18 Giá trị khuyết
18.1 Giới thiệu
Bạn đã học những kiến thức cơ bản về missing value ở các phần trước của cuốn sách. Bạn lần đầu gặp chúng trong Chương 1 khi chúng gây ra cảnh báo khi vẽ biểu đồ, cũng như trong Phần 3.5.2 khi chúng ảnh hưởng đến việc tính toán các thống kê tóm tắt, và bạn đã tìm hiểu về tính “lây lan” của chúng cũng như cách kiểm tra sự hiện diện của chúng trong Phần 12.2.2. Giờ chúng ta sẽ quay lại theme này một cách chi tiết hơn, để bạn có thể hiểu sâu hơn.
Chúng ta sẽ bắt đầu bằng việc thảo luận một số công cụ chung để làm việc với missing value được ghi nhận dưới dạng NA. Tiếp theo, chúng ta sẽ khám phá khái niệm missing value ẩn (implicitly missing value) – những giá trị đơn giản là vắng mặt trong dữ liệu của bạn, và giới thiệu một số công cụ để biến chúng thành missing value tường minh (explicitly missing value). Cuối cùng, chúng ta sẽ kết thúc với một thảo luận liên quan về nhóm rỗng (empty group), xảy ra khi các mức factor (factor level) không xuất hiện trong dữ liệu.
18.1.1 Điều kiện tiên quyết
Các function để làm việc với dữ liệu khuyết chủ yếu đến từ dplyr và tidyr, là những thành viên cốt lõi của tidyverse.
18.2 Giá trị khuyết tường minh
Để bắt đầu, hãy khám phá một số công cụ hữu ích để tạo hoặc loại bỏ các missing value tường minh, tức là các ô mà bạn thấy NA.
18.2.1 Lấp đầy bằng quan sát cuối cùng
Một trường hợp sử dụng phổ biến của missing value là để thuận tiện cho việc nhập dữ liệu. Khi dữ liệu được nhập bằng tay, missing value đôi khi chỉ ra rằng giá trị ở row trước đó đã được iterate lại (hay mang xuống):
treatment <- tribble(
~person, ~treatment, ~response,
"Derrick Whitmore", 1, 7,
NA, 2, 10,
NA, 3, NA,
"Katherine Burke", 1, 4
)Bạn có thể lấp đầy các missing value này bằng tidyr::fill(). Nó hoạt động giống select(), nhận một tập hợp các column:
treatment |>
fill(everything())
#> # A tibble: 4 × 3
#> person treatment response
#> <chr> <dbl> <dbl>
#> 1 Derrick Whitmore 1 7
#> 2 Derrick Whitmore 2 10
#> 3 Derrick Whitmore 3 10
#> 4 Katherine Burke 1 4Cách xử lý này đôi khi được gọi là “lấp đầy bằng quan sát cuối cùng” (last observation carried forward), hay viết tắt là locf. Bạn có thể sử dụng argument .direction để lấp đầy các missing value được tạo ra theo những cách phức tạp hơn.
18.2.2 Giá trị cố định
Đôi khi missing value đại diện cho một giá trị cố định và đã biết, thường gặp nhất là 0. Bạn có thể sử dụng dplyr::coalesce() để thay thế chúng:
Đôi khi bạn gặp vấn đề ngược lại: một giá trị cụ thể thực ra đại diện cho missing value. Điều này thường xảy ra với dữ liệu được tạo bởi phần mềm cũ không có cách biểu diễn missing value đúng cách, nên phải sử dụng một giá trị đặc biệt như 99 hoặc -999.
Nếu có thể, hãy xử lý vấn đề này khi đọc dữ liệu, ví dụ bằng cách sử dụng argument na của readr::read_csv(), như read_csv(path, na = "99"). Nếu bạn phát hiện vấn đề muộn hơn, hoặc nguồn dữ liệu không cung cấp cách xử lý khi đọc, bạn có thể sử dụng dplyr::na_if():
18.2.3 NaN
Trước khi tiếp tục, có một loại missing value đặc biệt mà bạn sẽ thỉnh thoảng gặp: NaN (đọc là “nan”), viết tắt của not a number (không phải số). Bạn không cần quá quan tâm đến nó vì nó thường hoạt động giống hệt NA:
Trong trường hợp hiếm hoi bạn cần phân biệt NA với NaN, bạn có thể sử dụng is.nan(x).
