16 Nhân tố
16.1 Giới thiệu
Nhân tố (factor) được sử dụng cho các biến phân loại (categorical variable), tức là các biến có một tập hợp giá trị khả dĩ cố định và đã biết trước. Chúng cũng hữu ích khi bạn muốn hiển thị các vector ký tự theo thứ tự không phải bảng chữ cái.
Chúng ta sẽ bắt đầu bằng việc giải thích tại sao factor cần thiết cho phân tích dữ liệu1 và cách bạn có thể tạo chúng với factor(). Sau đó chúng ta sẽ giới thiệu tập dữ liệu gss_cat chứa một loạt biến phân loại để bạn thử nghiệm. Tiếp theo bạn sẽ sử dụng tập dữ liệu đó để thực hành thay đổi thứ tự và giá trị của các factor, trước khi kết thúc bằng phần thảo luận về factor có thứ tự (ordered factor).
16.1.1 Điều kiện tiên quyết
base R cung cấp một số công cụ cơ bản để tạo và thao tác với factor. Chúng ta sẽ bổ sung thêm với package forcats, là một phần của tidyverse cốt lõi. Gói mở rộng này cung cấp các công cụ để xử lý các biến phân loại (categorical) bằng một loạt các function hỗ trợ để làm việc với factor.
16.2 Kiến thức cơ bản về factor
Hãy tưởng tượng bạn có một biến ghi lại tháng:
x1 <- c("Dec", "Apr", "Jan", "Mar")Sử dụng string để ghi lại biến này có hai vấn đề:
-
Chỉ có mười hai tháng hợp lệ, và không có gì ngăn bạn khỏi lỗi đánh máy:
x2 <- c("Dec", "Apr", "Jam", "Mar") -
Nó không sắp xếp theo cách hữu ích:
sort(x1) #> [1] "Apr" "Dec" "Jan" "Mar"
Bạn có thể khắc phục cả hai vấn đề này với factor. Để tạo một factor, bạn phải bắt đầu bằng việc tạo list các mức (level) hợp lệ:
month_levels <- c(
"Jan", "Feb", "Mar", "Apr", "May", "Jun",
"Jul", "Aug", "Sep", "Oct", "Nov", "Dec"
)Bây giờ bạn có thể tạo một factor:
Và bất kỳ giá trị nào không nằm trong list mức sẽ được tự động chuyển thành NA:
y2 <- factor(x2, levels = month_levels)
y2
#> [1] Dec Apr <NA> Mar
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov DecĐiều này có vẻ rủi ro, nên bạn có thể muốn sử dụng forcats::fct() thay thế:
y2 <- fct(x2, levels = month_levels)
#> Error in `fct()`:
#> ! All values of `x` must appear in `levels` or `na`
#> ℹ Missing level: "Jam"Nếu bạn bỏ qua các mức, chúng sẽ được lấy từ dữ liệu theo thứ tự bảng chữ cái:
factor(x1)
#> [1] Dec Apr Jan Mar
#> Levels: Apr Dec Jan MarSắp xếp theo bảng chữ cái có phần rủi ro vì không phải máy tính nào cũng sắp xếp string theo cùng một cách. Vì vậy forcats::fct() sắp xếp theo thứ tự xuất hiện đầu tiên:
fct(x1)
#> [1] Dec Apr Jan Mar
#> Levels: Dec Apr Jan MarNếu bạn cần truy cập trực tiếp tập hợp các mức hợp lệ, bạn có thể làm điều đó với levels():
levels(y2)
#> [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"Bạn cũng có thể tạo factor khi đọc dữ liệu với readr bằng col_factor():
csv <- "
month,value
Jan,12
Feb,56
Mar,12"
df <- read_csv(csv, col_types = cols(month = col_factor(month_levels)))
#> Warning: The `file` argument of `read_csv()` should use `I()` for literal data as of
#> readr 2.2.0.
