12 Vector logic
12.1 Giới thiệu
Trong chương này, bạn sẽ học các công cụ để làm việc với vector logic (logical vector). Vector logic là loại vector đơn giản nhất vì mỗi phần tử chỉ có thể là một trong ba giá trị: TRUE, FALSE, và NA. Khá hiếm khi bạn tìm thấy vector logic trong dữ liệu thô, nhưng bạn sẽ tạo và thao tác với chúng trong hầu hết mọi phân tích.
Chúng ta sẽ bắt đầu bằng cách thảo luận về cách phổ biến nhất để tạo vector logic: so sánh số học. Sau đó bạn sẽ học cách sử dụng đại số Boole (Boole algebra) để kết hợp các vector logic khác nhau, cũng như một số phép tóm tắt hữu ích. Chúng ta sẽ kết thúc với if_else() và case_when(), hai function hữu ích để thực hiện các thay đổi có điều kiện dựa trên vector logic.
12.1.1 Điều kiện tiên quyết
Hầu hết các function bạn sẽ học trong chương này được cung cấp bởi base R, vì vậy chúng ta không cần tidyverse, nhưng chúng ta vẫn sẽ tải nó để có thể sử dụng mutate(), filter(), và các function liên quan để làm việc với data frame. Chúng ta cũng sẽ tiếp tục sử dụng các ví dụ từ tập dữ liệu nycflights13::flights.
Tuy nhiên, khi chúng ta bắt đầu đề cập đến nhiều công cụ hơn, sẽ không phải lúc nào cũng có ví dụ thực tế hoàn hảo. Vì vậy chúng ta sẽ bắt đầu tạo một số dữ liệu giả với c():
x <- c(1, 2, 3, 5, 7, 11, 13)
x * 2
#> [1] 2 4 6 10 14 22 26Điều này giúp việc giải thích từng function dễ dàng hơn nhưng đổi lại khó thấy được cách áp dụng vào bài toán dữ liệu của bạn. Chỉ cần nhớ rằng bất kỳ thao tác nào chúng ta thực hiện trên một vector độc lập, bạn đều có thể thực hiện trên một biến bên trong data frame với mutate() và các function liên quan.
12.2 Phép so sánh
Một cách rất phổ biến để tạo vector logic là thông qua phép so sánh số học với <, <=, >, >=, !=, và ==. Cho đến nay, chúng ta chủ yếu tạo các biến logic tạm thời bên trong filter() — chúng được tính toán, sử dụng, rồi bị loại bỏ. Ví dụ, bộ lọc sau tìm tất cả các chuyến bay khởi hành ban ngày đến nơi gần đúng giờ:
flights |>
filter(dep_time > 600 & dep_time < 2000 & abs(arr_delay) < 20)
#> # A tibble: 172,286 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 601 600 1 844 850
#> 2 2013 1 1 602 610 -8 812 820
#> 3 2013 1 1 602 605 -3 821 805
#> 4 2013 1 1 606 610 -4 858 910
#> 5 2013 1 1 606 610 -4 837 845
#> 6 2013 1 1 607 607 0 858 915
#> # ℹ 172,280 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Sẽ hữu ích khi biết rằng đây là một cách viết tắt và bạn có thể tạo rõ ràng các biến logic cơ sở với mutate():
flights |>
mutate(
daytime = dep_time > 600 & dep_time < 2000,
approx_ontime = abs(arr_delay) < 20,
.keep = "used"
)
#> # A tibble: 336,776 × 4
#> dep_time arr_delay daytime approx_ontime
#> <int> <dbl> <lgl> <lgl>
#> 1 517 11 FALSE TRUE
#> 2 533 20 FALSE FALSE
#> 3 542 33 FALSE FALSE
#> 4 544 -18 FALSE TRUE
#> 5 554 -25 FALSE FALSE
#> 6 554 12 FALSE TRUE
#> # ℹ 336,770 more rowsĐiều này đặc biệt hữu ích cho logic phức tạp hơn vì việc đặt tên cho các bước trung gian giúp bạn dễ đọc mã hơn và kiểm tra xem mỗi bước đã được tính toán chính xác chưa.
