15 Biểu thức chính quy
15.1 Giới thiệu
Trong Chương 14, bạn đã học được rất nhiều function hữu ích để làm việc với string. Chương này sẽ tập trung vào các function sử dụng regular expression, một ngôn ngữ ngắn gọn và mạnh mẽ để mô tả các mẫu trong string. Thuật ngữ “regular expression” khá dài dòng, nên hầu hết mọi người viết tắt thành “regex”1 hoặc “regexp”.
Chương này bắt đầu với những kiến thức cơ bản về regular expression và các function stringr hữu ích nhất cho phân tích dữ liệu. Sau đó chúng ta sẽ mở rộng kiến thức của bạn về các mẫu và đề cập đến bảy theme quan trọng mới (thoát ký tự, neo, lớp ký tự, lớp viết tắt, bộ định lượng, thứ tự ưu tiên, và nhóm). Tiếp theo, chúng ta sẽ nói về một số loại mẫu khác mà các function stringr có thể làm việc và các “cờ” (flag) khác nhau cho phép bạn điều chỉnh hoạt động của regular expression. Chúng ta sẽ kết thúc với một khảo sát về các nơi khác trong tidyverse và base R mà bạn có thể sử dụng regex.
15.1.1 Điều kiện tiên quyết
Trong chương này, chúng ta sẽ sử dụng các function regular expression từ stringr và tidyr, cả hai đều là thành viên cốt lõi của tidyverse, cũng như dữ liệu từ package babynames.
Xuyên suốt chương này, chúng ta sẽ sử dụng kết hợp các ví dụ inline rất đơn giản để bạn nắm được ý tưởng cơ bản, dữ liệu tên em bé, và ba vector ký tự từ stringr:
-
fruitchứa tên của 80 loại trái cây. -
wordschứa 980 từ tiếng Anh thông dụng. -
sentenceschứa 720 câu ngắn.
15.2 Cơ bản về mẫu
Chúng ta sẽ sử dụng str_view() để tìm hiểu cách các mẫu regex hoạt động. Chúng ta đã sử dụng str_view() trong chương trước để hiểu rõ hơn sự khác biệt giữa một string và biểu diễn in ra của nó, và bây giờ chúng ta sẽ sử dụng nó với argument thứ hai, một regular expression. Khi argument này được cung cấp, str_view() sẽ chỉ hiển thị các phần tử của vector string khớp với mẫu, bao quanh mỗi kết quả khớp bằng <>, và khi có thể, tô sáng kết quả khớp bằng màu xanh.
Các mẫu đơn giản nhất bao gồm các chữ cái và số khớp chính xác với các ký tự đó:
str_view(fruit, "berry")
#> [6] │ bil<berry>
#> [7] │ black<berry>
#> [10] │ blue<berry>
#> [11] │ boysen<berry>
#> [19] │ cloud<berry>
#> [21] │ cran<berry>
#> ... and 8 moreCác chữ cái và số khớp chính xác và được gọi là ký tự chữ (literal character). Hầu hết các ký tự dấu câu, như ., +, *, [, ], và ?, có ý nghĩa đặc biệt2 và được gọi là siêu ký tự (metacharacter). Ví dụ, . sẽ khớp với bất kỳ ký tự nào3, nên "a." sẽ khớp với bất kỳ string nào chứa “a” theo sau bởi một ký tự khác :
Hoặc chúng ta có thể tìm tất cả các loại trái cây chứa “a”, theo sau bởi ba chữ cái, theo sau bởi “e”:
str_view(fruit, "a...e")
#> [1] │ <apple>
#> [7] │ bl<ackbe>rry
#> [48] │ mand<arine>
#> [51] │ nect<arine>
#> [62] │ pine<apple>
#> [64] │ pomegr<anate>
#> ... and 2 moreBộ định lượng (quantifier) kiểm soát số lần một mẫu có thể khớp:
-
?làm cho mẫu trở thành tùy chọn (tức là nó khớp 0 hoặc 1 lần) -
+cho phép mẫu iterate lại (tức là nó khớp ít nhất một lần) -
*cho phép mẫu là tùy chọn hoặc iterate lại (tức là nó khớp bất kỳ số lần nào, kể cả 0).
# ab? khớp với "a", tùy chọn theo sau bởi "b".
str_view(c("a", "ab", "abb"), "ab?")
#> [1] │ <a>
#> [2] │ <ab>
#> [3] │ <ab>b
# ab+ khớp với "a", theo sau bởi ít nhất một "b".
str_view(c("a", "ab", "abb"), "ab+")
#> [2] │ <ab>
#> [3] │ <abb>
# ab* khớp với "a", theo sau bởi bất kỳ số lượng "b" nào.
str_view(c("a", "ab", "abb"), "ab*")
#> [1] │ <a>
#> [2] │ <ab>
#> [3] │ <abb>Lớp ký tự (character class) được định nghĩa bằng [] và cho phép bạn khớp bất kỳ ký tự nào trong một tập hợp, ví dụ [abcd] khớp với “a”, “b”, “c”, hoặc “d”. Bạn cũng có thể đảo ngược kết quả khớp bằng cách bắt đầu với ^: [^abcd] khớp với bất kỳ ký tự nào ngoại trừ “a”, “b”, “c”, hoặc “d”. Chúng ta có thể sử dụng ý tưởng này để tìm các từ chứa “x” được bao quanh bởi nguyên âm, hoặc “y” được bao quanh bởi phụ âm:
Bạn có thể sử dụng phép thay thế (alternation), |, để chọn giữa một hoặc nhiều mẫu thay thế. Ví dụ, các mẫu sau tìm kiếm trái cây chứa “apple”, “melon”, hoặc “nut”, hoặc một nguyên âm iterate lại.
