25 Function
25.1 Giới thiệu
Một trong những cách tốt nhất để mở rộng khả năng của bạn với tư cách là nhà khoa học dữ liệu là viết function (function). Function cho phép bạn tự động hóa các tác vụ thường gặp theo cách mạnh mẽ và tổng quát hơn so với sao chép-dán. Viết function có bốn lợi thế lớn so với sao chép-dán:
Bạn có thể đặt cho function một cái tên gợi nhớ giúp mã của bạn dễ hiểu hơn.
Khi yêu cầu thay đổi, bạn chỉ cần cập nhật mã ở một nơi, thay vì nhiều nơi.
Bạn loại bỏ nguy cơ mắc lỗi vặt khi sao chép và dán (ví dụ: cập nhật tên biến ở một chỗ nhưng quên chỗ khác).
Việc tái sử dụng công việc từ dự án này sang dự án khác trở nên dễ dàng hơn, tăng năng suất theo thời gian.
Một quy tắc hữu ích là hãy cân nhắc viết function bất cứ khi nào bạn đã sao chép-dán một đoạn mã hơn hai lần (tức là bạn có ba bản sao của cùng một đoạn mã). Trong chương này, bạn sẽ học về ba loại function hữu ích:
- Function vector nhận một hoặc nhiều vector làm đầu vào và trả về một vector làm đầu ra.
- Function data frame nhận một data frame làm đầu vào và trả về một data frame làm đầu ra.
- Function biểu đồ nhận một data frame làm đầu vào và trả về một biểu đồ làm đầu ra.
Mỗi phần này bao gồm nhiều ví dụ giúp bạn tổng quát hóa các mẫu mà bạn thấy. Những ví dụ này sẽ không thể có được nếu thiếu sự giúp đỡ của mọi người trên Twitter, và chúng tôi khuyến khích bạn theo các liên kết trong phần bình luận để xem nguồn cảm hứng gốc. Bạn cũng có thể muốn đọc các tweet gốc tạo động lực cho hàm tổng quát và hàm vẽ biểu đồ để xem thêm nhiều function nữa.
25.1.1 Điều kiện tiên quyết
Chúng ta sẽ sử dụng nhiều function khác nhau từ tidyverse. Chúng ta cũng sẽ dùng nycflights13 làm nguồn dữ liệu quen thuộc để sử dụng với các function của mình.
25.2 Function vector
Chúng ta sẽ bắt đầu với function vector: các function nhận một hoặc nhiều vector và trả về một kết quả dạng vector. Ví dụ, hãy xem đoạn mã này. Nó làm gì?
df <- tibble(
a = rnorm(5),
b = rnorm(5),
c = rnorm(5),
d = rnorm(5),
)
df |> mutate(
a = (a - min(a, na.rm = TRUE)) /
(max(a, na.rm = TRUE) - min(a, na.rm = TRUE)),
b = (b - min(a, na.rm = TRUE)) /
(max(b, na.rm = TRUE) - min(b, na.rm = TRUE)),
c = (c - min(c, na.rm = TRUE)) /
(max(c, na.rm = TRUE) - min(c, na.rm = TRUE)),
d = (d - min(d, na.rm = TRUE)) /
(max(d, na.rm = TRUE) - min(d, na.rm = TRUE)),
)
#> # A tibble: 5 × 4
#> a b c d
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.339 0.387 0.291 0
#> 2 0.880 -0.613 0.611 0.557
#> 3 0 -0.0833 1 0.752
#> 4 0.795 -0.0822 0 1
#> 5 1 -0.0952 0.580 0.394Bạn có thể đoán ra rằng đoạn mã này co giãn (rescale) mỗi column về khoảng từ 0 đến 1. Nhưng bạn có phát hiện ra lỗi không? Khi Hadley viết đoạn mã này, ông đã mắc lỗi khi sao chép-dán và quên đổi a thành b. Ngăn ngừa loại lỗi này là một lý do rất tốt để học cách viết function.
25.2.1 Viết một function
Để viết một function, trước tiên bạn cần phân tích mã iterate lại để tìm ra phần nào là hằng và phần nào thay đổi. Nếu chúng ta lấy đoạn mã ở trên và đưa ra ngoài mutate(), sẽ dễ thấy mẫu hơn vì mỗi lần iterate giờ chỉ là một dòng:
Để rõ ràng hơn, chúng ta có thể thay phần thay đổi bằng █:
(█ - min(█, na.rm = TRUE)) / (max(█, na.rm = TRUE) - min(█, na.rm = TRUE))Để biến đoạn mã này thành function, bạn cần ba thứ:
Một tên. Ở đây chúng ta sẽ dùng
rescale01vì function này co giãn một vector về khoảng từ 0 đến 1.Các argument (argument). Đối số là những thứ thay đổi giữa các lần gọi và phân tích ở trên cho ta biết rằng chỉ có một argument. Chúng ta sẽ gọi nó là
xvì đây là tên quy ước cho vector số.Thân hàm (body). Thân function là đoạn mã được iterate lại qua tất cả các lần gọi.
Sau đó bạn tạo function bằng cách theo mẫu:
name <- function(arguments) {
body
}Trong trường hợp này ta có:
Tại thời điểm này bạn có thể kiểm tra với một vài đầu vào đơn giản để đảm bảo đã nắm bắt đúng logic:
Sau đó bạn có thể viết lại lời gọi mutate() như sau:
df |> mutate(
a = rescale01(a),
b = rescale01(b),
c = rescale01(c),
d = rescale01(d),
)
#> # A tibble: 5 × 4
#> a b c d
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.339 1 0.291 0
#> 2 0.880 0 0.611 0.557
#> 3 0 0.530 1 0.752
#> 4 0.795 0.531 0 1
#> 5 1 0.518 0.580 0.394(Trong Chương 26, bạn sẽ học cách dùng across() để giảm sự trùng iterate hơn nữa, chỉ cần df |> mutate(across(a:d, rescale01))).
25.2.2 Cải thiện function của chúng ta
Bạn có thể nhận thấy rằng function rescale01() thực hiện một số công việc không cần thiết — thay vì tính min() hai lần và max() một lần, chúng ta có thể tính cả giá trị nhỏ nhất và lớn nhất trong một bước với range():
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}Hoặc bạn có thể thử function này trên một vector có chứa giá trị vô hạn:
x <- c(1:10, Inf)
rescale01(x)
#> [1] 0 0 0 0 0 0 0 0 0 0 NaNKết quả đó không hữu ích lắm nên chúng ta có thể yêu cầu range() bỏ qua các giá trị vô hạn:
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE, finite = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
rescale01(x)
#> [1] 0.0000000 0.1111111 0.2222222 0.3333333 0.4444444 0.5555556 0.6666667
#> [8] 0.7777778 0.8888889 1.0000000 InfNhững thay đổi này minh họa một lợi ích quan trọng của function: vì chúng ta đã chuyển mã iterate lại vào một function, chúng ta chỉ cần thay đổi ở một nơi duy nhất.
