10 Phân tích dữ liệu khám phá
10.1 Giới thiệu
Chương này sẽ cho bạn thấy cách sử dụng visualization và biến đổi để khám phá dữ liệu một cách có hệ thống, một tác vụ mà các nhà thống kê gọi là phân tích dữ liệu khám phá (exploratory data analysis), hay EDA. EDA là một chu trình iterate. Bạn:
Đặt câu hỏi về dữ liệu.
Tìm câu trả lời bằng cách visualization, biến đổi, và mô hình hóa dữ liệu.
Sử dụng những gì học được để tinh chỉnh câu hỏi và/hoặc đặt câu hỏi mới.
EDA không phải workflow chính thức với bộ quy tắc nghiêm ngặt. Hơn hết, EDA là một trạng thái tư duy. Trong giai đoạn đầu của EDA, bạn nên thoải mái khảo sát mọi ý tưởng xuất hiện. Một số sẽ có kết quả, một số sẽ đi vào ngõ cụt. Khi khám phá tiếp tục, bạn sẽ tập trung vào một số phát hiện đặc biệt hiệu quả mà cuối cùng bạn sẽ viết lại và truyền đạt cho người khác.
EDA là phần quan trọng của mọi phân tích dữ liệu, ngay cả khi câu hỏi nghiên cứu chính đã được đưa sẵn, vì bạn luôn cần khảo sát chất lượng dữ liệu. Làm sạch dữ liệu chỉ là một ứng dụng của EDA: bạn đặt câu hỏi liệu dữ liệu có đáp ứng kỳ vọng hay không. Để làm sạch dữ liệu, bạn cần triển khai tất cả công cụ EDA: visualization, biến đổi, và mô hình hóa.
10.1.1 Điều kiện tiên quyết
Trong chương này chúng ta sẽ kết hợp những gì đã học về dplyr và ggplot2 để đặt câu hỏi tương tác, trả lời bằng dữ liệu, rồi đặt câu hỏi mới.
10.2 Câu hỏi
“Không có câu hỏi thống kê thường lệ, chỉ có workflow thống kê đáng nghi ngờ.” — Sir David Cox
“Câu trả lời gần đúng cho câu hỏi đúng, vốn thường mơ hồ, tốt hơn nhiều câu trả lời chính xác cho câu hỏi sai, vốn luôn có thể được làm cho chính xác.” — John Tukey
Mục tiêu của bạn trong EDA là phát triển sự hiểu biết về dữ liệu. Cách dễ nhất là sử dụng câu hỏi như công cụ hướng dẫn khảo sát. Khi bạn đặt câu hỏi, nó tập trung sự chú ý vào phần cụ thể của tập dữ liệu và giúp bạn quyết định đồ thị, mô hình, hay biến đổi nào cần tạo.
EDA về cơ bản là quá trình sáng tạo. Và giống hầu hết quá trình sáng tạo, chìa khóa để đặt câu hỏi chất lượng là tạo ra số lượng lớn câu hỏi. Khó đặt câu hỏi sâu sắc ngay đầu phân tích vì bạn chưa biết những hiểu biết nào có thể rút ra từ tập dữ liệu. Mặt khác, mỗi câu hỏi mới sẽ cho bạn thấy khía cạnh mới của dữ liệu và tăng cơ hội khám phá. Bạn có thể nhanh chóng đi sâu vào phần thú vị nhất nếu theo đuổi mỗi câu hỏi bằng câu hỏi mới dựa trên phát hiện.
Không có quy tắc về câu hỏi nào nên đặt để hướng dẫn nghiên cứu. Tuy nhiên, hai loại câu hỏi luôn hữu ích:
Loại biến thiên (variation) nào xảy ra trong các biến của tôi?
Loại đồng biến thiên (covariation) nào xảy ra giữa các biến?
Phần còn lại của chương sẽ xem xét hai câu hỏi này. Chúng ta sẽ giải thích biến thiên và đồng biến thiên là gì, và cho thấy nhiều cách trả lời.
10.3 Biến thiên
Biến thiên (variation) là xu hướng giá trị của biến thay đổi từ phép đo này sang phép đo khác. Bạn có thể thấy biến thiên dễ dàng trong thực tế; nếu đo bất kỳ biến liên tục nào hai lần, bạn sẽ nhận hai kết quả khác nhau. Điều này đúng ngay cả khi đo đại lượng hằng số, như tốc độ ánh sáng. Mỗi phép đo sẽ bao gồm một lượng nhỏ sai số thay đổi giữa các lần đo. Biến cũng có thể thay đổi nếu đo trên các đối tượng khác nhau (ví dụ, màu mắt của những người khác nhau) hoặc ở thời điểm khác nhau (ví dụ, mức năng lượng electron ở các thời điểm khác nhau). Mỗi biến có mẫu biến thiên riêng, có thể tiết lộ thông tin thú vị. Cách tốt nhất để hiểu mẫu đó là visualization phân phối (distribution) giá trị của biến, điều bạn đã học trong Chương 1.
Chúng ta sẽ bắt đầu bằng visualization phân phối trọng lượng (carat) của ~54.000 viên kim cương từ tập dữ liệu diamonds. Vì carat là biến số, chúng ta dùng biểu đồ tần suất:
ggplot(diamonds, aes(x = carat)) +
geom_histogram(binwidth = 0.5)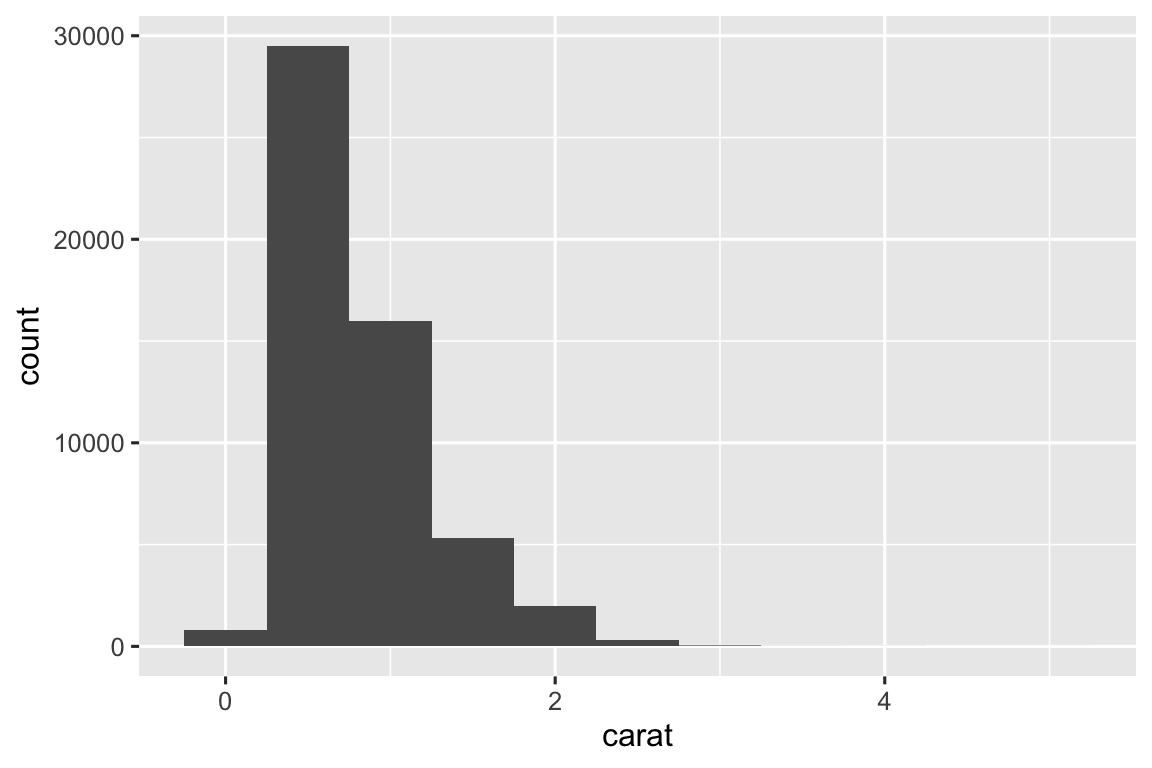
Giờ bạn đã có thể visualization biến thiên, bạn nên tìm gì trong biểu đồ? Và nên đặt câu hỏi tiếp theo gì? Dưới đây là list các loại thông tin hữu ích nhất cùng câu hỏi tiếp theo. Chìa khóa là dựa vào sự tò mò (Bạn muốn tìm hiểu thêm gì?) và hoài nghi (Điều này có thể gây nhầm lẫn thế nào?).
10.3.1 Giá trị điển hình
Trong biểu đồ column và biểu đồ tần suất, thanh cao hiển thị giá trị phổ biến, thanh thấp hiển thị giá trị hiếm. Nơi không có thanh cho thấy giá trị không xuất hiện trong dữ liệu. Để biến thông tin này thành câu hỏi hữu ích, tìm điều bất ngờ:
Giá trị nào phổ biến nhất? Tại sao?
Giá trị nào hiếm? Tại sao? Có khớp với kỳ vọng không?
Bạn có thấy mẫu bất thường nào không? Điều gì có thể giải thích chúng?