str_view(fruit, "apple|melon|nut")
#> [1] │ <apple>
#> [13] │ canary <melon>
#> [20] │ coco<nut>
#> [52] │ <nut>
#> [62] │ pine<apple>
#> [72] │ rock <melon>
#> ... and 1 more
str_view(fruit, "aa|ee|ii|oo|uu")
#> [9] │ bl<oo>d orange
#> [33] │ g<oo>seberry
#> [47] │ lych<ee>
#> [66] │ purple mangost<ee>nBiểu thức chính quy rất cô đọng và sử dụng nhiều ký tự dấu câu, nên ban đầu chúng có thể trông choáng ngợp và khó đọc. Đừng lo lắng; bạn sẽ giỏi hơn với sự luyện tập, và các mẫu đơn giản sẽ sớm trở nên quen thuộc. Hãy bắt đầu quá trình đó bằng cách thực hành với một số function stringr hữu ích.
15.3 Các function chính
Bây giờ bạn đã nắm được kiến thức cơ bản về regular expression, hãy sử dụng chúng với một số function stringr và tidyr. Trong phần tiếp theo, bạn sẽ học cách phát hiện sự có mặt hoặc vắng mặt của một kết quả khớp, cách đếm số lượng kết quả khớp, cách thay thế kết quả khớp bằng văn bản cố định, và cách trích xuất văn bản bằng mẫu.
15.3.1 Phát hiện kết quả khớp
str_detect() trả về một vector logic có giá trị TRUE nếu mẫu khớp với một phần tử của vector ký tự và FALSE nếu không:
str_detect(c("a", "b", "c"), "[aeiou]")
#> [1] TRUE FALSE FALSEVì str_detect() trả về một vector logic có cùng độ dài với vector ban đầu, nó kết hợp tốt với filter(). Ví dụ, đoạn mã này tìm tất cả các tên phổ biến nhất chứa chữ “x” viết thường:
babynames |>
filter(str_detect(name, "x")) |>
count(name, wt = n, sort = TRUE)
#> # A tibble: 974 × 2
#> name n
#> <chr> <int>
#> 1 Alexander 665492
#> 2 Alexis 399551
#> 3 Alex 278705
#> 4 Alexandra 232223
#> 5 Max 148787
#> 6 Alexa 123032
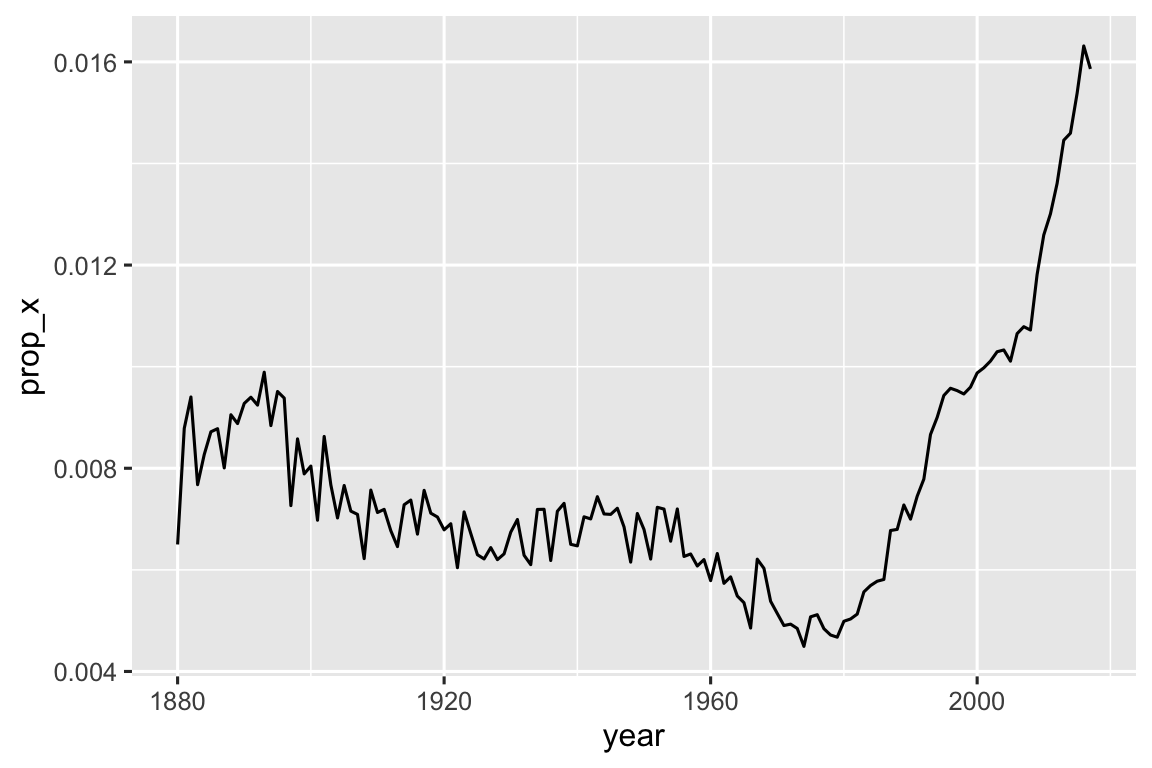
#> # ℹ 968 more rowsChúng ta cũng có thể sử dụng str_detect() với summarize() bằng cách kết hợp nó với sum() hoặc mean(): sum(str_detect(x, pattern)) cho bạn biết số quan sát khớp và mean(str_detect(x, pattern)) cho bạn biết tỷ lệ khớp. Ví dụ, đoạn mã sau tính toán và visualization tỷ lệ tên em bé4 chứa “x”, phân chia theo năm. Có vẻ như chúng đã tăng mạnh về độ phổ biến gần đây!