Tổng hợp lại, bộ lọc ban đầu tương đương với:
12.2.1 So sánh số thực dấu phẩy động
Hãy cẩn thận khi sử dụng == với số. Ví dụ, có vẻ như vector này chứa các số 1 và 2:
Nhưng nếu bạn kiểm tra tính bằng nhau, bạn sẽ nhận được FALSE:
x == c(1, 2)
#> [1] FALSE FALSEChuyện gì đang xảy ra? Máy tính lưu trữ số với một số lượng chữ số thập phân cố định nên không có cách nào biểu diễn chính xác 1/49 hoặc sqrt(2) và các phép tính tiếp theo sẽ bị sai lệch rất nhỏ. Chúng ta có thể xem giá trị chính xác bằng cách gọi print() với argument digits1:
print(x, digits = 16)
#> [1] 0.9999999999999999 2.0000000000000004Bạn có thể thấy tại sao R mặc định làm tròn các số này; chúng thực sự rất gần với giá trị bạn mong đợi.
Bây giờ bạn đã hiểu tại sao == bị sai, bạn có thể làm gì? Một lựa chọn là sử dụng dplyr::near() để bỏ qua các khác biệt nhỏ:
12.2.2 Giá trị khuyết
Giá trị khuyết (missing value) đại diện cho điều chưa biết nên chúng có tính “lây lan”: hầu hết mọi phép toán liên quan đến một giá trị chưa biết cũng sẽ cho kết quả chưa biết:
NA > 5
#> [1] NA
10 == NA
#> [1] NAKết quả khó hiểu nhất là kết quả này:
NA == NA
#> [1] NACách dễ nhất để hiểu tại sao điều này đúng là thêm một chút ngữ cảnh:
# Chúng ta không biết Mary bao nhiêu tuổi
age_mary <- NA
# Chúng ta không biết John bao nhiêu tuổi
age_john <- NA
# Mary và John có cùng tuổi không?
age_mary == age_john
#> [1] NA
# Chúng ta không biết!Vì vậy nếu bạn muốn tìm tất cả các chuyến bay có dep_time bị khuyết, đoạn mã sau sẽ không hoạt động vì dep_time == NA sẽ trả về NA cho mọi row, và filter() tự động loại bỏ các missing value:
flights |>
filter(dep_time == NA)
#> # A tibble: 0 × 19
#> # ℹ 19 variables: year <int>, month <int>, day <int>, dep_time <int>,
#> # sched_dep_time <int>, dep_delay <dbl>, arr_time <int>, …Thay vào đó chúng ta sẽ cần một công cụ mới: is.na().
12.2.3 is.na()
is.na(x) hoạt động với bất kỳ loại vector nào và trả về TRUE cho missing value và FALSE cho mọi thứ khác:
Chúng ta có thể sử dụng is.na() để tìm tất cả các row có dep_time bị khuyết:
flights |>
filter(is.na(dep_time))
#> # A tibble: 8,255 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 2 NA 1540 NA NA 1747
#> 6 2013 1 2 NA 1620 NA NA 1746
#> # ℹ 8,249 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …is.na() cũng có thể hữu ích trong arrange(). arrange() thường đặt tất cả missing value ở cuối nhưng bạn có thể ghi đè mặc định này bằng cách sắp xếp theo is.na() trước:
flights |>
filter(month == 1, day == 1) |>
arrange(dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …
flights |>
filter(month == 1, day == 1) |>
arrange(desc(is.na(dep_time)), dep_time)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 NA 1630 NA NA 1815
#> 2 2013 1 1 NA 1935 NA NA 2240
#> 3 2013 1 1 NA 1500 NA NA 1825
#> 4 2013 1 1 NA 600 NA NA 901
#> 5 2013 1 1 517 515 2 830 819
#> 6 2013 1 1 533 529 4 850 830
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Chúng ta sẽ quay lại đề cập missing value chi tiết hơn trong Chương 18.
12.2.4 Bài tập
-
dplyr::near()hoạt động như thế nào? Gõnearđể xem mã nguồn.sqrt(2)^2có gần bằng 2 không? - Sử dụng
mutate(),is.na(), vàcount()cùng nhau để mô tả cách các missing value trongdep_time,sched_dep_timevàdep_delayliên quan với nhau.
12.3 Đại số Boole
Khi bạn có nhiều vector logic, bạn có thể kết hợp chúng lại bằng đại số Boole (Boole algebra). Trong R, & là “và”, | là “hoặc”, ! là “phủ định”, và xor() là hoặc loại trừ (exclusive or)2. Ví dụ, df |> filter(!is.na(x)) tìm tất cả các row mà x không bị khuyết và df |> filter(x < -10 | x > 0) tìm tất cả các row mà x nhỏ hơn -10 hoặc lớn hơn 0. Hình 12.1 cho thấy các ví dụ về các phép toán Boole thường dùng và cách chúng hoạt động.
