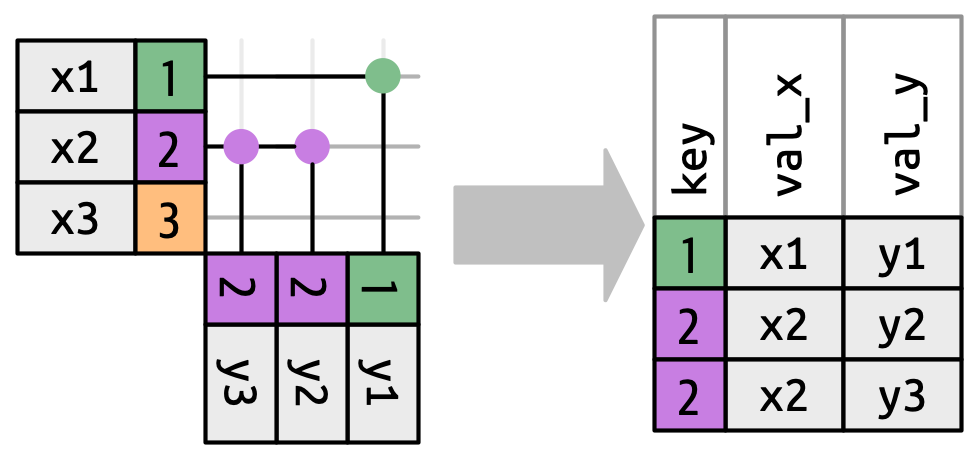
x có thể khớp. x1 khớp một row trong y, x2 khớp hai row trong y, x3 khớp không row nào trong y. Lưu ý rằng dù có ba row trong x và ba row trong đầu ra, không có sự tương ứng trực tiếp giữa các row.
Có ba kết quả có thể cho một row trong x:
- Nếu nó không khớp gì, nó bị loại bỏ.
- Nếu nó khớp 1 row trong
y, nó được giữ lại. - Nếu nó khớp nhiều hơn 1 row trong
y, nó được nhân bản một lần cho mỗi khớp.
Về nguyên tắc, điều này có nghĩa là không có sự tương ứng đảm bảo giữa các row trong đầu ra và các row trong x, nhưng trong thực tế, điều này hiếm khi gây ra vấn đề. Tuy nhiên, có một trường hợp đặc biệt nguy hiểm có thể gây ra sự bùng nổ tổ hợp các row. Hãy tưởng tượng nối hai bảng sau:
Trong khi row đầu tiên trong df1 chỉ khớp một row trong df2, row thứ hai và thứ ba đều khớp hai row. Điều này đôi khi được gọi là nối many-to-many (nhiều-nhiều), và sẽ khiến dplyr phát ra cảnh báo:
df1 |>
inner_join(df2, join_by(key))
#> Warning in inner_join(df1, df2, join_by(key)): Detected an unexpected many-to-many relationship between `x` and `y`.
#> ℹ Row 2 of `x` matches multiple rows in `y`.
#> ℹ Row 2 of `y` matches multiple rows in `x`.
#> ℹ If a many-to-many relationship is expected, set `relationship =
#> "many-to-many"` to silence this warning.
#> # A tibble: 5 × 3
#> key val_x val_y
#> <dbl> <chr> <chr>
#> 1 1 x1 y1
#> 2 2 x2 y2
#> 3 2 x2 y3
#> 4 2 x3 y2
#> 5 2 x3 y3Nếu bạn đang cố ý làm điều này, bạn có thể đặt relationship = "many-to-many", như cảnh báo gợi ý.
19.4.2 Nối lọc
Số lượng khớp cũng xác định hành vi của các phép nối lọc. Nối bán phần giữ các row trong x có một hoặc nhiều khớp trong y, như trong Hình 19.10. Nối phản giữ các row trong x khớp với không row nào trong y, như trong Hình 19.11. Trong cả hai trường hợp, chỉ sự tồn tại của khớp là quan trọng; không quan trọng nó khớp bao nhiêu lần. Điều này có nghĩa là nối lọc không bao giờ nhân bản row như nối biến đổi.
