9 Các lớp
9.1 Giới thiệu
Trong Chương 1, bạn đã học được nhiều hơn là chỉ cách tạo biểu đồ phân tán (scatter plot), biểu đồ column (bar chart), và biểu đồ hộp (box plot). Bạn đã học được nền tảng mà bạn có thể sử dụng để tạo bất kỳ loại biểu đồ nào với ggplot2.
Trong chương này, bạn sẽ mở rộng nền tảng đó khi tìm hiểu về ngữ pháp đồ họa theo lớp (layered grammar of graphics). Chúng ta sẽ bắt đầu với việc tìm hiểu sâu hơn về mapping thuộc tính đồ họa (aesthetic mapping), đối tượng đồ họa (geoms), và facet. Sau đó, bạn sẽ tìm hiểu về các phép biến đổi thống kê mà ggplot2 thực hiện ngầm khi tạo biểu đồ. Các phép biến đổi này được sử dụng để tính toán các giá trị mới để vẽ, chẳng hạn như chiều cao của các thanh trong biểu đồ column hoặc trung vị trong biểu đồ hộp. Bạn cũng sẽ tìm hiểu về điều chỉnh vị trí (position adjustment), giúp thay đổi cách các geom được hiển thị trong biểu đồ của bạn. Cuối cùng, chúng ta sẽ giới thiệu ngắn gọn về hệ tọa độ (coordinate system).
Chúng ta sẽ không đề cập đến từng function và tùy chọn cho mỗi lớp này, nhưng chúng ta sẽ hướng dẫn bạn qua các chức năng quan trọng và thường được sử dụng nhất do ggplot2 cung cấp cũng như giới thiệu cho bạn các package ggplot2.
9.1.1 Điều kiện tiên quyết
Chương này tập trung vào ggplot2. Để truy cập các bộ dữ liệu, trang trợ giúp, và các function được sử dụng trong chương này, hãy tải tidyverse bằng cách chạy đoạn mã sau:
9.2 Ánh xạ thuộc tính đồ họa
“Giá trị lớn nhất của một bức tranh là khi nó buộc chúng ta phải chú ý đến những điều mà chúng ta không bao giờ mong đợi được thấy.” — John Tukey
Hãy nhớ rằng data frame mpg đi kèm với package ggplot2 chứa 234 quan sát trên 38 mẫu xe.
mpg
#> # A tibble: 234 × 11
#> manufacturer model displ year cyl trans drv cty hwy fl
#> <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr>
#> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p
#> 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p
#> 3 audi a4 2 2008 4 manual(m6) f 20 31 p
#> 4 audi a4 2 2008 4 auto(av) f 21 30 p
#> 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p
#> 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p
#> # ℹ 228 more rows
#> # ℹ 1 more variable: class <chr>Trong số các biến trong mpg có:
displ: Dung tích động cơ của xe, tính bằng lít. Một biến số.hwy: Hiệu suất nhiên liệu của xe trên đường cao tốc, tính bằng dặm trên gallon (mpg). Một chiếc xe có hiệu suất nhiên liệu thấp tiêu thụ nhiều nhiên liệu hơn một chiếc xe có hiệu suất nhiên liệu cao khi chúng đi cùng một quãng đường. Một biến số.class: Loại xe. Một biến phân loại.
Hãy bắt đầu bằng việc visualization mối quan hệ giữa displ và hwy cho các class khác nhau của xe. Chúng ta có thể làm điều này với biểu đồ phân tán trong đó các biến số được mapping đến thuộc tính đồ họa x và y, và biến phân loại được mapping đến một thuộc tính đồ họa như color hoặc shape.
# Trái
ggplot(mpg, aes(x = displ, y = hwy, color = class)) +
geom_point()
# Phải
ggplot(mpg, aes(x = displ, y = hwy, shape = class)) +
geom_point()
#> Warning: The shape palette can deal with a maximum of 6 discrete values because more
#> than 6 becomes difficult to discriminate
#> ℹ you have requested 7 values. Consider specifying shapes manually if you
#> need that many of them.
#> Warning: Removed 62 rows containing missing values or values outside the scale range
#> (`geom_point()`).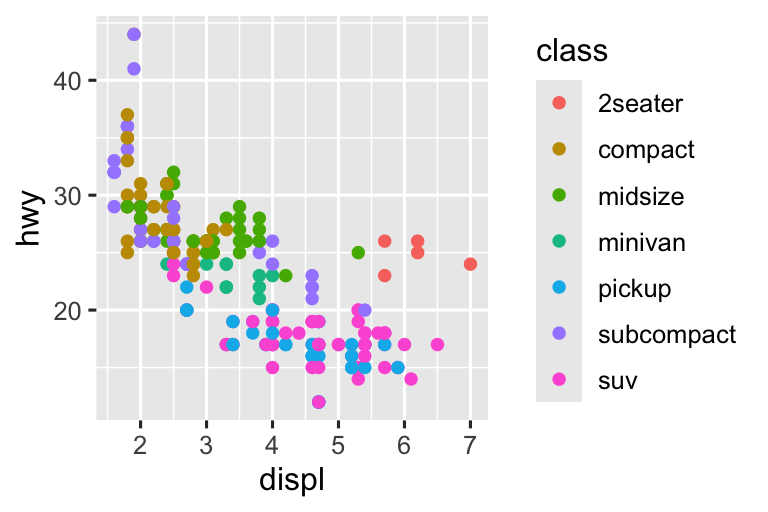
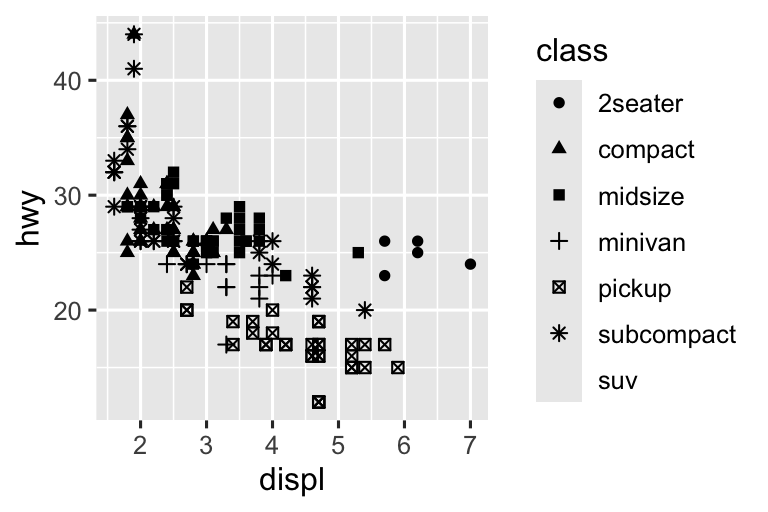
Khi class được mapping đến shape, chúng ta nhận được hai cảnh báo:
1: The shape palette can deal with a maximum of 6 discrete values because more than 6 becomes difficult to discriminate; you have 7. Consider specifying shapes manually if you must have them.
2: Removed 62 rows containing missing values (
geom_point()).
Vì ggplot2 chỉ sử dụng sáu hình dạng tại một thời điểm theo mặc định, các nhóm bổ sung sẽ không được vẽ khi bạn sử dụng thuộc tính đồ họa shape. Cảnh báo thứ hai có liên quan – có 62 xe SUV trong bộ dữ liệu và chúng không được vẽ.
Tương tự, chúng ta có thể mapping class đến thuộc tính đồ họa size hoặc alpha, lần lượt kiểm soát kích thước và độ trong suốt của các điểm.
# Trái
ggplot(mpg, aes(x = displ, y = hwy, size = class)) +
geom_point()
#> Warning: Using size for a discrete variable is not advised.
# Phải
ggplot(mpg, aes(x = displ, y = hwy, alpha = class)) +
geom_point()
#> Warning: Using alpha for a discrete variable is not advised.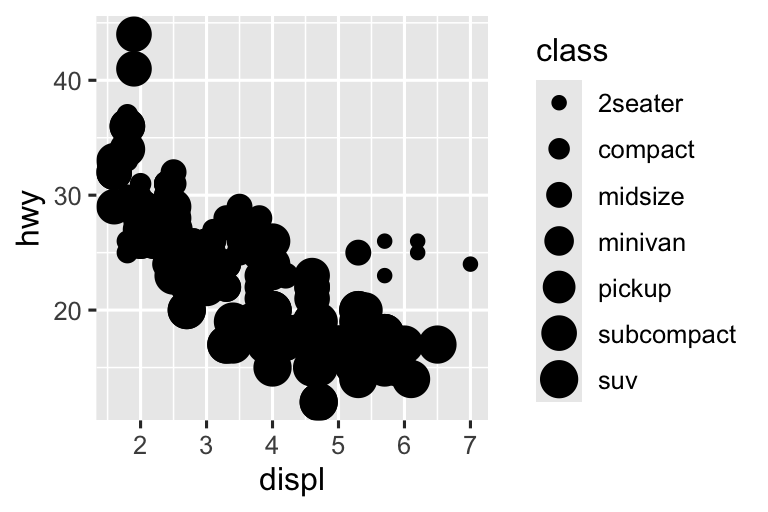
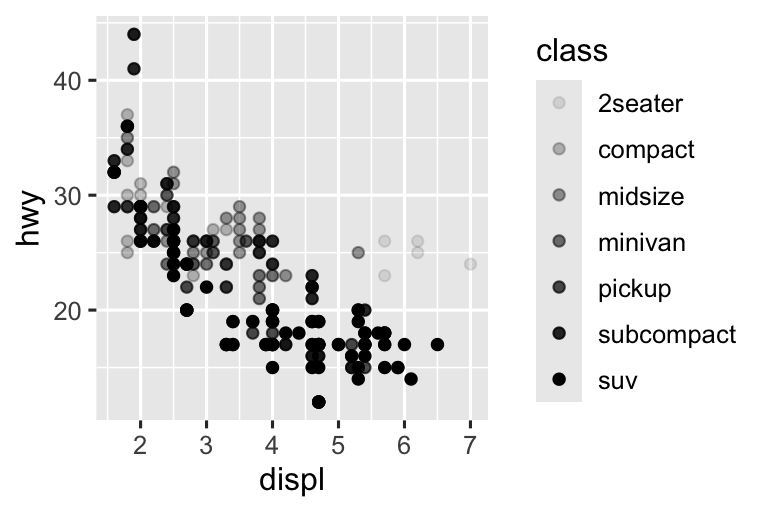
Cả hai đều tạo ra cảnh báo:
Using alpha for a discrete variable is not advised.
Ánh xạ một biến rời rạc (phân loại) không có thứ tự (class) đến một thuộc tính đồ họa có thứ tự (size hoặc alpha) thường không phải là ý tưởng tốt vì nó ngụ ý một thứ hạng mà thực tế không tồn tại.
Một khi bạn mapping một thuộc tính đồ họa, ggplot2 sẽ lo phần còn lại. Nó chọn một scale hợp lý để sử dụng với thuộc tính đồ họa đó, và nó xây dựng một chú giải giải thích mapping giữa các mức và giá trị. Đối với thuộc tính đồ họa x và y, ggplot2 không tạo chú giải, nhưng nó tạo một đường trục với các vạch đánh dấu và nhãn. Đường trục cung cấp thông tin giống như chú giải; nó giải thích mapping giữa vị trí và giá trị.
Bạn cũng có thể đặt các thuộc tính trực quan của geom một cách thủ công như một argument của function geom (bên ngoài aes()) thay vì dựa vào mapping biến để xác định giao diện. Ví dụ, chúng ta có thể làm tất cả các điểm trong biểu đồ có màu xanh:
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(color = "blue")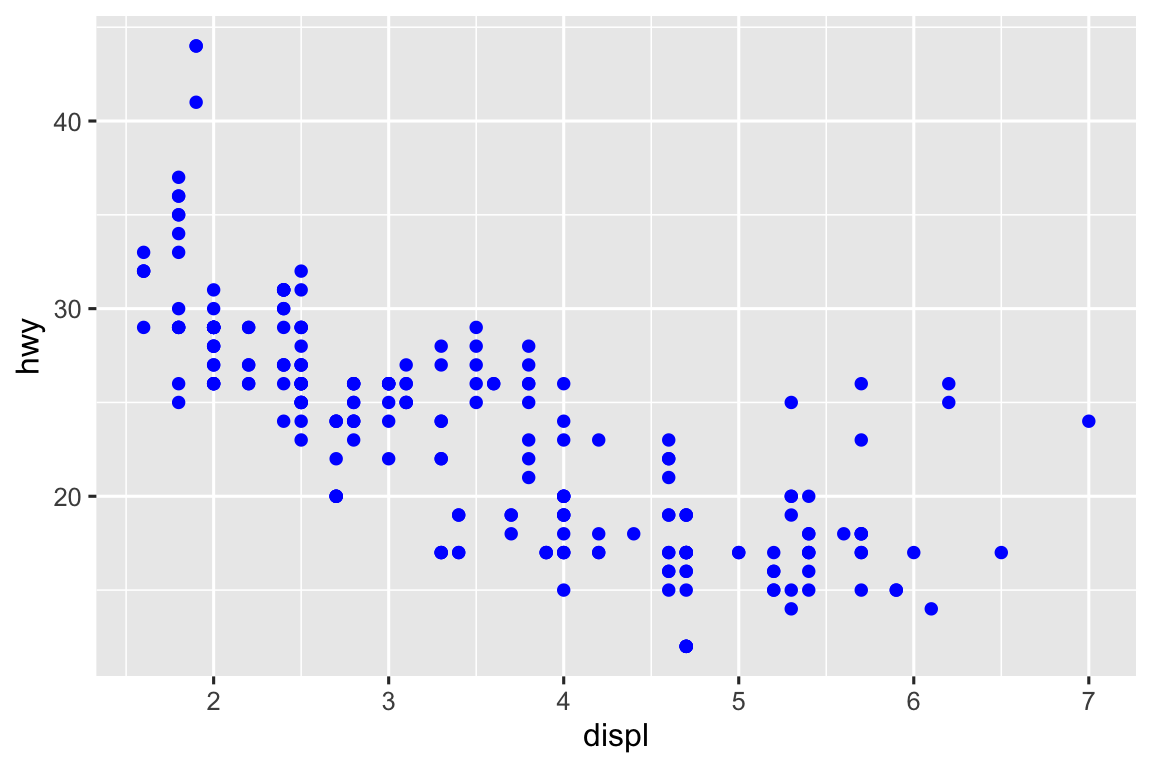
Ở đây, màu sắc không truyền tải thông tin về một biến, mà chỉ thay đổi giao diện của biểu đồ. Bạn sẽ cần chọn một giá trị có ý nghĩa cho thuộc tính đồ họa đó:
- Tên của một màu dưới dạng string, ví dụ
color = "blue" - Kích thước của một điểm tính bằng mm, ví dụ
size = 1 - Hình dạng của một điểm dưới dạng số, ví dụ
shape = 1, như được hiển thị trong Hình 9.1.