#>
#> # Bad (for example):
#> read_csv("x,y\n1,2")
#>
#> # Good:
#> read_csv(I("x,y\n1,2"))
df$month
#> [1] Jan Feb Mar
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec16.3 Khảo sát Xã hội Tổng quát
Trong phần còn lại của chương này, chúng ta sẽ sử dụng forcats::gss_cat. Đây là một mẫu dữ liệu từ Khảo sát Xã hội Tổng quát (General Social Survey), một cuộc khảo sát lâu dài tại Mỹ được thực hiện bởi tổ chức nghiên cứu độc lập NORC tại Đại học Chicago. Cuộc khảo sát có row nghìn câu hỏi, vì vậy trong gss_cat Hadley đã chọn một số câu hỏi minh họa cho các thách thức phổ biến mà bạn sẽ gặp khi làm việc với factor.
gss_cat
#> # A tibble: 21,483 × 9
#> year marital age race rincome partyid
#> <int> <fct> <int> <fct> <fct> <fct>
#> 1 2000 Never married 26 White $8000 to 9999 Ind,near rep
#> 2 2000 Divorced 48 White $8000 to 9999 Not str republican
#> 3 2000 Widowed 67 White Not applicable Independent
#> 4 2000 Never married 39 White Not applicable Ind,near rep
#> 5 2000 Divorced 25 White Not applicable Not str democrat
#> 6 2000 Married 25 White $20000 - 24999 Strong democrat
#> # ℹ 21,477 more rows
#> # ℹ 3 more variables: relig <fct>, denom <fct>, tvhours <int>(Hãy nhớ rằng, vì tập dữ liệu này được cung cấp bởi một package, bạn có thể xem thêm thông tin về các biến với ?gss_cat.)
Khi factor được lưu trong một tibble, bạn không thể dễ dàng nhìn thấy các mức của chúng. Một cách để xem chúng là dùng count():
gss_cat |>
count(race)
#> # A tibble: 3 × 2
#> race n
#> <fct> <int>
#> 1 Other 1959
#> 2 Black 3129
#> 3 White 16395Khi làm việc với factor, hai thao tác phổ biến nhất là thay đổi thứ tự các mức và thay đổi giá trị của các mức. Các thao tác đó được mô tả trong các phần bên dưới.
16.3.1 Bài tập
Khám phá phân phối của
rincome(thu nhập được báo cáo). Điều gì khiến biểu đồ column mặc định khó hiểu? Bạn có thể cải thiện biểu đồ như thế nào?religphổ biến nhất trong khảo sát này là gì?partyidphổ biến nhất là gì?denom(giáo phái) áp dụng chorelignào? Bạn có thể tìm ra bằng bảng như thế nào? Bạn có thể tìm ra bằng visualization như thế nào?
16.4 Thay đổi thứ tự factor
Việc thay đổi thứ tự các mức factor trong biểu đồ thường rất hữu ích. Ví dụ, hãy tưởng tượng bạn muốn khám phá số giờ trung bình xem TV mỗi ngày theo các tôn giáo:
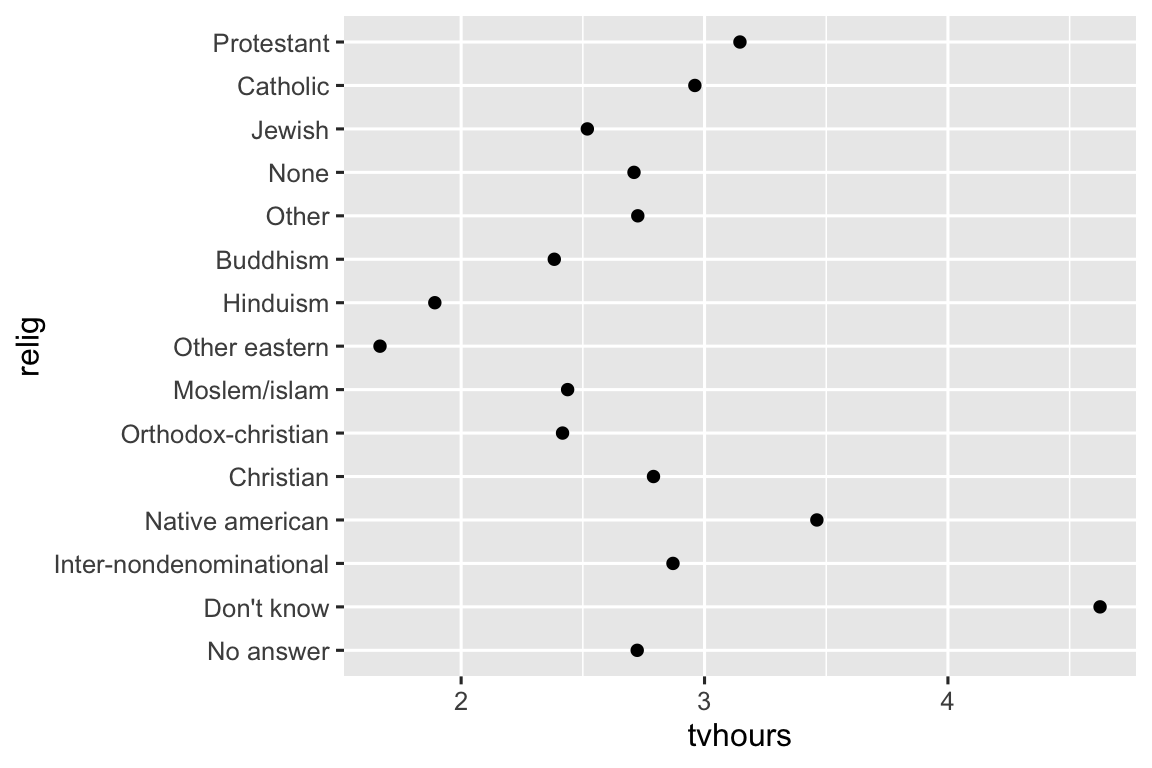
Biểu đồ này khó đọc vì không có mô hình tổng thể nào. Chúng ta có thể cải thiện nó bằng cách sắp xếp lại các mức của relig sử dụng fct_reorder(). fct_reorder() nhận ba argument:
-
.f, factor mà bạn muốn thay đổi các mức. -
.x, một vector số mà bạn muốn dùng để sắp xếp lại các mức. - Tùy chọn,
.fun, một function được sử dụng nếu có nhiều giá trị.xcho mỗi giá trị.f. Giá trị mặc định làmedian.