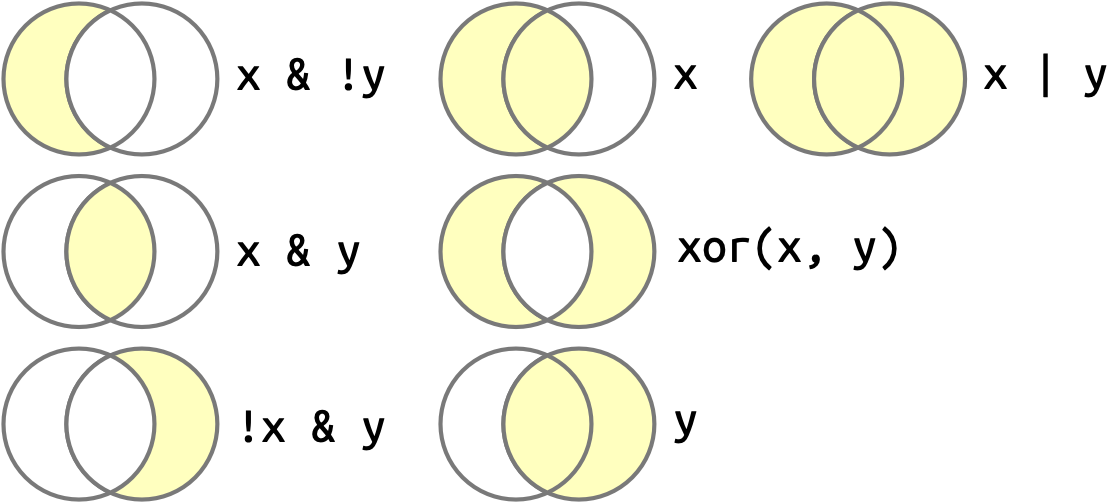
x là vòng tròn bên trái, y là vòng tròn bên phải, và vùng tô đậm cho thấy phần nào mỗi toán tử chọn.
Ngoài & và |, R còn có && và ||. Đừng sử dụng chúng trong các function dplyr! Đây được gọi là toán tử đoản mạch (short-circuiting operator) và chỉ trả về một giá trị TRUE hoặc FALSE duy nhất. Chúng quan trọng cho lập trình, không phải cho khoa học dữ liệu.
12.3.1 Giá trị khuyết
Các quy tắc cho missing value trong đại số Boole hơi khó giải thích vì thoạt nhìn chúng có vẻ không nhất quán:
Để hiểu chuyện gì đang xảy ra, hãy nghĩ về NA | TRUE (NA hoặc TRUE). Một missing value trong vector logic có nghĩa là giá trị đó có thể là TRUE hoặc FALSE. TRUE | TRUE và FALSE | TRUE đều là TRUE vì ít nhất một trong số chúng là TRUE. NA | TRUE cũng phải là TRUE vì NA có thể là TRUE hoặc FALSE. Tuy nhiên, NA | FALSE là NA vì chúng ta không biết NA là TRUE hay FALSE. Lý luận tương tự áp dụng cho & khi xem xét rằng cả hai điều kiện phải được thỏa mãn. Do đó NA & TRUE là NA vì NA có thể là TRUE hoặc FALSE và NA & FALSE là FALSE vì ít nhất một trong các điều kiện là FALSE.