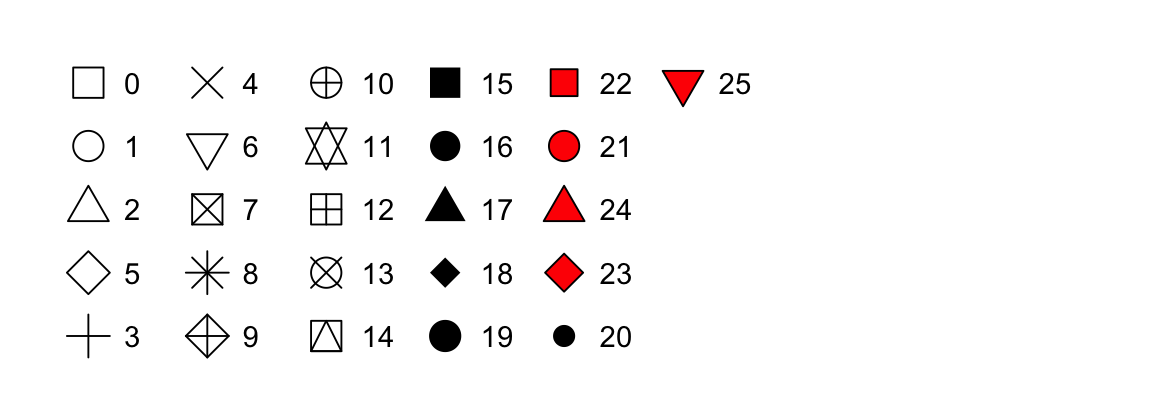
color và fill. Các hình rỗng (0–14) có viền được xác định bởi color; các hình đặc (15–20) được tô bằng color; các hình có tô màu (21–25) có viền color và được tô bằng fill. Các hình dạng được sắp xếp để giữ các hình tương tự cạnh nhau.
Cho đến nay chúng ta đã thảo luận về các thuộc tính đồ họa mà chúng ta có thể mapping hoặc đặt trong biểu đồ phân tán, khi sử dụng geom điểm. Bạn có thể tìm hiểu thêm về tất cả các mapping thuộc tính đồ họa có thể trong tài liệu đặc tả thuộc tính đồ họa tại https://ggplot2.tidyverse.org/articles/ggplot2-specs.html.
Các thuộc tính đồ họa cụ thể mà bạn có thể sử dụng cho một biểu đồ phụ thuộc vào geom mà bạn sử dụng để biểu diễn dữ liệu. Trong phần tiếp theo chúng ta sẽ tìm hiểu sâu hơn về các geom.
9.2.1 Bài tập
Tạo một biểu đồ phân tán của
hwytheodispltrong đó các điểm là tam giác tô màu hồng.-
Tại sao đoạn mã sau không tạo ra biểu đồ với các điểm màu xanh?
ggplot(mpg) + geom_point(aes(x = displ, y = hwy, color = "blue")) Thuộc tính thẩm mỹ
strokelàm gì? Nó hoạt động với những hình dạng nào? (Gợi ý: sử dụng?geom_point)Điều gì xảy ra nếu bạn mapping một thuộc tính đồ họa đến một thứ không phải tên biến, ví dụ
aes(color = displ < 5)? Lưu ý, bạn cũng cần chỉ định x và y.
9.3 Đối tượng hình học
Hai biểu đồ sau giống nhau như thế nào?
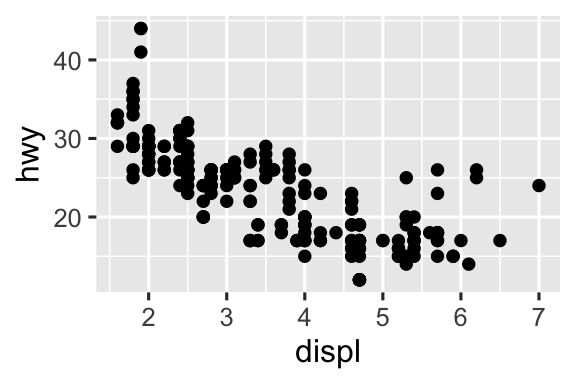
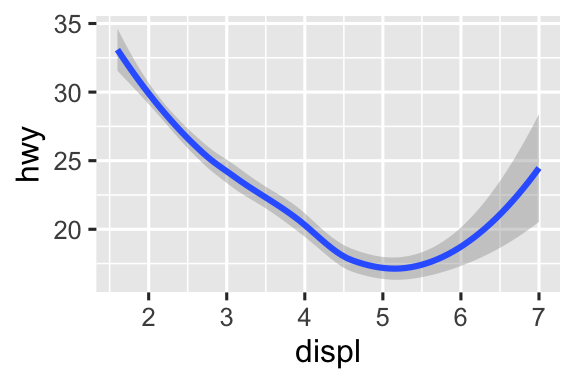
Cả hai biểu đồ chứa cùng biến x, cùng biến y, và cả hai mô tả cùng dữ liệu. Nhưng các biểu đồ không giống hệt nhau. Mỗi biểu đồ sử dụng một geom khác nhau để biểu diễn dữ liệu. Biểu đồ bên trái sử dụng geom điểm, và biểu đồ bên phải sử dụng geom trơn, một đường trơn được khớp với dữ liệu.
Để thay đổi geom trong biểu đồ của bạn, hãy thay đổi function geom mà bạn thêm vào ggplot(). Ví dụ, để tạo các biểu đồ ở trên, bạn có thể sử dụng đoạn mã sau:
# Trái
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point()
# Phải
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_smooth()
#> `geom_smooth()` using method = 'loess' and formula = 'y ~ x'Mọi function geom trong ggplot2 đều nhận một argument mapping, được định nghĩa cục bộ trong lớp geom hoặc toàn cục trong lớp ggplot(). Tuy nhiên, không phải thuộc tính đồ họa nào cũng hoạt động với mọi geom. Bạn có thể đặt hình dạng của một điểm, nhưng bạn không thể đặt “hình dạng” của một đường. Nếu bạn thử, ggplot2 sẽ lặng lẽ bỏ qua mapping thuộc tính đồ họa đó. Mặt khác, bạn có thể đặt kiểu đường của một đường. geom_smooth() sẽ vẽ một đường khác nhau, với kiểu đường khác nhau, cho mỗi giá trị duy nhất của biến mà bạn mapping đến linetype.
# Trái
ggplot(mpg, aes(x = displ, y = hwy, shape = drv)) +
geom_smooth()
# Phải
ggplot(mpg, aes(x = displ, y = hwy, linetype = drv)) +
geom_smooth()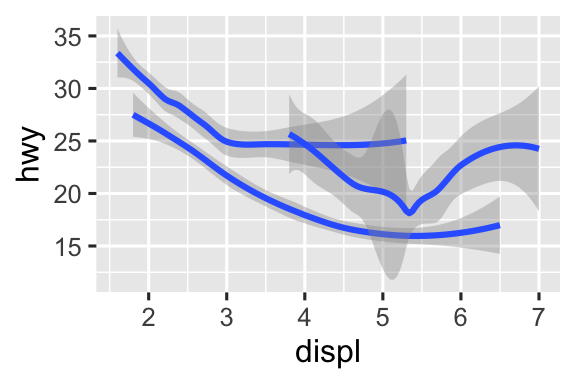
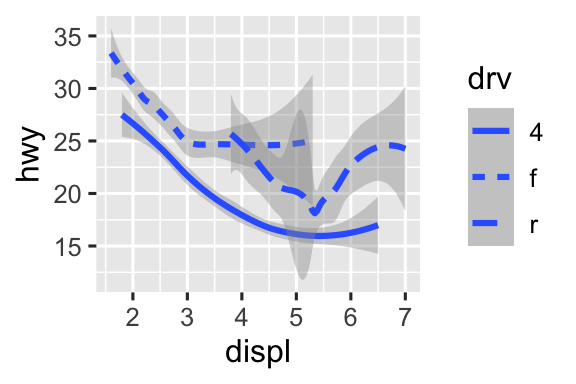
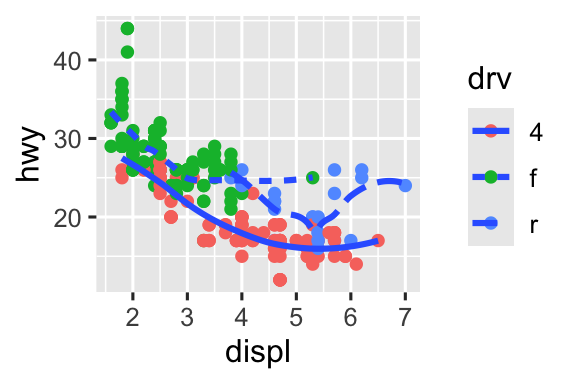
Ở đây, geom_smooth() phân tách các xe thành ba đường dựa trên giá trị drv của chúng, mô tả hệ dẫn động của xe. Một đường mô tả tất cả các điểm có giá trị 4, một đường mô tả tất cả các điểm có giá trị f, và một đường mô tả tất cả các điểm có giá trị r. Ở đây, 4 là viết tắt của dẫn động bốn bánh, f cho dẫn động cầu trước, và r cho dẫn động cầu sau.
Nếu điều này nghe có vẻ khó hiểu, chúng ta có thể làm rõ hơn bằng cách chồng các đường lên trên dữ liệu thô và sau đó tô màu mọi thứ theo drv.
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth(aes(linetype = drv))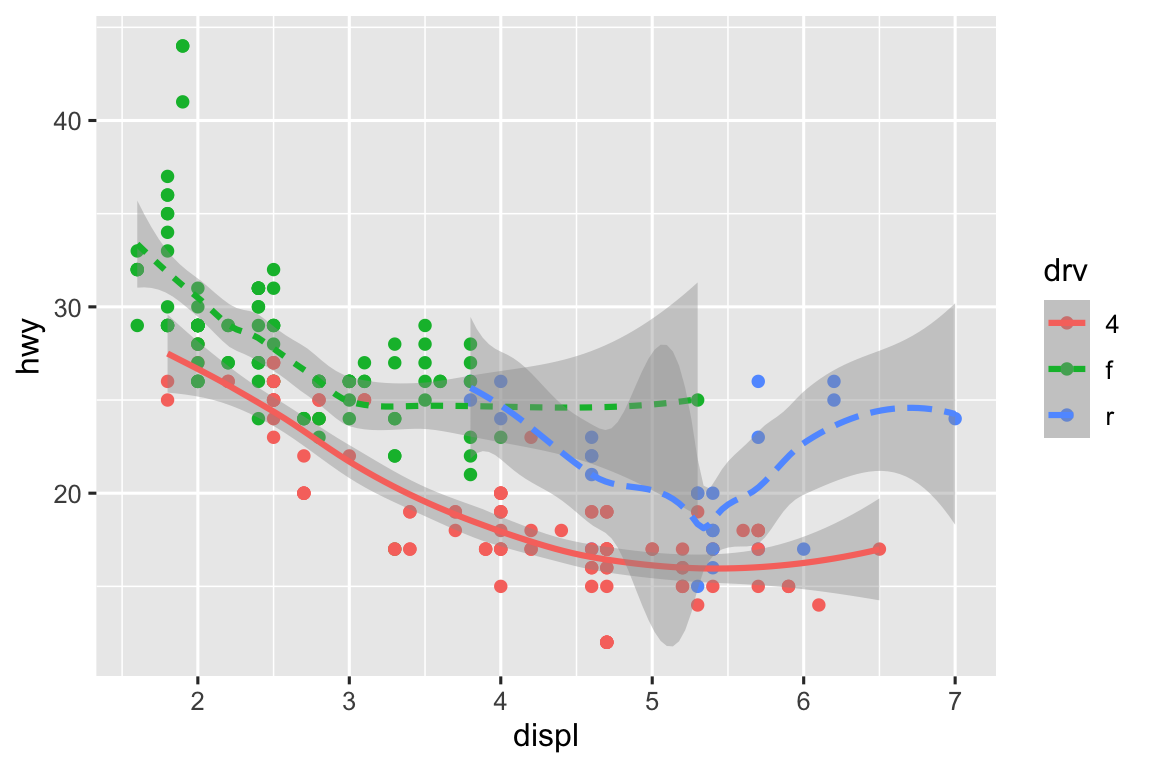
Lưu ý rằng biểu đồ này chứa hai geom trong cùng một đồ thị.
Nhiều geom, như geom_smooth(), sử dụng một geom duy nhất để hiển thị nhiều row dữ liệu. Đối với các geom này, bạn có thể đặt thuộc tính đồ họa group cho một biến phân loại để vẽ nhiều đối tượng. ggplot2 sẽ vẽ một đối tượng riêng biệt cho mỗi giá trị duy nhất của biến nhóm. Trong thực tế, ggplot2 sẽ tự động nhóm dữ liệu cho các geom này bất cứ khi nào bạn mapping một thuộc tính đồ họa đến một biến rời rạc (như trong ví dụ linetype). Việc dựa vào tính năng này rất tiện lợi vì thuộc tính đồ họa group tự nó không thêm chú giải hoặc đặc điểm phân biệt cho các geom.