ggplot(relig_summary, aes(x = tvhours, y = fct_reorder(relig, tvhours))) +
geom_point()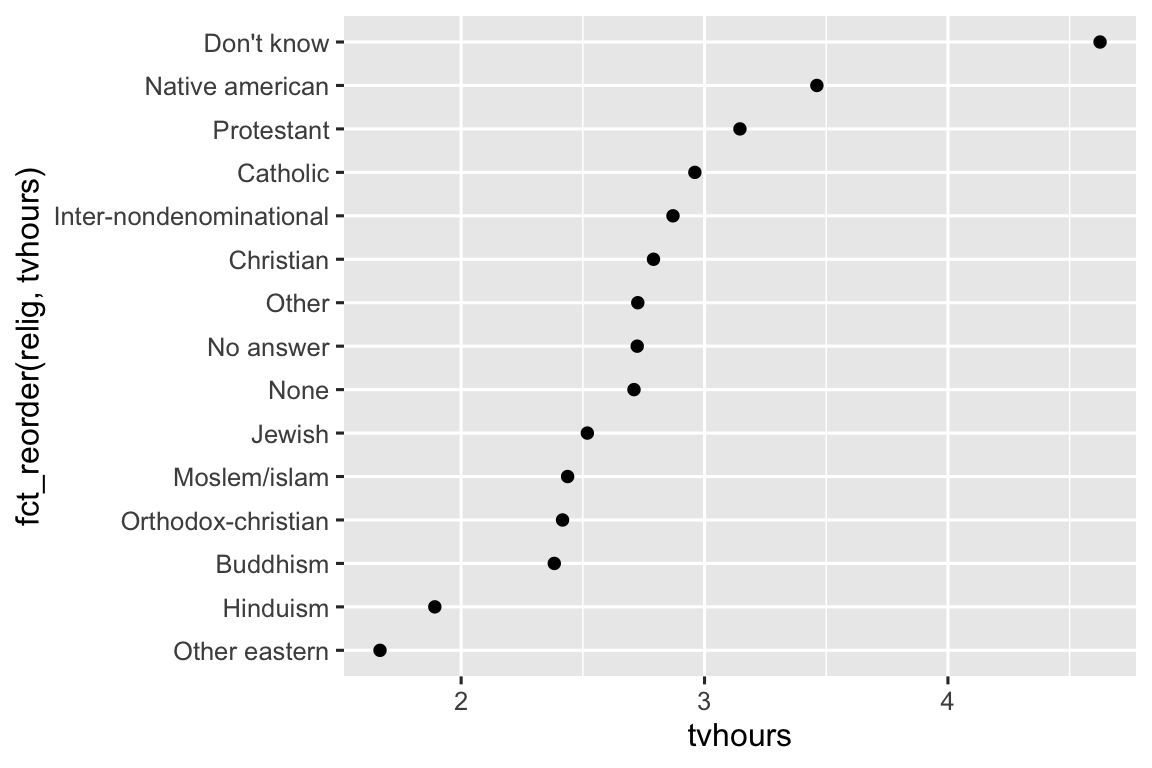
Sắp xếp lại tôn giáo giúp dễ dàng nhận ra rằng những người trong danh mục “Don’t know” xem TV nhiều hơn hẳn, còn Hindu giáo & Các tôn giáo phương Đông khác xem ít hơn nhiều.