12.3.2 Thứ tự phép toán
Lưu ý rằng thứ tự phép toán không hoạt động giống như tiếng Anh. Xem đoạn mã sau tìm tất cả các chuyến bay khởi hành vào tháng Mười Một hoặc tháng Mười Hai:
flights |>
filter(month == 11 | month == 12)Bạn có thể muốn viết như cách nói trong tiếng Anh: “Tìm tất cả các chuyến bay khởi hành vào tháng Mười Một hoặc tháng Mười Hai.”:
flights |>
filter(month == 11 | 12)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Đoạn mã này không báo lỗi nhưng cũng có vẻ không hoạt động đúng. Chuyện gì đang xảy ra? Ở đây, R trước tiên tính month == 11 tạo ra một vector logic, mà chúng ta gọi là nov. Nó tính nov | 12. Khi bạn sử dụng một số với toán tử logic, nó chuyển đổi mọi thứ ngoại trừ 0 thành TRUE, vì vậy điều này tương đương với nov | TRUE và sẽ luôn là TRUE, nên mọi row sẽ được chọn:
flights |>
mutate(
nov = month == 11,
final = nov | 12,
.keep = "used"
)
#> # A tibble: 336,776 × 3
#> month nov final
#> <int> <lgl> <lgl>
#> 1 1 FALSE TRUE
#> 2 1 FALSE TRUE
#> 3 1 FALSE TRUE
#> 4 1 FALSE TRUE
#> 5 1 FALSE TRUE
#> 6 1 FALSE TRUE
#> # ℹ 336,770 more rows
12.3.3 %in%
Một cách dễ dàng để tránh vấn đề sắp xếp đúng thứ tự == và | là sử dụng %in%. x %in% y trả về một vector logic có cùng độ dài với x, là TRUE bất cứ khi nào một giá trị trong x xuất hiện ở bất kỳ đâu trong y.
Vì vậy để tìm tất cả các chuyến bay vào tháng Mười Một và tháng Mười Hai, chúng ta có thể viết:
Lưu ý rằng %in% tuân theo các quy tắc khác với == đối với NA, vì NA %in% NA là TRUE.
Điều này có thể tạo thành một phím tắt hữu ích:
flights |>
filter(dep_time %in% c(NA, 0800))
#> # A tibble: 8,803 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 800 800 0 1022 1014
#> 2 2013 1 1 800 810 -10 949 955
#> 3 2013 1 1 NA 1630 NA NA 1815
#> 4 2013 1 1 NA 1935 NA NA 2240
#> 5 2013 1 1 NA 1500 NA NA 1825
#> 6 2013 1 1 NA 600 NA NA 901
#> # ℹ 8,797 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …12.3.4 Bài tập
- Tìm tất cả các chuyến bay mà
arr_delaybị khuyết nhưngdep_delaythì không. Tìm tất cả các chuyến bay mà cảarr_timelẫnsched_arr_timeđều không bị khuyết, nhưngarr_delaythì bị khuyết. - Có bao nhiêu chuyến bay có
dep_timebị khuyết? Những biến nào khác cũng bị khuyết trong các row này? Những row này có thể đại diện cho điều gì? - Giả sử rằng
dep_timebị khuyết nghĩa là chuyến bay bị hủy, hãy xem số lượng chuyến bay bị hủy theo ngày. Có quy luật nào không? Có mối liên hệ nào giữa tỷ lệ chuyến bay bị hủy và độ trễ trung bình của các chuyến bay không bị hủy không?
12.4 Tóm tắt thống kê
Các phần tiếp theo mô tả một số kỹ thuật hữu ích để tóm tắt vector logic. Ngoài các function chỉ hoạt động riêng với vector logic, bạn cũng có thể sử dụng các function hoạt động với vector số.
12.4.1 Tóm tắt logic
Có hai function tóm tắt logic chính: any() và all(). any(x) tương đương với |; nó sẽ trả về TRUE nếu có bất kỳ giá trị TRUE nào trong x. all(x) tương đương với &; nó sẽ trả về TRUE chỉ khi tất cả các giá trị của x đều là TRUE. Giống như hầu hết các function tóm tắt, bạn có thể loại bỏ missing value bằng na.rm = TRUE.
Ví dụ, chúng ta có thể sử dụng all() và any() để tìm xem liệu mọi chuyến bay có bị trễ khởi hành tối đa một giờ hay không hoặc liệu có chuyến bay nào bị trễ đến nơi năm giờ trở lên hay không. Và sử dụng group_by() cho phép chúng ta thực hiện điều đó theo ngày:
flights |>
group_by(year, month, day) |>
summarize(
all_delayed = all(dep_delay <= 60, na.rm = TRUE),
any_long_delay = any(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day all_delayed any_long_delay
#> <int> <int> <int> <lgl> <lgl>
#> 1 2013 1 1 FALSE TRUE
#> 2 2013 1 2 FALSE TRUE
#> 3 2013 1 3 FALSE FALSE
#> 4 2013 1 4 FALSE FALSE
#> 5 2013 1 5 FALSE TRUE
#> 6 2013 1 6 FALSE FALSE
#> # ℹ 359 more rowsTuy nhiên trong hầu hết các trường hợp, any() và all() hơi quá thô sơ, và sẽ tốt hơn nếu có thể biết thêm chi tiết về số lượng giá trị TRUE hoặc FALSE. Điều đó dẫn chúng ta đến phần tóm tắt bằng số.