# Trái
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_smooth()
# Giữa
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_smooth(aes(group = drv))
# Phải
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_smooth(aes(color = drv), show.legend = FALSE)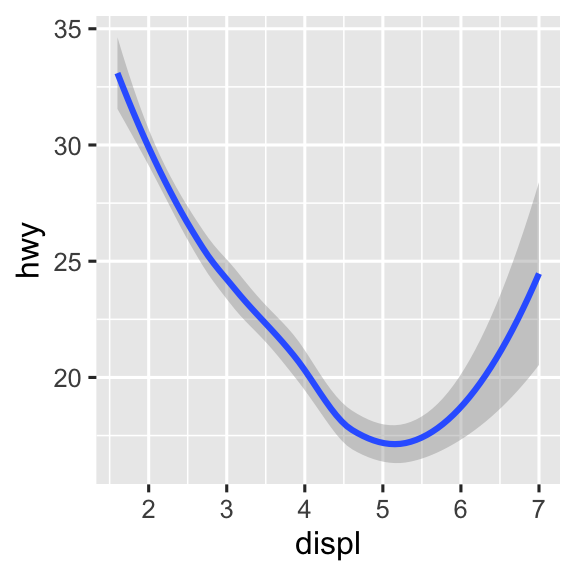
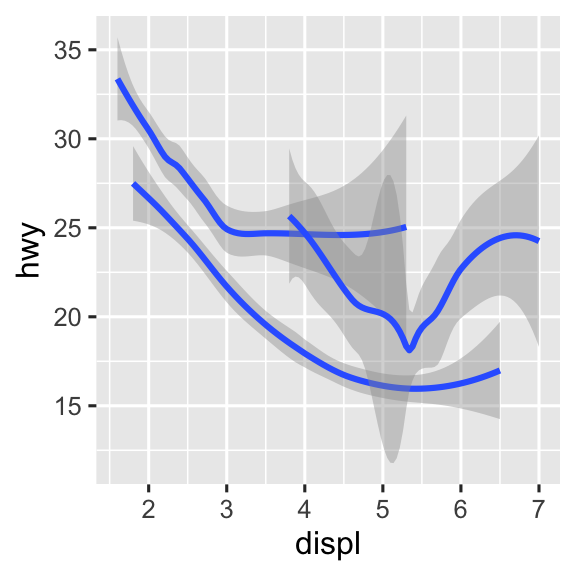
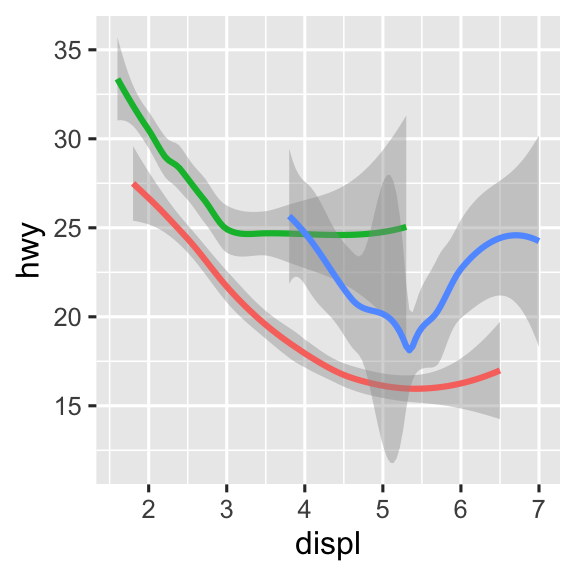
Nếu bạn đặt các mapping trong function geom, ggplot2 sẽ coi chúng là mapping cục bộ cho lớp đó. Nó sẽ sử dụng các mapping này để mở rộng hoặc ghi đè các mapping toàn cục chỉ cho lớp đó. Điều này giúp hiển thị các thuộc tính đồ họa khác nhau trong các lớp khác nhau trở nên khả thi.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(aes(color = class)) +
geom_smooth()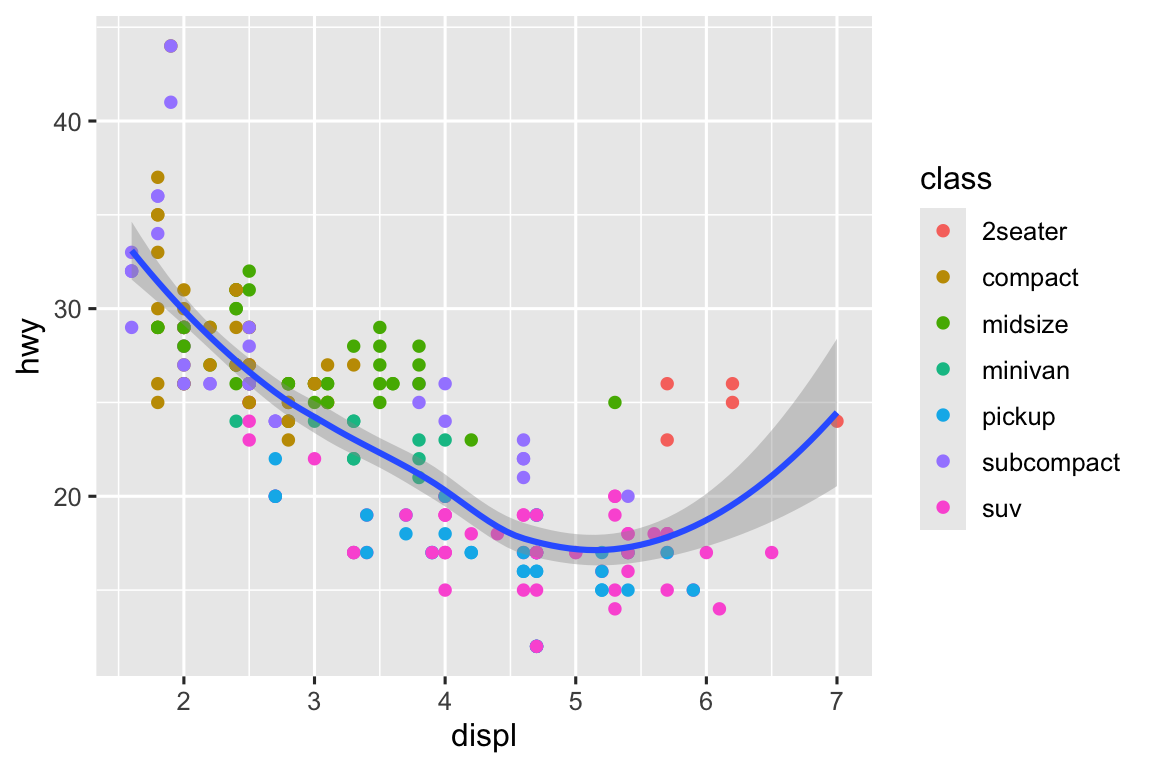
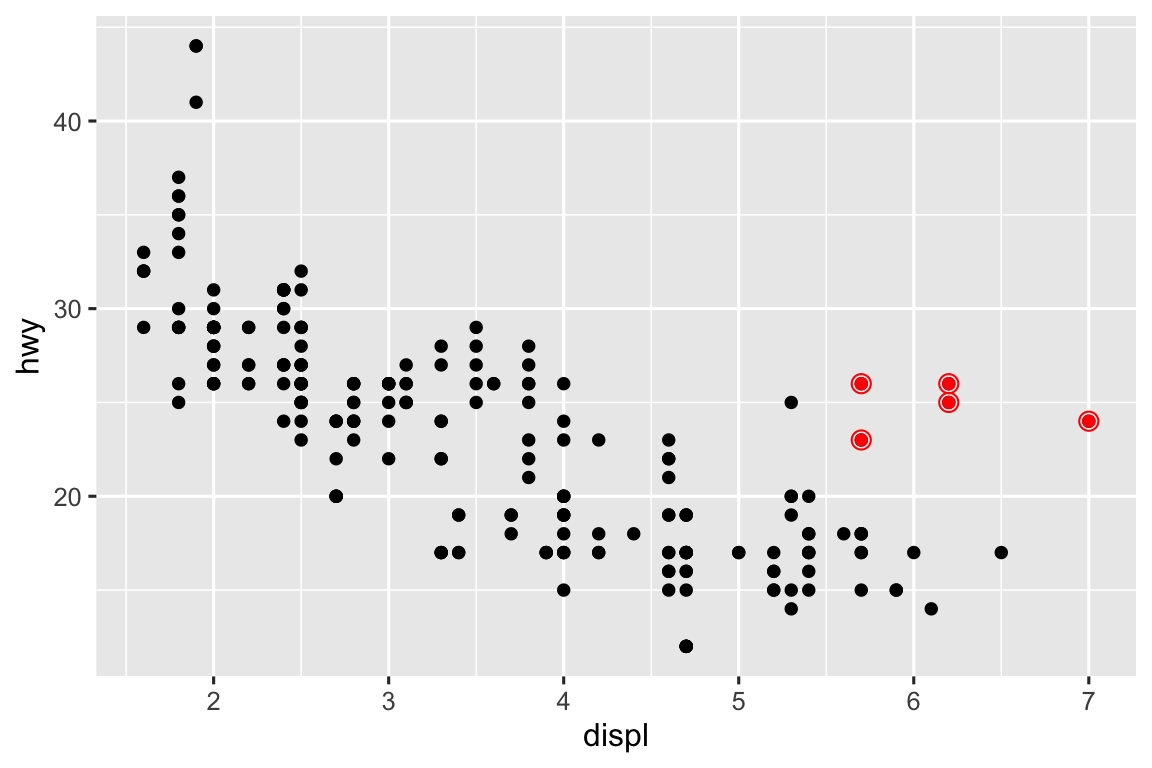
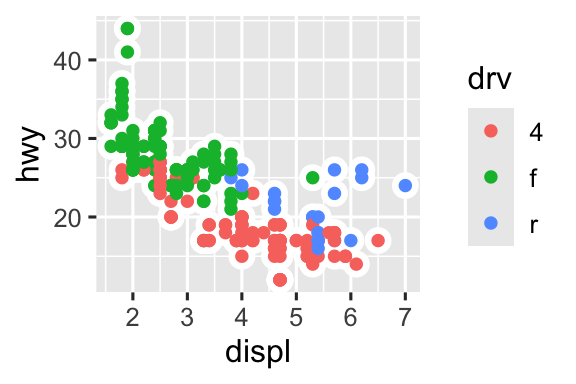
Bạn có thể sử dụng cùng ý tưởng để chỉ định data khác nhau cho mỗi lớp. Ở đây, chúng ta sử dụng các điểm đỏ cũng như các vòng tròn rỗng để làm nổi bật xe hai chỗ. Đối số data cục bộ trong geom_point() ghi đè argument data toàn cục trong ggplot() chỉ cho lớp đó.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
geom_point(
data = mpg |> filter(class == "2seater"),
color = "red"
) +
geom_point(
data = mpg |> filter(class == "2seater"),
shape = "circle open", size = 3, color = "red"
)
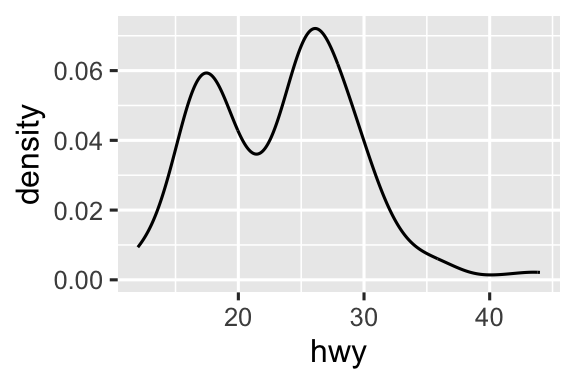
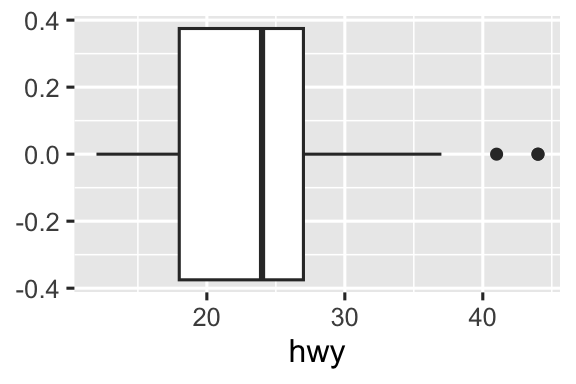
Geom là khối xây dựng cơ bản của ggplot2. Bạn có thể hoàn toàn biến đổi giao diện biểu đồ bằng cách thay đổi geom của nó, và các geom khác nhau có thể bộc lộ các đặc điểm khác nhau của dữ liệu. Ví dụ, biểu đồ tần suất và biểu đồ mật độ bên dưới cho thấy phân phối của quãng đường đường cao tốc là hai đỉnh và lệch phải trong khi biểu đồ hộp cho thấy hai giá trị ngoại lai tiềm năng.