Có hai function liên quan chặt chẽ với str_detect(): str_subset() và str_which(). str_subset() trả về một vector ký tự chỉ chứa các string khớp. str_which() trả về một vector số nguyên cho biết vị trí của các string khớp.
15.3.2 Đếm kết quả khớp
Bước tiếp theo phức tạp hơn str_detect() là str_count(): thay vì đúng hoặc sai, nó cho bạn biết có bao nhiêu kết quả khớp trong mỗi string.
Lưu ý rằng mỗi kết quả khớp bắt đầu tại cuối kết quả khớp trước đó, tức là các kết quả khớp regex không bao giờ chồng chéo nhau. Ví dụ, trong "abababa", mẫu "aba" sẽ khớp bao nhiêu lần? Biểu thức chính quy cho kết quả là hai, không phải ba:
Việc sử dụng str_count() với mutate() là rất tự nhiên. Ví dụ sau sử dụng str_count() với các lớp ký tự để đếm số nguyên âm và phụ âm trong mỗi tên.
babynames |>
count(name) |>
mutate(
vowels = str_count(name, "[aeiou]"),
consonants = str_count(name, "[^aeiou]")
)
#> # A tibble: 97,310 × 4
#> name n vowels consonants
#> <chr> <int> <int> <int>
#> 1 Aaban 10 2 3
#> 2 Aabha 5 2 3
#> 3 Aabid 2 2 3
#> 4 Aabir 1 2 3
#> 5 Aabriella 5 4 5
#> 6 Aada 1 2 2
#> # ℹ 97,304 more rowsNếu bạn nhìn kỹ, bạn sẽ nhận ra có điều gì đó không đúng với phép tính của chúng ta: “Aaban” chứa ba chữ “a”, nhưng bảng tóm tắt chỉ báo cáo hai nguyên âm. Đó là vì regular expression phân biệt chữ hoa chữ thường. Có ba cách chúng ta có thể sửa điều này:
- Thêm các nguyên âm viết hoa vào lớp ký tự:
str_count(name, "[aeiouAEIOU]"). - Yêu cầu regular expression bỏ qua chữ hoa chữ thường:
str_count(name, regex("[aeiou]", ignore_case = TRUE)). Chúng ta sẽ nói thêm về điều này trong Phần 15.5.1. - Sử dụng
str_to_lower()để chuyển tên thành chữ thường:str_count(str_to_lower(name), "[aeiou]").
Sự đa dạng về cách tiếp cận này khá điển hình khi làm việc với string — thường có nhiều cách để đạt được mục tiêu, bằng cách làm mẫu phức tạp hơn hoặc bằng cách tiền xử lý string. Nếu bạn bị mắc kẹt khi thử một cách tiếp cận, thường sẽ hữu ích khi chuyển hướng và giải quyết vấn đề từ một góc nhìn khác.
Trong trường hợp này, vì chúng ta đang áp dụng hai function cho tên, tôi nghĩ việc biến đổi nó trước sẽ dễ hơn:
babynames |>
count(name) |>
mutate(
name = str_to_lower(name),
vowels = str_count(name, "[aeiou]"),
consonants = str_count(name, "[^aeiou]")
)
#> # A tibble: 97,310 × 4
#> name n vowels consonants
#> <chr> <int> <int> <int>
#> 1 aaban 10 3 2
#> 2 aabha 5 3 2
#> 3 aabid 2 3 2
#> 4 aabir 1 3 2
#> 5 aabriella 5 5 4
#> 6 aada 1 3 1
#> # ℹ 97,304 more rows15.3.3 Thay thế giá trị
Ngoài việc phát hiện và đếm kết quả khớp, chúng ta cũng có thể sửa đổi chúng với str_replace() và str_replace_all(). str_replace() thay thế kết quả khớp đầu tiên, và đúng như tên gọi, str_replace_all() thay thế tất cả kết quả khớp.
x <- c("apple", "pear", "banana")
str_replace_all(x, "[aeiou]", "-")
#> [1] "-ppl-" "p--r" "b-n-n-"str_remove() và str_remove_all() là các phím tắt tiện lợi cho str_replace(x, pattern, ""):
x <- c("apple", "pear", "banana")
str_remove_all(x, "[aeiou]")
#> [1] "ppl" "pr" "bnn"Các function này tự nhiên kết hợp với mutate() khi làm sạch dữ liệu, và bạn sẽ thường áp dụng chúng nhiều lần để gỡ bỏ các lớp định dạng không nhất quán.
15.3.4 Trích xuất biến
Function cuối cùng chúng ta sẽ thảo luận sử dụng regular expression để trích xuất dữ liệu từ một column thành một hoặc nhiều column mới: separate_wider_regex(). Nó là đồng cấp của các function separate_wider_position() và separate_wider_delim() mà bạn đã học trong Phần 14.4.2. Các function này nằm trong tidyr vì chúng hoạt động trên (các column của) data frame, thay vì các vector riêng lẻ.
Hãy tạo một tập dữ liệu đơn giản để minh họa cách nó hoạt động. Ở đây chúng ta có một số dữ liệu được lấy từ babynames trong đó chúng ta có tên, giới tính, và tuổi của một số người ở một định dạng khá kỳ lạ5:
df <- tribble(
~str,
"<Sheryl>-F_34",
"<Kisha>-F_45",
"<Brandon>-N_33",
"<Sharon>-F_38",
"<Penny>-F_58",
"<Justin>-M_41",
"<Patricia>-F_84",
)Để trích xuất dữ liệu này bằng separate_wider_regex() chúng ta chỉ cần xây dựng một string các regular expression khớp với từng phần. Nếu chúng ta muốn nội dung của phần đó xuất hiện trong kết quả đầu ra, chúng ta đặt tên cho nó:
df |>
separate_wider_regex(
str,
patterns = c(
"<",
name = "[A-Za-z]+",
">-",
gender = ".",
"_",
age = "[0-9]+"
)
)
#> # A tibble: 7 × 3
#> name gender age
#> <chr> <chr> <chr>
#> 1 Sheryl F 34
#> 2 Kisha F 45
#> 3 Brandon N 33
#> 4 Sharon F 38
#> 5 Penny F 58
#> 6 Justin M 41
#> # ℹ 1 more rowNếu việc khớp thất bại, bạn có thể sử dụng too_few = "debug" để tìm hiểu điều gì đã sai, giống như separate_wider_delim() và separate_wider_position().