12.4.2 Tóm tắt bằng số của vector logic
Khi bạn sử dụng vector logic trong ngữ cảnh số, TRUE trở thành 1 và FALSE trở thành 0. Điều này khiến sum() và mean() rất hữu ích với vector logic vì sum(x) cho số lượng giá trị TRUE và mean(x) cho tỷ lệ giá trị TRUE (vì mean() chỉ là sum() chia cho length()).
Ví dụ, điều đó cho phép chúng ta xem tỷ lệ chuyến bay bị trễ khởi hành tối đa một giờ và số lượng chuyến bay bị trễ đến nơi năm giờ trở lên:
flights |>
group_by(year, month, day) |>
summarize(
proportion_delayed = mean(dep_delay <= 60, na.rm = TRUE),
count_long_delay = sum(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day proportion_delayed count_long_delay
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 0.939 3
#> 2 2013 1 2 0.914 3
#> 3 2013 1 3 0.941 0
#> 4 2013 1 4 0.953 0
#> 5 2013 1 5 0.964 1
#> 6 2013 1 6 0.959 0
#> # ℹ 359 more rows12.4.3 Lọc con bằng logic
Còn một cách sử dụng cuối cùng cho vector logic trong tóm tắt: bạn có thể sử dụng vector logic để lọc một biến đơn lẻ thành một tập con quan tâm. Điều này sử dụng toán tử [ (đọc là subset) của base R, mà bạn sẽ tìm hiểu thêm trong Phần 27.2.
Hãy tưởng tượng chúng ta muốn xem độ trễ trung bình chỉ cho các chuyến bay thực sự bị trễ. Một cách để làm điều này là lọc các chuyến bay trước rồi tính độ trễ trung bình:
flights |>
filter(arr_delay > 0) |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 5
#> year month day behind n
#> <int> <int> <int> <dbl> <int>
#> 1 2013 1 1 32.5 461
#> 2 2013 1 2 32.0 535
#> 3 2013 1 3 27.7 460
#> 4 2013 1 4 28.3 297
#> 5 2013 1 5 22.6 238
#> 6 2013 1 6 24.4 381
#> # ℹ 359 more rowsCách này hoạt động, nhưng nếu chúng ta cũng muốn tính độ trễ trung bình cho các chuyến bay đến sớm thì sao? Chúng ta sẽ cần thực hiện một bước lọc riêng, rồi tìm cách kết hợp hai data frame lại với nhau3. Thay vào đó bạn có thể sử dụng [ để lọc trực tiếp: arr_delay[arr_delay > 0] sẽ chỉ trả về các giá trị trễ đến dương.
Điều này dẫn đến:
flights |>
group_by(year, month, day) |>
summarize(
behind = mean(arr_delay[arr_delay > 0], na.rm = TRUE),
ahead = mean(arr_delay[arr_delay < 0], na.rm = TRUE),
n = n(),
.groups = "drop"
)
#> # A tibble: 365 × 6
#> year month day behind ahead n
#> <int> <int> <int> <dbl> <dbl> <int>
#> 1 2013 1 1 32.5 -12.5 842
#> 2 2013 1 2 32.0 -14.3 943
#> 3 2013 1 3 27.7 -18.2 914
#> 4 2013 1 4 28.3 -17.0 915
#> 5 2013 1 5 22.6 -14.0 720
#> 6 2013 1 6 24.4 -13.6 832
#> # ℹ 359 more rowsCũng lưu ý sự khác biệt về kích thước nhóm: trong khối mã đầu tiên n() cho số lượng chuyến bay bị trễ mỗi ngày; trong khối thứ hai, n() cho tổng số chuyến bay.
12.4.4 Bài tập
12.5 Biến đổi có điều kiện
Một trong những tính năng mạnh mẽ nhất của vector logic là khả năng sử dụng chúng cho biến đổi có điều kiện (conditional transformation), tức là thực hiện một điều cho điều kiện x, và một điều khác cho điều kiện y. Có hai công cụ quan trọng cho việc này: if_else() và case_when().