# Trái
ggplot(mpg, aes(x = hwy)) +
geom_histogram(binwidth = 2)
# Giữa
ggplot(mpg, aes(x = hwy)) +
geom_density()
# Phải
ggplot(mpg, aes(x = hwy)) +
geom_boxplot()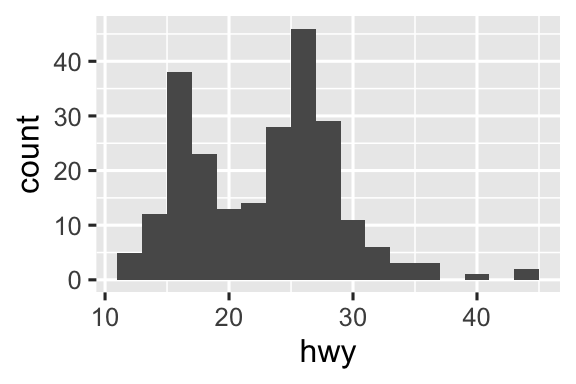
ggplot2 cung cấp hơn 40 geom nhưng chúng không bao phủ tất cả các biểu đồ có thể tạo. Nếu bạn cần một geom khác, chúng tôi khuyên bạn nên xem các package trước để kiểm tra xem ai đó đã triển khai nó chưa (xem https://exts.ggplot2.tidyverse.org/gallery/ để xem một số mẫu). Ví dụ, package ggridges (https://wilkelab.org/ggridges) hữu ích để tạo biểu đồ đường sống núi (ridgeline plot), có thể hữu ích để visualization mật độ của một biến số cho các mức khác nhau của một biến phân loại. Trong biểu đồ sau, chúng ta không chỉ sử dụng một geom mới (geom_density_ridges()), mà còn mapping cùng một biến đến nhiều thuộc tính đồ họa (drv đến y, fill, và color) cũng như đặt một thuộc tính đồ họa (alpha = 0.5) để làm các đường cong mật độ trong suốt.
library(ggridges)
ggplot(mpg, aes(x = hwy, y = drv, fill = drv, color = drv)) +
geom_density_ridges(alpha = 0.5, show.legend = FALSE)
#> Picking joint bandwidth of 1.28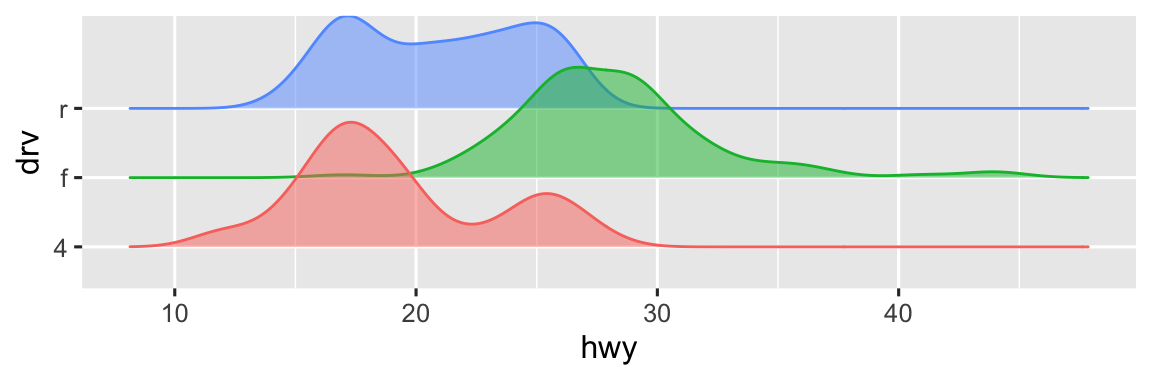
Nơi tốt nhất để có cái nhìn tổng quan toàn diện về tất cả các geom mà ggplot2 cung cấp, cũng như tất cả các function trong package, là trang tham khảo: https://ggplot2.tidyverse.org/reference. Để tìm hiểu thêm về bất kỳ geom đơn lẻ nào, hãy sử dụng trang trợ giúp (ví dụ, ?geom_smooth).
9.3.1 Bài tập
Bạn sẽ sử dụng geom nào để vẽ biểu đồ đường? Biểu đồ hộp? Biểu đồ tần suất? Biểu đồ diện tích?
-
Trước đó trong chương này chúng ta đã sử dụng
show.legendmà không giải thích nó:ggplot(mpg, aes(x = displ, y = hwy)) + geom_smooth(aes(color = drv), show.legend = FALSE)show.legend = FALSElàm gì ở đây? Điều gì xảy ra nếu bạn bỏ nó đi? Tại sao bạn nghĩ chúng ta đã sử dụng nó trước đó? Đối số
secủageom_smooth()làm gì?-
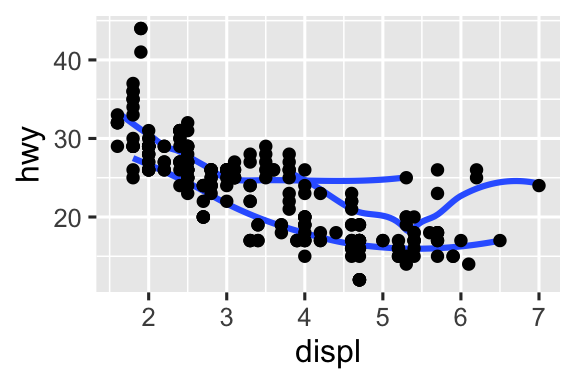
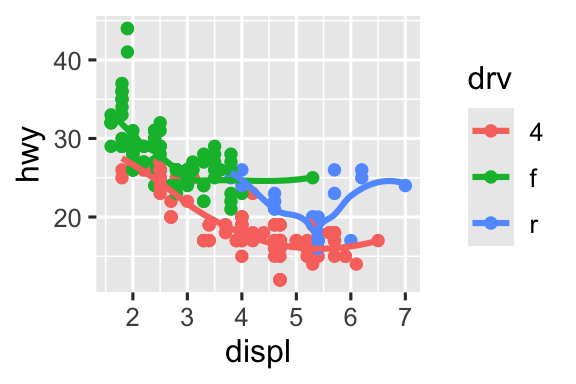
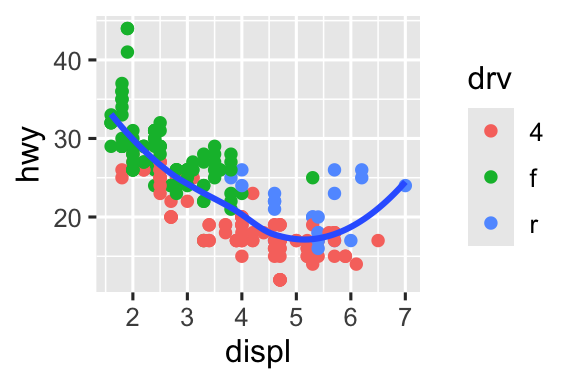
Tái tạo đoạn mã R cần thiết để tạo ra các biểu đồ sau. Lưu ý rằng bất cứ nơi nào một biến phân loại được sử dụng trong biểu đồ, đó là
drv.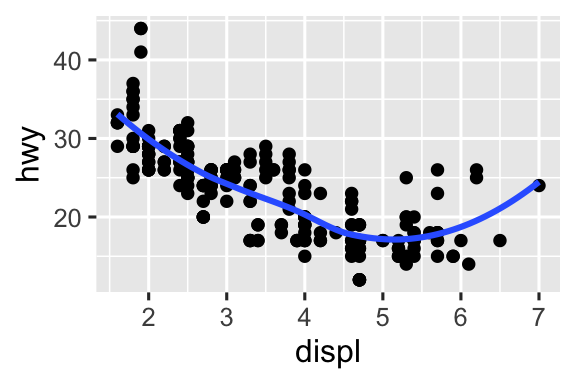
9.4 Facet
Trong Chương 1 bạn đã tìm hiểu về facet với facet_wrap(), chia một biểu đồ thành các biểu đồ con mà mỗi biểu đồ hiển thị một tập con dữ liệu dựa trên một biến phân loại.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_wrap(~cyl)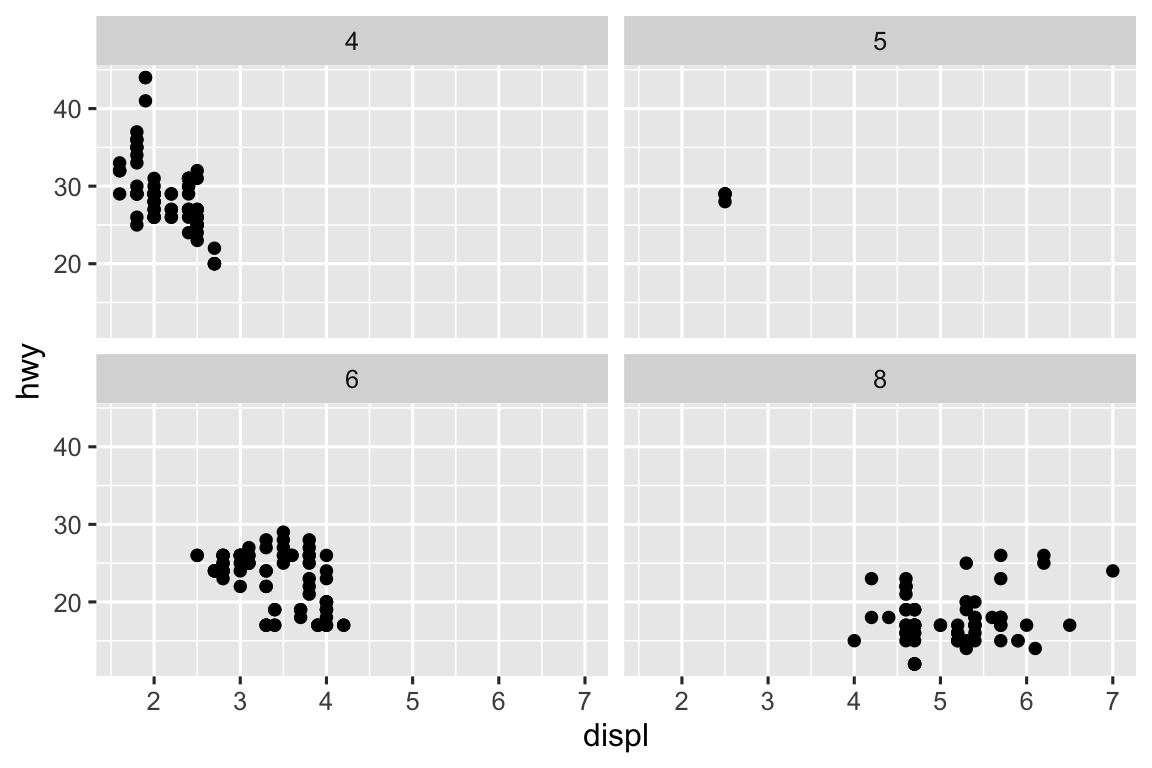
Để chia facet biểu đồ của bạn với sự kết hợp của hai biến, chuyển từ facet_wrap() sang facet_grid(). Đối số đầu tiên của facet_grid() cũng là một công thức, nhưng bây giờ nó là công thức hai vế: hàng ~ cột.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_grid(drv ~ cyl)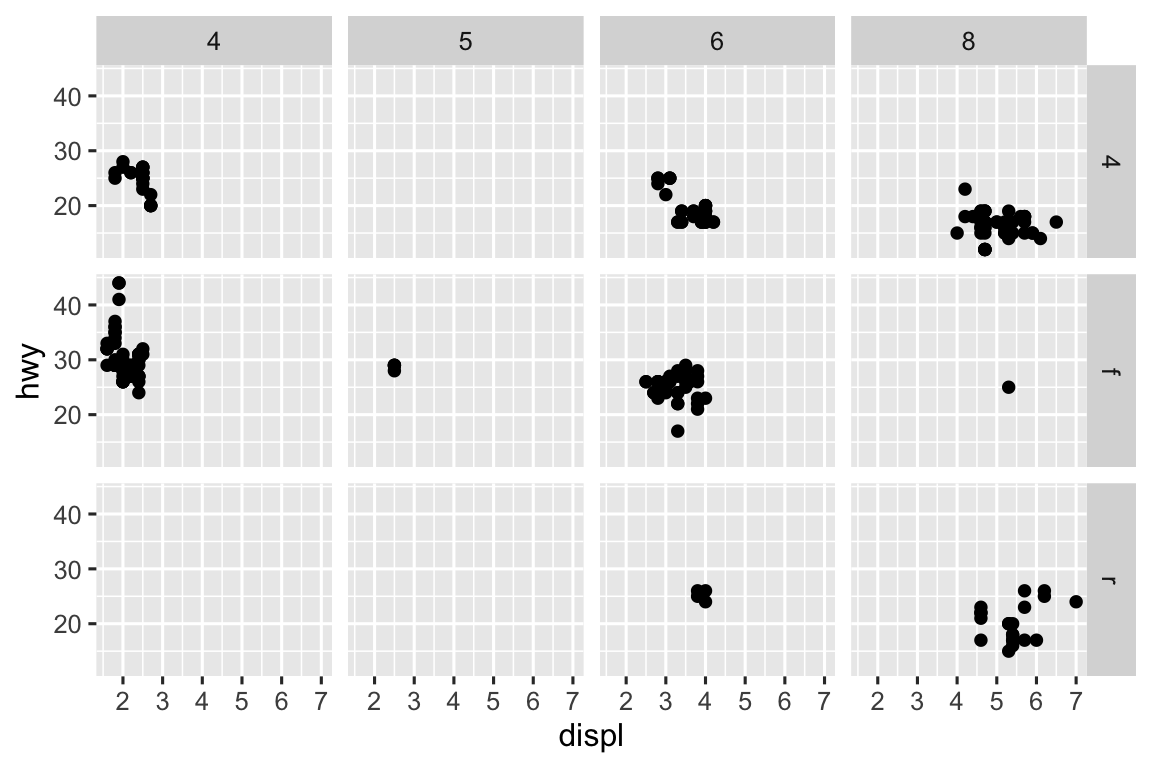
Mặc định, mỗi facet chia sẻ cùng scale và phạm vi cho trục x và y. Điều này hữu ích khi bạn muốn so sánh dữ liệu giữa các facet nhưng có thể hạn chế khi bạn muốn visualization mối quan hệ trong mỗi facet tốt hơn. Đặt argument scales trong function facet thành "free_x" sẽ cho phép các scale trục x khác nhau giữa các column, "free_y" sẽ cho phép các scale trục y khác nhau giữa các row, và "free" sẽ cho phép cả hai.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_grid(drv ~ cyl, scales = "free")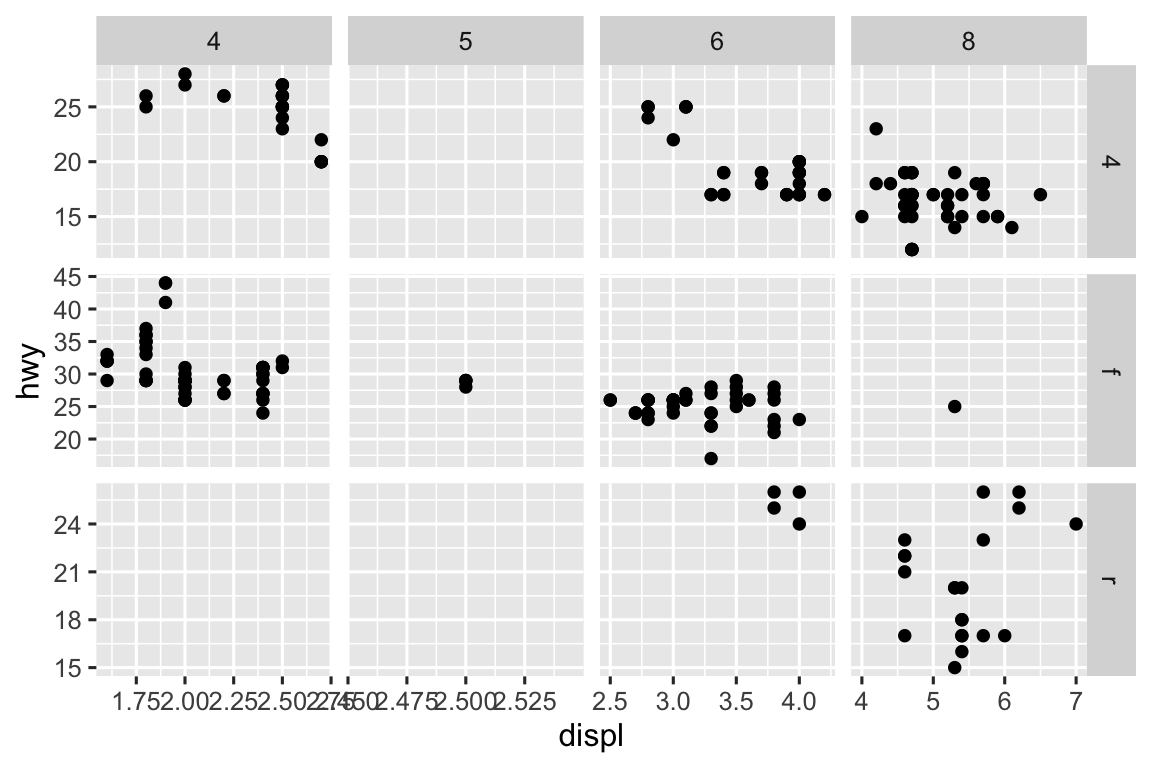
9.4.1 Bài tập
Điều gì xảy ra nếu bạn chia facet theo một biến liên tục?