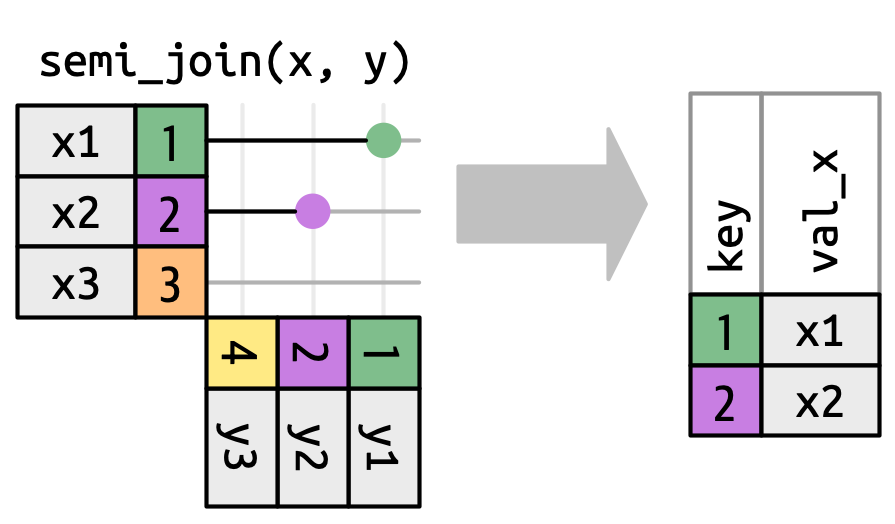
y không ảnh hưởng đến đầu ra.
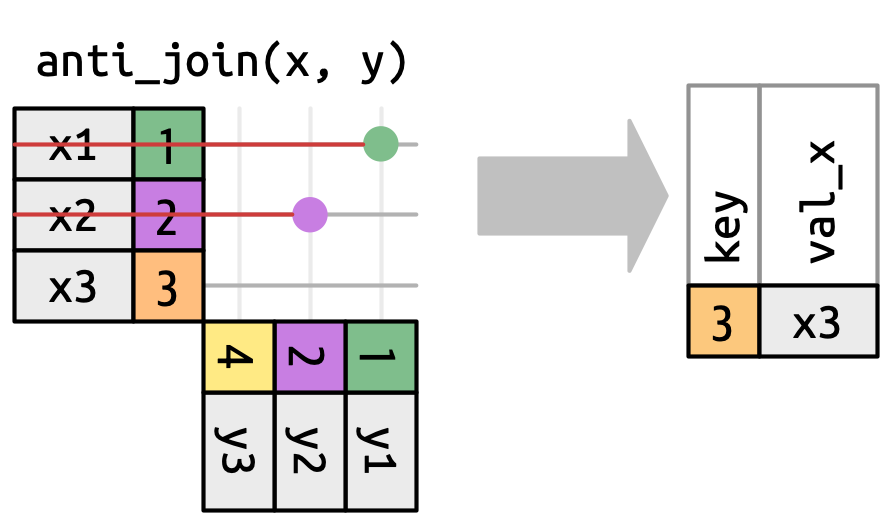
x có khớp trong y.
19.5 Nối không đẳng thức
Cho đến giờ bạn chỉ thấy nối đẳng thức, các phép nối trong đó các row khớp nếu khóa x bằng khóa y. Bây giờ chúng ta sẽ nới lỏng hạn chế đó và thảo luận về các cách khác để xác định liệu một cặp row có khớp hay không.