15.3.5 Bài tập
Tên em bé nào có nhiều nguyên âm nhất? Tên nào có tỷ lệ nguyên âm cao nhất? (Gợi ý: mẫu số là gì?)
Thay thế tất cả dấu gạch chéo xuôi trong
"a/b/c/d/e"bằng dấu gạch chéo ngược. Điều gì xảy ra nếu bạn cố gắng hoàn tác phép biến đổi bằng cách thay thế tất cả dấu gạch chéo ngược bằng dấu gạch chéo xuôi? (Chúng ta sẽ thảo luận vấn đề này rất sớm.)Triển khai một phiên bản đơn giản của
str_to_lower()bằngstr_replace_all().Tạo một regular expression khớp với số điện thoại như cách viết thông dụng ở nước bạn.
15.4 Chi tiết về mẫu
Bây giờ bạn đã hiểu những kiến thức cơ bản về ngôn ngữ mẫu và cách sử dụng nó với một số function stringr và tidyr, đã đến lúc đi sâu vào chi tiết hơn. Đầu tiên, chúng ta sẽ bắt đầu với thoát ký tự (escaping), cho phép bạn khớp các siêu ký tự mà nếu không sẽ được xử lý đặc biệt. Tiếp theo, bạn sẽ học về neo (anchor) cho phép bạn khớp ở đầu hoặc cuối string. Sau đó, bạn sẽ tìm hiểu thêm về lớp ký tự và các phím tắt của chúng cho phép bạn khớp bất kỳ ký tự nào từ một tập hợp. Tiếp theo, bạn sẽ tìm hiểu chi tiết cuối cùng về bộ định lượng kiểm soát số lần một mẫu có thể khớp. Sau đó, chúng ta phải đề cập đến theme quan trọng (nhưng phức tạp) về thứ tự ưu tiên toán tử (operator precedence) và dấu ngoặc đơn. Và chúng ta sẽ kết thúc với một số chi tiết về nhóm (grouping) các thành phần của mẫu.
Các thuật ngữ chúng ta sử dụng ở đây là tên kỹ thuật cho mỗi thành phần. Chúng không phải lúc nào cũng gợi nhớ nhất về mục đích của mình, nhưng việc biết đúng thuật ngữ rất hữu ích nếu sau này bạn muốn tìm kiếm thêm chi tiết trên Google.
15.4.1 Thoát ký tự
Để khớp với dấu . theo nghĩa đen, bạn cần một ký tự thoát (escape) để yêu cầu regular expression khớp các siêu ký tự6 theo nghĩa đen. Giống như string, regexp sử dụng dấu gạch chéo ngược để thoát ký tự. Vì vậy, để khớp với dấu ., bạn cần regexp \.. Thật không may điều này tạo ra một vấn đề. Chúng ta sử dụng string để biểu diễn regular expression, và \ cũng được sử dụng làm ký hiệu thoát trong string. Vì vậy để tạo regular expression \. chúng ta cần string "\\.", như ví dụ sau minh họa.
Trong cuốn sách này, chúng ta thường viết regular expression không có dấu ngoặc kép, như \.. Nếu chúng ta cần nhấn mạnh những gì bạn thực sự gõ, chúng ta sẽ bao quanh nó bằng dấu ngoặc kép và thêm các ký tự thoát bổ sung, như "\\.".
Nếu \ được sử dụng làm ký tự thoát trong regular expression, làm thế nào bạn khớp với dấu \ theo nghĩa đen? Bạn cần thoát nó, tạo ra regular expression \\. Để tạo regular expression đó, bạn cần sử dụng một string, mà cũng cần thoát \. Điều đó có nghĩa là để khớp với dấu \ theo nghĩa đen, bạn cần viết "\\\\" — bạn cần bốn dấu gạch chéo ngược để khớp với một!
Ngoài ra, bạn có thể thấy dễ hơn khi sử dụng string thô (raw string) mà bạn đã học trong Phần 14.2.2. Điều đó cho phép bạn tránh một lớp thoát ký tự:
str_view(x, r"{\\}")
#> [1] │ a<\>bNếu bạn đang cố khớp dấu ., $, |, *, +, ?, {, }, (, ) theo nghĩa đen, có một cách thay thế cho việc sử dụng ký tự thoát bằng dấu gạch chéo ngược: bạn có thể sử dụng lớp ký tự: [.], [$], [|], … tất cả đều khớp với các giá trị theo nghĩa đen.
15.4.2 Neo
Theo mặc định, regular expression sẽ khớp với bất kỳ phần nào của string. Nếu bạn muốn khớp ở đầu hoặc cuối, bạn cần neo (anchor) regular expression bằng ^ để khớp ở đầu hoặc $ để khớp ở cuối:
Bạn có thể muốn nghĩ rằng $ nên khớp ở đầu string, vì đó là cách chúng ta viết số tiền đô la, nhưng đó không phải là điều regular expression muốn.