12.5.1 if_else()
Nếu bạn muốn sử dụng một giá trị khi điều kiện là TRUE và một giá trị khác khi điều kiện là FALSE, bạn có thể sử dụng dplyr::if_else()4. Bạn sẽ luôn sử dụng ba argument đầu tiên của if_else(). Đối số thứ nhất, condition, là một vector logic, argument thứ hai, true, cho kết quả khi điều kiện đúng, và argument thứ ba, false, cho kết quả khi điều kiện sai.
Hãy bắt đầu với một ví dụ đơn giản về việc gán nhãn một vector số là “+ve” (dương) hoặc “-ve” (âm):
Có một argument thứ tư tùy chọn, missing, sẽ được sử dụng nếu đầu vào là NA:
if_else(x > 0, "+ve", "-ve", "???")
#> [1] "-ve" "-ve" "-ve" "-ve" "+ve" "+ve" "+ve" "???"Bạn cũng có thể sử dụng vector cho các argument true và false. Ví dụ, điều này cho phép chúng ta tạo một phiên bản tối giản của abs():
if_else(x < 0, -x, x)
#> [1] 3 2 1 0 1 2 3 NACho đến nay tất cả các argument đều sử dụng cùng một vector, nhưng tất nhiên bạn có thể kết hợp linh hoạt. Ví dụ, bạn có thể triển khai một phiên bản đơn giản của coalesce() như thế này:
Bạn có thể đã nhận thấy một điểm chưa hoàn hảo nhỏ trong ví dụ gán nhãn ở trên: số không không phải là số dương cũng không phải số âm. Chúng ta có thể giải quyết điều này bằng cách thêm một if_else() bổ sung:
Đoạn mã này đã hơi khó đọc, và bạn có thể tưởng tượng nó sẽ càng khó hơn nếu có thêm điều kiện. Thay vào đó, bạn có thể chuyển sang dplyr::case_when().
12.5.2 case_when()
case_when() của dplyr được lấy cảm hứng từ câu lệnh CASE của SQL và cung cấp một cách linh hoạt để thực hiện các phép tính khác nhau cho các điều kiện khác nhau. Nó có cú pháp đặc biệt mà không giống bất kỳ thứ gì khác bạn sẽ sử dụng trong tidyverse. Nó nhận các cặp có dạng condition ~ output. condition phải là một vector logic; khi nó là TRUE, output sẽ được sử dụng.
Điều này có nghĩa là chúng ta có thể tái tạo if_else() lồng nhau trước đó như sau:
Đoạn mã này dài hơn, nhưng cũng rõ ràng hơn.
Để giải thích cách case_when() hoạt động, hãy khám phá một số trường hợp đơn giản hơn. Nếu không có trường hợp nào khớp, kết quả sẽ là NA:
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve"
)
#> [1] "-ve" "-ve" "-ve" NA "+ve" "+ve" "+ve" NASử dụng .default nếu bạn muốn tạo giá trị “mặc định”/bắt tất cả:
case_when(
x < 0 ~ "-ve",
x > 0 ~ "+ve",
.default = "???"
)
#> [1] "-ve" "-ve" "-ve" "???" "+ve" "+ve" "+ve" "???"Và lưu ý rằng nếu nhiều điều kiện khớp, chỉ điều kiện đầu tiên sẽ được sử dụng:
case_when(
x > 0 ~ "+ve",
x > 2 ~ "big"
)
#> [1] NA NA NA NA "+ve" "+ve" "+ve" NAGiống như với if_else(), bạn có thể sử dụng biến ở cả hai bên của ~ và có thể kết hợp linh hoạt các biến tùy theo bài toán. Ví dụ, chúng ta có thể sử dụng case_when() để cung cấp các nhãn dễ đọc cho độ trễ đến nơi:
flights |>
mutate(
status = case_when(
is.na(arr_delay) ~ "cancelled",
arr_delay < -30 ~ "very early",
arr_delay < -15 ~ "early",
abs(arr_delay) <= 15 ~ "on time",
arr_delay < 60 ~ "late",
arr_delay < Inf ~ "very late",
),
.keep = "used"
)
#> # A tibble: 336,776 × 2
#> arr_delay status
#> <dbl> <chr>
#> 1 11 on time
#> 2 20 late
#> 3 33 late
#> 4 -18 early
#> 5 -25 early
#> 6 12 on time
#> # ℹ 336,770 more rowsHãy cẩn thận khi viết loại case_when() phức tạp này; hai lần thử đầu tiên của tôi đã sử dụng kết hợp < và > và tôi liên tục tạo ra các điều kiện chồng lấp.