Nhưng trước khi làm điều đó, chúng ta cần xem lại một phép đơn giản hóa ở trên. Trong nối đẳng thức, các khóa x và y luôn bằng nhau, nên chúng ta chỉ cần hiển thị một trong đầu ra. Chúng ta có thể yêu cầu dplyr giữ cả hai khóa với keep = TRUE, dẫn đến đoạn code bên dưới và inner_join() được vẽ lại trong Hình 19.12.
x |> inner_join(y, join_by(key == key), keep = TRUE)
#> # A tibble: 2 × 4
#> key.x val_x key.y val_y
#> <dbl> <chr> <dbl> <chr>
#> 1 1 x1 1 y1
#> 2 2 x2 2 y2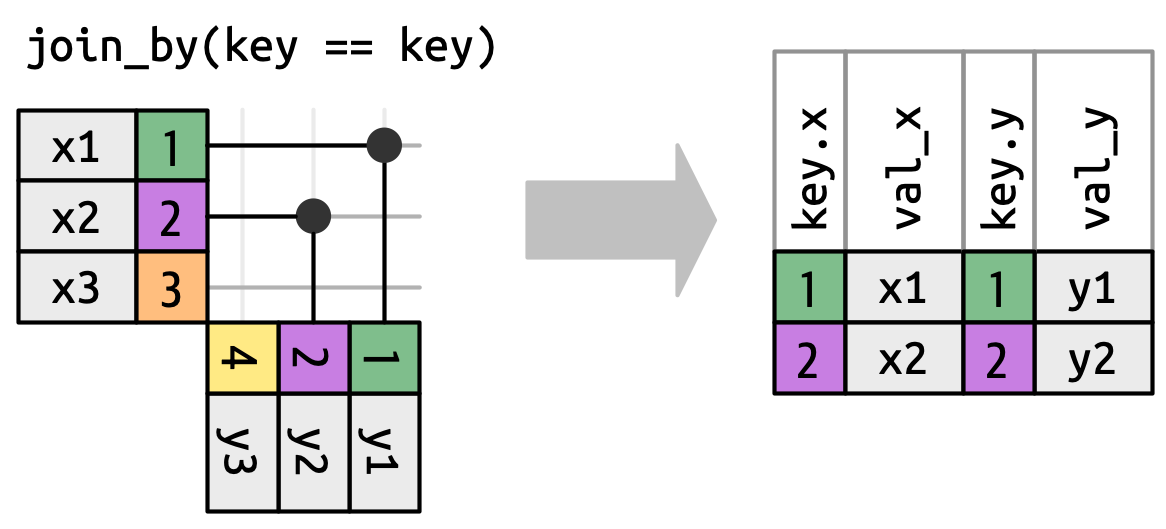
x và y trong đầu ra.
Khi chúng ta rời khỏi nối đẳng thức, chúng ta sẽ luôn hiển thị các khóa, vì các giá trị khóa thường sẽ khác nhau. Ví dụ, thay vì chỉ khớp khi x$key và y$key bằng nhau, chúng ta có thể khớp khi x$key lớn hơn hoặc bằng y$key, dẫn đến Hình 19.13. Các function nối của dplyr hiểu sự phân biệt giữa nối đẳng thức và không đẳng thức nên sẽ luôn hiển thị cả hai khóa khi bạn thực hiện nối không đẳng thức.
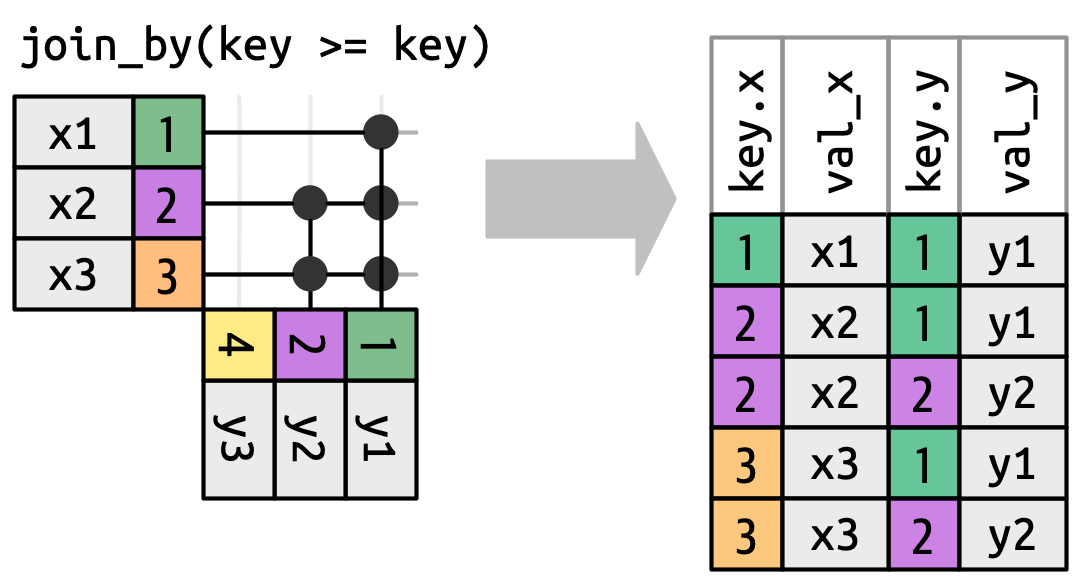
x phải lớn hơn hoặc bằng khóa y. Nhiều row tạo ra nhiều khớp.