Khi bạn bắt đầu thực hiện các biến đổi phức tạp hơn, chúng tôi khuyên bạn nên chuyển chúng ra khỏi aes() và vào một bước mutate() riêng. Ví dụ, bạn có thể viết lại biểu đồ trên như sau:
relig_summary |>
mutate(
relig = fct_reorder(relig, tvhours)
) |>
ggplot(aes(x = tvhours, y = relig)) +
geom_point()Nếu chúng ta tạo một biểu đồ tương tự xem tuổi trung bình thay đổi như thế nào theo mức thu nhập được báo cáo thì sao?
rincome_summary <- gss_cat |>
group_by(rincome) |>
summarize(
age = mean(age, na.rm = TRUE),
n = n()
)
ggplot(rincome_summary, aes(x = age, y = fct_reorder(rincome, age))) +
geom_point()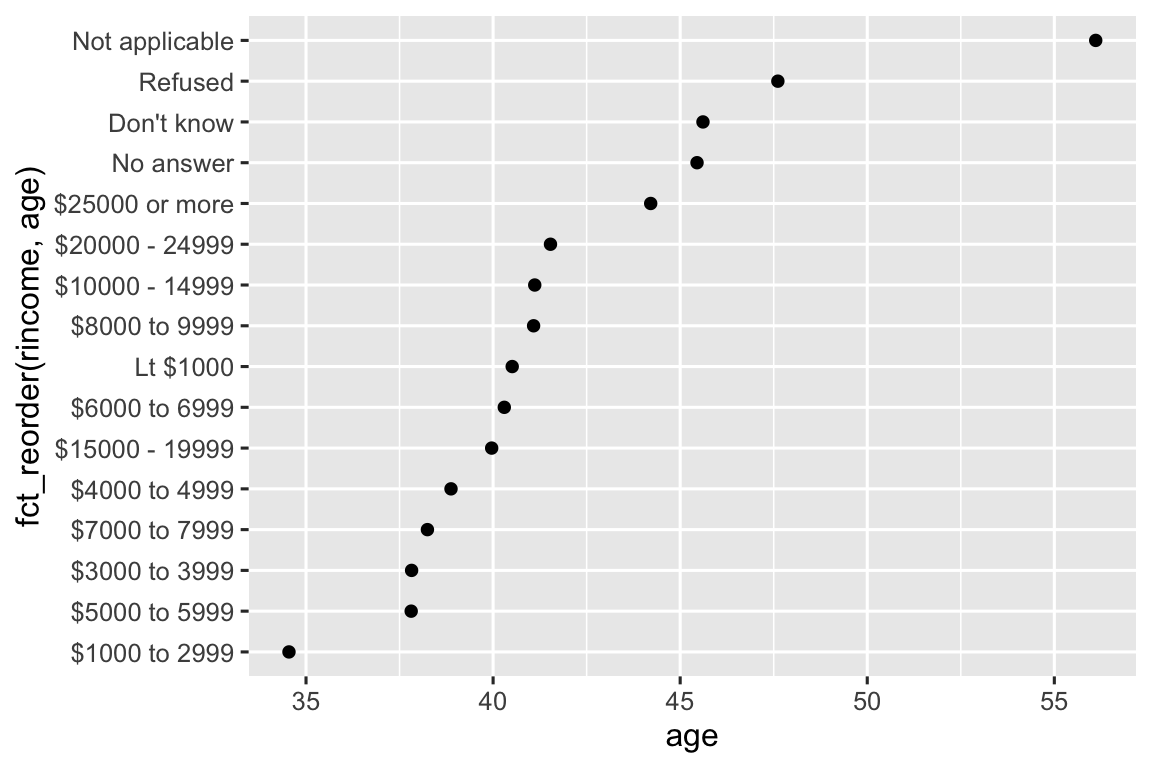
Ở đây, việc sắp xếp lại các mức một cách tùy ý không phải là ý hay! Đó là vì rincome đã có một thứ tự có nguyên tắc mà chúng ta không nên phá vỡ. Hãy dành fct_reorder() cho các factor có các mức được sắp xếp tùy ý.