12.5.3 Kiểu tương thích
Lưu ý rằng cả if_else() và case_when() đều yêu cầu các kiểu tương thích trong kết quả đầu ra. Nếu chúng không tương thích, bạn sẽ thấy các lỗi như thế này:
Nhìn chung, khá ít kiểu dữ liệu tương thích với nhau, vì việc tự động chuyển đổi một kiểu vector sang kiểu khác là nguồn gốc phổ biến của lỗi. Dưới đây là các trường hợp quan trọng nhất tương thích với nhau:
- Vector số và vector logic tương thích, như chúng ta đã thảo luận trong Phần 12.4.2.
- Chuỗi ký tự và factor (Chương 16) tương thích, vì bạn có thể coi factor là string với tập giá trị bị giới hạn.
- Ngày và ngày-giờ, mà chúng ta sẽ thảo luận trong Chương 17, tương thích vì bạn có thể coi ngày là trường hợp đặc biệt của ngày-giờ.
-
NA, về mặt kỹ thuật là vector logic, tương thích với mọi thứ vì mọi vector đều có cách biểu diễn missing value.
Chúng tôi không mong bạn ghi nhớ các quy tắc này, nhưng chúng sẽ trở thành bản năng thứ hai theo thời gian vì chúng được áp dụng nhất quán trong toàn bộ tidyverse.
12.5.4 Bài tập
Một số là số chẵn nếu nó chia hết cho hai, mà trong R bạn có thể kiểm tra bằng
x %% 2 == 0. Sử dụng sự kiện này vàif_else()để xác định xem mỗi số từ 0 đến 20 là chẵn hay lẻ.Cho một vector các ngày như
x <- c("Monday", "Saturday", "Wednesday"), sử dụng câu lệnhif_else()để gán nhãn chúng là ngày cuối tuần hoặc ngày trong tuần.Sử dụng
if_else()để tính giá trị tuyệt đối của một vector số có tênx.Viết một câu lệnh
case_when()sử dụng các columnmonthvàdaytừflightsđể gán nhãn cho một số ngày lễ quan trọng của Mỹ (ví dụ: Ngày Năm Mới, ngày 4 tháng 7, Lễ Tạ Ơn, và Giáng Sinh). Đầu tiên tạo một column logic có giá trịTRUEhoặcFALSE, sau đó tạo một column ký tự cho tên ngày lễ hoặc làNA.
12.6 Tổng kết
Định nghĩa của vector logic rất đơn giản vì mỗi giá trị chỉ có thể là TRUE, FALSE, hoặc NA. Nhưng vector logic mang lại sức mạnh rất lớn. Trong chương này, bạn đã học cách tạo vector logic với >, <, <=, >=, ==, !=, và is.na(), cách kết hợp chúng với !, &, và |, và cách tóm tắt chúng với any(), all(), sum(), và mean(). Bạn cũng đã học các function mạnh mẽ if_else() và case_when() cho phép bạn trả về giá trị tùy thuộc vào giá trị của vector logic.
Chúng ta sẽ gặp lại vector logic nhiều lần nữa trong các chương tiếp theo. Ví dụ trong Chương 14 bạn sẽ học về str_detect(x, pattern) trả về một vector logic là TRUE cho các phần tử của x khớp với pattern, và trong Chương 17 bạn sẽ tạo vector logic từ phép so sánh ngày và giờ. Nhưng bây giờ, chúng ta sẽ chuyển sang loại vector quan trọng tiếp theo: vector số.
R thường tự gọi print cho bạn (tức là
xlà cách viết tắt củaprint(x)), nhưng việc gọi tường minh sẽ hữu ích nếu bạn muốn cung cấp các argument khác.↩︎Nghĩa là
xor(x, y)đúng nếu x đúng, hoặc y đúng, nhưng không phải cả hai. Đây là cách chúng ta thường sử dụng “hoặc” trong tiếng Anh. “Cả hai” thường không phải là câu trả lời chấp nhận được cho câu hỏi “bạn muốn kem hay bánh?”.↩︎if_else()của dplyr rất giống vớiifelse()của base R. Có hai ưu điểm chính củaif_else()so vớiifelse(): bạn có thể chọn điều gì xảy ra với missing value, vàif_else()có nhiều khả năng hơn để đưa ra lỗi có ý nghĩa nếu các biến của bạn có kiểu không tương thích.↩︎