Bạn thường gặp NaN khi thực hiện phép toán có kết quả không xác định:
0 / 0
#> [1] NaN
0 * Inf
#> [1] NaN
Inf - Inf
#> [1] NaN
sqrt(-1)
#> Warning in sqrt(-1): NaNs produced
#> [1] NaN18.3 Giá trị khuyết ẩn
Cho đến giờ chúng ta đã nói về missing value tường minh (explicitly missing), tức là bạn có thể thấy NA trong dữ liệu. Nhưng missing value cũng có thể ẩn (implicitly missing), nếu toàn bộ một row dữ liệu đơn giản là vắng mặt trong dữ liệu. Hãy minh họa sự khác biệt với một tập dữ liệu đơn giản ghi lại giá cổ phiếu theo từng quý:
Tập dữ liệu này có hai quan sát bị khuyết:
pricetrong quý 4 năm 2020 bị khuyết tường minh, vì giá trị của nó làNA.pricecho quý 1 năm 2021 bị khuyết ẩn, vì nó đơn giản là không xuất hiện trong tập dữ liệu.
Một cách để suy nghĩ về sự khác biệt này là thông qua câu nói mang tính triết lý sau:
Giá trị khuyết tường minh là sự hiện diện của một sự vắng mặt.
Giá trị khuyết ẩn là sự vắng mặt của một sự hiện diện.
Đôi khi bạn muốn biến missing value ẩn thành tường minh để có thứ gì đó cụ thể để làm việc. Trong các trường hợp khác, missing value tường minh bị áp đặt bởi cấu trúc dữ liệu và bạn muốn loại bỏ chúng. Các phần tiếp theo sẽ thảo luận một số công cụ để chuyển đổi giữa missing value ẩn và tường minh.
18.3.1 Xoay bảng
Bạn đã thấy một công cụ có thể biến missing value ẩn thành tường minh và ngược lại: xoay bảng (pivot). Mở rộng dữ liệu có thể làm cho missing value ẩn trở nên tường minh vì mỗi tổ hợp của các row và column mới đều phải có một giá trị nào đó. Ví dụ, nếu chúng ta xoay stocks để đặt quarter vào các column, cả hai missing value đều trở nên tường minh:
stocks |>
pivot_wider(
names_from = qtr,
values_from = price
)
#> # A tibble: 2 × 5
#> year `1` `2` `3` `4`
#> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2020 1.88 0.59 0.35 NA
#> 2 2021 NA 0.92 0.17 2.66Theo mặc định, kéo dài dữ liệu giữ nguyên missing value tường minh, nhưng nếu chúng là missing value cấu trúc chỉ tồn tại vì dữ liệu chưa gọn gàng (tidy), bạn có thể loại bỏ chúng (biến thành ẩn) bằng cách đặt values_drop_na = TRUE. Xem các ví dụ trong Phần 5.2 để biết thêm chi tiết.
18.3.2 Complete
tidyr::complete() cho phép bạn tạo ra các missing value tường minh bằng cách cung cấp một tập hợp các biến xác định tổ hợp row nào nên tồn tại. Ví dụ, chúng ta biết rằng tất cả tổ hợp của year và qtr nên tồn tại trong dữ liệu stocks:
stocks |>
complete(year, qtr)
#> # A tibble: 8 × 3
#> year qtr price
#> <dbl> <dbl> <dbl>
#> 1 2020 1 1.88
#> 2 2020 2 0.59
#> 3 2020 3 0.35
#> 4 2020 4 NA
#> 5 2021 1 NA
#> 6 2021 2 0.92
#> # ℹ 2 more rowsThông thường, bạn sẽ gọi complete() với tên các biến hiện có, để lấp đầy các tổ hợp còn thiếu. Tuy nhiên, đôi khi bản thân các biến cũng không đầy đủ, nên bạn có thể cung cấp dữ liệu của riêng mình. Ví dụ, bạn có thể biết rằng tập dữ liệu stocks được cho là chạy từ 2019 đến 2021, vì vậy bạn có thể cung cấp rõ ràng các giá trị đó cho year:
stocks |>
complete(year = 2019:2021, qtr)
#> # A tibble: 12 × 3
#> year qtr price
#> <dbl> <dbl> <dbl>
#> 1 2019 1 NA
#> 2 2019 2 NA
#> 3 2019 3 NA
#> 4 2019 4 NA
#> 5 2020 1 1.88
#> 6 2020 2 0.59
#> # ℹ 6 more rowsNếu phạm vi của một biến là đúng nhưng không phải tất cả giá trị đều có mặt, bạn có thể sử dụng full_seq(x, 1) để tạo tất cả giá trị từ min(x) đến max(x) với bước nhảy là 1.