Tuy nhiên, việc kéo “Not applicable” lên phía trước cùng với các mức đặc biệt khác là hợp lý. Bạn có thể sử dụng fct_relevel(). Function này nhận một factor, .f, và sau đó bất kỳ số lượng mức nào mà bạn muốn di chuyển lên đầu.
ggplot(rincome_summary, aes(x = age, y = fct_relevel(rincome, "Not applicable"))) +
geom_point()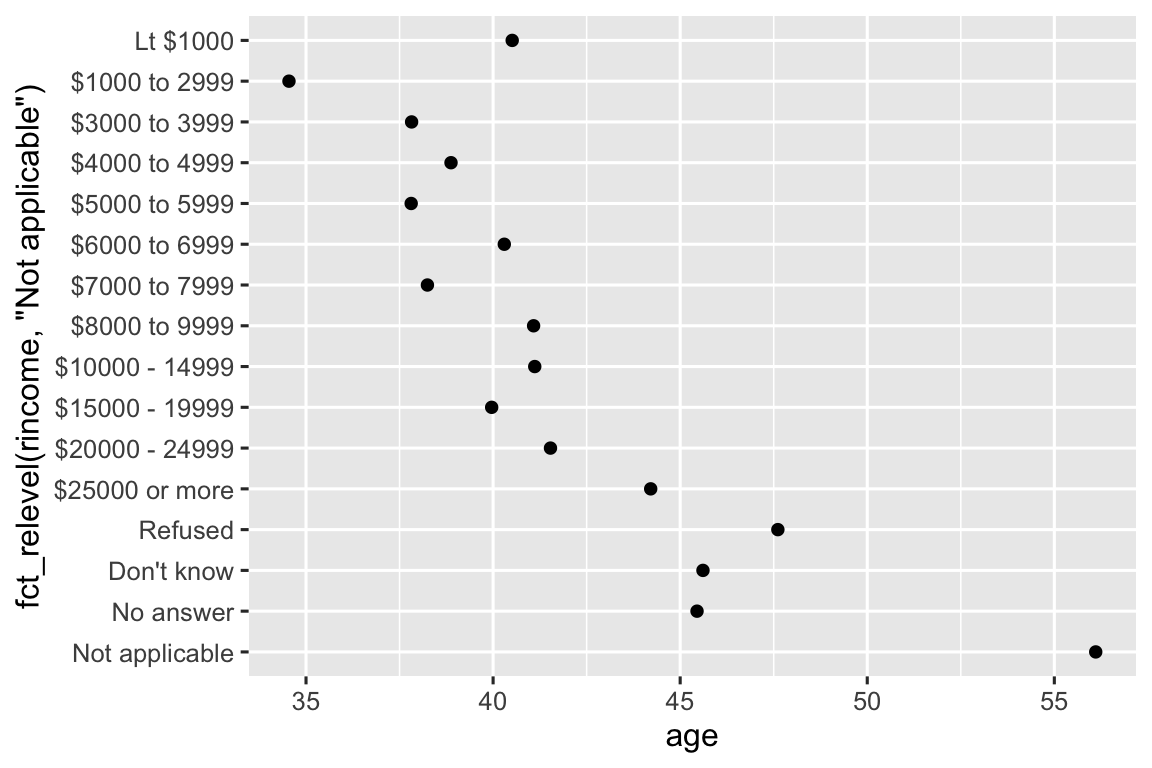
Theo bạn tại sao tuổi trung bình của “Not applicable” lại cao như vậy?
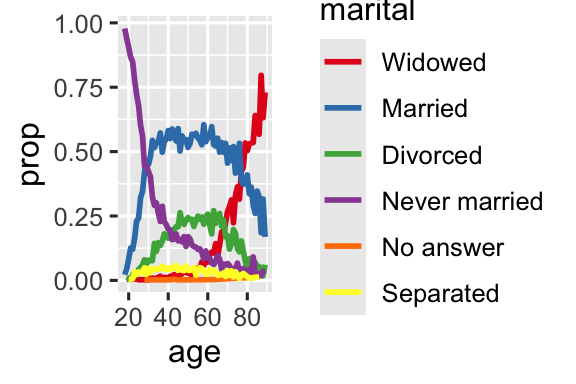
Một kiểu sắp xếp lại khác hữu ích khi bạn tô màu các đường trên biểu đồ. fct_reorder2(.f, .x, .y) sắp xếp lại factor .f theo các giá trị .y tương ứng với các giá trị .x lớn nhất. Điều này giúp biểu đồ dễ đọc hơn vì màu sắc của các đường ở phía ngoài cùng bên phải sẽ khớp với chú giải.