Để buộc regular expression chỉ khớp với toàn bộ string, hãy neo nó bằng cả ^ và $:
Bạn cũng có thể khớp ranh giới giữa các từ (tức là đầu hoặc cuối của một từ) bằng \b. Điều này có thể đặc biệt hữu ích khi sử dụng công cụ tìm và thay thế của RStudio. Ví dụ, để tìm tất cả các nơi sử dụng sum(), bạn có thể tìm kiếm \bsum\b để tránh khớp với summarize, summary, rowsum và những function khác:
Khi được sử dụng một mình, neo sẽ tạo ra một kết quả khớp có độ rộng bằng không:
Điều này giúp bạn hiểu điều gì xảy ra khi bạn thay thế một neo độc lập:
str_replace_all("abc", c("$", "^", "\\b"), "--")
#> [1] "abc--" "--abc" "--abc--"15.4.3 Lớp ký tự
Một lớp ký tự, hay tập ký tự (character set), cho phép bạn khớp bất kỳ ký tự nào trong một tập hợp. Như chúng ta đã thảo luận ở trên, bạn có thể tự xây dựng các tập hợp với [], trong đó [abc] khớp với “a”, “b”, hoặc “c” và [^abc] khớp với bất kỳ ký tự nào ngoại trừ “a”, “b”, hoặc “c”. Ngoài ^, có hai ký tự khác có ý nghĩa đặc biệt bên trong []:
-
-định nghĩa một phạm vi, ví dụ[a-z]khớp với bất kỳ chữ cái thường nào và[0-9]khớp với bất kỳ số nào. -
\thoát các ký tự đặc biệt, nên[\^\-\]]khớp với^,-, hoặc].
Đây là một vài ví dụ:
x <- "abcd ABCD 12345 -!@#%."
str_view(x, "[abc]+")
#> [1] │ <abc>d ABCD 12345 -!@#%.
str_view(x, "[a-z]+")
#> [1] │ <abcd> ABCD 12345 -!@#%.
str_view(x, "[^a-z0-9]+")
#> [1] │ abcd< ABCD >12345< -!@#%.>
# Bạn cần ký tự thoát để khớp với các ký tự đặc biệt
# bên trong []
str_view("a-b-c", "[a-c]")
#> [1] │ <a>-<b>-<c>
str_view("a-b-c", "[a\\-c]")
#> [1] │ <a><->b<-><c>Một số lớp ký tự được sử dụng phổ biến đến mức chúng có phím tắt riêng. Bạn đã thấy ., khớp với bất kỳ ký tự nào ngoại trừ ký tự xuống dòng. Có ba cặp đặc biệt hữu ích khác7:
-
\dkhớp với bất kỳ chữ số nào;\Dkhớp với bất kỳ thứ gì không phải chữ số. -
\skhớp với bất kỳ khoảng trắng nào (ví dụ dấu cách, tab, xuống dòng);\Skhớp với bất kỳ thứ gì không phải khoảng trắng. -
\wkhớp với bất kỳ ký tự “từ” nào, tức là chữ cái và số;\Wkhớp với bất kỳ ký tự “không phải từ” nào.
Đoạn mã sau minh họa sáu phím tắt với một lựa chọn các chữ cái, số, và ký tự dấu câu.
x <- "abcd ABCD 12345 -!@#%."
str_view(x, "\\d+")
#> [1] │ abcd ABCD <12345> -!@#%.
str_view(x, "\\D+")
#> [1] │ <abcd ABCD >12345< -!@#%.>
str_view(x, "\\s+")
#> [1] │ abcd< >ABCD< >12345< >-!@#%.
str_view(x, "\\S+")
#> [1] │ <abcd> <ABCD> <12345> <-!@#%.>
str_view(x, "\\w+")
#> [1] │ <abcd> <ABCD> <12345> -!@#%.
str_view(x, "\\W+")
#> [1] │ abcd< >ABCD< >12345< -!@#%.>15.4.4 Bộ định lượng
Bộ định lượng kiểm soát số lần một mẫu khớp. Trong Phần 15.2 bạn đã học về ? (0 hoặc 1 lần khớp), + (1 hoặc nhiều lần khớp), và * (0 hoặc nhiều lần khớp). Ví dụ, colou?r sẽ khớp với cách viết tiếng Anh Mỹ hoặc Anh, \d+ sẽ khớp với một hoặc nhiều chữ số, và \s? sẽ tùy chọn khớp với một khoảng trắng. Bạn cũng có thể chỉ định chính xác số lần khớp bằng {}:
-
{n}khớp chính xác n lần. -
{n,}khớp ít nhất n lần. -
{n,m}khớp từ n đến m lần.
15.4.5 Thứ tự ưu tiên toán tử và dấu ngoặc đơn
ab+ khớp với cái gì? Nó khớp với “a” theo sau bởi một hoặc nhiều “b”, hay nó khớp với “ab” iterate lại bất kỳ số lần nào? ^a|b$ khớp với cái gì? Nó khớp với toàn bộ string a hoặc toàn bộ string b, hay nó khớp với string bắt đầu bằng a hoặc string kết thúc bằng b?
Câu trả lời cho những câu hỏi này được xác định bởi thứ tự ưu tiên toán tử, tương tự như quy tắc PEMDAS hoặc BEDMAS mà bạn có thể đã học ở trường. Bạn biết rằng a + b * c tương đương với a + (b * c) chứ không phải (a + b) * c vì * có thứ tự ưu tiên cao hơn và + có thứ tự ưu tiên thấp hơn: bạn tính * trước +.
Tương tự, regular expression có quy tắc ưu tiên riêng: bộ định lượng có thứ tự ưu tiên cao và phép thay thế có thứ tự ưu tiên thấp, nghĩa là ab+ tương đương với a(b+), và ^a|b$ tương đương với (^a)|(b$). Giống như trong đại số, bạn có thể sử dụng dấu ngoặc đơn để ghi đè thứ tự thông thường. Nhưng không giống đại số, bạn khó có thể nhớ các quy tắc ưu tiên cho regex, vì vậy hãy thoải mái sử dụng dấu ngoặc đơn một cách tự do.