Hãy xem phân phối carat cho kim cương nhỏ hơn.
smaller <- diamonds |>
filter(carat < 3)
ggplot(smaller, aes(x = carat)) +
geom_histogram(binwidth = 0.01)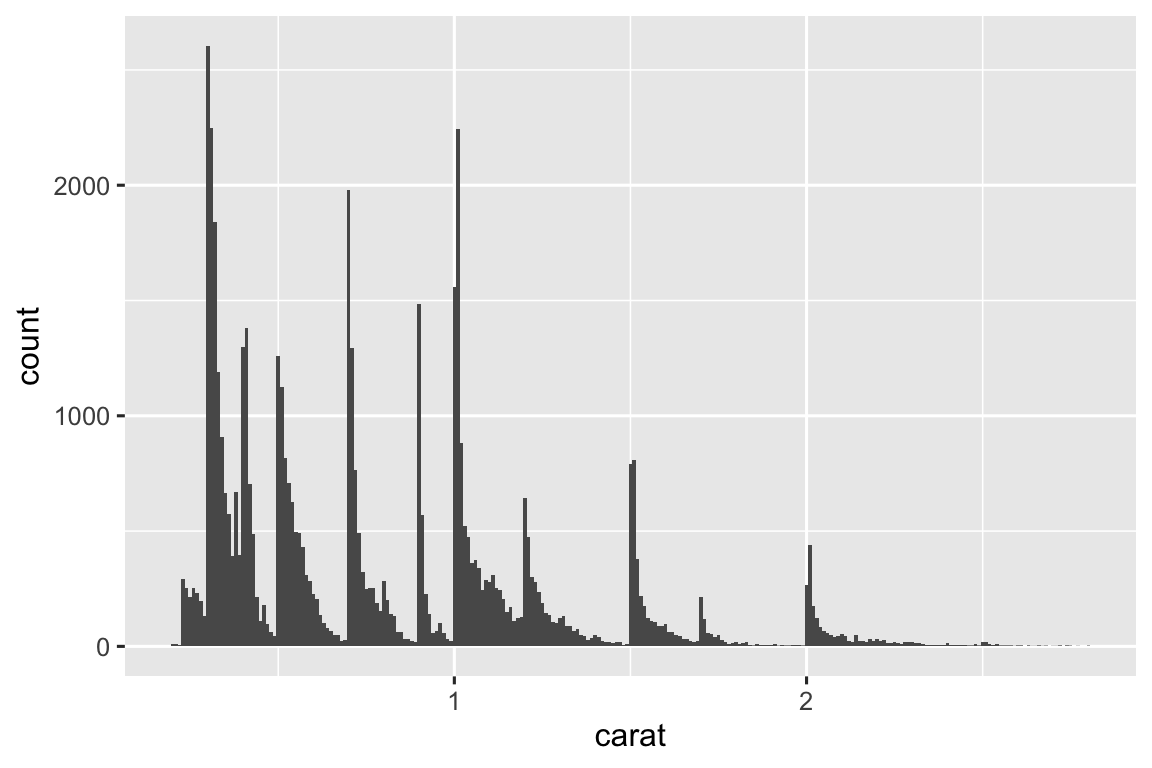
Biểu đồ tần suất này gợi ý nhiều câu hỏi thú vị:
Tại sao có nhiều kim cương hơn ở các giá trị carat nguyên và phân số phổ biến?
Tại sao có nhiều kim cương hơn ở bên phải mỗi đỉnh so với bên trái?
Trực quan hóa cũng có thể tiết lộ cụm (cluster), gợi ý rằng có nhóm con trong dữ liệu. Để hiểu các nhóm con, hãy hỏi:
Các quan sát trong mỗi nhóm con giống nhau thế nào?
Các quan sát ở cụm khác nhau khác nhau thế nào?
Bạn có thể giải thích hoặc mô tả các cụm thế nào?
Tại sao sự xuất hiện của cụm có thể gây nhầm lẫn?
Một số câu hỏi có thể trả lời bằng dữ liệu, một số cần kiến thức chuyên môn. Nhiều câu hỏi sẽ thúc đẩy bạn khám phá mối quan hệ giữa các biến. Chúng ta sẽ đến đó ngay.
10.3.2 Giá trị bất thường
Ngoại lệ (outlier) là các quan sát bất thường; điểm dữ liệu không khớp với mẫu. Đôi khi ngoại lệ là lỗi nhập liệu, đôi khi chỉ là giá trị cực đoan, và đôi khi gợi ý khám phá mới quan trọng. Khi có nhiều dữ liệu, ngoại lệ đôi khi khó thấy trong biểu đồ tần suất. Ví dụ, xem phân phối biến y từ tập dữ liệu diamonds. Bằng chứng duy nhất về ngoại lệ là giới hạn rộng bất thường trên trục x.
ggplot(diamonds, aes(x = y)) +
geom_histogram(binwidth = 0.5)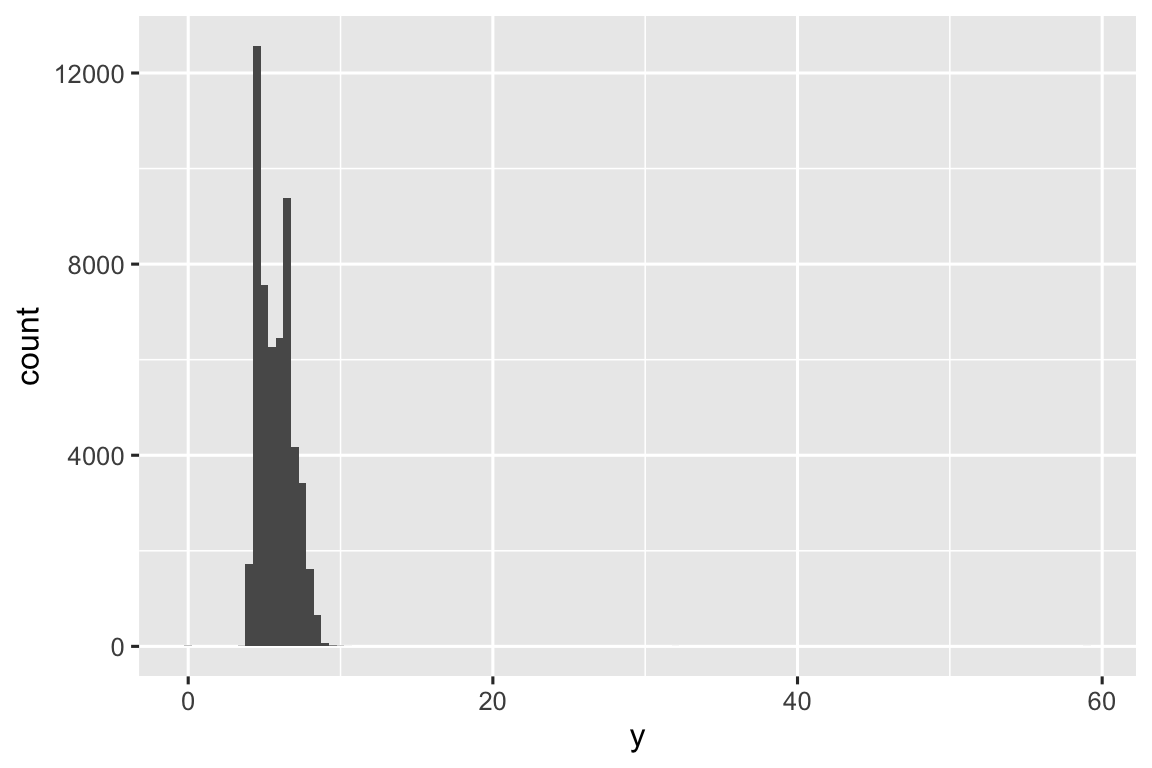
Có quá nhiều quan sát ở bin phổ biến nên bin hiếm rất ngắn, khó thấy. Để dễ thấy giá trị bất thường, chúng ta cần phóng to vào giá trị nhỏ của trục y với coord_cartesian():
ggplot(diamonds, aes(x = y)) +
geom_histogram(binwidth = 0.5) +
coord_cartesian(ylim = c(0, 50))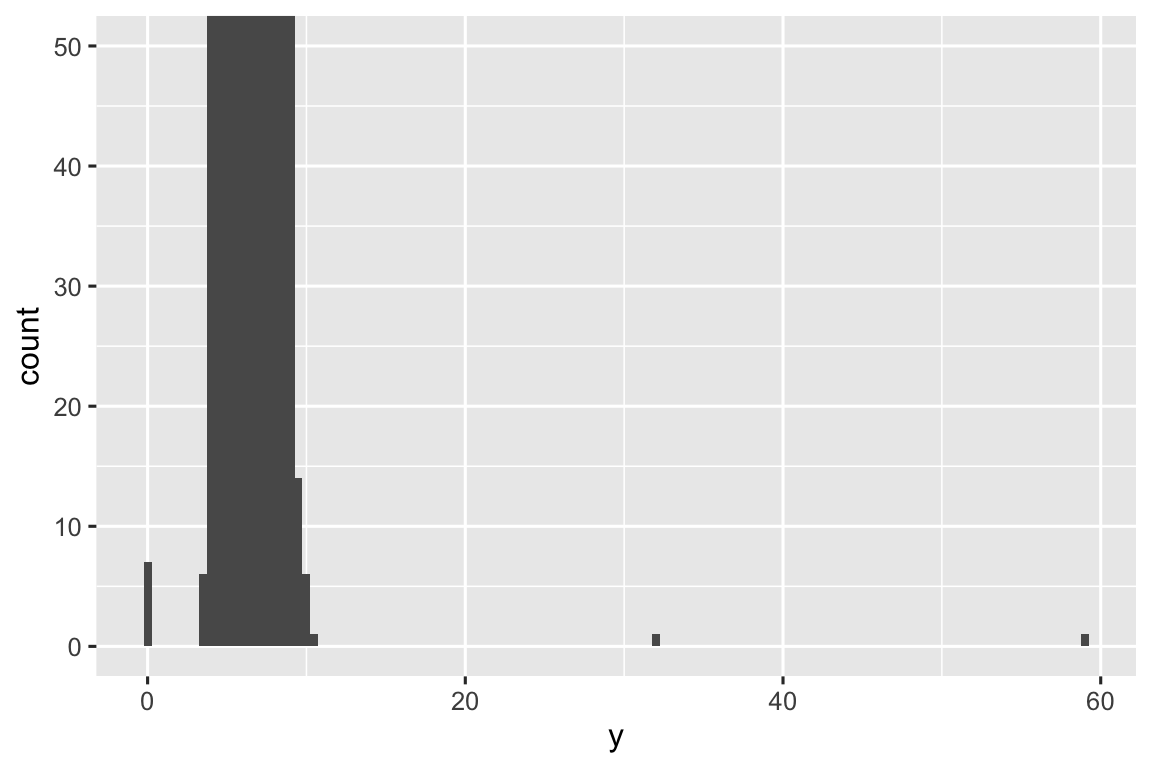
coord_cartesian() cũng có argument xlim() khi bạn cần phóng to trục x. ggplot2 cũng có function xlim() và ylim() hoạt động hơi khác: chúng loại bỏ dữ liệu ngoài giới hạn.
Điều này cho thấy có ba giá trị bất thường: 0, ~30, và ~60. Chúng ta trích xuất chúng bằng dplyr:
unusual <- diamonds |>
filter(y < 3 | y > 20) |>
select(price, x, y, z) |>
arrange(y)
unusual
#> # A tibble: 9 × 4
#> price x y z
#> <int> <dbl> <dbl> <dbl>
#> 1 5139 0 0 0
#> 2 6381 0 0 0
#> 3 12800 0 0 0
#> 4 15686 0 0 0
#> 5 18034 0 0 0
#> 6 2130 0 0 0
#> 7 2130 0 0 0
#> 8 2075 5.15 31.8 5.12
#> 9 12210 8.09 58.9 8.06Biến y đo một trong ba kích thước kim cương, tính bằng mm. Chúng ta biết kim cương không thể có chiều rộng 0mm, vì vậy các giá trị này phải sai. Bằng EDA, chúng ta đã phát hiện dữ liệu thiếu được mã hóa thành 0, điều không bao giờ tìm thấy nếu chỉ tìm NA. Chúng ta có thể chọn mã hóa lại thành NA để tránh tính toán sai lệch. Chúng ta cũng có thể nghi ngờ rằng đo 32mm và 59mm là không hợp lý: kim cương đó dài hơn một inch nhưng không có giá row trăm nghìn đô la!