by_age <- gss_cat |>
filter(!is.na(age)) |>
count(age, marital) |>
group_by(age) |>
mutate(
prop = n / sum(n)
)
ggplot(by_age, aes(x = age, y = prop, color = marital)) +
geom_line(linewidth = 1) +
scale_color_brewer(palette = "Set1")
ggplot(by_age, aes(x = age, y = prop, color = fct_reorder2(marital, age, prop))) +
geom_line(linewidth = 1) +
scale_color_brewer(palette = "Set1") +
labs(color = "marital")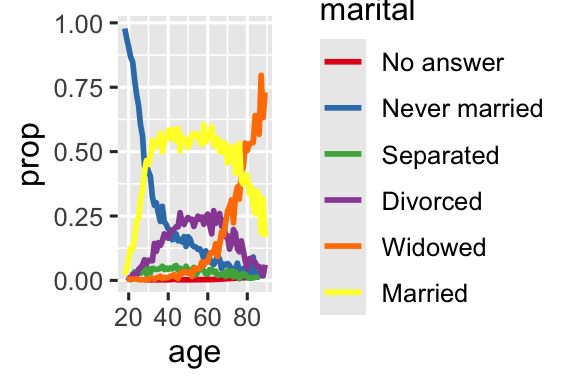
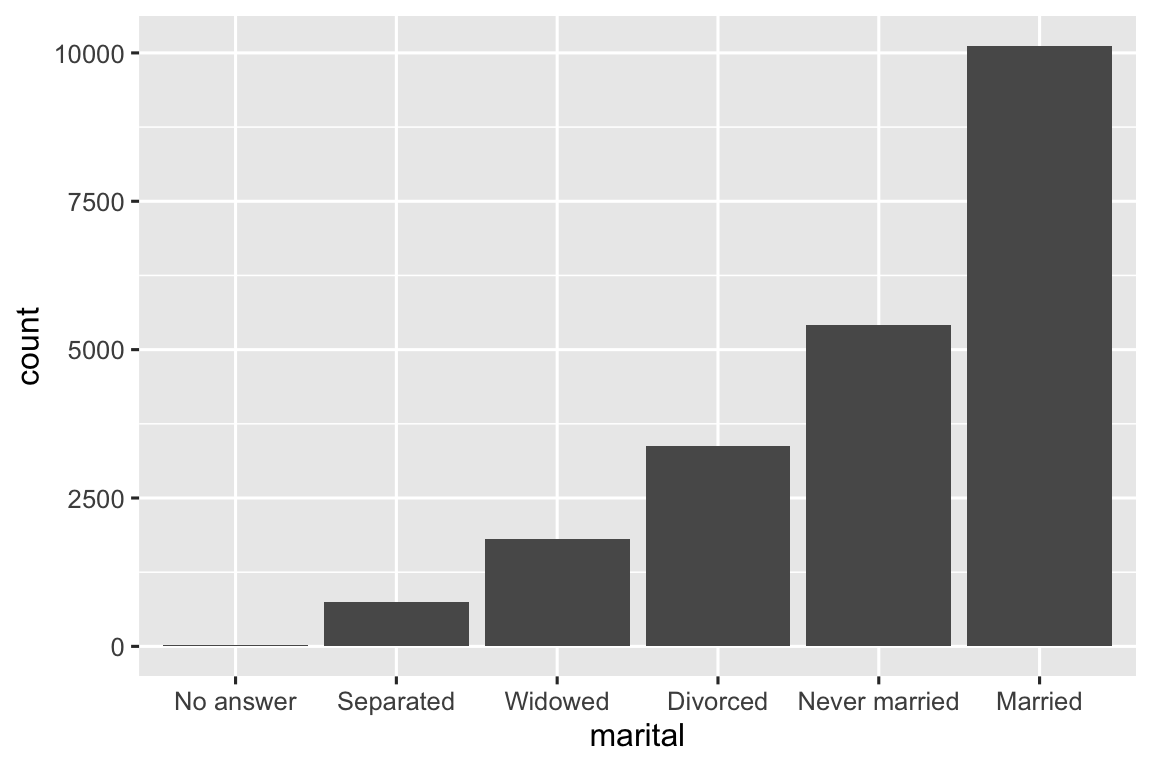
Cuối cùng, đối với biểu đồ column, bạn có thể sử dụng fct_infreq() để sắp xếp các mức theo tần suất giảm dần: đây là kiểu sắp xếp lại đơn giản nhất vì không cần thêm biến nào. Kết hợp nó với fct_rev() nếu bạn muốn theo tần suất tăng dần để trong biểu đồ column các giá trị lớn nhất ở bên phải, không phải bên trái.