Nối không đẳng thức không phải là một thuật ngữ đặc biệt hữu ích vì nó chỉ cho bạn biết phép nối không phải là gì, chứ không phải nó là gì. dplyr giúp bằng cách xác định bốn loại nối không đẳng thức đặc biệt hữu ích:
- Nối chéo (cross join) khớp mỗi cặp row.
-
Nối bất đẳng thức (inequality join) sử dụng
<,<=,>, và>=thay vì==. - Nối cuộn (rolling join) tương tự như nối bất đẳng thức nhưng chỉ tìm khớp gần nhất.
- Nối chồng lấp (overlap join) là một loại nối bất đẳng thức đặc biệt được thiết kế để làm việc với các khoảng.
Mỗi loại được mô tả chi tiết hơn trong các phần sau.
19.5.1 Nối chéo
Một nối chéo khớp mọi thứ, như trong Hình 19.14, tạo ra tích Descartes của các row. Điều này có nghĩa là đầu ra sẽ có nrow(x) * nrow(y) row.
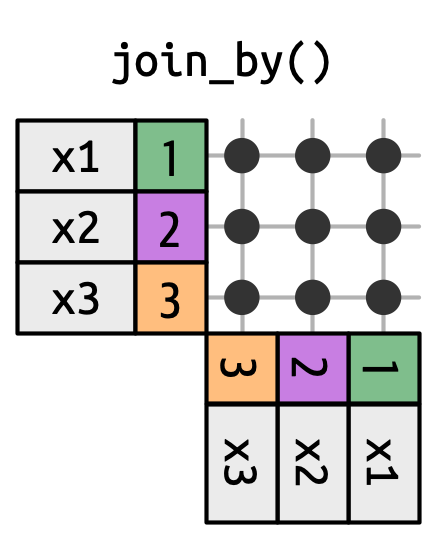
x với mọi row trong y.
Nối chéo hữu ích khi tạo hoán vị. Ví dụ, đoạn code dưới đây tạo ra mọi cặp tên có thể. Vì chúng ta đang nối df với chính nó, điều này đôi khi được gọi là tự nối (self-join). Nối chéo sử dụng một function nối khác vì không có sự phân biệt giữa nối trong/trái/phải/đầy đủ khi bạn khớp mọi row.
df <- tibble(name = c("John", "Simon", "Tracy", "Max"))
df |> cross_join(df)
#> # A tibble: 16 × 2
#> name.x name.y
#> <chr> <chr>
#> 1 John John
#> 2 John Simon
#> 3 John Tracy
#> 4 John Max
#> 5 Simon John
#> 6 Simon Simon
#> # ℹ 10 more rows19.5.2 Nối bất đẳng thức
Nối bất đẳng thức sử dụng <, <=, >=, hoặc > để hạn chế tập các khớp có thể, như trong Hình 19.13 và Hình 19.15.