Nên iterate lại phân tích có và không có ngoại lệ. Nếu chúng ít ảnh hưởng đến kết quả, và bạn không tìm được lý do, có thể bỏ qua chúng. Tuy nhiên, nếu ảnh hưởng đáng kể, bạn không nên bỏ mà không có lý do. Bạn cần tìm nguyên nhân (ví dụ, lỗi nhập liệu) và công bố rằng đã loại bỏ chúng.
10.3.3 Bài tập
Khám phá phân phối mỗi biến
x,y, vàztrongdiamonds. Bạn học được gì? Nghĩ về viên kim cương và cách quyết định kích thước nào là chiều dài, rộng, sâu.Khám phá phân phối
price. Bạn phát hiện điều gì bất thường hay bất ngờ? (Gợi ý: Suy nghĩ kỹ vềbinwidthvà thử nhiều giá trị.)Có bao nhiêu kim cương 0.99 carat? Bao nhiêu 1 carat? Bạn nghĩ nguyên nhân sự khác biệt là gì?
So sánh
coord_cartesian()vớixlim()hoặcylim()khi phóng to biểu đồ tần suất. Điều gì xảy ra nếu không đặtbinwidth? Điều gì xảy ra nếu phóng to chỉ hiện nửa thanh?
10.4 Giá trị bất thường
Nếu bạn gặp giá trị bất thường trong tập dữ liệu, và muốn tiếp tục phân tích, bạn có hai lựa chọn.
-
Loại bỏ toàn bộ row chứa giá trị lạ:
Chúng tôi không khuyến nghị cách này vì một giá trị sai không có nghĩa tất cả giá trị khác trong quan sát đó cũng sai. Ngoài ra, nếu dữ liệu chất lượng thấp, khi áp dụng cách này cho mọi biến bạn có thể không còn dữ liệu nào!
-
Thay vào đó, chúng tôi khuyến nghị thay giá trị bất thường bằng missing value. Cách dễ nhất là dùng
mutate()để thay biến bằng bản sao đã sửa. Bạn có thể dùng functionif_else()để thay giá trị bất thường bằngNA:
Không rõ nên vẽ missing value ở đâu, nên ggplot2 không đưa chúng vào biểu đồ, nhưng cảnh báo rằng chúng đã bị loại bỏ:
ggplot(diamonds2, aes(x = x, y = y)) +
geom_point()
#> Warning: Removed 9 rows containing missing values or values outside the scale range
#> (`geom_point()`).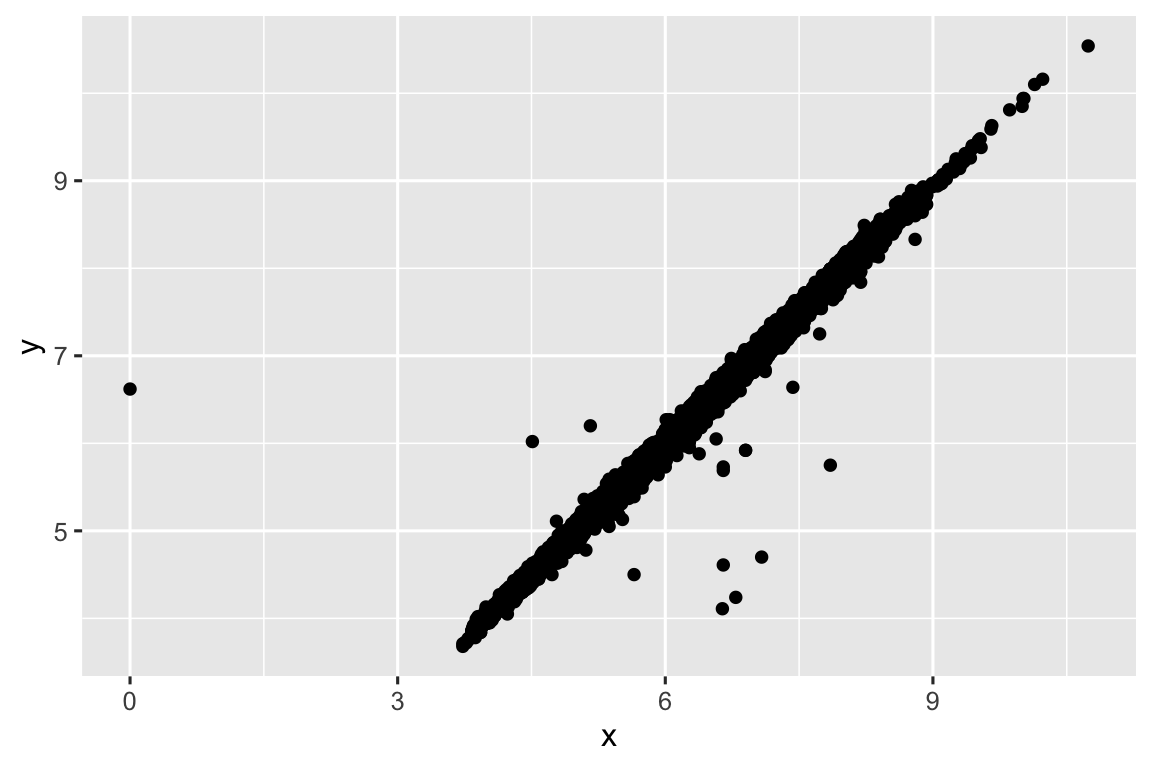
Để ẩn cảnh báo, đặt na.rm = TRUE:
ggplot(diamonds2, aes(x = x, y = y)) +
geom_point(na.rm = TRUE)Đôi khi bạn muốn hiểu quan sát có missing value khác gì so với quan sát có giá trị ghi nhận. Ví dụ, trong nycflights13::flights1, missing value trong biến dep_time cho biết chuyến bay bị hủy. Vì vậy bạn có thể muốn so sánh thời gian khởi hành dự kiến cho chuyến bị hủy và không bị hủy. Bạn có thể làm bằng cách tạo biến mới, dùng is.na() để kiểm tra dep_time có bị thiếu không.
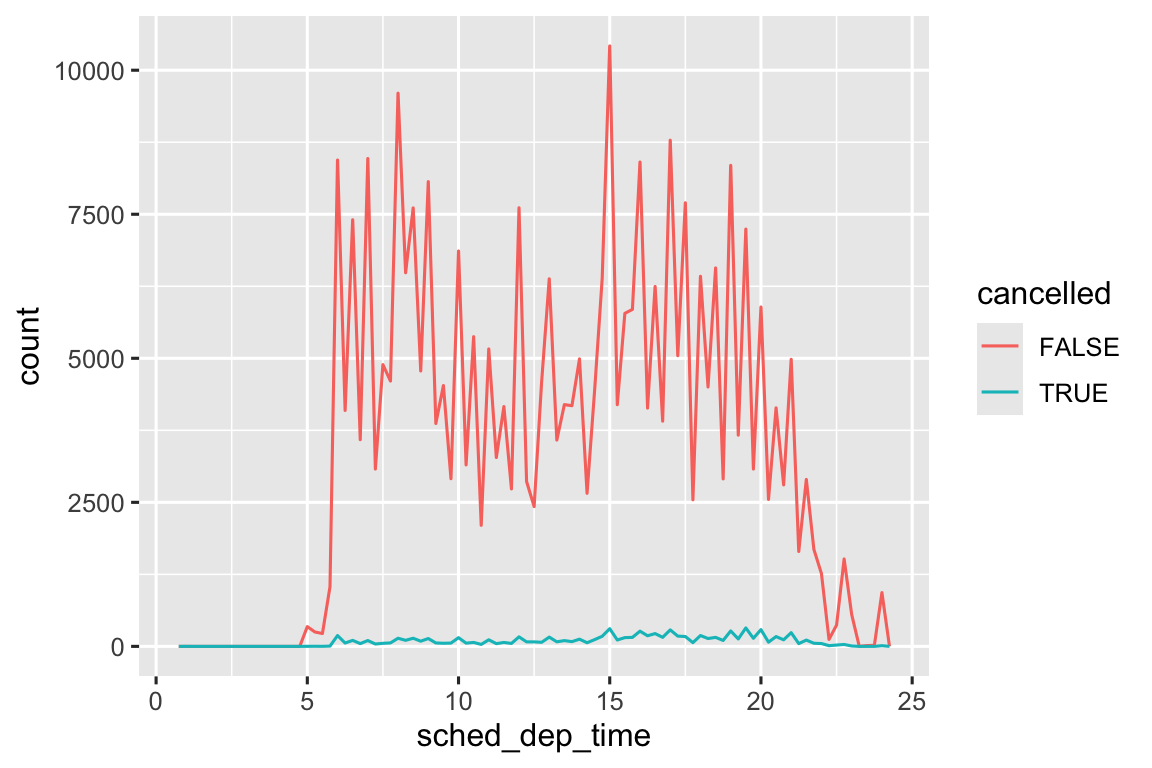
Tuy nhiên biểu đồ này không tốt lắm vì có nhiều chuyến không bị hủy hơn nhiều. Trong phần tiếp theo chúng ta sẽ khám phá kỹ thuật cải thiện so sánh này.
10.4.1 Bài tập
Điều gì xảy ra với missing value trong biểu đồ tần suất? Trong biểu đồ cột? Tại sao có sự khác biệt?
Tái tạo biểu đồ đa giác tần suất
scheduled_dep_timetô màu theo chuyến bay có bị hủy hay không. Cũng facet theo biếncancelled. Thử nghiệm các giá trị khác nhau củascalestrong function facet để giảm ảnh hưởng của chênh lệch số lượng.
10.5 Đồng biến thiên
Nếu biến thiên mô tả hành vi trong một biến, đồng biến thiên mô tả hành vi giữa các biến. Đồng biến thiên (covariation) là xu hướng giá trị của hai hoặc nhiều biến thay đổi cùng nhau theo cách liên quan. Cách tốt nhất để phát hiện đồng biến thiên là visualization mối quan hệ giữa hai hoặc nhiều biến.