15.4.6 Nhóm và bắt giữ
Ngoài việc ghi đè thứ tự ưu tiên toán tử, dấu ngoặc đơn còn có một tác dụng quan trọng khác: chúng tạo ra các nhóm bắt giữ (capturing group) cho phép bạn sử dụng các thành phần con của kết quả khớp.
Cách đầu tiên để sử dụng nhóm bắt giữ là tham chiếu ngược lại trong một kết quả khớp bằng tham chiếu ngược (back reference): \1 tham chiếu đến kết quả khớp chứa trong dấu ngoặc đơn thứ nhất, \2 trong dấu ngoặc đơn thứ hai, và cứ tiếp tục như vậy. Ví dụ, mẫu sau tìm tất cả trái cây có một cặp chữ cái iterate lại:
str_view(fruit, "(..)\\1")
#> [4] │ b<anan>a
#> [20] │ <coco>nut
#> [22] │ <cucu>mber
#> [41] │ <juju>be
#> [56] │ <papa>ya
#> [73] │ s<alal> berryVà mẫu này tìm tất cả các từ bắt đầu và kết thúc bằng cùng một cặp chữ cái:
str_view(words, "^(..).*\\1$")
#> [152] │ <church>
#> [217] │ <decide>
#> [617] │ <photograph>
#> [699] │ <require>
#> [739] │ <sense>Bạn cũng có thể sử dụng tham chiếu ngược trong str_replace(). Ví dụ, đoạn mã này hoán đổi thứ tự của từ thứ hai và thứ ba trong sentences:
sentences |>
str_replace("(\\w+) (\\w+) (\\w+)", "\\1 \\3 \\2") |>
str_view()
#> [1] │ The canoe birch slid on the smooth planks.
#> [2] │ Glue sheet the to the dark blue background.
#> [3] │ It's to easy tell the depth of a well.
#> [4] │ These a days chicken leg is a rare dish.
#> [5] │ Rice often is served in round bowls.
#> [6] │ The of juice lemons makes fine punch.
#> ... and 714 moreNếu bạn muốn trích xuất các kết quả khớp cho mỗi nhóm, bạn có thể sử dụng str_match(). Nhưng str_match() trả về một ma trận (matrix), nên nó không đặc biệt dễ làm việc8:
Bạn có thể chuyển đổi thành tibble và đặt tên các column:
sentences |>
str_match("the (\\w+) (\\w+)") |>
as_tibble(.name_repair = "minimal") |>
set_names("match", "word1", "word2")
#> # A tibble: 720 × 3
#> match word1 word2
#> <chr> <chr> <chr>
#> 1 the smooth planks smooth planks
#> 2 the sheet to sheet to
#> 3 the depth of depth of
#> 4 <NA> <NA> <NA>
#> 5 <NA> <NA> <NA>
#> 6 <NA> <NA> <NA>
#> # ℹ 714 more rowsNhưng khi đó bạn về cơ bản đã tự tạo lại phiên bản riêng của separate_wider_regex(). Thực tế, đằng sau hậu trường, separate_wider_regex() chuyển đổi vector mẫu của bạn thành một regex duy nhất sử dụng nhóm để bắt giữ các thành phần được đặt tên.
Đôi khi, bạn sẽ muốn sử dụng dấu ngoặc đơn mà không tạo nhóm khớp. Bạn có thể tạo một nhóm không bắt giữ (non-capturing group) bằng (?:).
15.4.7 Bài tập
Làm thế nào bạn khớp với string theo nghĩa đen
"'\? Còn"$^$"thì sao?Giải thích tại sao mỗi mẫu sau không khớp với
\:"\","\\","\\\".-
Cho tập từ thông dụng trong
stringr::words, tạo các regular expression tìm tất cả các từ mà:- Bắt đầu bằng “y”.
- Không bắt đầu bằng “y”.
- Kết thúc bằng “x”.
- Dài chính xác ba chữ cái. (Đừng gian lận bằng cách sử dụng
str_length()!) - Có bảy chữ cái trở lên.
- Chứa một cặp nguyên âm-phụ âm.
- Chứa ít nhất hai cặp nguyên âm-phụ âm liên tiếp.
- Chỉ bao gồm các cặp nguyên âm-phụ âm iterate lại.
Tạo 11 regular expression khớp với cách viết tiếng Anh Mỹ hoặc Anh cho mỗi từ sau: airplane/aeroplane, aluminum/aluminium, analog/analogue, ass/arse, center/centre, defense/defence, donut/doughnut, gray/grey, modeling/modelling, skeptic/sceptic, summarize/summarise. Hãy cố gắng tạo regex ngắn nhất có thể!
Hoán đổi chữ cái đầu tiên và cuối cùng trong
words. Chuỗi nào trong số đó vẫn làwords?-
Mô tả bằng lời các regular expression sau khớp với cái gì: (đọc kỹ để xem mỗi mục là regular expression hay string định nghĩa regular expression.)
^.*$"\\{.+\\}"\d{4}-\d{2}-\d{2}"\\\\{4}"\..\..\..(.)\1\1"(..)\\1"
Giải các câu đố ô chữ regexp mức cơ bản tại https://regexcrossword.com/challenges/beginner.
15.5 Kiểm soát mẫu
Bạn có thể kiểm soát thêm các chi tiết của kết quả khớp bằng cách sử dụng đối tượng mẫu thay vì chỉ một string. Điều này cho phép bạn kiểm soát cái gọi là cờ regex và khớp các loại string cố định khác nhau, như mô tả bên dưới.