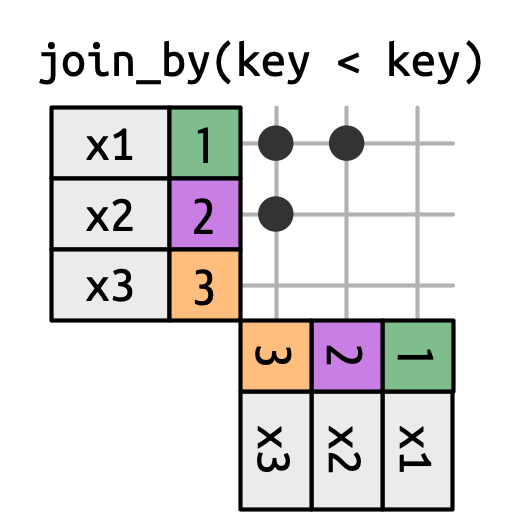
x được nối với y trên các row mà khóa của x nhỏ hơn khóa của y. Điều này tạo thành hình tam giác ở góc trên bên trái.
Nối bất đẳng thức cực kỳ tổng quát, tổng quát đến mức khó nghĩ ra các trường hợp sử dụng cụ thể có ý nghĩa. Một kỹ thuật nhỏ hữu ích là sử dụng chúng để hạn chế nối chéo sao cho thay vì tạo tất cả hoán vị, chúng ta tạo tất cả tổ hợp:
df <- tibble(id = 1:4, name = c("John", "Simon", "Tracy", "Max"))
df |> inner_join(df, join_by(id < id))
#> # A tibble: 6 × 4
#> id.x name.x id.y name.y
#> <int> <chr> <int> <chr>
#> 1 1 John 2 Simon
#> 2 1 John 3 Tracy
#> 3 1 John 4 Max
#> 4 2 Simon 3 Tracy
#> 5 2 Simon 4 Max
#> 6 3 Tracy 4 Max19.5.3 Nối cuộn
Nối cuộn là một loại nối bất đẳng thức đặc biệt, thay vì lấy mọi row thỏa mãn bất đẳng thức, bạn chỉ lấy row gần nhất, như trong Hình 19.16. Bạn có thể biến bất kỳ nối bất đẳng thức nào thành nối cuộn bằng cách thêm closest(). Ví dụ join_by(closest(x <= y)) khớp y nhỏ nhất lớn hơn hoặc bằng x, và join_by(closest(x > y)) khớp y lớn nhất nhỏ hơn x.
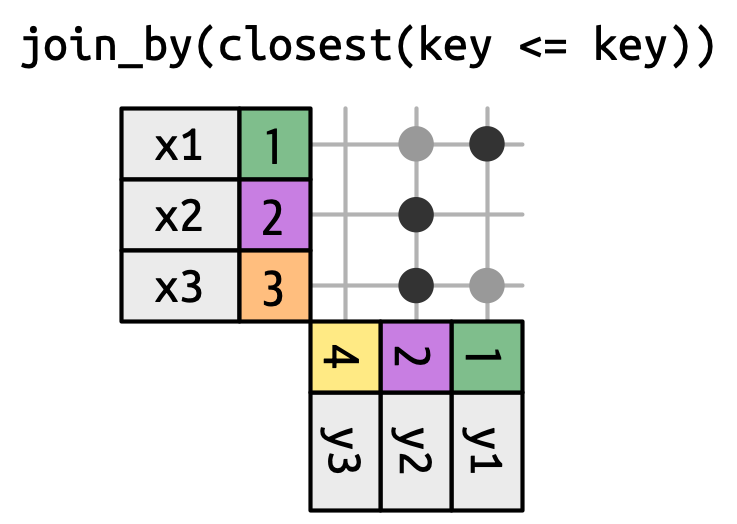
Nối cuộn đặc biệt hữu ích khi bạn có hai bảng ngày tháng không căn chỉnh hoàn hảo và bạn muốn tìm (ví dụ) ngày gần nhất trong bảng 1 đến trước (hoặc sau) một ngày nào đó trong bảng 2.