10.5.1 Một biến phân loại và một biến số
Ví dụ, hãy khám phá giá kim cương thay đổi theo chất lượng (cut) dùng geom_freqpoly():
ggplot(diamonds, aes(x = price)) +
geom_freqpoly(aes(color = cut), binwidth = 500, linewidth = 0.75)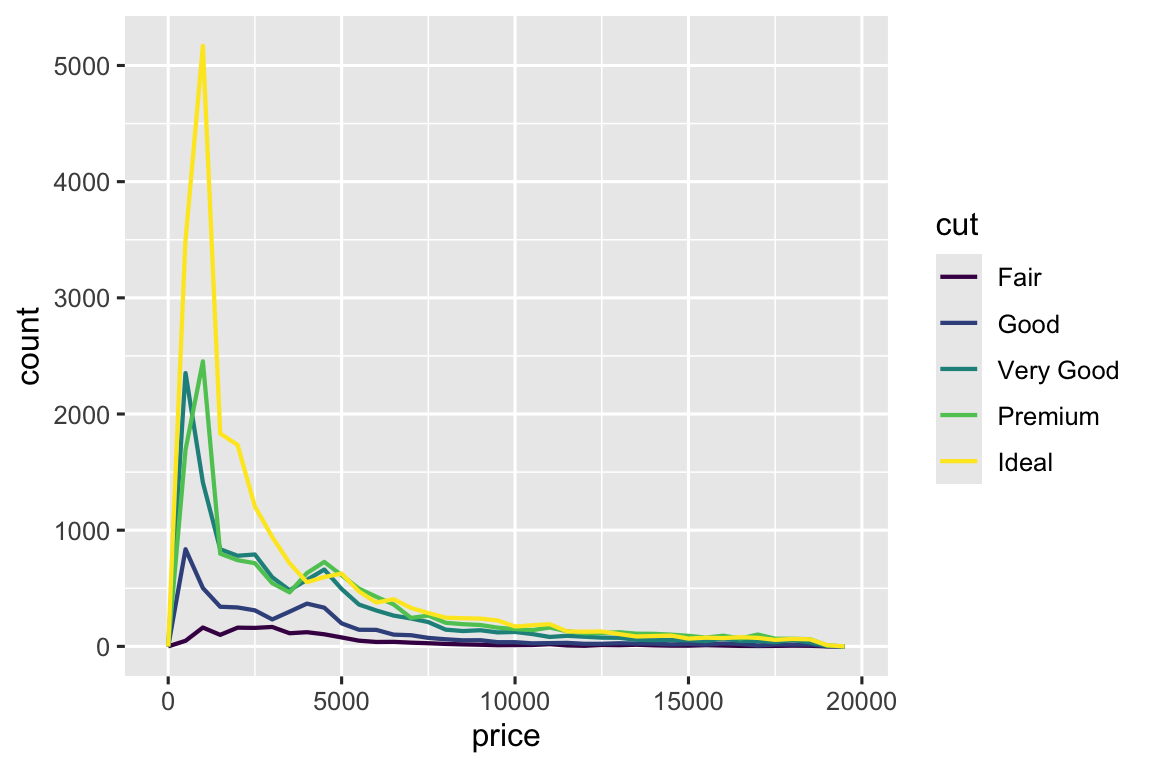
Lưu ý ggplot2 sử dụng thang màu có thứ tự cho cut vì nó được định nghĩa là biến factor có thứ tự. Bạn sẽ tìm hiểu thêm trong Phần 16.6.
Giao diện mặc định của geom_freqpoly() không hữu ích lắm ở đây vì chiều cao, phụ thuộc vào tổng số đếm, khác nhau nhiều giữa các cut, khiến khó thấy sự khác biệt hình dạng phân phối.
Để so sánh dễ hơn, chúng ta cần thay đổi hiển thị trên trục y. Thay vì số đếm, chúng ta hiển thị mật độ (density), là số đếm được chuẩn hóa sao cho diện tích dưới mỗi đa giác là một.
ggplot(diamonds, aes(x = price, y = after_stat(density))) +
geom_freqpoly(aes(color = cut), binwidth = 500, linewidth = 0.75)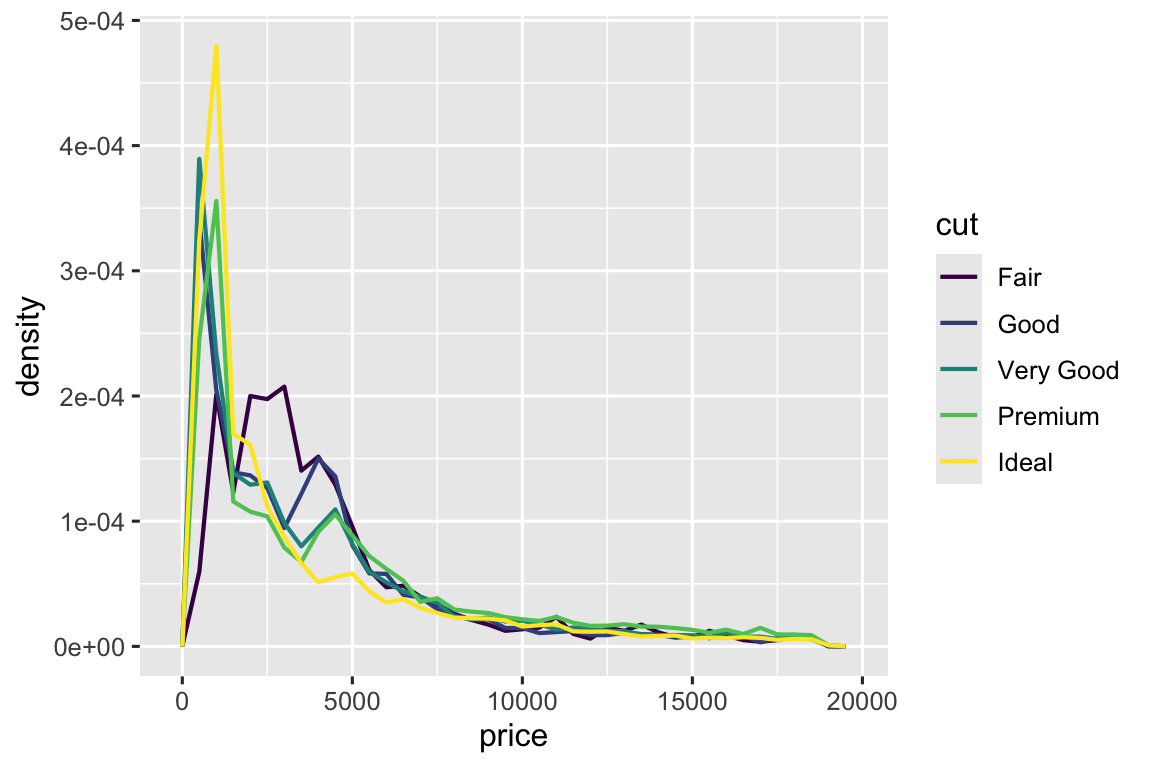
Lưu ý chúng ta mapping mật độ đến y, nhưng vì density không phải biến trong diamonds, chúng ta cần tính trước bằng function after_stat().
Có điều khá bất ngờ ở biểu đồ này - kim cương Fair (chất lượng thấp nhất) có vẻ có giá trung bình cao nhất! Nhưng có lẽ vì đa giác tần suất hơi khó đọc - có quá nhiều thứ xảy ra.
Biểu đồ trực quan đơn giản hơn để khám phá mối quan hệ này là biểu đồ hộp đặt cạnh nhau.
ggplot(diamonds, aes(x = cut, y = price)) +
geom_boxplot()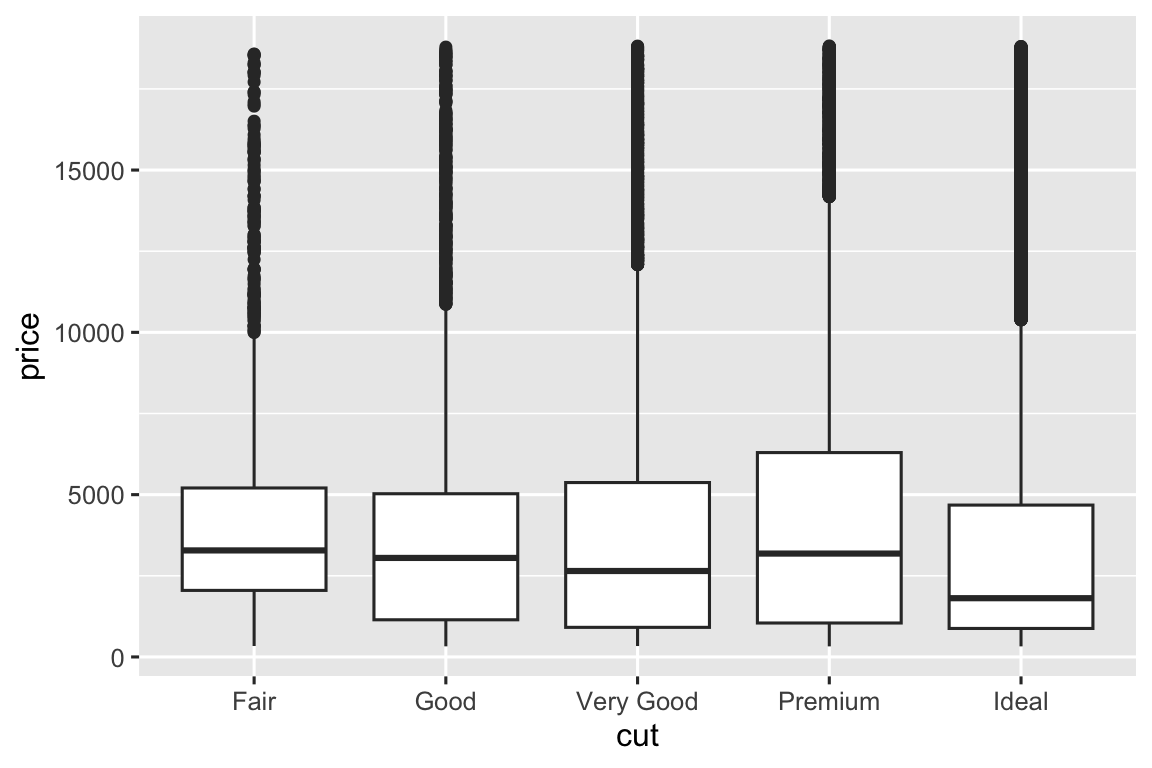
Chúng ta thấy ít thông tin về phân phối hơn, nhưng biểu đồ hộp gọn hơn nên dễ so sánh hơn. Nó ủng hộ phát hiện trái trực giác rằng kim cương chất lượng tốt hơn thường rẻ hơn! Trong bài tập, bạn sẽ được thách thức tìm hiểu tại sao.