15.5.1 Cờ regex
Có một số cài đặt có thể được sử dụng để kiểm soát chi tiết của regexp. Các cài đặt này thường được gọi là cờ (flag) trong các ngôn ngữ lập trình khác. Trong stringr, bạn có thể sử dụng chúng bằng cách bọc mẫu trong một lời gọi đến regex(). Cờ hữu ích nhất có lẽ là ignore_case = TRUE vì nó cho phép các ký tự khớp với dạng chữ hoa hoặc chữ thường:
Nếu bạn đang làm việc nhiều với string đa dòng (tức là string chứa \n), dotall và multiline cũng có thể hữu ích:
-
dotall = TRUEcho phép.khớp với mọi thứ, kể cả\n: -
multiline = TRUElàm cho^và$khớp ở đầu và cuối mỗi dòng thay vì đầu và cuối toàn bộ string:
Cuối cùng, nếu bạn đang viết một regular expression phức tạp và lo lắng rằng trong tương lai bạn có thể không hiểu nó, bạn có thể thử comments = TRUE. Nó điều chỉnh ngôn ngữ mẫu để bỏ qua khoảng trắng và xuống dòng, cũng như mọi thứ sau #. Điều này cho phép bạn sử dụng comment và khoảng trắng để làm cho regular expression phức tạp dễ hiểu hơn9, như trong ví dụ sau:
phone <- regex(
r"(
\(? # dấu ngoặc mở tùy chọn
(\d{3}) # mã vùng
[)\-]? # dấu ngoặc đóng hoặc gạch ngang tùy chọn
\ ? # khoảng trắng tùy chọn
(\d{3}) # ba số tiếp theo
[\ -]? # khoảng trắng hoặc gạch ngang tùy chọn
(\d{4}) # bốn số cuối
)",
comments = TRUE
)
str_extract(c("514-791-8141", "(123) 456 7890", "123456"), phone)
#> [1] "514-791-8141" "(123) 456 7890" NANếu bạn đang sử dụng comment và muốn khớp dấu cách, xuống dòng, hoặc #, bạn sẽ cần thoát nó bằng \.
15.5.2 Khớp cố định
Bạn có thể bỏ qua các quy tắc regular expression bằng cách sử dụng fixed():
fixed() cũng cho bạn khả năng bỏ qua chữ hoa chữ thường:
Nếu bạn đang làm việc với văn bản không phải tiếng Anh, bạn có thể sẽ muốn dùng coll() thay vì fixed(), vì nó triển khai đầy đủ các quy tắc viết hoa theo locale mà bạn chỉ định. Xem Phần 14.6 để biết thêm chi tiết về locale.
15.6 Thực hành
Để áp dụng những ý tưởng này vào thực tế, tiếp theo chúng ta sẽ giải một vài bài toán gần giống thực tế. Chúng ta sẽ thảo luận ba kỹ thuật chung:
- kiểm tra kết quả của bạn bằng cách tạo các trường hợp kiểm thử dương và âm đơn giản
- kết hợp regular expression với đại số Boole
- tạo các mẫu phức tạp bằng thao tác string
15.6.1 Kiểm tra kết quả của bạn
Đầu tiên, hãy tìm tất cả các câu bắt đầu bằng “The”. Chỉ sử dụng neo ^ thôi chưa đủ:
str_view(sentences, "^The")
#> [1] │ <The> birch canoe slid on the smooth planks.
#> [4] │ <The>se days a chicken leg is a rare dish.
#> [6] │ <The> juice of lemons makes fine punch.
#> [7] │ <The> box was thrown beside the parked truck.
#> [8] │ <The> hogs were fed chopped corn and garbage.
#> [11] │ <The> boy was there when the sun rose.
#> ... and 271 moreBởi vì mẫu đó cũng khớp với các câu bắt đầu bằng các từ như They hoặc These. Chúng ta cần đảm bảo rằng “e” là chữ cái cuối cùng trong từ, điều mà chúng ta có thể thực hiện bằng cách thêm ranh giới từ:
str_view(sentences, "^The\\b")
#> [1] │ <The> birch canoe slid on the smooth planks.
#> [6] │ <The> juice of lemons makes fine punch.
#> [7] │ <The> box was thrown beside the parked truck.
#> [8] │ <The> hogs were fed chopped corn and garbage.
#> [11] │ <The> boy was there when the sun rose.
#> [13] │ <The> source of the huge river is the clear spring.
#> ... and 250 moreCòn việc tìm tất cả các câu bắt đầu bằng đại từ thì sao?
str_view(sentences, "^She|He|It|They\\b")
#> [3] │ <It>'s easy to tell the depth of a well.
#> [15] │ <He>lp the woman get back to her feet.
#> [27] │ <He>r purse was full of useless trash.
#> [29] │ <It> snowed, rained, and hailed the same morning.
#> [63] │ <He> ran half way to the hardware store.
#> [90] │ <He> lay prone and hardly moved a limb.
#> ... and 57 moreKiểm tra nhanh kết quả cho thấy chúng ta đang có một số kết quả khớp sai. Đó là vì chúng ta quên sử dụng dấu ngoặc đơn:
str_view(sentences, "^(She|He|It|They)\\b")
#> [3] │ <It>'s easy to tell the depth of a well.
#> [29] │ <It> snowed, rained, and hailed the same morning.
#> [63] │ <He> ran half way to the hardware store.
#> [90] │ <He> lay prone and hardly moved a limb.
#> [116] │ <He> ordered peach pie with ice cream.
#> [127] │ <It> caught its hind paw in a rusty trap.