Ví dụ, hãy tưởng tượng bạn phụ trách ban tổ chức tiệc cho văn phòng. Công ty của bạn khá tiết kiệm nên thay vì tổ chức tiệc riêng, bạn chỉ tổ chức tiệc mỗi quý một lần. Các quy tắc để xác định khi nào tổ chức tiệc hơi phức tạp: tiệc luôn vào thứ Hai, bạn bỏ qua tuần đầu tiên của tháng Một vì nhiều người đang nghỉ phép, và thứ Hai đầu tiên của Q3 2022 là ngày 4 tháng 7, nên phải lùi lại một tuần. Điều đó dẫn đến các ngày tiệc sau:
Bây giờ hãy tưởng tượng bạn có một bảng sinh nhật nhân viên:
set.seed(123)
employees <- tibble(
name = sample(babynames::babynames$name, 100),
birthday = ymd("2022-01-01") + (sample(365, 100, replace = TRUE) - 1)
)
employees
#> # A tibble: 100 × 2
#> name birthday
#> <chr> <date>
#> 1 Kemba 2022-01-22
#> 2 Orean 2022-06-26
#> 3 Kirstyn 2022-02-11
#> 4 Amparo 2022-11-11
#> 5 Belen 2022-03-25
#> 6 Rayshaun 2022-01-11
#> # ℹ 94 more rowsVà cho mỗi nhân viên, chúng ta muốn tìm ngày tiệc cuối cùng đến trước (hoặc vào) ngày sinh nhật của họ. Chúng ta có thể biểu đạt điều đó bằng nối cuộn:
employees |>
left_join(parties, join_by(closest(birthday >= party)))
#> # A tibble: 100 × 4
#> name birthday q party
#> <chr> <date> <int> <date>
#> 1 Kemba 2022-01-22 1 2022-01-10
#> 2 Orean 2022-06-26 2 2022-04-04
#> 3 Kirstyn 2022-02-11 1 2022-01-10
#> 4 Amparo 2022-11-11 4 2022-10-03
#> 5 Belen 2022-03-25 1 2022-01-10
#> 6 Rayshaun 2022-01-11 1 2022-01-10
#> # ℹ 94 more rowsTuy nhiên, có một vấn đề với cách tiếp cận này: những người có sinh nhật trước ngày 10 tháng 1 không được tham gia tiệc:
Để giải quyết vấn đề này, chúng ta cần tiếp cận bài toán theo cách khác, với nối chồng lấp.
19.5.4 Nối chồng lấp
Nối chồng lấp cung cấp ba function trợ giúp sử dụng nối bất đẳng thức để giúp làm việc với khoảng dễ hơn:
-
between(x, y_lower, y_upper)là viết tắt củax >= y_lower, x <= y_upper. -
within(x_lower, x_upper, y_lower, y_upper)là viết tắt củax_lower >= y_lower, x_upper <= y_upper. -
overlaps(x_lower, x_upper, y_lower, y_upper)là viết tắt củax_lower <= y_upper, x_upper >= y_lower.
Hãy tiếp tục ví dụ sinh nhật để xem bạn có thể sử dụng chúng như thế nào. Có một vấn đề với chiến lược chúng ta đã dùng ở trên: không có tiệc nào trước các sinh nhật từ ngày 1-9 tháng 1. Vì vậy, có thể tốt hơn nếu chỉ rõ khoảng ngày mà mỗi bữa tiệc bao gồm, và tạo trường hợp đặc biệt cho những sinh nhật sớm:
parties <- tibble(
q = 1:4,
party = ymd(c("2022-01-10", "2022-04-04", "2022-07-11", "2022-10-03")),
start = ymd(c("2022-01-01", "2022-04-04", "2022-07-11", "2022-10-03")),
end = ymd(c("2022-04-03", "2022-07-11", "2022-10-02", "2022-12-31"))
)
parties
#> # A tibble: 4 × 4
#> q party start end
#> <int> <date> <date> <date>
#> 1 1 2022-01-10 2022-01-01 2022-04-03
#> 2 2 2022-04-04 2022-04-04 2022-07-11
#> 3 3 2022-07-11 2022-07-11 2022-10-02
#> 4 4 2022-10-03 2022-10-03 2022-12-31Hadley rất tệ trong việc nhập dữ liệu nên anh ấy cũng muốn kiểm tra rằng các khoảng tiệc không chồng lấp nhau. Một cách để làm điều này là sử dụng tự nối để kiểm tra xem có khoảng bắt đầu-kết thúc nào chồng lấp với khoảng khác không:
parties |>
inner_join(parties, join_by(overlaps(start, end, start, end), q < q)) |>
select(start.x, end.x, start.y, end.y)
#> # A tibble: 1 × 4
#> start.x end.x start.y end.y
#> <date> <date> <date> <date>
#> 1 2022-04-04 2022-07-11 2022-07-11 2022-10-02Ồ, có sự chồng lấp, vậy hãy sửa vấn đề đó và tiếp tục:
Bây giờ chúng ta có thể ghép mỗi nhân viên với bữa tiệc của họ. Đây là một chỗ tốt để sử dụng unmatched = "error" vì chúng ta muốn nhanh chóng phát hiện nếu có nhân viên nào không được xếp tiệc.