-
Các ô trống trong biểu đồ ở trên với
facet_grid(drv ~ cyl)có nghĩa gì? Chạy đoạn mã sau. Chúng liên quan đến biểu đồ kết quả như thế nào?ggplot(mpg) + geom_point(aes(x = drv, y = cyl)) -
Các đoạn mã sau tạo ra biểu đồ gì?
.làm gì?ggplot(mpg) + geom_point(aes(x = displ, y = hwy)) + facet_grid(drv ~ .) ggplot(mpg) + geom_point(aes(x = displ, y = hwy)) + facet_grid(. ~ cyl) -
Xem biểu đồ facet đầu tiên trong phần này:
ggplot(mpg) + geom_point(aes(x = displ, y = hwy)) + facet_wrap(~ cyl, nrow = 2)Ưu điểm của việc sử dụng facet thay vì thuộc tính đồ họa color là gì? Nhược điểm là gì? Sự cân bằng có thể thay đổi như thế nào nếu bạn có bộ dữ liệu lớn hơn?
Đọc
?facet_wrap.nrowlàm gì?ncollàm gì? Các tùy chọn khác nào kiểm soát bố cục của các panel riêng lẻ? Tại saofacet_grid()không có argumentnrowvàncol?-
Biểu đồ nào trong các biểu đồ sau giúp dễ dàng hơn để so sánh dung tích động cơ (
displ) giữa các xe có hệ dẫn động khác nhau? Điều này cho biết gì về thời điểm nên đặt biến facet theo row hay cột?ggplot(mpg, aes(x = displ)) + geom_histogram() + facet_grid(drv ~ .) ggplot(mpg, aes(x = displ)) + geom_histogram() + facet_grid(. ~ drv) -
Tái tạo biểu đồ sau bằng
facet_wrap()thay vìfacet_grid(). Vị trí của nhãn facet thay đổi như thế nào?ggplot(mpg) + geom_point(aes(x = displ, y = hwy)) + facet_grid(drv ~ .)
9.5 Phép biến đổi thống kê
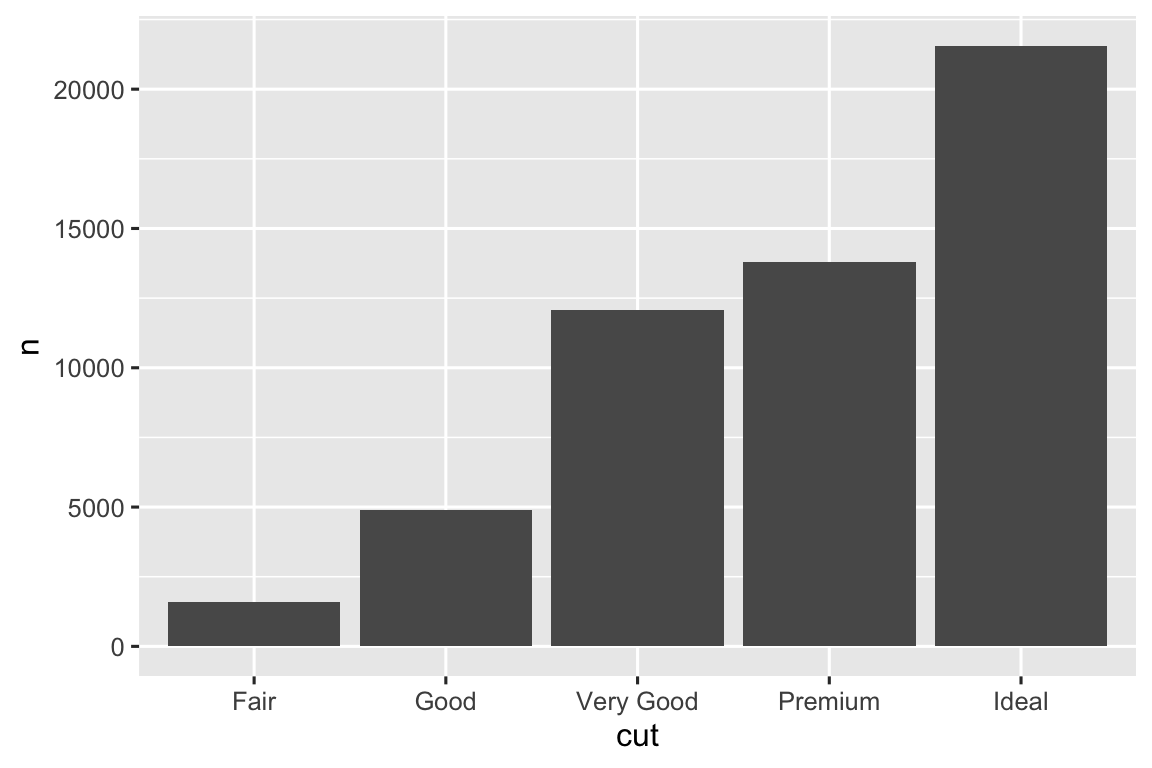
Hãy xem xét một biểu đồ column cơ bản, được vẽ với geom_bar() hoặc geom_col(). Biểu đồ sau hiển thị tổng số kim cương trong bộ dữ liệu diamonds, được nhóm theo cut. Bộ dữ liệu diamonds nằm trong package ggplot2 và chứa thông tin về ~54.000 viên kim cương, bao gồm price, carat, color, clarity, và cut của mỗi viên kim cương. Biểu đồ cho thấy nhiều kim cương hơn có sẵn với chất lượng cắt cao hơn so với chất lượng cắt thấp.
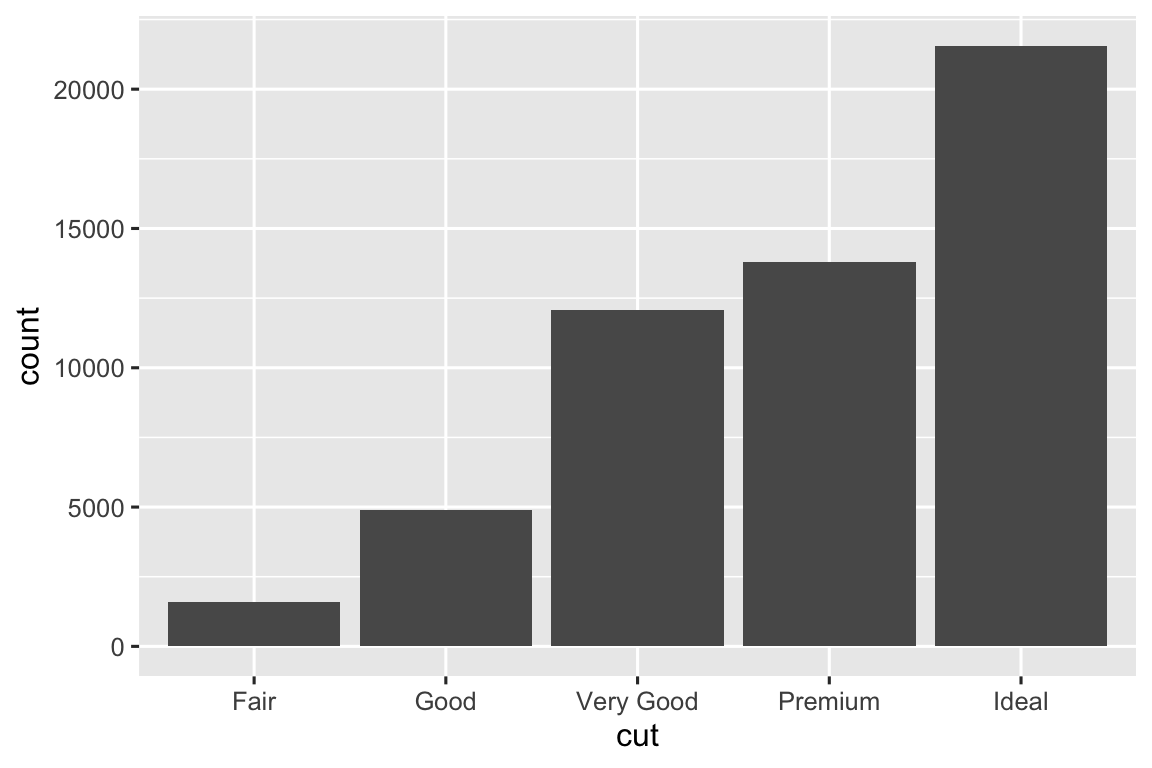
Trên trục x, biểu đồ hiển thị cut, một biến từ diamonds. Trên trục y, nó hiển thị count, nhưng count không phải là biến trong diamonds! Count đến từ đâu? Nhiều biểu đồ, như biểu đồ phân tán, vẽ các giá trị thô của bộ dữ liệu. Các biểu đồ khác, như biểu đồ column, tính toán các giá trị mới để vẽ:
Biểu đồ column, biểu đồ tần suất, và đa giác tần suất chia dữ liệu thành các khoảng và sau đó vẽ số đếm của mỗi khoảng, số điểm rơi vào mỗi khoảng.
Đường trơn khớp một mô hình với dữ liệu của bạn và sau đó vẽ các dự đoán từ mô hình.
Biểu đồ hộp tính toán tóm tắt năm số của phân phối và sau đó hiển thị tóm tắt đó dưới dạng một hộp được định dạng đặc biệt.
Thuật toán được sử dụng để tính toán các giá trị mới cho biểu đồ được gọi là stat, viết tắt của phép biến đổi thống kê (statistical transformation). Hình 9.2 cho thấy quá trình này hoạt động như thế nào với geom_bar().
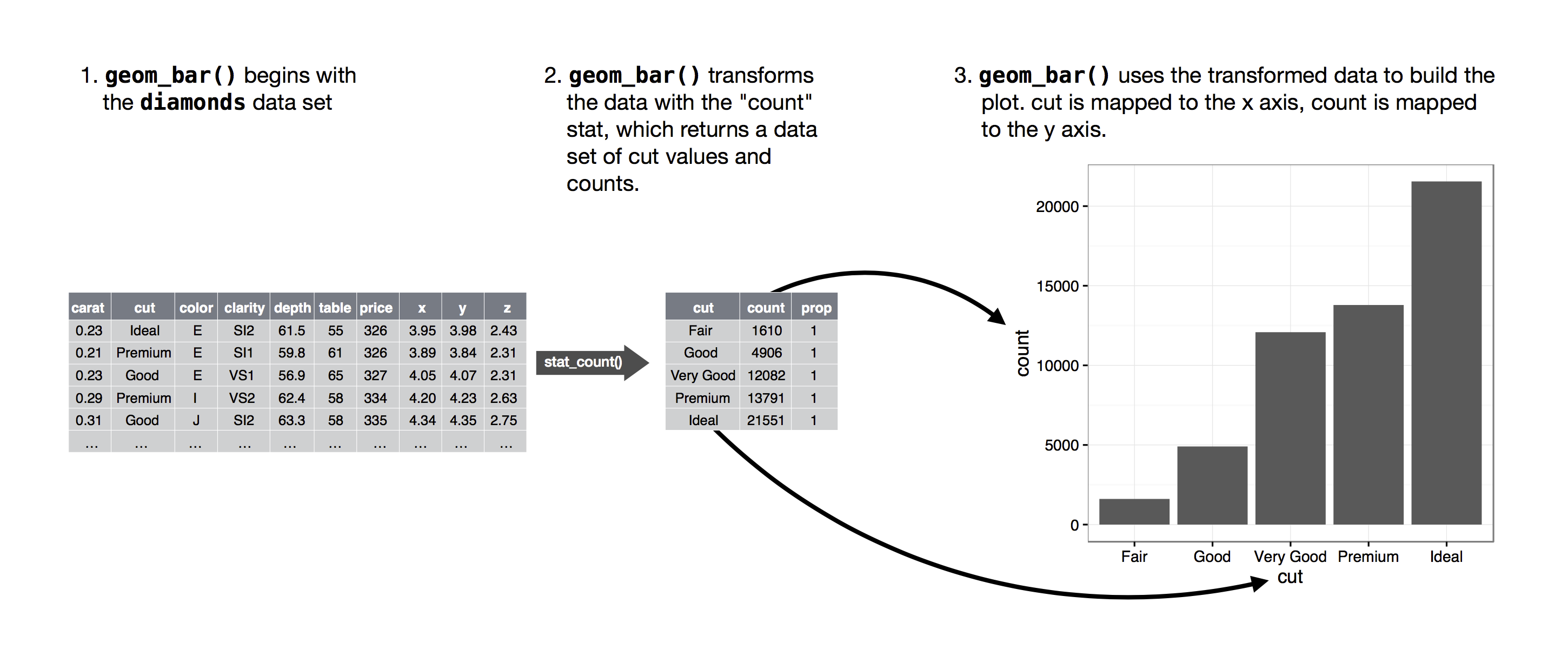
Bạn có thể biết stat nào mà một geom sử dụng bằng cách kiểm tra giá trị mặc định cho argument stat. Ví dụ, ?geom_bar cho thấy giá trị mặc định cho stat là “count”, nghĩa là geom_bar() sử dụng stat_count(). stat_count() được ghi chép trên cùng trang với geom_bar(). Nếu bạn cuộn xuống, phần có tiêu đề “Computed variables” giải thích rằng nó tính toán hai biến mới: count và prop.