Trong một số trường hợp, tập hợp đầy đủ các quan sát không thể được tạo bằng một tổ hợp đơn giản của các biến. Trong trường hợp đó, bạn có thể tự làm thủ công những gì complete() làm cho bạn: tạo một data frame chứa tất cả các row cần tồn tại (sử dụng bất kỳ tổ hợp kỹ thuật nào bạn cần), rồi kết hợp nó với tập dữ liệu gốc bằng dplyr::full_join().
18.3.3 Nối bảng
Điều này đưa chúng ta đến một cách quan trọng khác để phát hiện các quan sát bị khuyết ẩn: nối bảng (join). Bạn sẽ tìm hiểu thêm về nối bảng trong Chương 19, nhưng chúng tôi muốn đề cập nhanh ở đây vì bạn thường chỉ biết rằng các giá trị bị thiếu từ một tập dữ liệu khi so sánh nó với tập dữ liệu khác.
dplyr::anti_join(x, y) là một công cụ đặc biệt hữu ích ở đây vì nó chỉ chọn các row trong x không có row khớp trong y. Ví dụ, chúng ta có thể sử dụng hai anti_join() để phát hiện rằng chúng ta đang thiếu thông tin cho bốn sân bay và 722 máy bay được đề cập trong flights:
library(nycflights13)
flights |>
distinct(faa = dest) |>
anti_join(airports)
#> Joining with `by = join_by(faa)`
#> # A tibble: 4 × 1
#> faa
#> <chr>
#> 1 BQN
#> 2 SJU
#> 3 STT
#> 4 PSE
flights |>
distinct(tailnum) |>
anti_join(planes)
#> Joining with `by = join_by(tailnum)`
#> # A tibble: 722 × 1
#> tailnum
#> <chr>
#> 1 N3ALAA
#> 2 N3DUAA
#> 3 N542MQ
#> 4 N730MQ
#> 5 N9EAMQ
#> 6 N532UA
#> # ℹ 716 more rows18.3.4 Bài tập
- Bạn có thể tìm thấy mối quan hệ nào giữa hãng bay và các row có vẻ bị thiếu trong
planeskhông?
18.4 Nhân tố và nhóm rỗng
Loại missing value cuối cùng là nhóm rỗng, một nhóm không chứa bất kỳ quan sát nào, có thể phát sinh khi làm việc với factor (factor). Ví dụ, hãy tưởng tượng chúng ta có một tập dữ liệu chứa một số thông tin sức khỏe về mọi người:
Và chúng ta muốn đếm số người hút thuốc với dplyr::count():
health |> count(smoker)
#> # A tibble: 1 × 2
#> smoker n
#> <fct> <int>
#> 1 no 5Tập dữ liệu này chỉ chứa người không hút thuốc, nhưng chúng ta biết rằng người hút thuốc tồn tại; nhóm người hút thuốc là rỗng. Chúng ta có thể yêu cầu count() giữ tất cả các nhóm, kể cả những nhóm không có trong dữ liệu bằng cách sử dụng .drop = FALSE:
health |> count(smoker, .drop = FALSE)
#> # A tibble: 2 × 2
#> smoker n
#> <fct> <int>
#> 1 yes 0
#> 2 no 5Nguyên tắc tương tự áp dụng cho các trục rời rạc (discrete axis) của ggplot2, vốn cũng sẽ loại bỏ các mức không có giá trị nào. Bạn có thể buộc chúng hiển thị bằng cách cung cấp drop = FALSE cho trục rời rạc tương ứng:
ggplot(health, aes(x = smoker)) +
geom_bar() +
scale_x_discrete()