25.2.3 Function mutate
Bây giờ bạn đã nắm ý tưởng cơ bản về function, hãy xem qua row loạt ví dụ. Chúng ta sẽ bắt đầu bằng việc xem các function “mutate”, tức là các function hoạt động tốt bên trong mutate() và filter() vì chúng trả về đầu ra có cùng độ dài với đầu vào.
Hãy bắt đầu với một biến thể đơn giản của rescale01(). Có thể bạn muốn tính điểm Z (Z-score), co giãn một vector để có trung bình bằng không và độ lệch chuẩn bằng một:
Hoặc có thể bạn muốn gói gọn một case_when() đơn giản và đặt cho nó một cái tên hữu ích. Ví dụ, function clamp() này đảm bảo tất cả giá trị của một vector nằm giữa một giá trị nhỏ nhất và lớn nhất:
clamp <- function(x, min, max) {
case_when(
x < min ~ min,
x > max ~ max,
.default = x
)
}
clamp(1:10, min = 3, max = 7)
#> [1] 3 3 3 4 5 6 7 7 7 7Tất nhiên function không chỉ cần làm việc với biến số. Bạn có thể muốn thực hiện một số thao tác xử lý string (string) iterate đi iterate lại. Có thể bạn cần viết hoa ký tự đầu tiên:
first_upper <- function(x) {
str_sub(x, 1, 1) <- str_to_upper(str_sub(x, 1, 1))
x
}
first_upper("hello")
#> [1] "Hello"Hoặc có thể bạn muốn loại bỏ dấu phần trăm, dấu phẩy, và ký hiệu đô la khỏi một string trước khi chuyển đổi thành số:
# https://twitter.com/NVlabormarket/status/1571939851922198530
clean_number <- function(x) {
is_pct <- str_detect(x, "%")
num <- x |>
str_remove_all("%") |>
str_remove_all(",") |>
str_remove_all(fixed("$")) |>
as.numeric()
if_else(is_pct, num / 100, num)
}
clean_number("$12,300")
#> [1] 12300
clean_number("45%")
#> [1] 0.45Đôi khi function của bạn sẽ rất chuyên biệt cho một bước phân tích dữ liệu cụ thể. Ví dụ, nếu bạn có nhiều biến ghi nhận missing value (missing value) bằng 997, 998, hoặc 999, bạn có thể muốn viết một function để thay thế chúng bằng NA:
Chúng tôi đã tập trung vào các ví dụ nhận một vector duy nhất vì chúng tôi nghĩ đây là trường hợp phổ biến nhất. Nhưng không có lý do gì mà function của bạn không thể nhận nhiều vector đầu vào.
25.2.4 Function tóm tắt
Một họ function vector quan trọng khác là function tóm tắt (summary function), các function trả về một giá trị duy nhất để sử dụng trong summarize(). Đôi khi điều này chỉ đơn giản là đặt một hoặc hai argument mặc định:
commas <- function(x) {
str_flatten(x, collapse = ", ", last = " and ")
}
commas(c("cat", "dog", "pigeon"))
#> [1] "cat, dog and pigeon"Hoặc bạn có thể gói gọn một phép tính đơn giản, như hệ số biến thiên (coefficient of variation), chia độ lệch chuẩn cho trung bình:
Hoặc có thể bạn chỉ muốn làm cho một mẫu thường gặp dễ nhớ hơn bằng cách đặt cho nó một cái tên dễ nhớ:
Bạn cũng có thể viết function với nhiều vector đầu vào. Ví dụ, có thể bạn muốn tính sai số phần trăm tuyệt đối trung bình (mean absolute percentage error) để so sánh dự đoán của mô hình với giá trị thực:
Khi bạn bắt đầu viết function, có hai phím tắt RStudio cực kỳ hữu ích:
Để tìm định nghĩa của một function bạn đã viết, đặt con trỏ lên tên function và nhấn
F2.Để nhảy nhanh đến một function, nhấn
Ctrl + .để mở công cụ tìm kiếm mờ (fuzzy finder) cho file và function, rồi gõ vài ký tự đầu của tên function. Bạn cũng có thể điều hướng đến các file, phần Quarto, và nhiều thứ khác, khiến đây trở thành một công cụ điều hướng rất tiện lợi.
25.2.5 Bài tập
-
Thực hành biến các đoạn mã sau thành function. Hãy nghĩ xem mỗi function làm gì. Bạn sẽ đặt tên gì cho nó? Nó cần bao nhiêu argument?
Trong biến thể thứ hai của
rescale01(), các giá trị vô hạn bị giữ nguyên. Bạn có thể viết lạirescale01()sao cho-Infđược mapping thành 0, vàInfđược mapping thành 1 không?Cho một vector ngày sinh, hãy viết một function để tính tuổi theo năm.
Hãy viết function riêng của bạn để tính phương sai (variance) và độ lệch (skewness) của một vector số. Bạn có thể tra cứu định nghĩa trên Wikipedia hoặc nơi khác.
Viết function
both_na(), một function tóm tắt nhận hai vector cùng độ dài và trả về số vị trí mà cả hai vector đều cóNA.-
Đọc tài liệu để tìm hiểu các function sau làm gì. Tại sao chúng hữu ích mặc dù rất ngắn?
is_directory <- function(x) { file.info(x)$isdir } is_readable <- function(x) { file.access(x, 4) == 0 }
25.3 Function data frame
Function vector hữu ích để tách ra mã iterate lại bên trong một động từ dplyr. Nhưng bạn thường cũng iterate lại chính các động từ, đặc biệt trong một pipeline lớn. Khi bạn nhận thấy mình sao chép-dán nhiều động từ nhiều lần, bạn có thể nghĩ đến việc viết một function data frame. Function data frame hoạt động giống các động từ dplyr: chúng nhận một data frame làm argument đầu tiên, một số argument bổ sung cho biết phải làm gì với nó, và trả về một data frame hoặc một vector.
Để cho phép bạn viết function sử dụng các động từ dplyr, trước tiên chúng tôi sẽ giới thiệu thách thức của tham chiếu gián tiếp (indirection) và cách bạn có thể vượt qua nó bằng cách ôm (embracing), { }. Với lý thuyết này trong tay, chúng ta sẽ chỉ cho bạn row loạt ví dụ để minh họa những gì bạn có thể làm với nó.
25.3.1 Tham chiếu gián tiếp và đánh giá gọn gàng (tidy evaluation)
Khi bạn bắt đầu viết function sử dụng các động từ dplyr, bạn nhanh chóng gặp phải vấn đề tham chiếu gián tiếp. Hãy minh họa vấn đề với một function rất đơn giản: grouped_mean(). Mục tiêu của function này là tính trung bình của mean_var theo nhóm group_var:
Nếu chúng ta thử sử dụng nó, ta sẽ nhận được lỗi:
diamonds |> grouped_mean(cut, carat)
#> Error in `group_by()`:
#> ! Must group by variables found in `.data`.