cut là factor có thứ tự: fair kém hơn good, kém hơn very good, v.v. Nhiều biến phân loại không có thứ tự tự nhiên, vì vậy bạn có thể muốn sắp xếp lại chúng. Một cách là dùng fct_reorder(). Bạn sẽ tìm hiểu thêm trong Phần 16.4, nhưng chúng tôi muốn cho bạn xem trước vì nó rất hữu ích. Ví dụ, xem biến class trong tập dữ liệu mpg. Bạn có thể muốn biết quãng đường cao tốc thay đổi thế nào theo loại xe:
ggplot(mpg, aes(x = class, y = hwy)) +
geom_boxplot()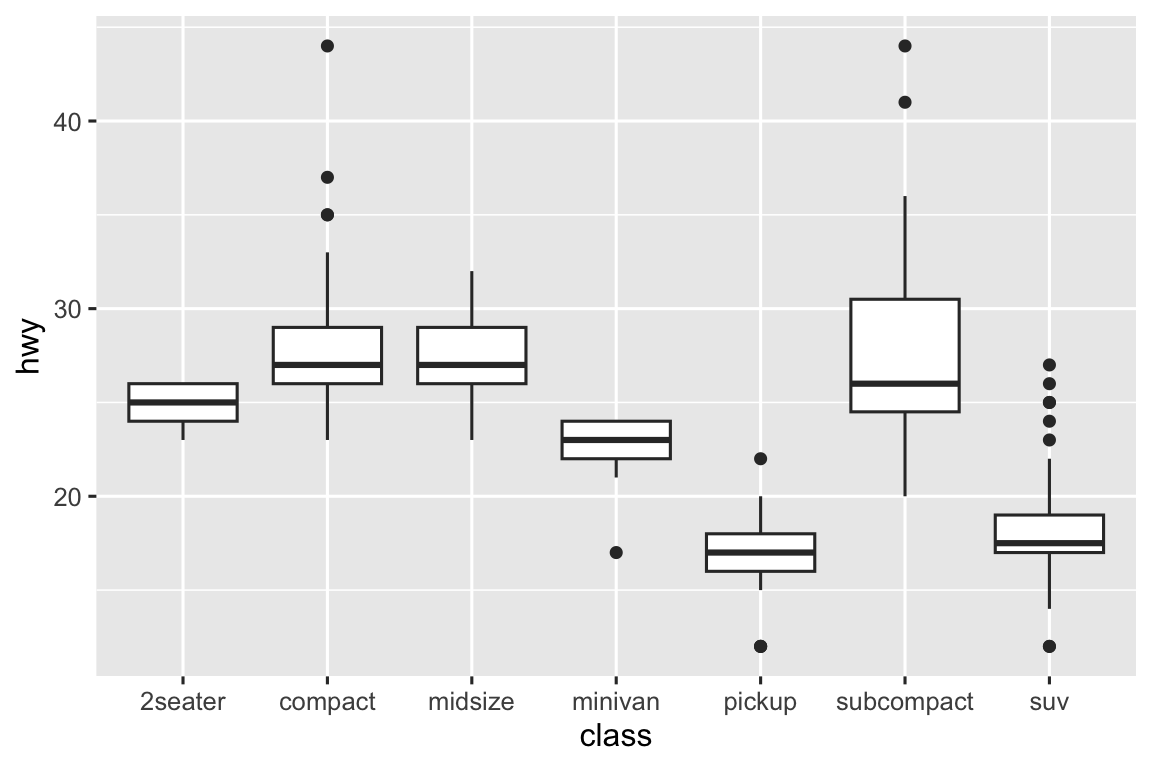
Để xu hướng dễ thấy hơn, chúng ta sắp xếp lại class theo trung vị hwy:
ggplot(mpg, aes(x = fct_reorder(class, hwy, median), y = hwy)) +
geom_boxplot()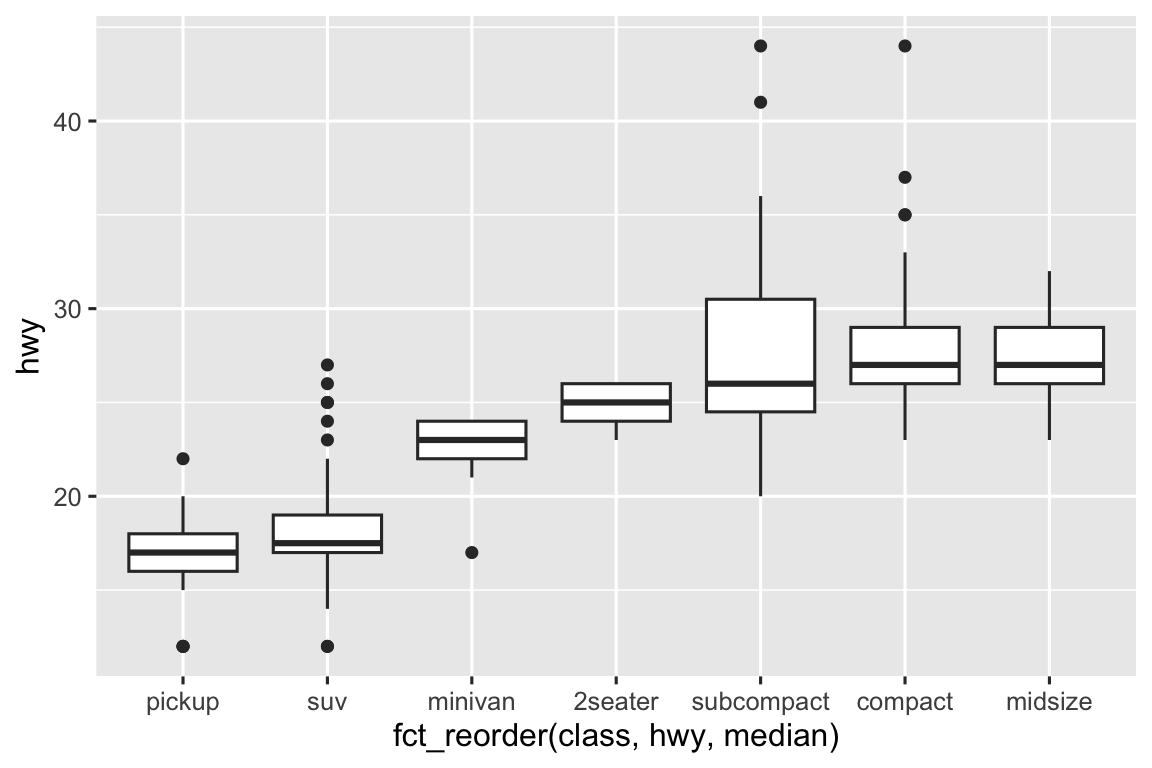
Nếu tên biến dài, geom_boxplot() sẽ hoạt động tốt hơn nếu xoay 90°. Bạn có thể làm bằng cách đổi mapping aesthetic x và y.
ggplot(mpg, aes(x = hwy, y = fct_reorder(class, hwy, median))) +
geom_boxplot()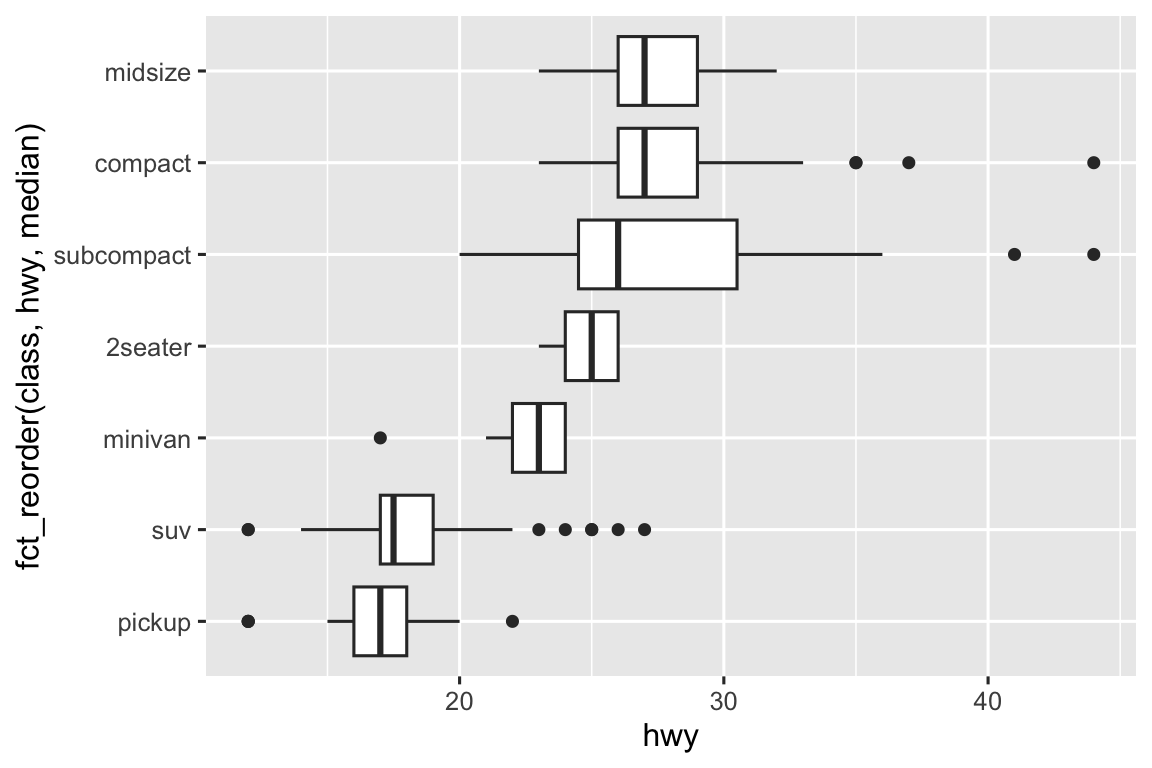
10.5.1.1 Bài tập
Dùng những gì đã học để cải thiện visualization thời gian khởi hành của chuyến bay bị hủy và không bị hủy.
Dựa trên EDA, biến nào trong tập dữ liệu diamonds có vẻ quan trọng nhất để dự đoán giá? Biến đó tương quan với cut thế nào? Tại sao sự kết hợp hai mối quan hệ đó dẫn đến kim cương chất lượng thấp đắt hơn?