Mỗi geom có một stat mặc định; và mỗi stat có một geom mặc định. Điều này có nghĩa là bạn thường có thể sử dụng các geom mà không cần lo lắng về phép biến đổi thống kê ngầm. Tuy nhiên, có ba lý do tại sao bạn có thể cần sử dụng stat một cách rõ ràng:
-
Bạn có thể muốn ghi đè stat mặc định. Trong đoạn mã dưới đây, chúng ta thay đổi stat của
geom_bar()từ count (mặc định) sang identity. Điều này cho phép chúng ta mapping chiều cao của các thanh đến giá trị thô của biến y. -
Bạn có thể muốn ghi đè mapping mặc định từ biến đã biến đổi đến thuộc tính đồ họa. Ví dụ, bạn có thể muốn hiển thị biểu đồ column tỷ lệ thay vì số đếm:
ggplot(diamonds, aes(x = cut, y = after_stat(prop), group = 1)) + geom_bar()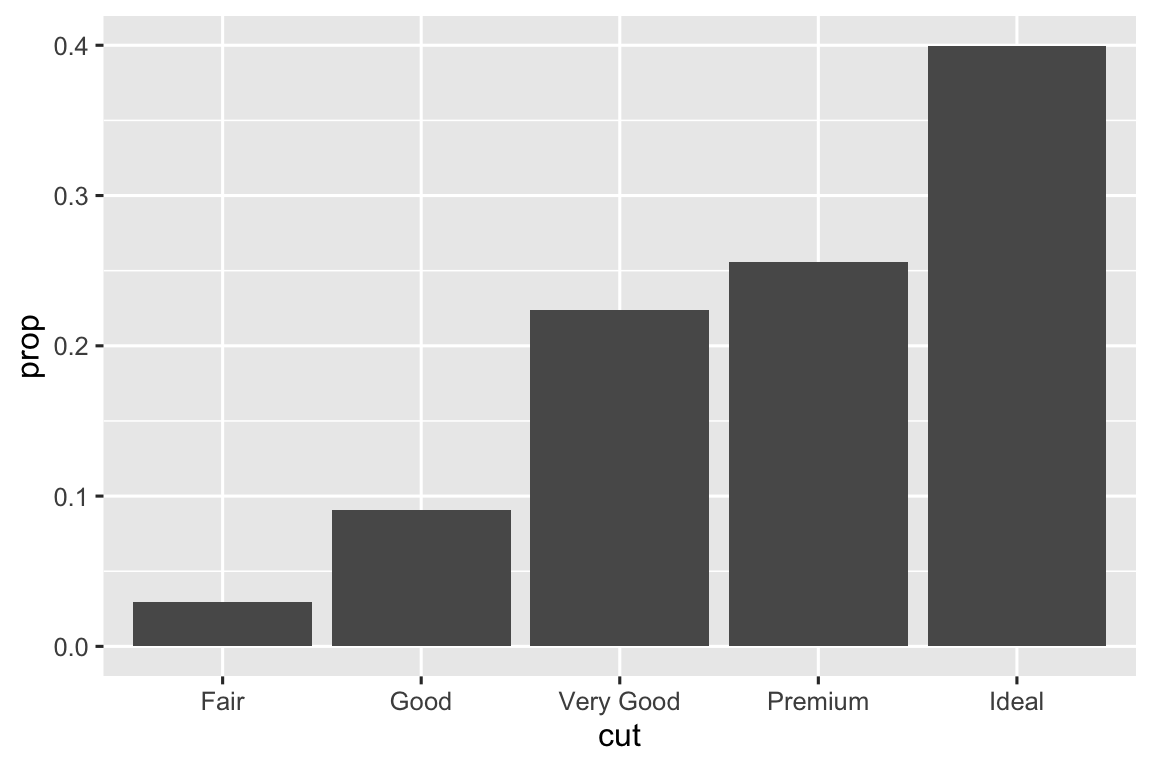
Để tìm các biến có thể được tính toán bởi stat, hãy tìm phần có tiêu đề “computed variables” trong trang trợ giúp cho
geom_bar(). -
Bạn có thể muốn thu hút sự chú ý nhiều hơn đến phép biến đổi thống kê trong mã của bạn. Ví dụ, bạn có thể sử dụng
stat_summary(), tóm tắt các giá trị y cho mỗi giá trị x duy nhất, để thu hút sự chú ý đến phần tóm tắt mà bạn đang tính toán:ggplot(diamonds) + stat_summary( aes(x = cut, y = depth), fun.min = min, fun.max = max, fun = median )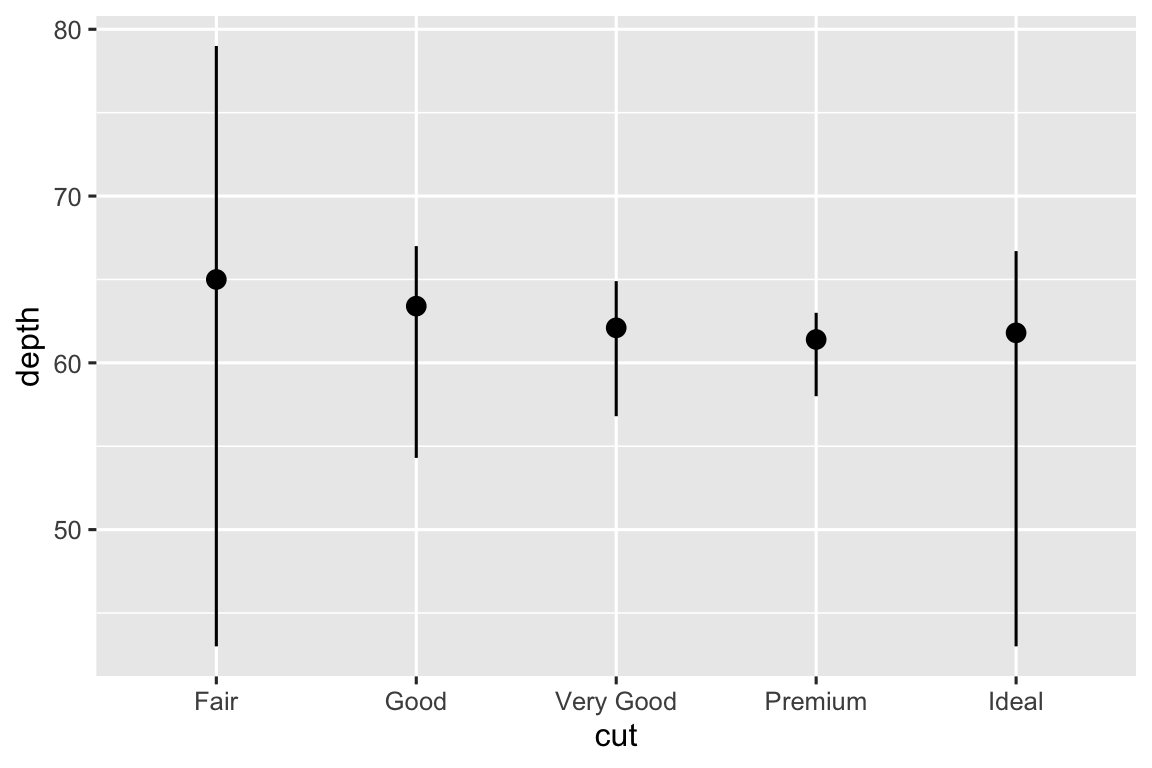
ggplot2 cung cấp hơn 20 stat cho bạn sử dụng. Mỗi stat là một function, vì vậy bạn có thể xem trợ giúp theo cách thông thường, ví dụ ?stat_bin.
9.5.1 Bài tập
Geom mặc định liên kết với
stat_summary()là gì? Bạn có thể viết lại biểu đồ trước đó để sử dụng function geom đó thay vì function stat như thế nào?geom_col()làm gì? Nó khác gì so vớigeom_bar()?Hầu hết các geom và stat đi theo cặp gần như luôn được sử dụng cùng nhau. Hãy liệt kê tất cả các cặp. Chúng có điểm gì chung? (Gợi ý: Đọc qua tài liệu.)
stat_smooth()tính toán những biến nào? Những argument nào kiểm soát hành vi của nó?-
Trong biểu đồ column tỷ lệ của chúng ta, chúng ta cần đặt
group = 1. Tại sao? Nói cách khác, vấn đề với hai biểu đồ sau là gì?ggplot(diamonds, aes(x = cut, y = after_stat(prop))) + geom_bar() ggplot(diamonds, aes(x = cut, fill = color, y = after_stat(prop))) + geom_bar()
9.6 Điều chỉnh vị trí
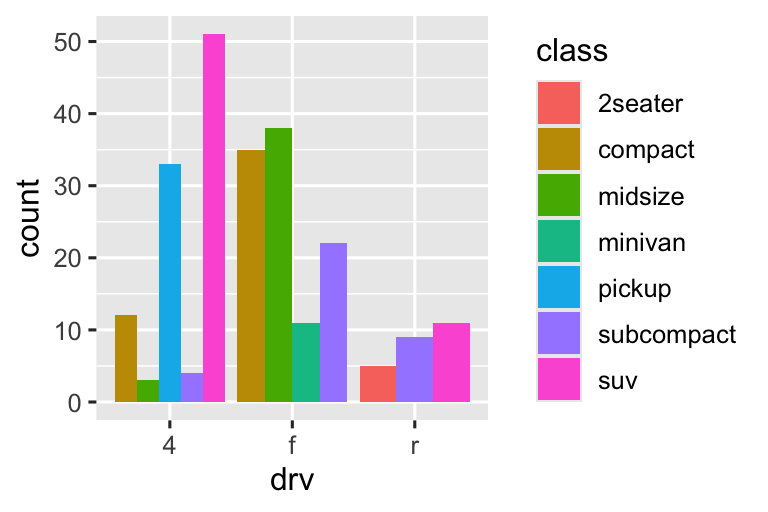
Còn một phép thuật nữa liên quan đến biểu đồ column. Bạn có thể tô màu biểu đồ column bằng thuộc tính đồ họa color, hoặc hữu ích hơn, thuộc tính đồ họa fill:
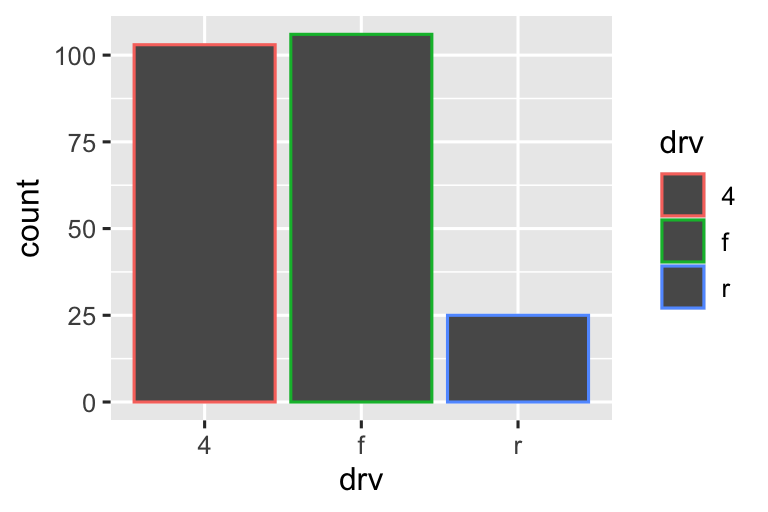
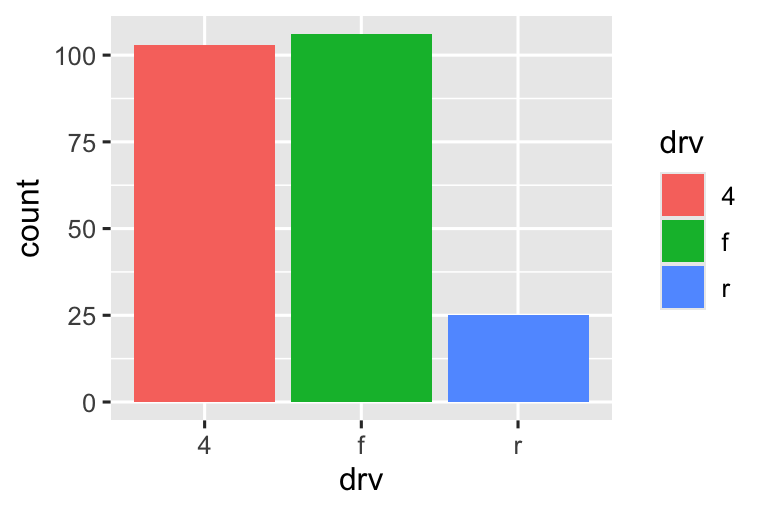
Lưu ý điều gì xảy ra nếu bạn mapping thuộc tính đồ họa fill đến một biến khác, như class: các thanh tự động được xếp chồng. Mỗi hình chữ nhật có màu đại diện cho một sự kết hợp của drv và class.