16.4.1 Bài tập
Có một số con số đáng ngờ cao trong
tvhours. Giá trị trung bình có phải là thống kê tóm tắt tốt không?Đối với mỗi factor trong
gss_cat, hãy xác định xem thứ tự các mức là tùy ý hay có nguyên tắc.Tại sao việc di chuyển “Not applicable” lên đầu list các mức lại khiến nó xuất hiện ở cuối biểu đồ?
16.5 Thay đổi giá trị các mức factor
Mạnh hơn việc thay đổi thứ tự các mức là thay đổi giá trị của chúng. Điều này cho phép bạn làm rõ nhãn cho ấn phẩm, và gộp các mức lại cho các hiển thị tổng quát. Công cụ tổng quát và mạnh nhất là fct_recode(). Function này cho phép bạn mã hóa lại, hay thay đổi, giá trị của từng mức. Ví dụ, hãy xem biến partyid từ data frame gss_cat:
gss_cat |> count(partyid)
#> # A tibble: 10 × 2
#> partyid n
#> <fct> <int>
#> 1 No answer 154
#> 2 Don't know 1
#> 3 Other party 393
#> 4 Strong republican 2314
#> 5 Not str republican 3032
#> 6 Ind,near rep 1791
#> # ℹ 4 more rowsCác mức ngắn gọn và không nhất quán. Hãy chỉnh sửa chúng cho dài hơn và sử dụng cấu trúc song song. Giống như hầu hết các function đổi tên và mã hóa lại trong tidyverse, giá trị mới nằm bên trái và giá trị cũ nằm bên phải:
gss_cat |>
mutate(
partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat"
)
) |>
count(partyid)
#> # A tibble: 10 × 2
#> partyid n
#> <fct> <int>
#> 1 No answer 154
#> 2 Don't know 1
#> 3 Other party 393
#> 4 Republican, strong 2314
#> 5 Republican, weak 3032
#> 6 Independent, near rep 1791
#> # ℹ 4 more rowsfct_recode() sẽ giữ nguyên các mức không được đề cập rõ ràng, và sẽ cảnh báo bạn nếu bạn vô tình tham chiếu đến một mức không tồn tại.
Để gộp các nhóm, bạn có thể gán nhiều mức cũ cho cùng một mức mới:
gss_cat |>
mutate(
partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat",
"Other" = "No answer",
"Other" = "Don't know",
"Other" = "Other party"
)
)Hãy sử dụng kỹ thuật này một cách cẩn thận: nếu bạn gộp các danh mục thực sự khác nhau, bạn sẽ nhận được kết quả sai lệch.
Nếu bạn muốn gộp nhiều mức, fct_collapse() là một biến thể hữu ích của fct_recode(). Với mỗi biến mới, bạn có thể cung cấp một vector các mức cũ:
gss_cat |>
mutate(
partyid = fct_collapse(partyid,
"other" = c("No answer", "Don't know", "Other party"),
"rep" = c("Strong republican", "Not str republican"),
"ind" = c("Ind,near rep", "Independent", "Ind,near dem"),
"dem" = c("Not str democrat", "Strong democrat")
)
) |>
count(partyid)
#> # A tibble: 4 × 2
#> partyid n
#> <fct> <int>
#> 1 other 548
#> 2 rep 5346
#> 3 ind 8409
#> 4 dem 7180Đôi khi bạn chỉ muốn gộp các nhóm nhỏ lại để làm biểu đồ hoặc bảng đơn giản hơn. Đó là công việc của họ function fct_lump_*(). fct_lump_lowfreq() là điểm khởi đầu đơn giản, function này dần dần gộp các nhóm danh mục nhỏ nhất vào “Other”, luôn giữ “Other” là danh mục nhỏ nhất.
gss_cat |>
mutate(relig = fct_lump_lowfreq(relig)) |>
count(relig)
#> # A tibble: 2 × 2
#> relig n
#> <fct> <int>
#> 1 Protestant 10846
#> 2 Other 10637Trong trường hợp này, kết quả không hữu ích lắm: đúng là đa số người Mỹ trong khảo sát này là Tin lành, nhưng có lẽ chúng ta muốn xem thêm chi tiết! Thay vào đó, chúng ta có thể sử dụng fct_lump_n() để chỉ định rằng chúng ta muốn chính xác 10 nhóm:
gss_cat |>
mutate(relig = fct_lump_n(relig, n = 10)) |>
count(relig, sort = TRUE)
#> # A tibble: 10 × 2
#> relig n
#> <fct> <int>
#> 1 Protestant 10846
#> 2 Catholic 5124
#> 3 None 3523
#> 4 Christian 689
#> 5 Other 458
#> 6 Jewish 388
#> # ℹ 4 more rowsHãy đọc tài liệu để tìm hiểu về fct_lump_min() và fct_lump_prop(), những function hữu ích trong các trường hợp khác.