Thay vì đổi biến x và y, thêm
coord_flip()như lớp mới vào biểu đồ hộp dọc để tạo biểu đồ ngang. So sánh với cách đổi biến?Một vấn đề với biểu đồ hộp là chúng được phát triển trong thời kỳ tập dữ liệu nhỏ hơn nhiều và có xu hướng hiển thị quá nhiều “giá trị ngoại lệ”. Một cách khắc phục là biểu đồ letter value. Cài đặt package lvplot, và thử dùng
geom_lv()để hiển thị phân phối giá theo cut. Bạn học được gì? Bạn diễn giải biểu đồ thế nào?Tạo visualization giá kim cương theo biến phân loại dùng
geom_violin(), rồigeom_histogram()có facet, rồigeom_freqpoly()có màu, rồigeom_density()có màu. So sánh bốn biểu đồ. Ưu nhược điểm của mỗi phương pháp?Nếu tập dữ liệu nhỏ, đôi khi hữu ích khi dùng
geom_jitter()để tránh chồng chéo điểm. Gói mở rộng ggbeeswarm cung cấp nhiều phương pháp tương tựgeom_jitter(). Liệt kê và mô tả ngắn gọn từng phương pháp.
10.5.2 Hai biến phân loại
Để visualization đồng biến thiên giữa biến phân loại, bạn cần đếm số quan sát cho mỗi tổ hợp mức. Một cách là dùng geom_count() tích hợp sẵn:
ggplot(diamonds, aes(x = cut, y = color)) +
geom_count()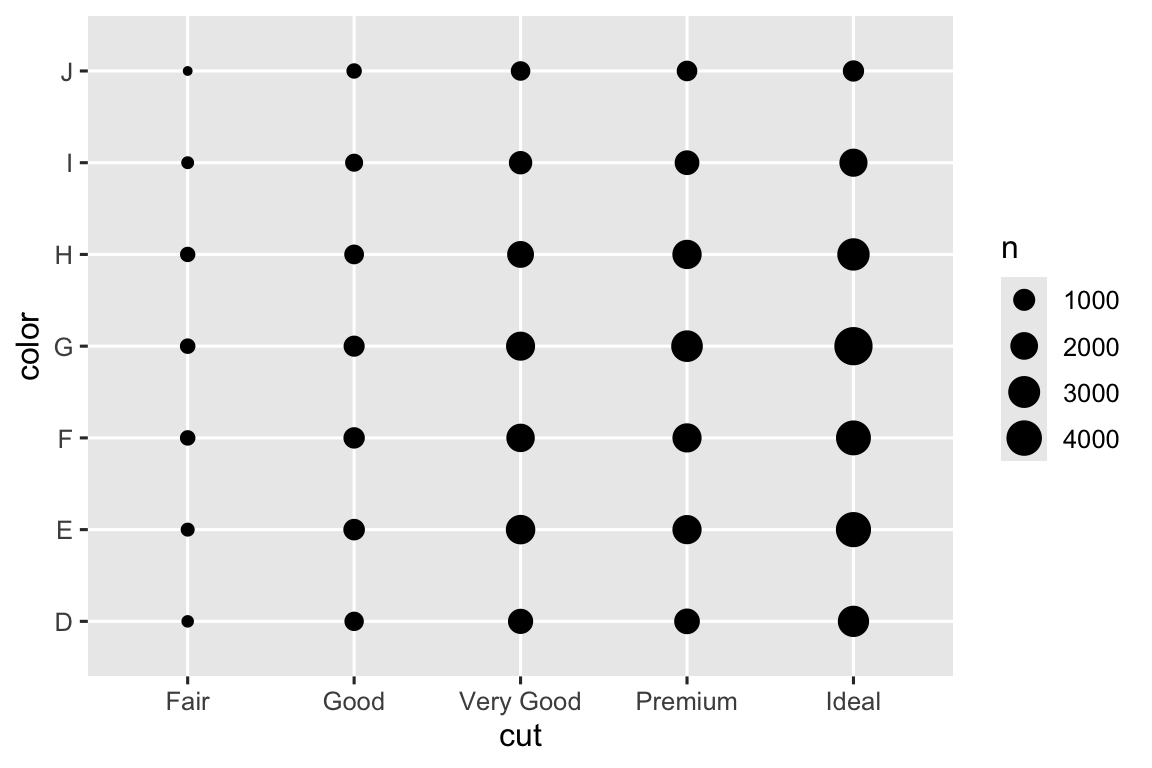
Kích thước mỗi vòng tròn hiển thị số quan sát ở mỗi tổ hợp giá trị. Đồng biến thiên sẽ xuất hiện như tương quan mạnh giữa giá trị x và y cụ thể.
Cách khác là tính số đếm bằng dplyr:
diamonds |>
count(color, cut)
#> # A tibble: 35 × 3
#> color cut n
#> <ord> <ord> <int>
#> 1 D Fair 163
#> 2 D Good 662
#> 3 D Very Good 1513
#> 4 D Premium 1603
#> 5 D Ideal 2834
#> 6 E Fair 224
#> # ℹ 29 more rowsRồi visualization bằng geom_tile() và aesthetic fill:
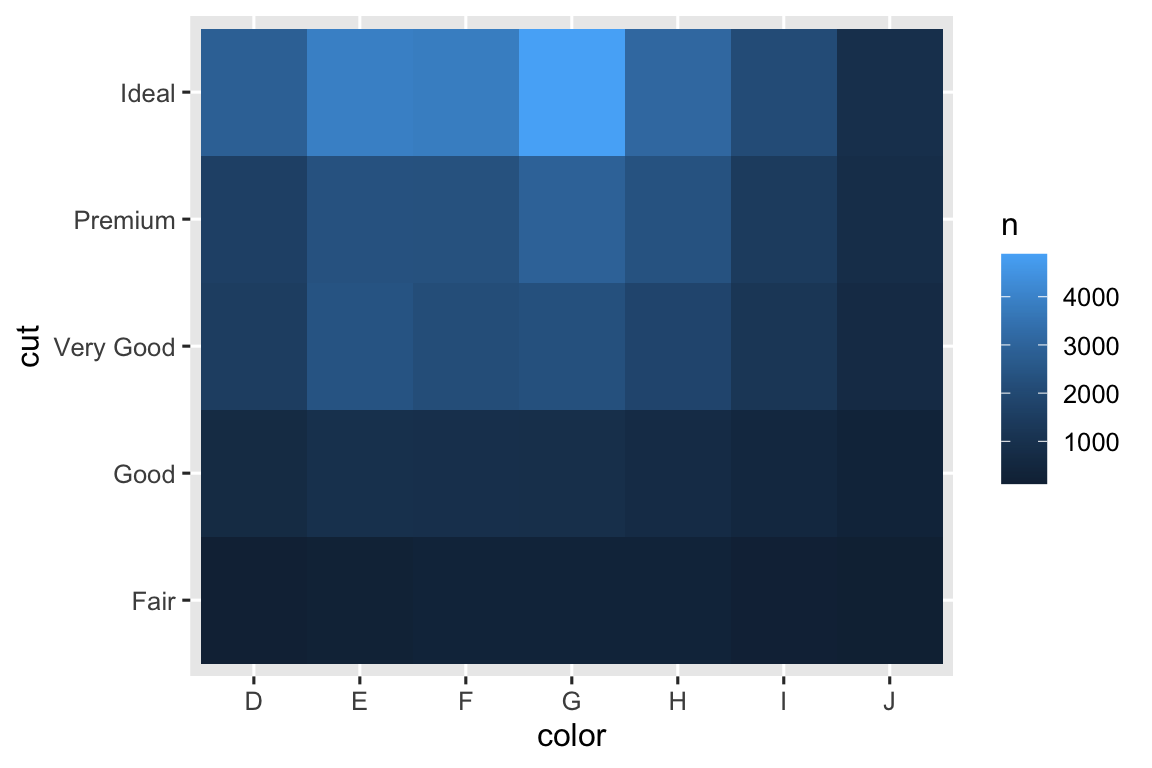
Nếu biến phân loại không có thứ tự, bạn có thể muốn dùng package seriation để sắp xếp lại row và column nhằm tiết lộ mẫu rõ hơn. Với biểu đồ lớn hơn, bạn có thể thử package heatmaply, tạo biểu đồ tương tác.
10.5.2.1 Bài tập
Bạn có thể chia tỷ lệ lại tập dữ liệu đếm ở trên để hiển thị rõ hơn phân phối cut trong color, hoặc color trong cut?
Bạn nhận được hiểu biết gì khác từ biểu đồ column phân đoạn nếu color mapping đến
xvàcutmapping đếnfill? Tính số đếm rơi vào mỗi phân đoạn.Dùng
geom_tile()cùng dplyr để khám phá độ trễ khởi hành trung bình theo điểm đến và tháng. Điều gì khiến biểu đồ khó đọc? Bạn có thể cải thiện thế nào?
10.5.3 Hai biến số
Bạn đã thấy một cách tuyệt vời để visualization đồng biến thiên giữa hai biến số: vẽ biểu đồ phân tán bằng geom_point(). Bạn có thể thấy đồng biến thiên như mẫu trong các điểm. Ví dụ, bạn thấy mối quan hệ tích cực giữa kích thước carat và giá kim cương: kim cương nhiều carat hơn có giá cao hơn. Mối quan hệ là function mũ.
ggplot(smaller, aes(x = carat, y = price)) +
geom_point()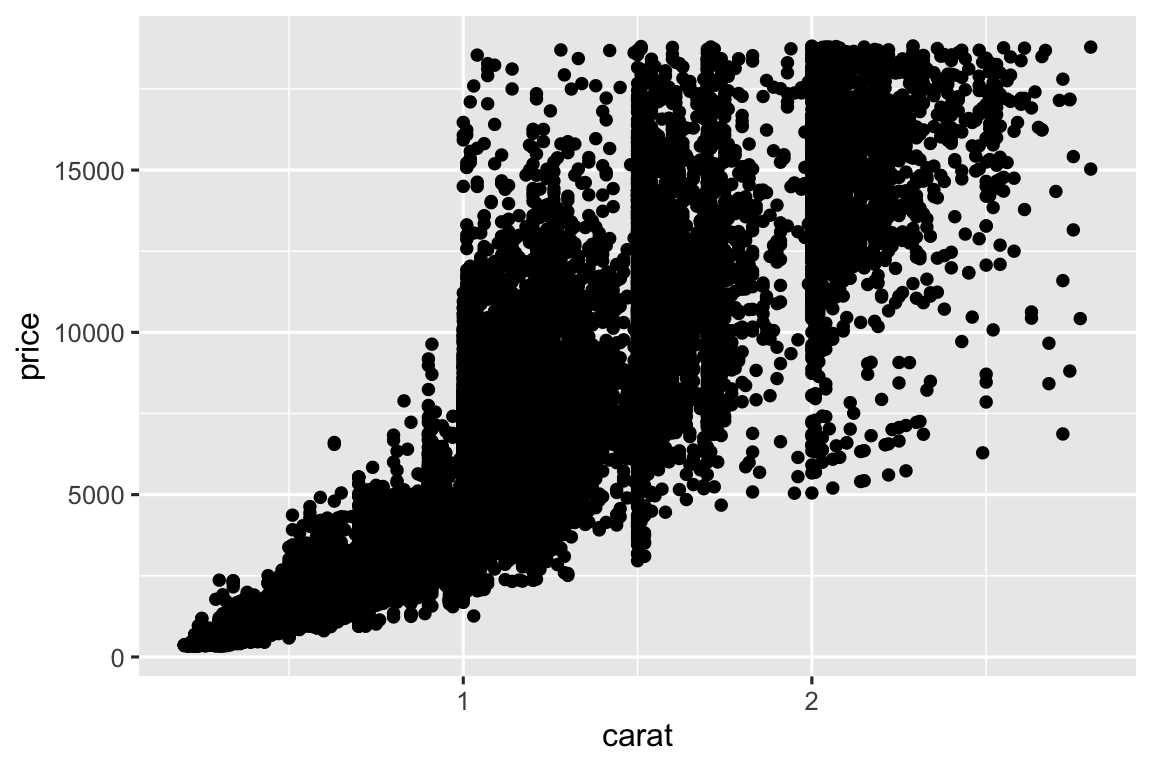
(Trong phần này chúng ta dùng tập dữ liệu smaller để tập trung vào phần lớn kim cương nhỏ hơn 3 carat)
Biểu đồ phân tán kém hữu ích hơn khi tập dữ liệu lớn, vì các điểm chồng chéo thành vùng đen đồng nhất, khiến khó đánh giá mật độ và khó thấy xu hướng. Bạn đã thấy một cách khắc phục: dùng aesthetic alpha để thêm độ trong suốt.