#> ✖ Column `group_var` is not found.Để vấn đề rõ ràng hơn, chúng ta có thể dùng một data frame tự tạo:
df <- tibble(
mean_var = 1,
group_var = "g",
group = 1,
x = 10,
y = 100
)
df |> grouped_mean(group, x)
#> # A tibble: 1 × 2
#> group_var `mean(mean_var)`
#> <chr> <dbl>
#> 1 g 1
df |> grouped_mean(group, y)
#> # A tibble: 1 × 2
#> group_var `mean(mean_var)`
#> <chr> <dbl>
#> 1 g 1Bất kể chúng ta gọi grouped_mean() thế nào, nó luôn thực hiện df |> group_by(group_var) |> summarize(mean(mean_var)), thay vì df |> group_by(group) |> summarize(mean(x)) hay df |> group_by(group) |> summarize(mean(y)). Đây là vấn đề tham chiếu gián tiếp, và nó phát sinh vì dplyr sử dụng đánh giá gọn gàng (tidy evaluation) để cho phép bạn tham chiếu đến tên biến bên trong data frame mà không cần xử lý đặc biệt.
Đánh giá gọn gàng tuyệt vời trong 95% trường hợp vì nó giúp phân tích dữ liệu của bạn rất gọn gàng — bạn không bao giờ phải nói biến đến từ data frame nào; điều đó hiển nhiên từ ngữ cảnh. Nhược điểm của đánh giá gọn gàng xuất hiện khi chúng ta muốn gói gọn mã tidyverse iterate lại vào một function. Ở đây chúng ta cần một cách nào đó để nói với group_by() và summarize() đừng coi group_var và mean_var là tên biến, mà thay vào đó hãy nhìn vào bên trong chúng để tìm biến mà chúng ta thực sự muốn dùng.
Đánh giá gọn gàng bao gồm giải pháp cho vấn đề này gọi là ôm (embracing) 🤗. Ôm một biến nghĩa là bọc nó trong dấu ngoặc nhọn, ví dụ var trở thành { var }. Ôm một biến cho dplyr biết hãy sử dụng giá trị được lưu bên trong argument, chứ không phải argument như tên biến trực tiếp. Một cách để nhớ điều đang xảy ra là nghĩ { } như nhìn qua một đường hầm — { var } sẽ khiến function dplyr nhìn vào bên trong var thay vì tìm kiếm một biến có tên var.
Vậy để grouped_mean() hoạt động, chúng ta cần bao quanh group_var và mean_var bằng { }:
Thành công!
25.3.2 Khi nào cần ôm?
Vậy thách thức chính khi viết function data frame là xác định argument nào cần được ôm. May mắn thay, điều này rất dễ vì bạn có thể tra cứu trong tài liệu 😄. Có hai thuật ngữ cần tìm trong tài liệu, tương ứng với hai kiểu phụ phổ biến nhất của đánh giá gọn gàng:
Che dữ liệu (Data-masking): được dùng trong các function như
arrange(),filter(), vàsummarize()— các function tính toán với biến.Chọn gọn gàng (Tidy-selection): được dùng trong các function như
select(),relocate(), vàrename()— các function chọn biến.
Trực giác của bạn về argument nào sử dụng đánh giá gọn gàng sẽ đúng cho nhiều function phổ biến — chỉ cần nghĩ xem bạn có thể tính toán (ví dụ: x + 1) hay chọn (ví dụ: a:x).
Trong các phần tiếp theo, chúng ta sẽ khám phá các loại function tiện ích mà bạn có thể viết khi đã hiểu về ôm.
25.3.3 Các trường hợp sử dụng phổ biến
Nếu bạn thường thực hiện cùng một bộ tóm tắt khi khám phá dữ liệu ban đầu, bạn có thể cân nhắc gói gọn chúng vào một function trợ giúp:
summary6 <- function(data, var) {
data |> summarize(
min = min({{ var }}, na.rm = TRUE),
mean = mean({{ var }}, na.rm = TRUE),
median = median({{ var }}, na.rm = TRUE),
max = max({{ var }}, na.rm = TRUE),
n = n(),
n_miss = sum(is.na({{ var }})),
.groups = "drop"
)
}
diamonds |> summary6(carat)
#> # A tibble: 1 × 6
#> min mean median max n n_miss
#> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 0.2 0.798 0.7 5.01 53940 0(Bất cứ khi nào bạn gói summarize() trong một function trợ giúp, chúng tôi nghĩ đặt .groups = "drop" là một thực hành tốt để vừa tránh thông báo vừa để dữ liệu ở trạng thái không nhóm.)
Điều hay của function này là, vì nó bọc summarize(), bạn có thể dùng nó trên dữ liệu đã nhóm:
diamonds |>
group_by(cut) |>
summary6(carat)
#> # A tibble: 5 × 7
#> cut min mean median max n n_miss
#> <ord> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 Fair 0.22 1.05 1 5.01 1610 0
#> 2 Good 0.23 0.849 0.82 3.01 4906 0
#> 3 Very Good 0.2 0.806 0.71 4 12082 0
#> 4 Premium 0.2 0.892 0.86 4.01 13791 0
#> 5 Ideal 0.2 0.703 0.54 3.5 21551 0Hơn nữa, vì các argument của summarize() sử dụng che dữ liệu, argument var của summary6() cũng vậy. Điều đó có nghĩa bạn cũng có thể tóm tắt các biến được tính toán:
diamonds |>
group_by(cut) |>
summary6(log10(carat))
#> # A tibble: 5 × 7
#> cut min mean median max n n_miss
#> <ord> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 Fair -0.658 -0.0273 0 0.700 1610 0
#> 2 Good -0.638 -0.133 -0.0862 0.479 4906 0
#> 3 Very Good -0.699 -0.164 -0.149 0.602 12082 0
#> 4 Premium -0.699 -0.125 -0.0655 0.603 13791 0
#> 5 Ideal -0.699 -0.225 -0.268 0.544 21551 0Để tóm tắt nhiều biến, bạn sẽ cần đợi đến Phần 26.2, nơi bạn sẽ học cách dùng across().