ggplot(health, aes(x = smoker)) +
geom_bar() +
scale_x_discrete(drop = FALSE)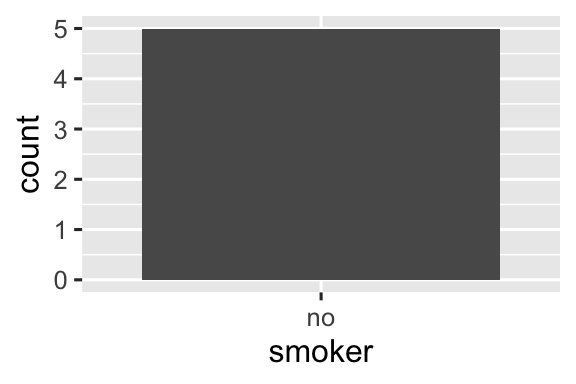
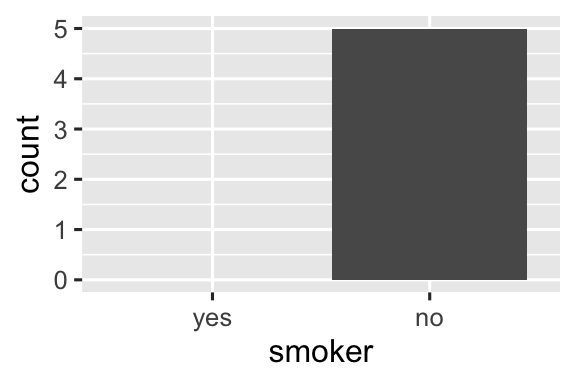
Vấn đề tương tự cũng xảy ra nói chung với dplyr::group_by(). Và một lần nữa bạn có thể sử dụng .drop = FALSE để giữ tất cả các mức factor:
health |>
group_by(smoker, .drop = FALSE) |>
summarize(
n = n(),
mean_age = mean(age),
min_age = min(age),
max_age = max(age),
sd_age = sd(age)
)
#> # A tibble: 2 × 6
#> smoker n mean_age min_age max_age sd_age
#> <fct> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 yes 0 NaN Inf -Inf NA
#> 2 no 5 60 34 88 21.6Chúng ta nhận được một số kết quả thú vị ở đây vì khi tóm tắt một nhóm rỗng, các function tóm tắt được áp dụng cho vector có độ dài bằng 0. Có một sự phân biệt quan trọng giữa vector rỗng (có độ dài 0) và missing value (mỗi giá trị có độ dài 1).
Tất cả các function tóm tắt đều hoạt động với vector có độ dài bằng 0, nhưng chúng có thể trả về kết quả gây bất ngờ lúc đầu. Ở đây chúng ta thấy mean(age) trả về NaN vì mean(age) = sum(age)/length(age) mà ở đây là 0/0. max() và min() trả về -Inf và Inf cho vector rỗng nên nếu bạn kết hợp kết quả với một vector dữ liệu mới không rỗng và tính lại, bạn sẽ nhận được giá trị nhỏ nhất hoặc lớn nhất của dữ liệu mới1.
Đôi khi cách tiếp cận đơn giản hơn là thực hiện phép tóm tắt trước rồi biến missing value ẩn thành tường minh với complete().
health |>
group_by(smoker) |>
summarize(
n = n(),
mean_age = mean(age),
min_age = min(age),
max_age = max(age),
sd_age = sd(age)
) |>
complete(smoker)
#> # A tibble: 2 × 6
#> smoker n mean_age min_age max_age sd_age
#> <fct> <int> <dbl> <dbl> <dbl> <dbl>
#> 1 yes NA NA NA NA NA
#> 2 no 5 60 34 88 21.6Nhược điểm chính của cách tiếp cận này là bạn nhận được NA cho số đếm, mặc dù bạn biết rằng nó phải là 0.
18.5 Tóm tắt
Giá trị khuyết thật kỳ lạ! Đôi khi chúng được ghi nhận dưới dạng NA tường minh nhưng đôi khi bạn chỉ nhận ra chúng qua sự vắng mặt. Chương này đã cung cấp cho bạn một số công cụ để làm việc với missing value tường minh, công cụ để phát hiện missing value ẩn, và thảo luận về một số cách mà missing value ẩn có thể trở thành tường minh và ngược lại.
Trong chương tiếp theo, chúng ta sẽ giải quyết chương cuối cùng trong phần này của cuốn sách: nối bảng. Đây là một sự thay đổi so với các chương trước vì chúng ta sẽ thảo luận về các công cụ làm việc với toàn bộ data frame, chứ không phải thứ gì đó mà bạn đặt bên trong một data frame.
Nói cách khác,
min(c(x, y))luôn bằngmin(min(x), min(y)).↩︎