ggplot(smaller, aes(x = carat, y = price)) +
geom_point(alpha = 1 / 100)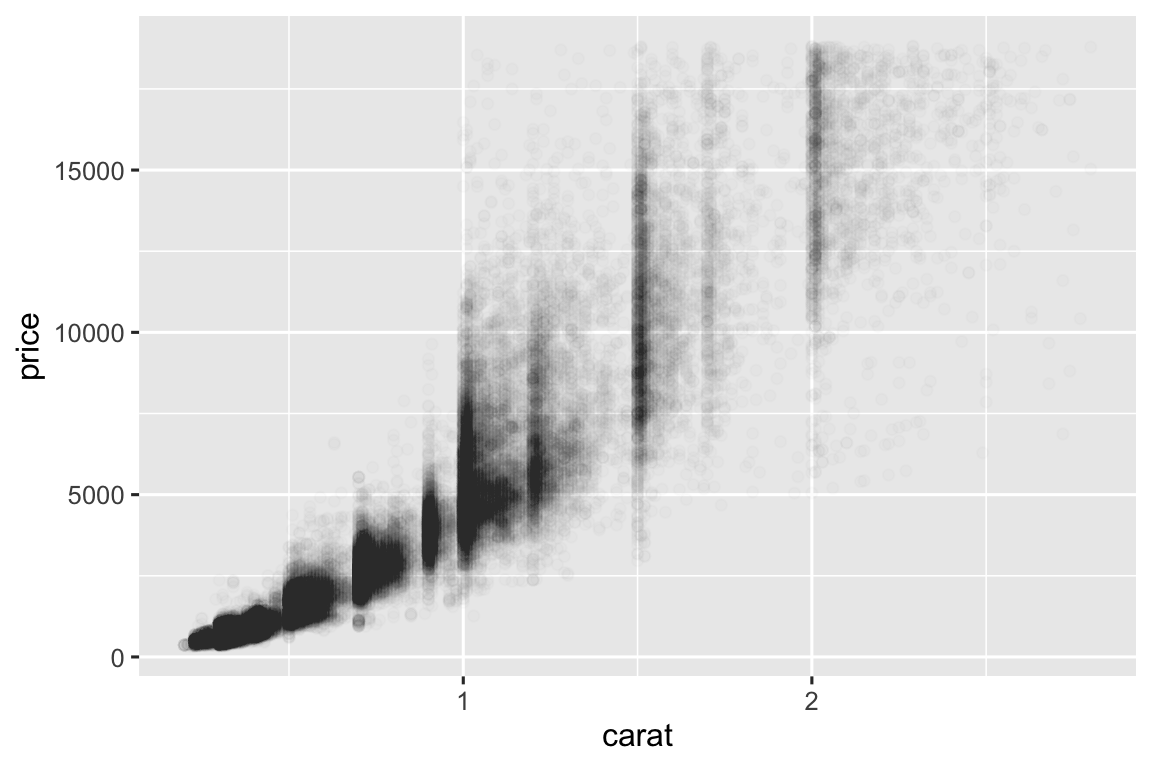
Nhưng dùng độ trong suốt có thể khó cho tập dữ liệu rất lớn. Giải pháp khác là dùng bin. Trước đây bạn dùng geom_histogram() và geom_freqpoly() để bin một chiều. Giờ bạn sẽ học dùng geom_bin2d() và geom_hex() để bin hai chiều.
geom_bin2d() và geom_hex() chia mặt phẳng tọa độ thành bin 2 chiều và dùng màu tô để hiển thị số điểm trong mỗi bin. geom_bin2d() tạo bin hình chữ nhật. geom_hex() tạo bin hình lục giác. Bạn cần cài package hexbin để dùng geom_hex().
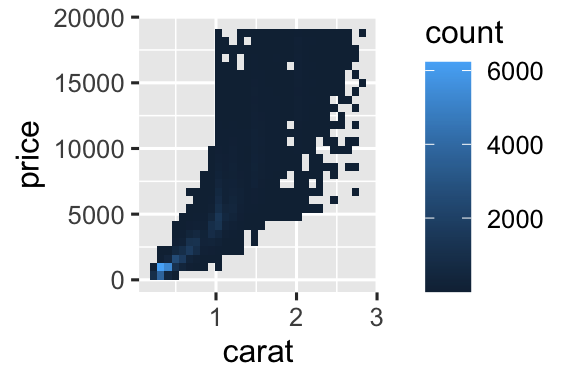
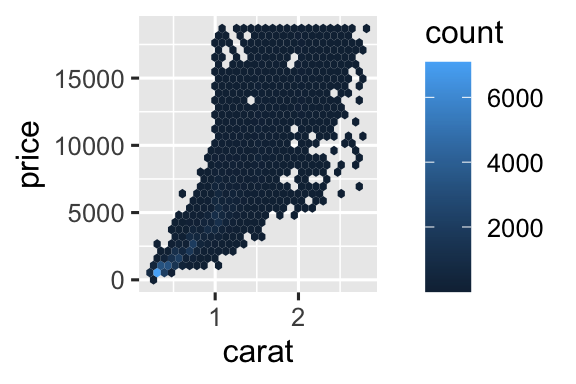
Cách khác là bin một biến liên tục để nó hoạt động như biến phân loại. Rồi dùng kỹ thuật visualization tổ hợp biến phân loại và liên tục đã học. Ví dụ, bạn có thể bin carat rồi hiển thị biểu đồ hộp cho mỗi nhóm:
ggplot(smaller, aes(x = carat, y = price)) +
geom_boxplot(aes(group = cut_width(carat, 0.1)))
#> Warning: Orientation is not uniquely specified when both the x and y aesthetics are
#> continuous. Picking default orientation 'x'.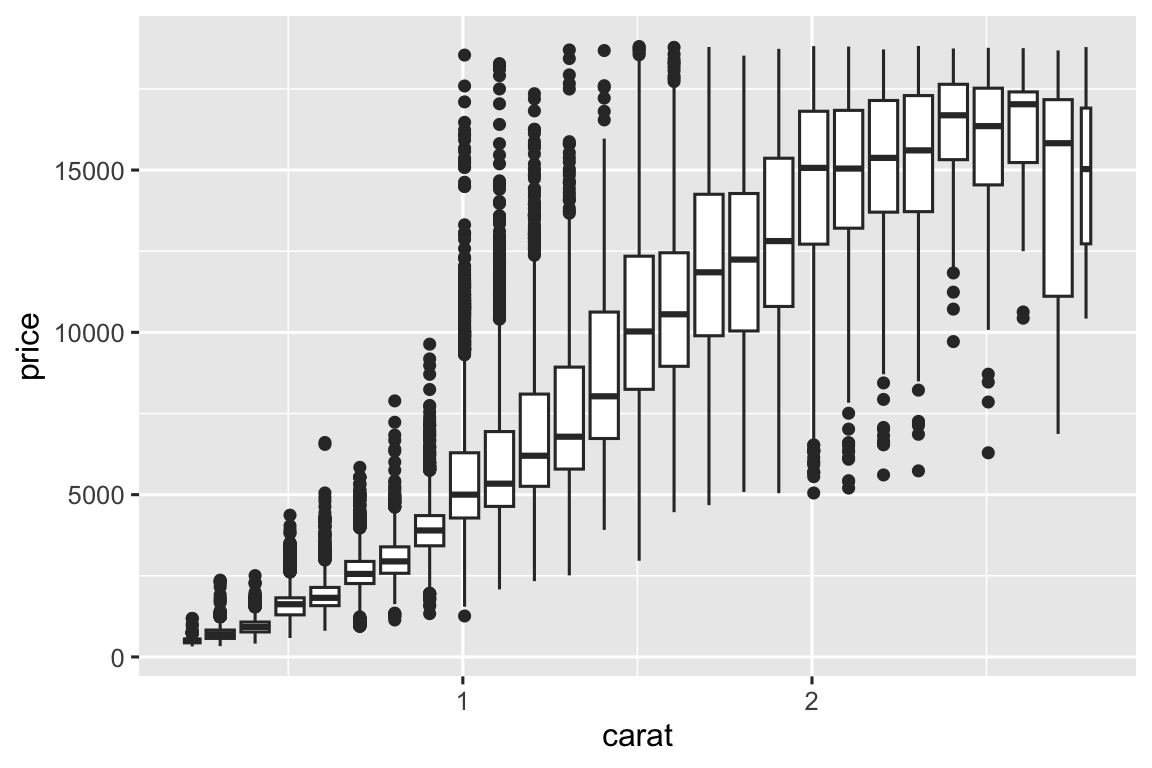
cut_width(x, width) chia x thành bin có độ rộng width. Mặc định, biểu đồ hộp trông gần giống nhau (ngoài số ngoại lệ) bất kể có bao nhiêu quan sát, nên khó biết mỗi biểu đồ hộp tóm tắt bao nhiêu điểm. Một cách hiển thị là làm chiều rộng biểu đồ hộp tỷ lệ với số điểm bằng varwidth = TRUE.