Một function trợ giúp summarize() phổ biến khác là phiên bản của count() cũng tính tỷ lệ:
# https://twitter.com/Diabb6/status/1571635146658402309
count_prop <- function(df, var, sort = FALSE) {
df |>
count({{ var }}, sort = sort) |>
mutate(prop = n / sum(n))
}
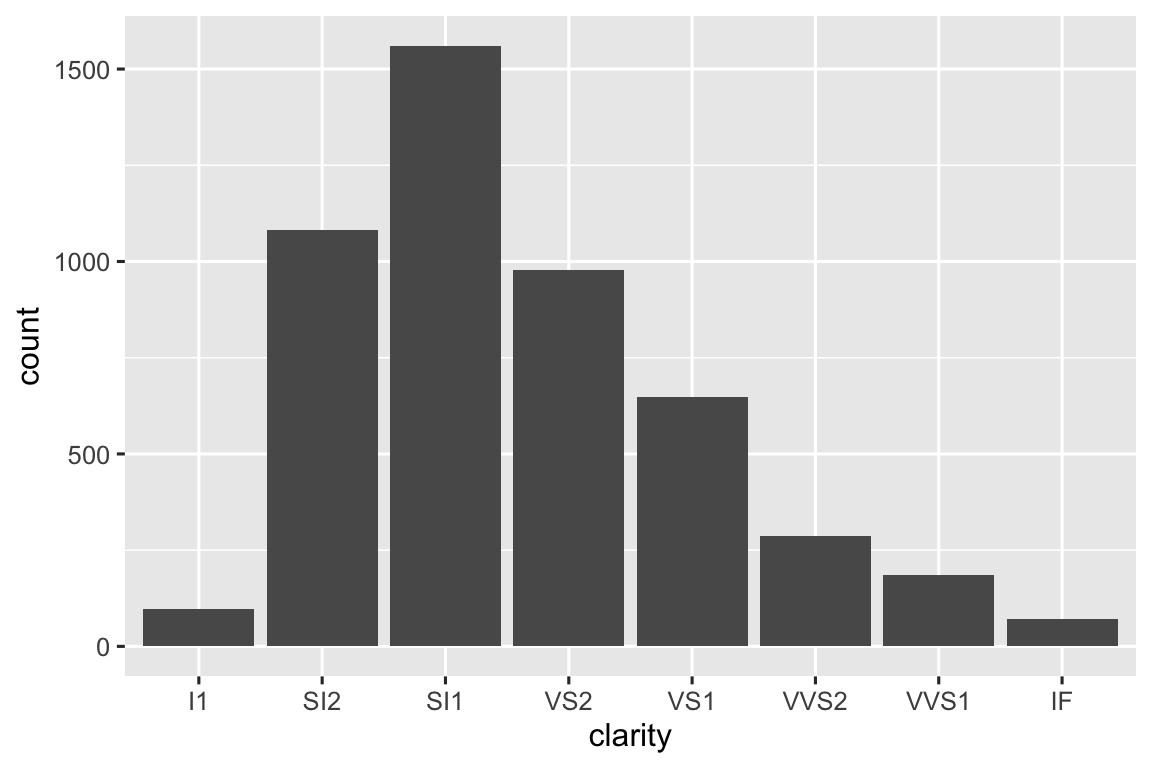
diamonds |> count_prop(clarity)
#> # A tibble: 8 × 3
#> clarity n prop
#> <ord> <int> <dbl>
#> 1 I1 741 0.0137
#> 2 SI2 9194 0.170
#> 3 SI1 13065 0.242
#> 4 VS2 12258 0.227
#> 5 VS1 8171 0.151
#> 6 VVS2 5066 0.0939
#> # ℹ 2 more rowsFunction này có ba argument: df, var, và sort, và chỉ var cần được ôm vì nó được truyền cho count() — function sử dụng che dữ liệu cho tất cả biến. Lưu ý rằng chúng ta dùng giá trị mặc định cho sort để nếu người dùng không cung cấp giá trị riêng, nó sẽ mặc định là FALSE.
Hoặc có thể bạn muốn tìm các giá trị duy nhất đã sắp xếp của một biến cho một tập con của dữ liệu. Thay vì cung cấp một biến và một giá trị để lọc, chúng ta sẽ cho phép người dùng cung cấp một điều kiện:
unique_where <- function(df, condition, var) {
df |>
filter({{ condition }}) |>
distinct({{ var }}) |>
arrange({{ var }})
}
# Tìm tất cả điểm đến trong tháng 12
flights |> unique_where(month == 12, dest)
#> # A tibble: 96 × 1
#> dest
#> <chr>
#> 1 ABQ
#> 2 ALB
#> 3 ATL
#> 4 AUS
#> 5 AVL
#> 6 BDL
#> # ℹ 90 more rowsỞ đây chúng ta ôm condition vì nó được truyền cho filter() và var vì nó được truyền cho distinct() và arrange().
Chúng ta đã tạo tất cả các ví dụ này nhận data frame làm argument đầu tiên, nhưng nếu bạn làm việc liên tục với cùng một dữ liệu, việc cố định nó có thể hợp lý. Ví dụ, function sau luôn làm việc với tập dữ liệu flights và luôn chọn time_hour, carrier, và flight vì chúng tạo thành khóa chính kết hợp cho phép bạn xác định một row.
25.3.4 Che dữ liệu so với chọn gọn gàng
Đôi khi bạn muốn chọn biến bên trong một function sử dụng che dữ liệu. Ví dụ, hãy tưởng tượng bạn muốn viết function count_missing() đếm số quan sát khuyết trong các row. Bạn có thể thử viết như sau:
count_missing <- function(df, group_vars, x_var) {
df |>
group_by({{ group_vars }}) |>
summarize(
n_miss = sum(is.na({{ x_var }})),
.groups = "drop"
)
}
flights |>
count_missing(c(year, month, day), dep_time)
#> Error in `group_by()`:
#> ℹ In argument: `c(year, month, day)`.
#> Caused by error:
#> ! `c(year, month, day)` must be size 336776 or 1, not 1010328.Điều này không hoạt động vì group_by() sử dụng che dữ liệu, không phải chọn gọn gàng. Chúng ta có thể giải quyết vấn đề đó bằng function tiện ích pick(), cho phép bạn sử dụng chọn gọn gàng bên trong các function che dữ liệu:
count_missing <- function(df, group_vars, x_var) {
df |>
group_by(pick({{ group_vars }})) |>
summarize(
n_miss = sum(is.na({{ x_var }})),
.groups = "drop"
)
}
flights |>
count_missing(c(year, month, day), dep_time)
#> # A tibble: 365 × 4
#> year month day n_miss
#> <int> <int> <int> <int>
#> 1 2013 1 1 4
#> 2 2013 1 2 8
#> 3 2013 1 3 10
#> 4 2013 1 4 6
#> 5 2013 1 5 3
#> 6 2013 1 6 1
#> # ℹ 359 more rowsMột cách sử dụng tiện lợi khác của pick() là tạo bảng đếm 2 chiều. Ở đây chúng ta đếm sử dụng tất cả các biến trong rows và columns, sau đó dùng pivot_wider() để sắp xếp lại số đếm thành lưới:
# https://twitter.com/pollicipes/status/1571606508944719876
count_wide <- function(data, rows, cols) {
data |>
count(pick(c({{ rows }}, {{ cols }}))) |>
pivot_wider(
names_from = {{ cols }},
values_from = n,
names_sort = TRUE,
values_fill = 0
)
}
diamonds |> count_wide(c(clarity, color), cut)
#> # A tibble: 56 × 7
#> clarity color Fair Good `Very Good` Premium Ideal
#> <ord> <ord> <int> <int> <int> <int> <int>
#> 1 I1 D 4 8 5 12 13
#> 2 I1 E 9 23 22 30 18
#> 3 I1 F 35 19 13 34 42
#> 4 I1 G 53 19 16 46 16
#> 5 I1 H 52 14 12 46 38
#> 6 I1 I 34 9 8 24 17
#> # ℹ 50 more rowsMặc dù các ví dụ của chúng ta chủ yếu tập trung vào dplyr, đánh giá gọn gàng cũng là nền tảng của tidyr, và nếu bạn xem tài liệu pivot_wider() bạn sẽ thấy rằng names_from sử dụng chọn gọn gàng.