employees |>
inner_join(parties, join_by(between(birthday, start, end)), unmatched = "error")
#> # A tibble: 100 × 6
#> name birthday q party start end
#> <chr> <date> <int> <date> <date> <date>
#> 1 Kemba 2022-01-22 1 2022-01-10 2022-01-01 2022-04-03
#> 2 Orean 2022-06-26 2 2022-04-04 2022-04-04 2022-07-10
#> 3 Kirstyn 2022-02-11 1 2022-01-10 2022-01-01 2022-04-03
#> 4 Amparo 2022-11-11 4 2022-10-03 2022-10-03 2022-12-31
#> 5 Belen 2022-03-25 1 2022-01-10 2022-01-01 2022-04-03
#> 6 Rayshaun 2022-01-11 1 2022-01-10 2022-01-01 2022-04-03
#> # ℹ 94 more rows19.5.5 Bài tập
-
Bạn có thể giải thích điều gì đang xảy ra với các khóa trong phép nối đẳng thức này không? Tại sao chúng khác nhau?
x |> full_join(y, join_by(key == key)) #> # A tibble: 4 × 3 #> key val_x val_y #> <dbl> <chr> <chr> #> 1 1 x1 y1 #> 2 2 x2 y2 #> 3 3 x3 <NA> #> 4 4 <NA> y3 x |> full_join(y, join_by(key == key), keep = TRUE) #> # A tibble: 4 × 4 #> key.x val_x key.y val_y #> <dbl> <chr> <dbl> <chr> #> 1 1 x1 1 y1 #> 2 2 x2 2 y2 #> 3 3 x3 NA <NA> #> 4 NA <NA> 4 y3 Khi tìm xem có khoảng tiệc nào chồng lấp với khoảng tiệc khác hay không, chúng ta đã sử dụng
q < qtrongjoin_by()? Tại sao? Điều gì xảy ra nếu bạn bỏ bất đẳng thức này?
19.6 Tóm tắt
Trong chương này, bạn đã học cách sử dụng nối biến đổi và nối lọc để kết hợp dữ liệu từ một cặp data frame. Trên đường đi, bạn đã học cách xác định khóa, và sự khác biệt giữa khóa chính và khóa ngoại. Bạn cũng hiểu cách phép nối hoạt động và cách tìm ra số row đầu ra sẽ có. Cuối cùng, bạn đã có cái nhìn thoáng qua về sức mạnh của nối không đẳng thức và thấy một vài trường hợp sử dụng thú vị.
Chương này kết thúc phần “Biến đổi” của cuốn sách, nơi trọng tâm là các công cụ bạn có thể sử dụng với từng column và tibble riêng lẻ. Bạn đã học về các function dplyr và base để làm việc với vector logic, số, và bảng hoàn chỉnh, các function stringr để làm việc với string, các function lubridate để làm việc với ngày-giờ, và các function forcats để làm việc với factor.
Trong phần tiếp theo của cuốn sách, bạn sẽ tìm hiểu thêm về cách đưa các loại dữ liệu khác nhau vào R ở dạng gọn gàng.