10.5.3.1 Bài tập
Thay vì tóm tắt phân phối có điều kiện bằng biểu đồ hộp, bạn có thể dùng đa giác tần suất. Bạn cần cân nhắc gì khi dùng
cut_width()so vớicut_number()? Điều đó ảnh hưởng visualization phân phối 2 chiều củacaratvàpricethế nào?Trực quan hóa phân phối
carat, phân vùng theoprice.Phân phối giá của kim cương rất lớn so với kim cương nhỏ thế nào? Có đúng như bạn mong đợi không?
Kết hợp hai kỹ thuật đã học để visualization phân phối kết hợp của cut, carat, và price.
-
Biểu đồ hai chiều tiết lộ ngoại lệ không thấy được trong biểu đồ một chiều. Ví dụ, một số điểm dưới đây có tổ hợp
xvàybất thường, dù xem riêng thì bình thường. Tại sao biểu đồ phân tán tốt hơn biểu đồ bin cho trường hợp này?diamonds |> filter(x >= 4) |> ggplot(aes(x = x, y = y)) + geom_point() + coord_cartesian(xlim = c(4, 11), ylim = c(4, 11)) -
Thay vì tạo hộp có chiều rộng bằng nhau bằng
cut_width(), chúng ta có thể tạo hộp chứa số điểm xấp xỉ bằng nhau bằngcut_number(). Ưu nhược điểm của cách tiếp cận này?ggplot(smaller, aes(x = carat, y = price)) + geom_boxplot(aes(group = cut_number(carat, 20)))
10.6 Mẫu và mô hình
Nếu có mối quan hệ hệ thống giữa hai biến, nó sẽ xuất hiện như mẫu (pattern) trong dữ liệu. Nếu bạn phát hiện mẫu, hãy tự hỏi:
Mẫu này có thể do trùng hợp (tức là ngẫu nhiên) không?
Bạn có thể mô tả mối quan hệ mà mẫu function ý thế nào?
Mối quan hệ mạnh đến mức nào?
Biến nào khác có thể ảnh hưởng đến mối quan hệ?
Mối quan hệ có thay đổi khi xem nhóm con riêng lẻ không?
Mẫu trong dữ liệu cung cấp manh mối về mối quan hệ, tức là tiết lộ đồng biến thiên. Nếu nghĩ biến thiên là hiện tượng tạo bất định, đồng biến thiên là hiện tượng giảm nó. Nếu hai biến đồng biến thiên, bạn có thể dùng giá trị một biến để dự đoán tốt hơn giá trị biến kia. Nếu đồng biến thiên do quan hệ nhân quả (trường hợp đặc biệt), bạn có thể dùng giá trị một biến để kiểm soát giá trị biến kia.
Mô hình là công cụ để trích xuất mẫu từ dữ liệu. Ví dụ, xem dữ liệu diamonds. Khó hiểu mối quan hệ giữa cut và price, vì cut và carat, carat và price liên quan chặt chẽ. Có thể dùng mô hình để loại bỏ mối quan hệ rất mạnh giữa price và carat để khám phá những sắc thái còn lại. Mã sau khớp mô hình dự đoán price từ carat rồi tính phần dư (chênh lệch giữa giá trị dự đoán và thực tế). Phần dư cho chúng ta cái nhìn về giá kim cương sau khi loại bỏ ảnh hưởng của carat. Lưu ý thay vì dùng giá trị thô, chúng ta biến đổi log trước, rồi mũ hóa phần dư để đưa về scale giá gốc.
library(tidymodels)
diamonds <- diamonds |>
mutate(
log_price = log(price),
log_carat = log(carat)
)
diamonds_fit <- linear_reg() |>
fit(log_price ~ log_carat, data = diamonds)
diamonds_aug <- augment(diamonds_fit, new_data = diamonds) |>
mutate(.resid = exp(.resid))
ggplot(diamonds_aug, aes(x = carat, y = .resid)) +
geom_point()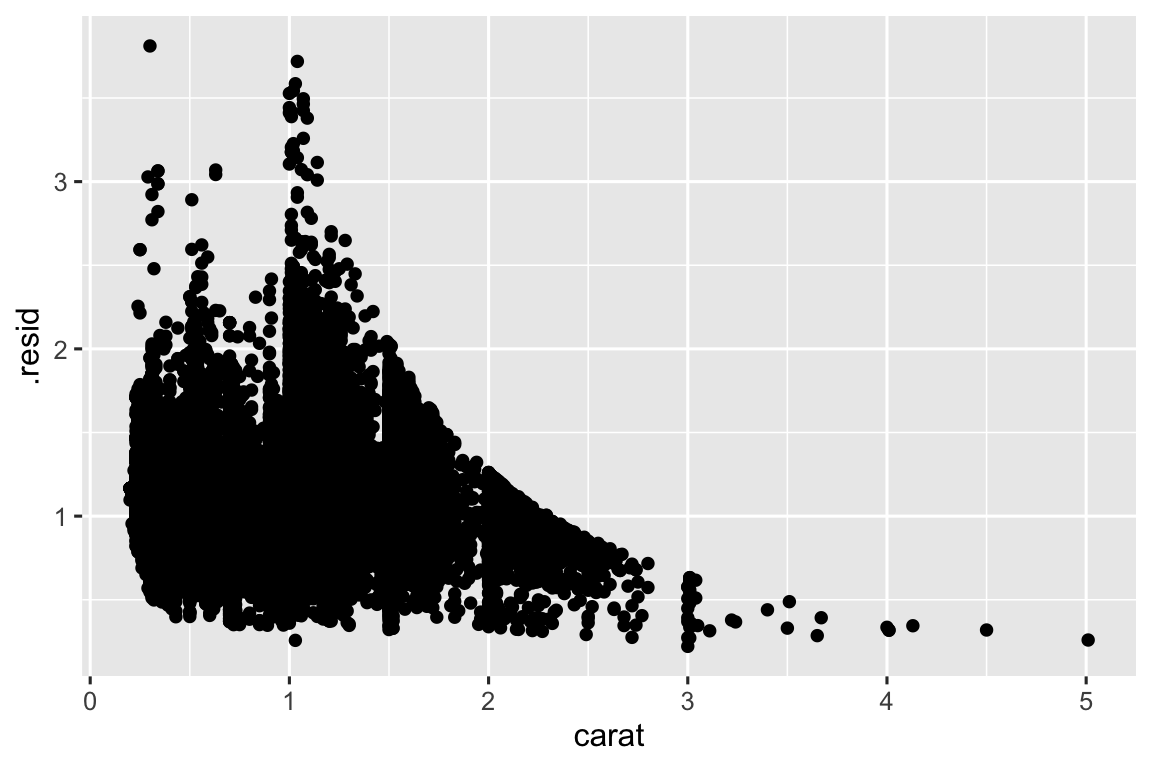
Sau khi loại bỏ mối quan hệ mạnh giữa carat và price, bạn thấy điều mong đợi: so với kích thước, kim cương chất lượng tốt hơn đắt hơn.
ggplot(diamonds_aug, aes(x = cut, y = .resid)) +
geom_boxplot()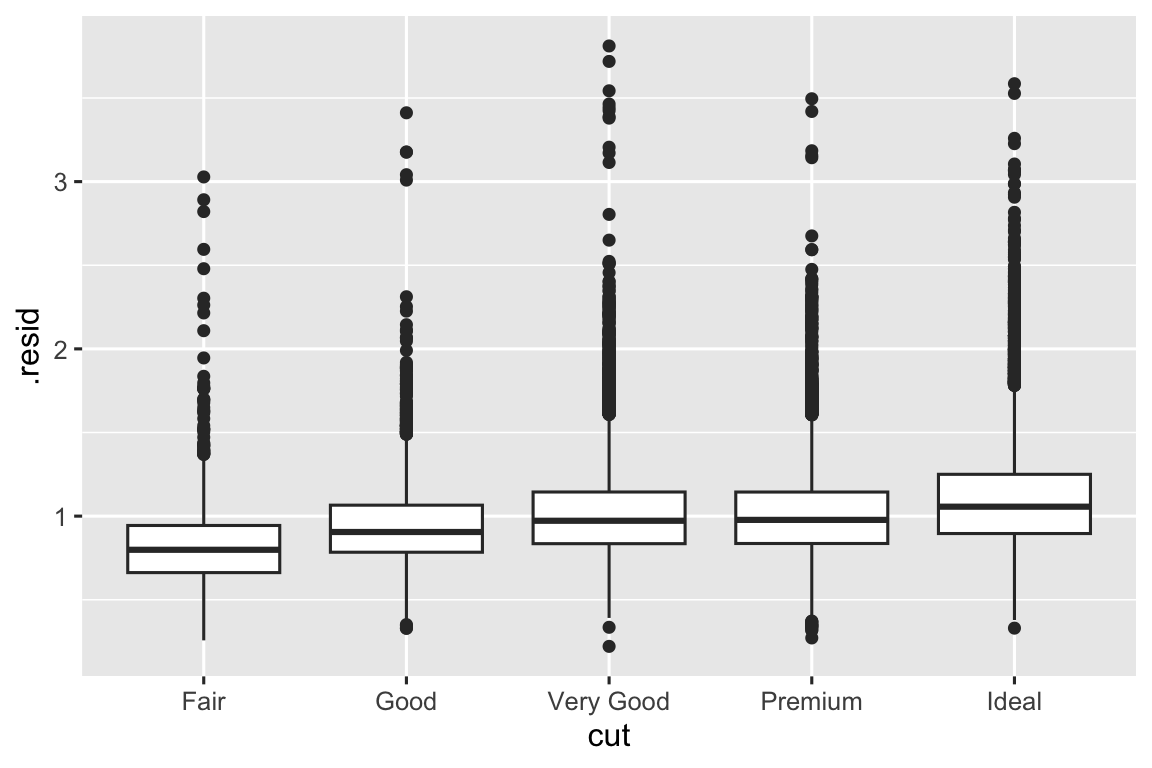
Chúng tôi không thảo luận mô hình hóa trong cuốn sách này vì hiểu mô hình dễ nhất khi bạn đã có công cụ xử lý dữ liệu và lập trình.
10.7 Tóm tắt
Trong chương này bạn đã học nhiều công cụ giúp hiểu biến thiên trong dữ liệu. Bạn đã thấy kỹ thuật hoạt động với một biến và với cặp biến. Điều này có vẻ hạn chế nếu bạn có row chục hoặc row trăm biến, nhưng chúng là nền tảng cho tất cả kỹ thuật khác.
Trong chương tiếp theo, chúng ta sẽ tập trung vào công cụ để truyền đạt kết quả.
Nhớ rằng khi cần chỉ rõ function (hoặc tập dữ liệu) đến từ đâu, chúng ta dùng dạng đặc biệt
package::function()hoặcpackage::dataset.↩︎