25.3.5 Bài tập
-
Sử dụng các tập dữ liệu từ nycflights13, hãy viết một function:
-
Tìm tất cả chuyến bay bị hủy (tức là
is.na(arr_time)) hoặc bị trễ hơn một giờ.flights |> filter_severe() -
Đếm số chuyến bay bị hủy và số chuyến bay bị trễ hơn một giờ.
flights |> group_by(dest) |> summarize_severe() -
Tìm tất cả chuyến bay bị hủy hoặc bị trễ hơn số giờ do người dùng chỉ định:
flights |> filter_severe(hours = 2) -
Tóm tắt dữ liệu thời tiết để tính giá trị nhỏ nhất, trung bình, và lớn nhất của một biến do người dùng chỉ định:
weather |> summarize_weather(temp) -
Chuyển đổi biến do người dùng chỉ định sử dụng thời gian đồng hồ (ví dụ:
dep_time,arr_time, v.v.) thành thời gian thập phân (tức là giờ + (phút / 60)).flights |> standardize_time(sched_dep_time)
-
Với mỗi function sau, hãy liệt kê tất cả argument sử dụng đánh giá gọn gàng và mô tả chúng dùng che dữ liệu hay chọn gọn gàng:
distinct(),count(),group_by(),rename_with(),slice_min(),slice_sample().-
Tổng quát hóa function sau để bạn có thể cung cấp bất kỳ số lượng biến nào để đếm.
25.4 Function biểu đồ
Thay vì trả về một data frame, bạn có thể muốn trả về một biểu đồ (plot). May mắn thay, bạn có thể sử dụng cùng các kỹ thuật với ggplot2, vì aes() là một function che dữ liệu. Ví dụ, hãy tưởng tượng bạn đang tạo nhiều biểu đồ tần suất (histogram):
diamonds |>
ggplot(aes(x = carat)) +
geom_histogram(binwidth = 0.1)
diamonds |>
ggplot(aes(x = carat)) +
geom_histogram(binwidth = 0.05)Sẽ thật tuyệt nếu bạn có thể gói gọn điều này thành một function biểu đồ tần suất? Điều này dễ như ăn bánh khi bạn biết rằng aes() là function che dữ liệu và bạn cần ôm:
histogram <- function(df, var, binwidth = NULL) {