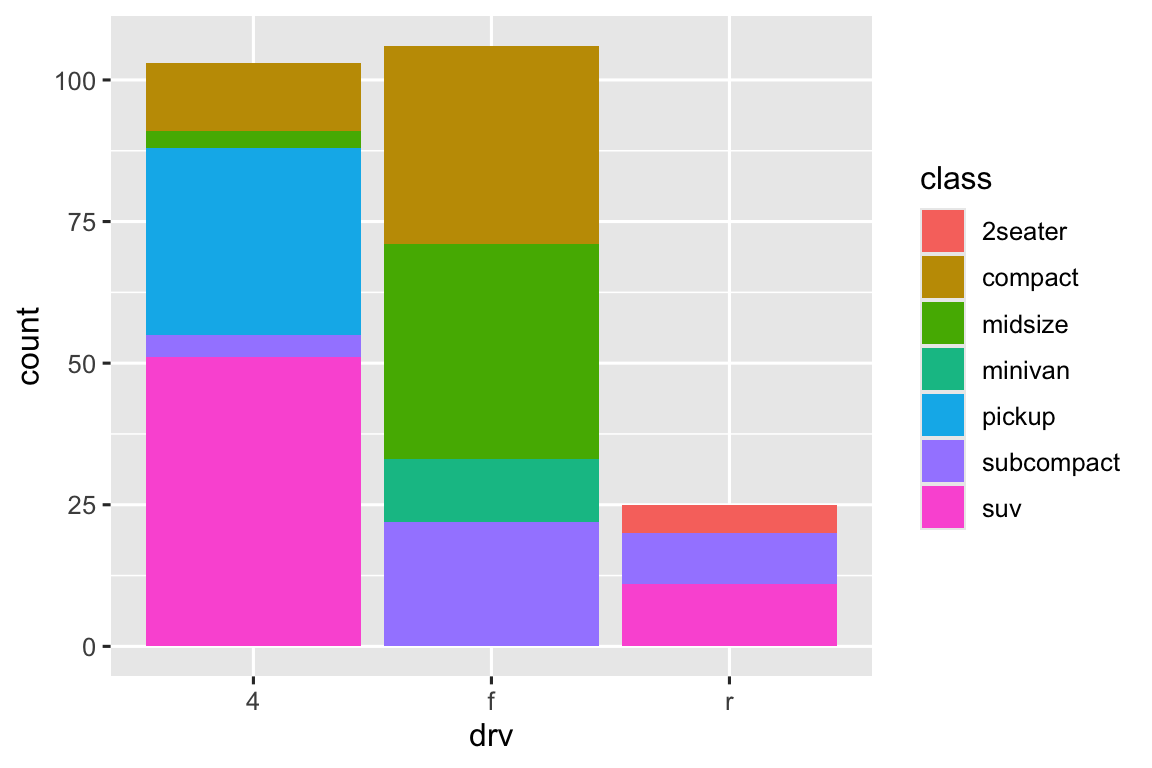
Việc xếp chồng được thực hiện tự động bằng điều chỉnh vị trí được chỉ định bởi argument position. Nếu bạn không muốn biểu đồ column xếp chồng, bạn có thể sử dụng một trong ba tùy chọn khác: "identity", "dodge" hoặc "fill".
-
position = "identity"sẽ đặt mỗi đối tượng chính xác tại vị trí nó rơi trong ngữ cảnh của biểu đồ. Điều này không hữu ích lắm cho các thanh, vì nó chồng chéo chúng. Để thấy sự chồng chéo đó, chúng ta cần làm các thanh hơi trong suốt bằng cách đặtalphathành một giá trị nhỏ, hoặc hoàn toàn trong suốt bằng cách đặtfill = NA.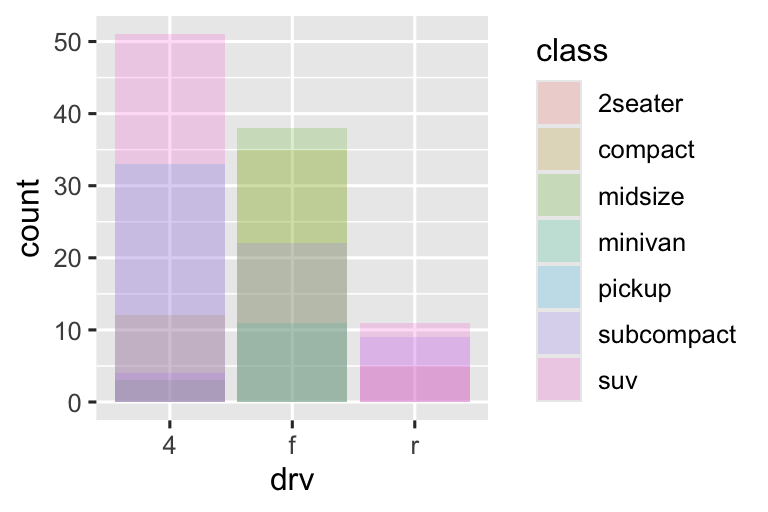
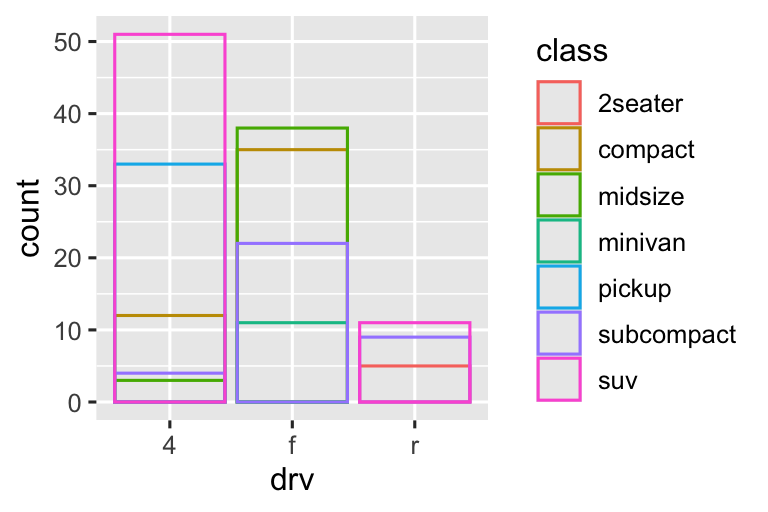
Điều chỉnh vị trí identity hữu ích hơn cho các geom 2d, như điểm, nơi nó là mặc định.
position = "fill"hoạt động giống như xếp chồng, nhưng làm cho mỗi tập hợp thanh xếp chồng có cùng chiều cao. Điều này giúp dễ dàng hơn để so sánh tỷ lệ giữa các nhóm.-
position = "dodge"đặt các đối tượng chồng chéo trực tiếp cạnh nhau. Điều này giúp dễ dàng hơn để so sánh các giá trị riêng lẻ.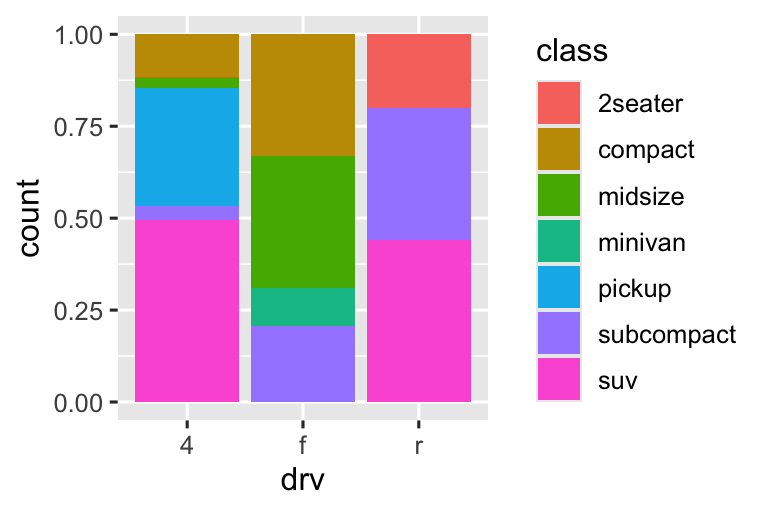
Có một loại điều chỉnh khác không hữu ích cho biểu đồ column, nhưng có thể rất hữu ích cho biểu đồ phân tán. Hãy nhớ lại biểu đồ phân tán đầu tiên của chúng ta. Bạn có nhận ra rằng biểu đồ chỉ hiển thị 126 điểm, mặc dù có 234 quan sát trong bộ dữ liệu không?
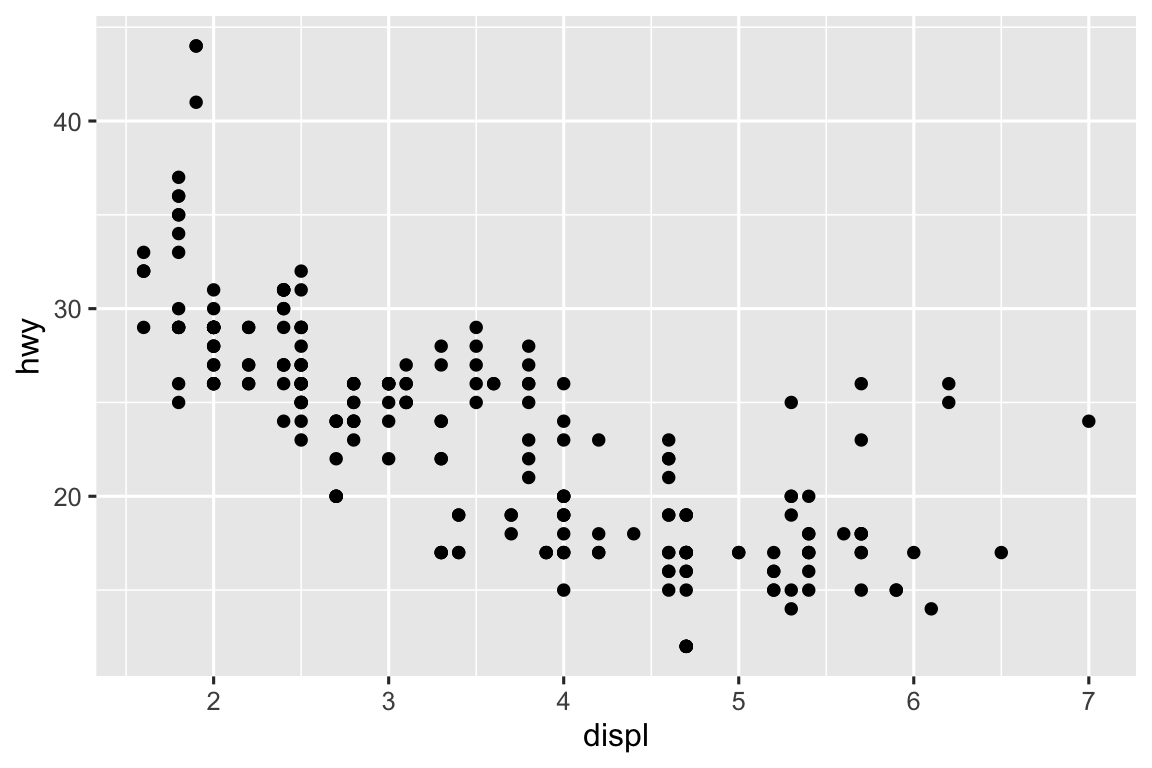
Các giá trị cơ bản của hwy và displ được làm tròn nên các điểm xuất hiện trên một lưới và nhiều điểm chồng chéo lên nhau. Vấn đề này được gọi là chồng chéo điểm (overplotting). Sự sắp xếp này gây khó khăn cho việc nhận biết phân phối của dữ liệu. Các điểm dữ liệu phân bố đều khắp biểu đồ, hay có một sự kết hợp đặc biệt nào đó của hwy và displ chứa 109 giá trị?
Bạn có thể tránh việc tạo lưới này bằng cách đặt điều chỉnh vị trí thành “jitter”. position = "jitter" thêm một lượng nhỏ nhiễu ngẫu nhiên vào mỗi điểm. Điều này phân tán các điểm ra vì không có hai điểm nào có khả năng nhận được cùng lượng nhiễu ngẫu nhiên.
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(position = "jitter")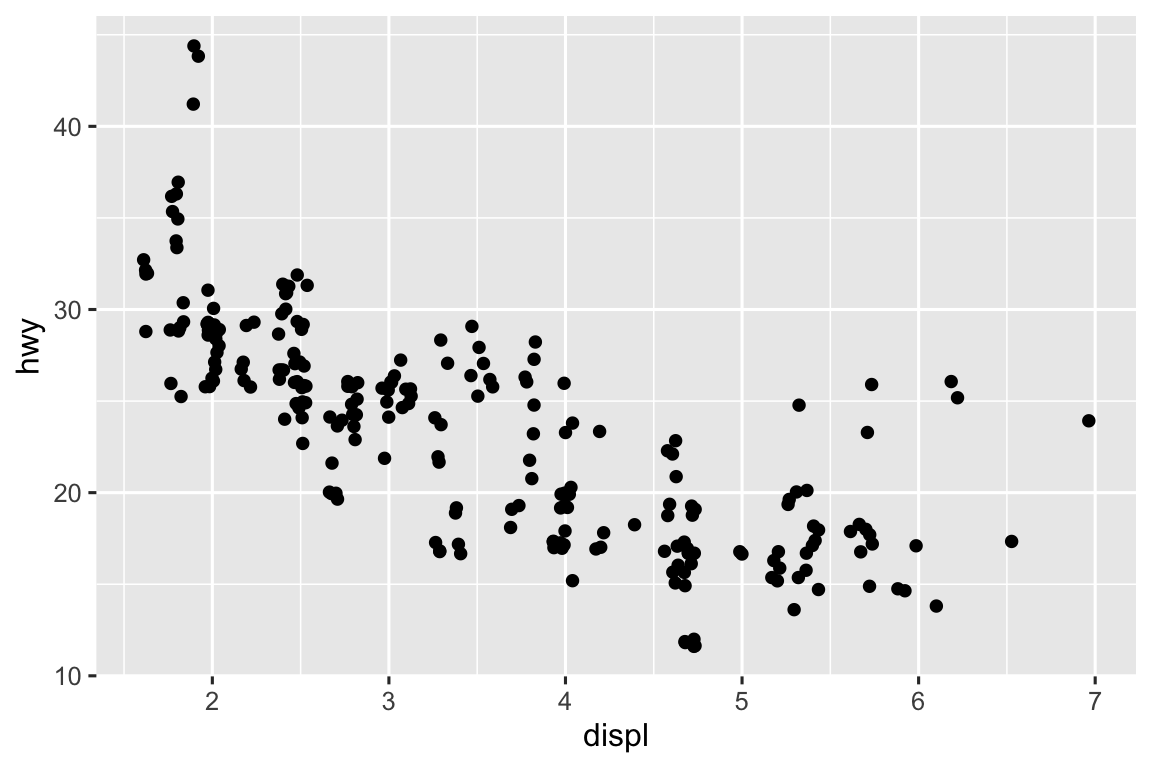
Thêm ngẫu nhiên có vẻ là cách kỳ lạ để cải thiện biểu đồ, nhưng mặc dù nó làm biểu đồ của bạn kém chính xác hơn ở quy mô nhỏ, nó làm biểu đồ hiệu quả hơn ở quy mô lớn. Vì đây là thao tác rất hữu ích, ggplot2 đi kèm với cách viết tắt cho geom_point(position = "jitter"): geom_jitter().