16.5.1 Bài tập
Tỷ lệ người tự nhận là Đảng Dân chủ, Đảng Cộng hòa, và Độc lập đã thay đổi như thế nào theo thời gian?
Bạn có thể gộp
rincomethành một tập hợp nhỏ các danh mục bằng cách nào?Lưu ý rằng có 9 nhóm (không tính other) trong ví dụ
fct_lumpở trên. Tại sao không phải 10? (Gợi ý: gõ?fct_lump, và tìm giá trị mặc định cho argumentother_levellà “Other”.)
16.6 Nhân tố có thứ tự
Trước khi tiếp tục, điều quan trọng là phải đề cập ngắn gọn về một loại factor đặc biệt: factor có thứ tự (ordered factor). Được tạo bằng function ordered(), factor có thứ tự ngụ ý một thứ tự nghiêm ngặt giữa các mức, nhưng không chỉ rõ bất kỳ điều gì về độ lớn của sự khác biệt giữa các mức. Bạn sử dụng factor có thứ tự khi bạn biết các mức có thứ hạng, nhưng không có thứ hạng số chính xác.
Bạn có thể nhận biết factor có thứ tự khi nó được in ra vì nó sử dụng ký hiệu < giữa các mức:
Trong cả base R và tidyverse, factor có thứ tự hoạt động rất giống với factor thông thường. Chỉ có hai nơi bạn có thể nhận thấy hành vi khác biệt:
- Nếu bạn mapping một factor có thứ tự vào color hoặc fill trong ggplot2, nó sẽ mặc định sử dụng
scale_color_viridis()/scale_fill_viridis(), một thang màu ngụ ý thứ hạng. - Nếu bạn sử dụng một biến dự đoán có thứ tự trong mô hình tuyến tính, nó sẽ sử dụng “tương phản đa thức” (polynomial contrasts). Những thứ này có phần hữu ích, nhưng bạn khó có thể đã nghe về chúng trừ khi bạn có bằng Tiến sĩ Thống kê, và ngay cả khi đó bạn có lẽ cũng không thường xuyên diễn giải chúng. Nếu bạn muốn tìm hiểu thêm, chúng tôi khuyên bạn nên xem
vignette("contrasts", package = "faux")của Lisa DeBruine.
Với mục đích của cuốn sách này, việc phân biệt chính xác giữa factor thông thường và factor có thứ tự không đặc biệt quan trọng. Tuy nhiên, rộng hơn, một số lĩnh vực (đặc biệt là khoa học xã hội) sử dụng factor có thứ tự rất nhiều. Trong những ngữ cảnh đó, việc xác định chính xác chúng là quan trọng để các package phân tích khác có thể cung cấp hành vi phù hợp.
16.7 Tóm tắt
Chương này giới thiệu cho bạn package forcats tiện dụng để làm việc với factor, giới thiệu các function được sử dụng phổ biến nhất. forcats chứa một loạt các function hỗ trợ khác mà chúng ta không có đủ chỗ để thảo luận ở đây, vì vậy mỗi khi bạn đối mặt với một thách thức phân tích factor mà bạn chưa gặp trước đây, tôi rất khuyên bạn nên lướt qua trang chỉ mục tham khảo để xem có function sẵn có nào có thể giúp giải quyết vấn đề của bạn không.
Nếu bạn muốn tìm hiểu thêm về factor sau khi đọc chương này, chúng tôi khuyên bạn nên đọc bài báo của Amelia McNamara và Nicholas Horton, Wrangling categorical data in R. Bài báo này trình bày một số lịch sử được thảo luận trong stringsAsFactors: An unauthorized biography và stringsAsFactors = <sigh>, và so sánh các phương pháp tidy để xử lý dữ liệu phân loại được trình bày trong cuốn sách này với các phương pháp base R. Phiên bản đầu tiên của bài báo đã giúp thúc đẩy và định hình phạm vi cho package forcats; cảm ơn Amelia & Nick!
Trong chương tiếp theo, chúng ta sẽ chuyển sang bắt đầu tìm hiểu về ngày tháng và thời gian trong R. Ngày tháng và thời gian có vẻ đơn giản một cách lừa dối, nhưng như bạn sẽ sớm thấy, bạn càng tìm hiểu về chúng, chúng càng có vẻ phức tạp hơn!
Chúng cũng rất quan trọng cho việc xây dựng mô hình.↩︎