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth)
}
diamonds |> histogram(carat, 0.1)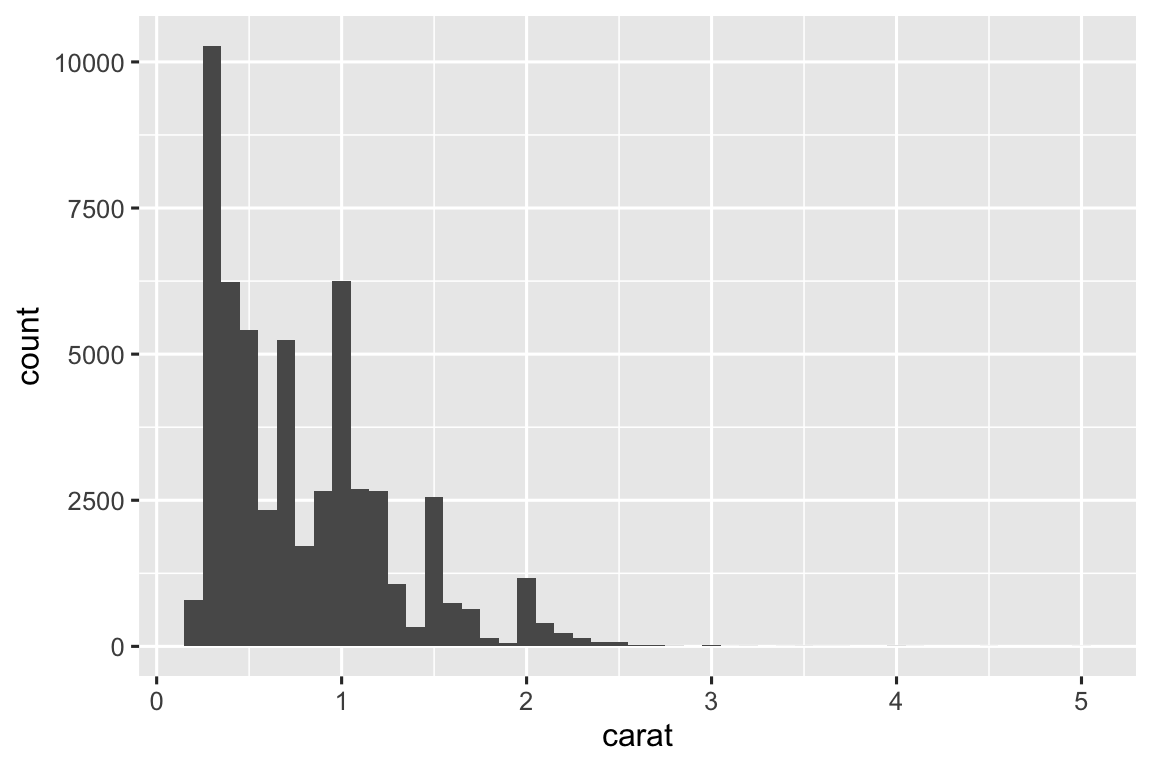
Lưu ý rằng histogram() trả về một biểu đồ ggplot2, có nghĩa bạn vẫn có thể thêm các thành phần bổ sung nếu muốn. Chỉ nhớ chuyển từ |> sang +:
diamonds |>
histogram(carat, 0.1) +
labs(x = "Size (in carats)", y = "Number of diamonds")25.4.1 Thêm biến
Việc thêm nhiều biến vào hỗn hợp rất đơn giản. Ví dụ, có thể bạn muốn một cách dễ dàng để xem bằng mắt liệu một tập dữ liệu có tuyến tính hay không bằng cách chồng một đường cong mượt và một đường thẳng:
# https://twitter.com/tyler_js_smith/status/1574377116988104704
linearity_check <- function(df, x, y) {
df |>
ggplot(aes(x = {{ x }}, y = {{ y }})) +
geom_point() +
geom_smooth(method = "loess", formula = y ~ x, color = "red", se = FALSE) +
geom_smooth(method = "lm", formula = y ~ x, color = "blue", se = FALSE)
}
starwars |>
filter(mass < 1000) |>
linearity_check(mass, height)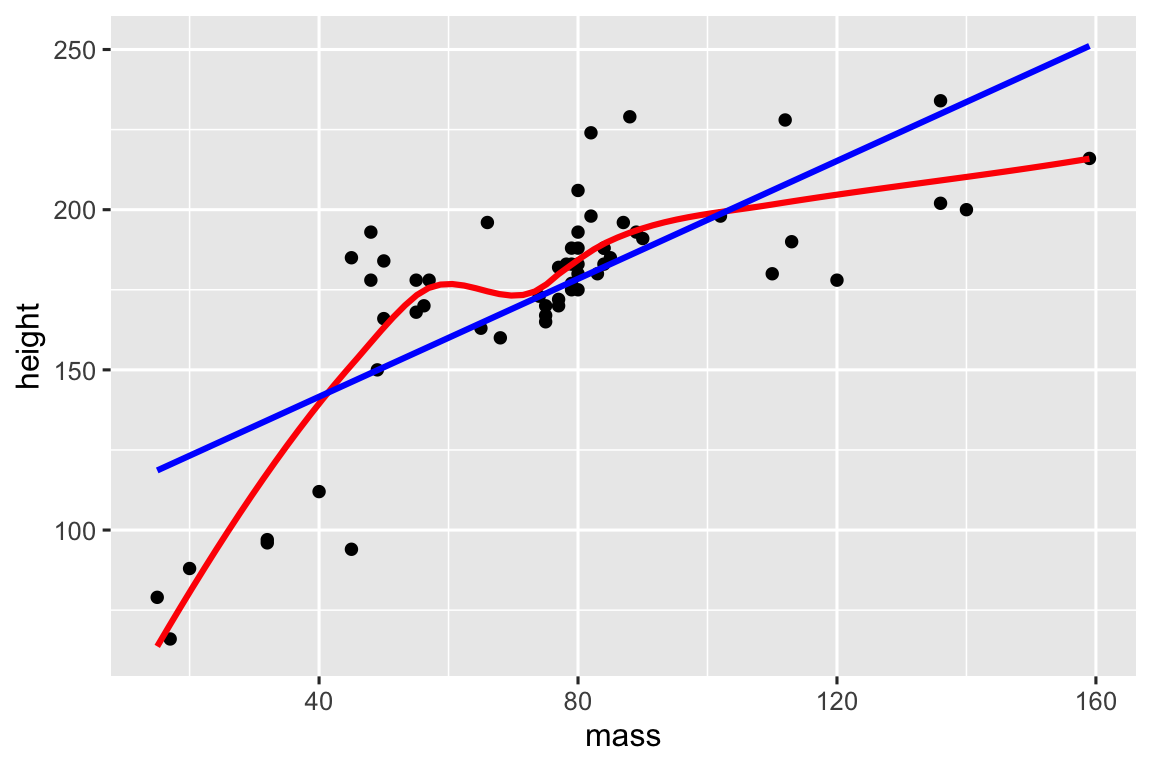
Hoặc có thể bạn muốn một giải pháp thay thế cho biểu đồ phân tán có màu dành cho tập dữ liệu rất lớn khi chồng chéo điểm là một vấn đề:
# https://twitter.com/ppaxisa/status/1574398423175921665
hex_plot <- function(df, x, y, z, bins = 20, fun = "mean") {
df |>
ggplot(aes(x = {{ x }}, y = {{ y }}, z = {{ z }})) +
stat_summary_hex(
aes(color = after_scale(fill)), # làm viền cùng màu với nền
bins = bins,
fun = fun,
)
}
diamonds |> hex_plot(carat, price, depth)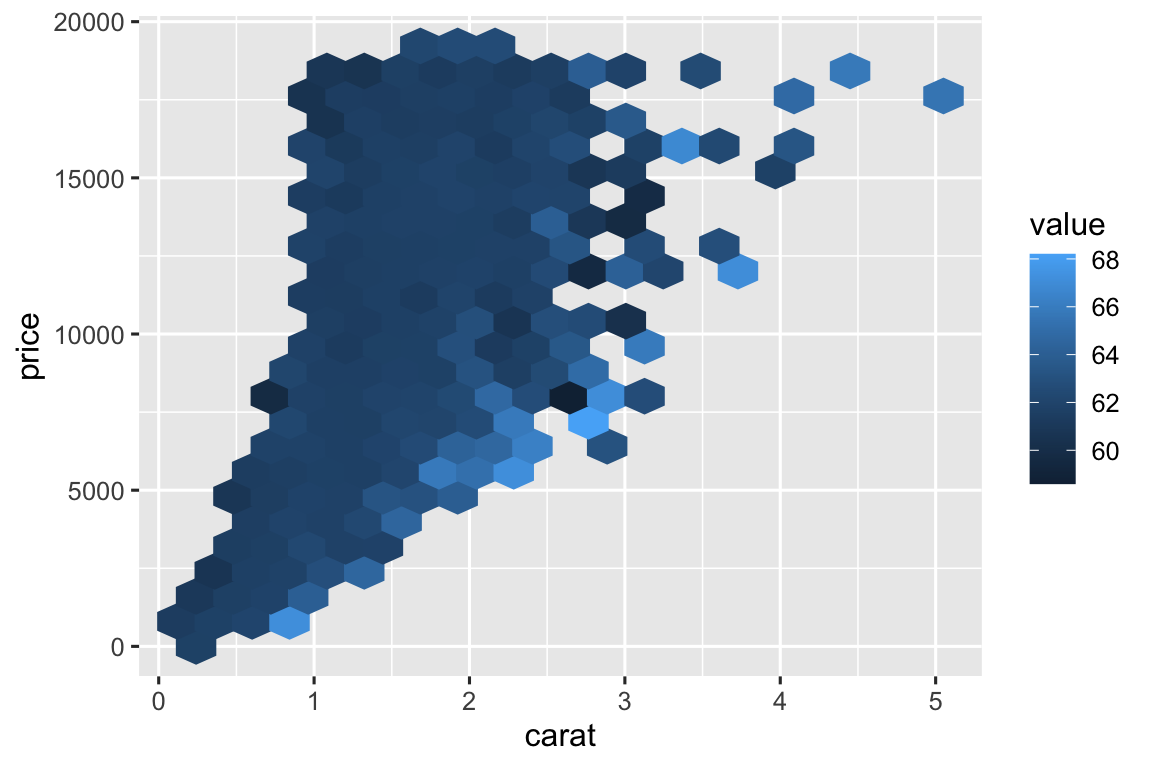
25.4.2 Kết hợp với tidyverse khác