Để tìm hiểu thêm về điều chỉnh vị trí, hãy xem trang trợ giúp liên quan đến mỗi điều chỉnh: ?position_dodge, ?position_fill, ?position_identity, ?position_jitter, và ?position_stack.
9.6.1 Bài tập
-
Vấn đề với biểu đồ sau là gì? Bạn có thể cải thiện nó như thế nào?
ggplot(mpg, aes(x = cty, y = hwy)) + geom_point() -
Có sự khác biệt nào giữa hai biểu đồ sau không? Tại sao?
ggplot(mpg, aes(x = displ, y = hwy)) + geom_point() ggplot(mpg, aes(x = displ, y = hwy)) + geom_point(position = "identity") Những parameter nào của
geom_jitter()kiểm soát lượng jitter?So sánh và đối chiếu
geom_jitter()vớigeom_count().Điều chỉnh vị trí mặc định cho
geom_boxplot()là gì? Tạo một biểu đồ visualization bộ dữ liệumpgđể minh họa điều đó.
9.7 Hệ tọa độ
Hệ tọa độ có lẽ là phần phức tạp nhất của ggplot2. Hệ tọa độ mặc định là hệ tọa độ Descartes (Cartesian) trong đó vị trí x và y hoạt động độc lập để xác định vị trí của mỗi điểm. Có hai hệ tọa độ khác đôi khi hữu ích.
-
coord_quickmap()đặt tỷ lệ khung hình chính xác cho bản đồ địa lý. Điều này rất quan trọng nếu bạn đang vẽ dữ liệu không gian với ggplot2. Chúng ta không có đủ không gian để thảo luận về bản đồ trong cuốn sách này, nhưng bạn có thể tìm hiểu thêm trong chương Maps của ggplot2: Elegant graphics for data analysis.nz <- map_data("nz") ggplot(nz, aes(x = long, y = lat, group = group)) + geom_polygon(fill = "white", color = "black") ggplot(nz, aes(x = long, y = lat, group = group)) + geom_polygon(fill = "white", color = "black") + coord_quickmap()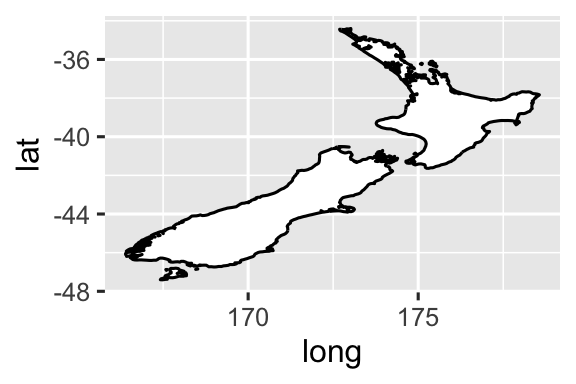
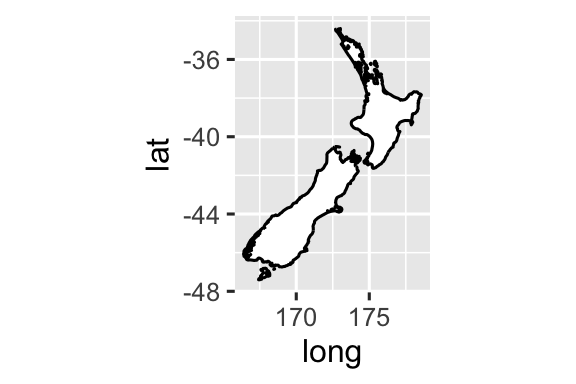
-
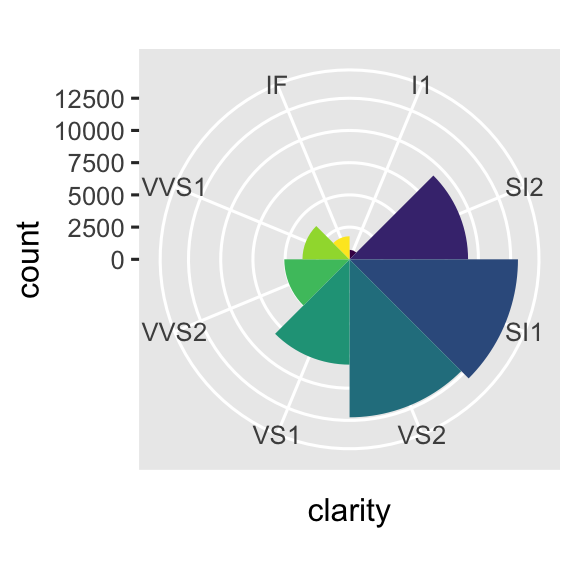
coord_polar()sử dụng tọa độ cực. Tọa độ cực cho thấy một mối liên hệ thú vị giữa biểu đồ column và biểu đồ Coxcomb.bar <- ggplot(data = diamonds) + geom_bar( mapping = aes(x = clarity, fill = clarity), show.legend = FALSE, width = 1 ) + theme(aspect.ratio = 1) bar + coord_flip() bar + coord_polar()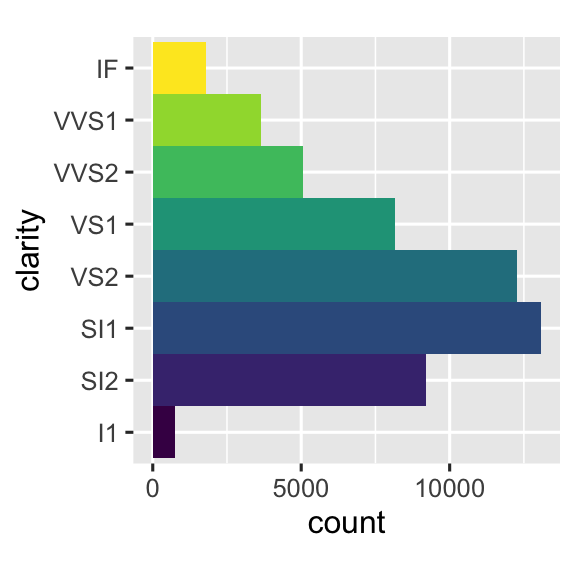
9.7.1 Bài tập
Biến một biểu đồ column xếp chồng thành biểu đồ tròn bằng
coord_polar().Sự khác biệt giữa
coord_quickmap()vàcoord_map()là gì?-
Biểu đồ sau cho bạn biết gì về mối quan hệ giữa mpg thành phố và đường cao tốc? Tại sao
coord_fixed()quan trọng?geom_abline()làm gì?ggplot(data = mpg, mapping = aes(x = cty, y = hwy)) + geom_point() + geom_abline() + coord_fixed()
9.8 Ngữ pháp đồ họa theo lớp
Chúng ta có thể mở rộng mẫu biểu đồ mà bạn đã học trong Phần 1.3 bằng cách thêm điều chỉnh vị trí, stat, hệ tọa độ, và facet:
ggplot(data = <DATA>) +
<GEOM_FUNCTION>(
mapping = aes(<MAPPINGS>),
stat = <STAT>,
position = <POSITION>
) +
<COORDINATE_FUNCTION> +
<FACET_FUNCTION>Mẫu mới của chúng ta nhận bảy parameter, các từ trong ngoặc nhọn xuất hiện trong mẫu. Trong thực tế, bạn hiếm khi cần cung cấp đủ bảy parameter để tạo biểu đồ vì ggplot2 sẽ cung cấp các giá trị mặc định hữu ích cho mọi thứ ngoại trừ dữ liệu, mapping, và function geom.
Bảy parameter trong mẫu tạo thành ngữ pháp đồ họa, một hệ thống hình thức để xây dựng biểu đồ. Ngữ pháp đồ họa dựa trên nhận thức rằng bạn có thể mô tả duy nhất bất kỳ biểu đồ nào như sự kết hợp của một bộ dữ liệu, một geom, một tập hợp mapping, một stat, một điều chỉnh vị trí, một hệ tọa độ, một sơ đồ facet, và một theme.
Để thấy cách thức hoạt động, hãy xem xét cách bạn có thể xây dựng một biểu đồ cơ bản từ đầu: bạn có thể bắt đầu với một bộ dữ liệu và sau đó biến đổi nó thành thông tin mà bạn muốn hiển thị (bằng stat). Tiếp theo, bạn có thể chọn một geom để biểu diễn mỗi quan sát trong dữ liệu đã biến đổi. Sau đó bạn có thể sử dụng các thuộc tính đồ họa của geom để biểu diễn các biến trong dữ liệu. Bạn sẽ mapping các giá trị của mỗi biến đến các mức của thuộc tính đồ họa. Các bước này được minh họa trong Hình 9.3. Sau đó bạn sẽ chọn một hệ tọa độ để đặt các geom vào, sử dụng vị trí của các đối tượng (bản thân nó là một thuộc tính đồ họa) để hiển thị giá trị của biến x và y.
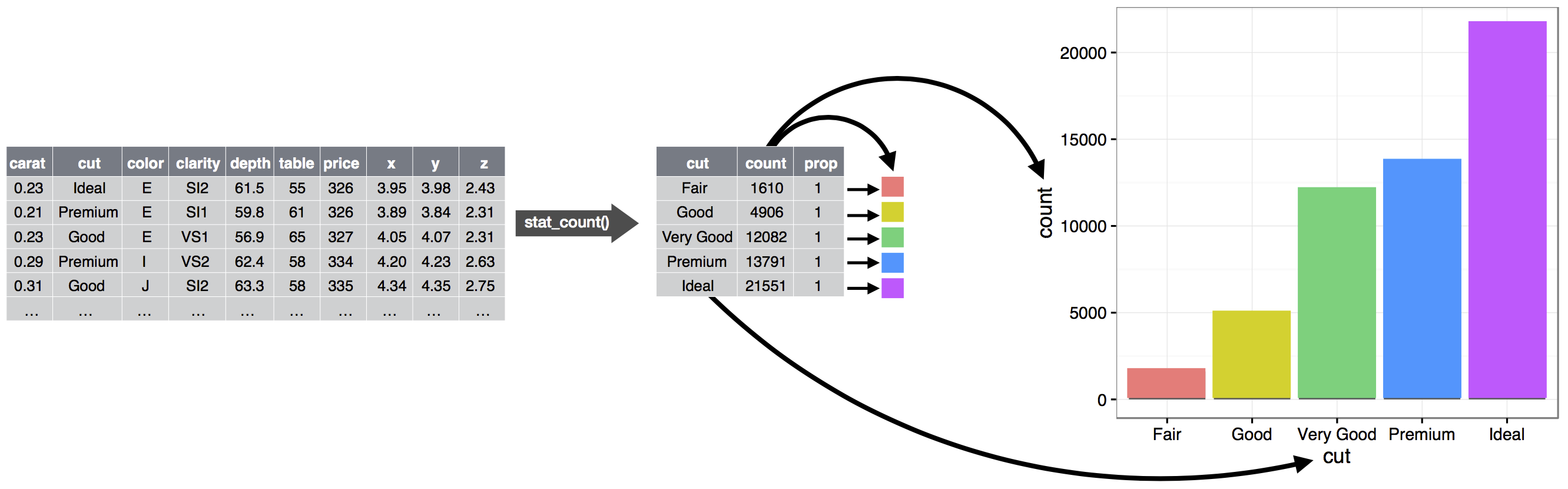
Tại thời điểm này, bạn sẽ có một biểu đồ hoàn chỉnh, nhưng bạn có thể điều chỉnh thêm vị trí của các geom trong hệ tọa độ (điều chỉnh vị trí) hoặc chia biểu đồ thành các biểu đồ con (facet). Bạn cũng có thể mở rộng biểu đồ bằng cách thêm một hoặc nhiều lớp bổ sung, trong đó mỗi lớp bổ sung sử dụng một bộ dữ liệu, một geom, một tập hợp mapping, một stat, và một điều chỉnh vị trí.
Bạn có thể sử dụng phương pháp này để xây dựng bất kỳ biểu đồ nào mà bạn tưởng tượng. Nói cách khác, bạn có thể sử dụng mẫu mã mà bạn đã học trong chương này để xây dựng row trăm nghìn biểu đồ độc đáo.
Nếu bạn muốn tìm hiểu thêm về nền tảng lý thuyết của ggplot2, bạn có thể thích đọc “The Layered Grammar of Graphics”, bài báo khoa học mô tả chi tiết lý thuyết của ggplot2.
9.9 Tóm tắt
Trong chương này bạn đã tìm hiểu về ngữ pháp đồ họa theo lớp bắt đầu với thuộc tính đồ họa và đối tượng hình học để xây dựng biểu đồ đơn giản, facet để chia biểu đồ thành các tập con, thống kê để hiểu cách geom được tính toán, điều chỉnh vị trí để kiểm soát các chi tiết vị trí khi các geom có thể chồng chéo, và hệ tọa độ cho phép bạn thay đổi căn bản ý nghĩa của x và y. Một lớp mà chúng ta chưa đề cập đến là theme (theme), sẽ được giới thiệu trong Phần 11.5.
Hai tài nguyên rất hữu ích để có cái nhìn tổng quan về toàn bộ chức năng của ggplot2 là bảng tóm tắt ggplot2 (bạn có thể tìm tại https://posit.co/resources/cheatsheets) và trang web package ggplot2 (https://ggplot2.tidyverse.org).
Một bài học quan trọng mà bạn nên rút ra từ chương này là khi bạn cảm thấy cần một geom mà ggplot2 không cung cấp, luôn là ý tưởng tốt để xem liệu ai đó đã giải quyết vấn đề của bạn chưa bằng cách tạo một package ggplot2 cung cấp geom đó.