Một số function trợ giúp hữu ích nhất kết hợp một chút xử lý dữ liệu với ggplot2. Ví dụ, có thể bạn muốn tạo biểu đồ column dọc trong đó bạn tự động sắp xếp các column theo thứ tự tần suất sử dụng fct_infreq(). Vì biểu đồ column là dọc, chúng ta cũng cần đảo ngược thứ tự thông thường để giá trị cao nhất ở trên cùng:
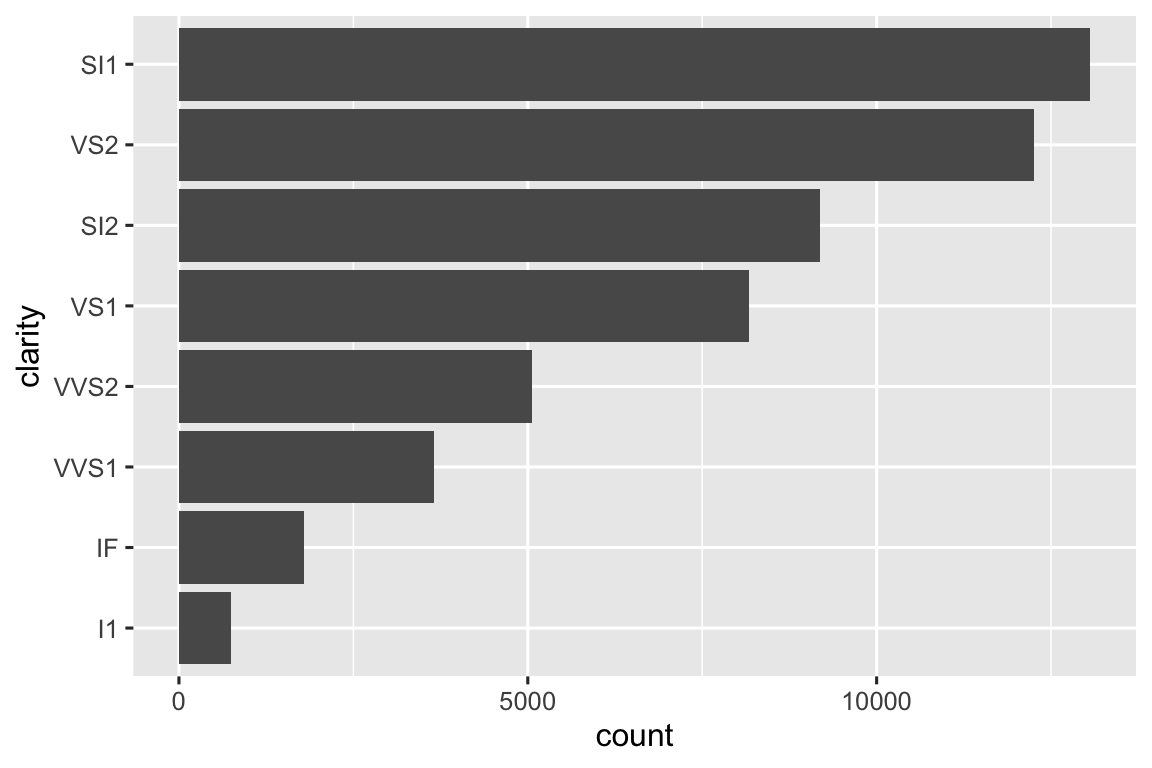
Chúng ta phải sử dụng một toán tử mới ở đây, := (thường được gọi là “toán tử hải mã”), vì chúng ta đang tạo tên biến dựa trên dữ liệu do người dùng cung cấp. Tên biến nằm ở vế trái của =, nhưng cú pháp R không cho phép bất kỳ thứ gì ở vế trái = ngoại trừ một tên trực tiếp đơn lẻ. Để giải quyết vấn đề này, chúng ta dùng toán tử đặc biệt := mà đánh giá gọn gàng xử lý giống hệt =.
Hoặc có thể bạn muốn dễ dàng vẽ biểu đồ column chỉ cho một tập con của dữ liệu:
Bạn cũng có thể sáng tạo và hiển thị tóm tắt dữ liệu theo những cách khác. Bạn có thể tìm một ứng dụng thú vị tại https://gist.github.com/GShotwell/b19ef520b6d56f61a830fabb3454965b; nó sử dụng nhãn trục để hiển thị giá trị cao nhất. Khi bạn học thêm về ggplot2, sức mạnh của các function bạn viết sẽ tiếp tục tăng lên.
Chúng ta sẽ kết thúc với một trường hợp phức tạp hơn: gắn nhãn cho các biểu đồ bạn tạo ra.
25.4.3 Gắn nhãn
Bạn còn nhớ function biểu đồ tần suất chúng tôi đã chỉ bạn trước đó?
histogram <- function(df, var, binwidth = NULL) {
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth)
}Sẽ thật tuyệt nếu chúng ta có thể gắn nhãn cho đầu ra với biến và độ rộng bin đã sử dụng? Để làm điều này, chúng ta sẽ phải đi sâu vào bên trong đánh giá gọn gàng và sử dụng một function từ package chúng ta chưa nói đến: rlang. rlang là một package cấp thấp được sử dụng bởi hầu hết mọi package khác trong tidyverse vì nó triển khai đánh giá gọn gàng (cùng nhiều công cụ hữu ích khác).
Để giải quyết vấn đề gắn nhãn, chúng ta có thể dùng rlang::englue(). Function này hoạt động tương tự str_glue(), nên bất kỳ giá trị nào được bọc trong { } sẽ được chèn vào string. Nhưng nó cũng hiểu { }, tự động chèn tên biến phù hợp:
histogram <- function(df, var, binwidth) {
label <- rlang::englue("A histogram of {{var}} with binwidth {binwidth}")
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth) +
labs(title = label)
}
diamonds |> histogram(carat, 0.1)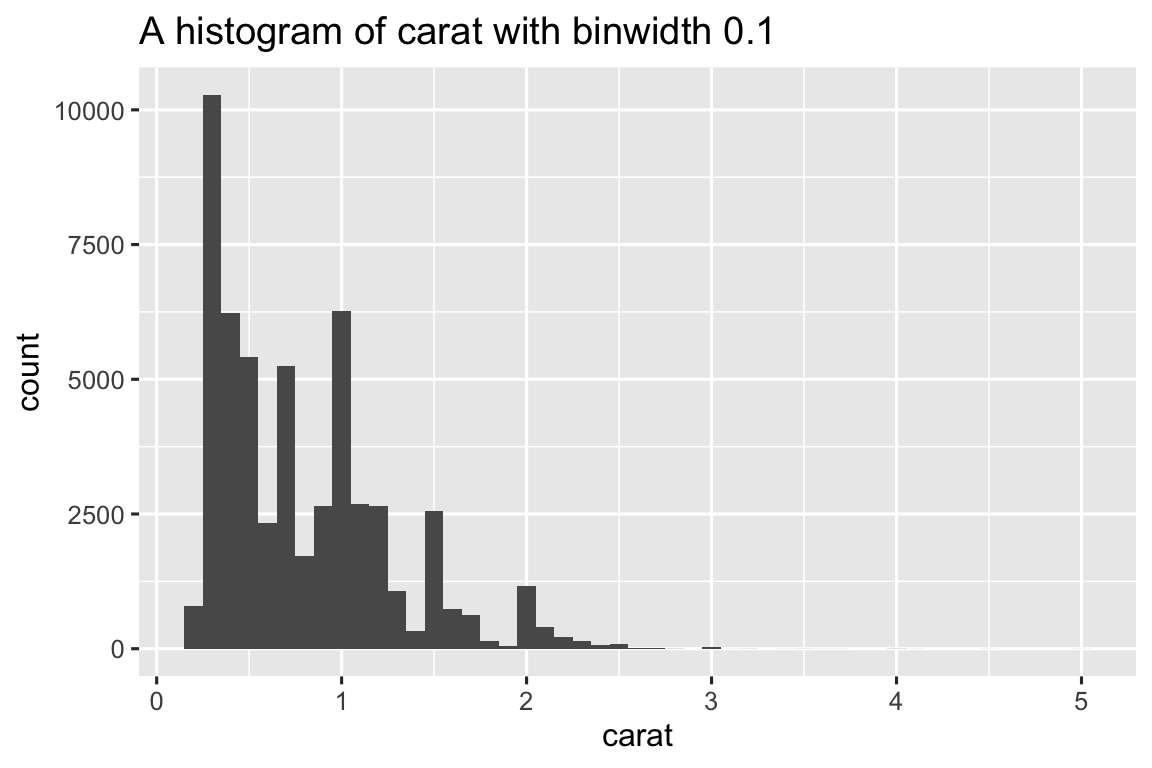
Bạn có thể sử dụng cùng cách tiếp cận ở bất kỳ nơi nào khác mà bạn muốn cung cấp một string trong biểu đồ ggplot2.
25.4.4 Bài tập
Xây dựng một function vẽ biểu đồ phong phú bằng cách triển khai từng bước dưới đây:
Vẽ biểu đồ phân tán (scatterplot) cho tập dữ liệu và các biến
xvày.Thêm đường hồi quy tốt nhất (tức là mô hình tuyến tính không có sai số chuẩn).
Thêm tiêu đề.
25.5 Phong cách
R không quan tâm function hay argument của bạn được đặt tên gì nhưng tên rất quan trọng đối với con người. Lý tưởng nhất, tên function của bạn nên ngắn nhưng gợi rõ function làm gì. Điều đó khó! Nhưng rõ ràng tốt hơn ngắn gọn, vì tính năng tự động hoàn thành của RStudio giúp dễ dàng gõ tên dài.
Nói chung, tên function nên là động từ, và argument nên là danh từ. Có một số ngoại lệ: danh từ được chấp nhận nếu function tính toán một danh từ rất quen thuộc (ví dụ: mean() tốt hơn compute_mean()), hoặc truy cập thuộc tính của một đối tượng (ví dụ: coef() tốt hơn get_coefficients()). Hãy dùng phán đoán tốt nhất của bạn và đừng ngại đổi tên function nếu bạn nghĩ ra tên tốt hơn sau này.
# Quá ngắn
f()
# Không phải động từ, hoặc không mô tả
my_awesome_function()
# Dài, nhưng rõ ràng
impute_missing()
collapse_years()R cũng không quan tâm cách bạn sử dụng khoảng trắng trong function nhưng người đọc trong tương lai sẽ quan tâm. Hãy tiếp tục tuân theo các quy tắc từ Chương 4. Ngoài ra, function() luôn nên được theo sau bởi dấu ngoặc nhọn ({}), và nội dung bên trong nên được thụt vào thêm hai dấu cách. Điều này giúp dễ dàng thấy cấu trúc phân cấp trong mã của bạn bằng cách lướt qua lề trái.
# Thiếu hai dấu cách bổ sung
density <- function(color, facets, binwidth = 0.1) {
diamonds |>
ggplot(aes(x = carat, y = after_stat(density), color = {{ color }})) +
geom_freqpoly(binwidth = binwidth) +
facet_wrap(vars({{ facets }}))
}
# Pipe thụt lề sai
density <- function(color, facets, binwidth = 0.1) {
diamonds |>
ggplot(aes(x = carat, y = after_stat(density), color = {{ color }})) +
geom_freqpoly(binwidth = binwidth) +
facet_wrap(vars({{ facets }}))
}Như bạn thấy, chúng tôi khuyên nên đặt thêm dấu cách bên trong { }. Điều này khiến điều bất thường đang xảy ra trở nên rất rõ ràng.
25.5.1 Bài tập
-
Đọc mã nguồn của hai function sau, đoán xem chúng làm gì, rồi nghĩ ra tên tốt hơn.
f1 <- function(string, prefix) { str_sub(string, 1, str_length(prefix)) == prefix } f3 <- function(x, y) { rep(y, length.out = length(x)) } Lấy một function bạn đã viết gần đây và dành 5 phút nghĩ ra tên tốt hơn cho nó và các argument của nó.
Hãy đưa ra lý lẽ vì sao
norm_r(),norm_d()v.v. sẽ tốt hơnrnorm(),dnorm(). Hãy đưa ra lý lẽ cho phía ngược lại. Làm thế nào bạn có thể làm cho các tên rõ ràng hơn nữa?
25.6 Tóm tắt
Trong chương này, bạn đã học cách viết function cho ba script hữu ích: tạo vector, tạo data frame, hoặc tạo biểu đồ. Trong quá trình đó, bạn đã thấy nhiều ví dụ, hy vọng đã kích thích sự sáng tạo của bạn và cho bạn một số ý tưởng về nơi function có thể giúp ích cho mã phân tích của bạn.
Chúng tôi chỉ mới chỉ cho bạn những điều tối thiểu để bắt đầu với function và còn rất nhiều điều để học. Một số nơi để tìm hiểu thêm:
- Để tìm hiểu thêm về lập trình với đánh giá gọn gàng, hãy xem các công thức hữu ích trong lập trình với dplyr và lập trình với tidyr và tìm hiểu thêm lý thuyết trong Che dữ liệu là gì và tại sao tôi cần {{?.
- Để tìm hiểu thêm về giảm sự trùng iterate trong mã ggplot2, hãy đọc chương Lập trình với ggplot2 của sách ggplot2.
- Để biết thêm lời khuyên về phong cách function, hãy xem hướng dẫn phong cách tidyverse.
Trong chương tiếp theo, chúng ta sẽ đi sâu vào iterate (iteration) — công cụ giúp bạn giảm sự trùng iterate mã hơn nữa.