#> ... and 51 moreBạn có thể thắc mắc làm thế nào bạn có thể phát hiện lỗi như vậy nếu nó không xuất hiện trong vài kết quả khớp đầu tiên. Một kỹ thuật tốt là tạo một vài kết quả khớp dương và âm và sử dụng chúng để kiểm tra rằng mẫu của bạn hoạt động đúng như mong đợi:
pos <- c("He is a boy", "She had a good time")
neg <- c("Shells come from the sea", "Hadley said 'It's a great day'")
pattern <- "^(She|He|It|They)\\b"
str_detect(pos, pattern)
#> [1] TRUE TRUE
str_detect(neg, pattern)
#> [1] FALSE FALSEThường dễ dàng hơn nhiều để đưa ra các ví dụ dương tốt so với ví dụ âm, vì phải mất một thời gian trước khi bạn đủ giỏi với regular expression để dự đoán điểm yếu của mình. Tuy nhiên, chúng vẫn hữu ích: khi bạn làm việc với bài toán, bạn có thể dần tích lũy một bộ sưu tập các lỗi của mình, đảm bảo rằng bạn không bao giờ mắc cùng một lỗi hai lần.
15.6.2 Phép toán Boole
Hãy tưởng tượng chúng ta muốn tìm các từ chỉ chứa phụ âm. Một kỹ thuật là tạo một lớp ký tự chứa tất cả chữ cái ngoại trừ nguyên âm ([^aeiou]), sau đó cho phép nó khớp với bất kỳ số lượng chữ cái nào ([^aeiou]+), rồi buộc nó khớp toàn bộ string bằng cách neo ở đầu và cuối (^[^aeiou]+$):
str_view(words, "^[^aeiou]+$")
#> [123] │ <by>
#> [249] │ <dry>
#> [328] │ <fly>
#> [538] │ <mrs>
#> [895] │ <try>
#> [952] │ <why>Nhưng bạn có thể làm bài toán này dễ hơn một chút bằng cách đảo ngược vấn đề. Thay vì tìm các từ chỉ chứa phụ âm, chúng ta có thể tìm các từ không chứa nguyên âm nào:
str_view(words[!str_detect(words, "[aeiou]")])
#> [1] │ by
#> [2] │ dry
#> [3] │ fly
#> [4] │ mrs
#> [5] │ try
#> [6] │ whyĐây là kỹ thuật hữu ích mỗi khi bạn xử lý các tổ hợp logic, đặc biệt là những tổ hợp liên quan đến “và” hoặc “không”. Ví dụ, hãy tưởng tượng bạn muốn tìm tất cả các từ chứa cả “a” và “b”. Không có toán tử “và” tích hợp sẵn trong regular expression nên chúng ta phải giải quyết bằng cách tìm tất cả các từ chứa “a” theo sau bởi “b”, hoặc “b” theo sau bởi “a”:
str_view(words, "a.*b|b.*a")
#> [2] │ <ab>le
#> [3] │ <ab>out
#> [4] │ <ab>solute
#> [62] │ <availab>le
#> [66] │ <ba>by
#> [67] │ <ba>ck
#> ... and 24 moreĐơn giản hơn là kết hợp kết quả của hai lời gọi str_detect():
words[str_detect(words, "a") & str_detect(words, "b")]
#> [1] "able" "about" "absolute" "available" "baby" "back"
#> [7] "bad" "bag" "balance" "ball" "bank" "bar"
#> [13] "base" "basis" "bear" "beat" "beauty" "because"
#> [19] "black" "board" "boat" "break" "brilliant" "britain"
#> [25] "debate" "husband" "labour" "maybe" "probable" "table"Nếu chúng ta muốn xem liệu có từ nào chứa tất cả nguyên âm không thì sao? Nếu chúng ta làm bằng mẫu, chúng ta cần tạo 5! (120) mẫu khác nhau:
words[str_detect(words, "a.*e.*i.*o.*u")]
# ...
words[str_detect(words, "u.*o.*i.*e.*a")]Đơn giản hơn nhiều là kết hợp năm lời gọi str_detect():
words[
str_detect(words, "a") &
str_detect(words, "e") &
str_detect(words, "i") &
str_detect(words, "o") &
str_detect(words, "u")
]
#> character(0)Nói chung, nếu bạn bị mắc kẹt khi cố tạo một regexp duy nhất để giải quyết bài toán, hãy lùi lại một bước và nghĩ xem liệu bạn có thể chia bài toán thành các phần nhỏ hơn, giải quyết từng thách thức trước khi chuyển sang phần tiếp theo.
15.6.3 Tạo mẫu bằng mã
Nếu chúng ta muốn tìm tất cả sentences đề cập đến một màu sắc thì sao? Ý tưởng cơ bản rất đơn giản: chúng ta chỉ cần kết hợp phép thay thế với ranh giới từ.
str_view(sentences, "\\b(red|green|blue)\\b")
#> [2] │ Glue the sheet to the dark <blue> background.
#> [26] │ Two <blue> fish swam in the tank.
#> [92] │ A wisp of cloud hung in the <blue> air.
#> [148] │ The spot on the blotter was made by <green> ink.
#> [160] │ The sofa cushion is <red> and of light weight.
#> [174] │ The sky that morning was clear and bright <blue>.
#> ... and 20 moreNhưng khi số lượng màu tăng lên, việc xây dựng mẫu này bằng tay sẽ nhanh chóng trở nên nhàm chán. Sẽ tiện biết bao nếu chúng ta có thể lưu các màu trong một vector?
rgb <- c("red", "green", "blue")Chúng ta hoàn toàn có thể! Chúng ta chỉ cần tạo mẫu từ vector bằng str_c() và str_flatten():
str_c("\\b(", str_flatten(rgb, "|"), ")\\b")
#> [1] "\\b(red|green|blue)\\b"Chúng ta có thể làm mẫu này toàn diện hơn nếu chúng ta có một list tốt các màu. Một nơi chúng ta có thể bắt đầu là list các màu tích hợp sẵn mà R có thể sử dụng cho biểu đồ:
Nhưng trước tiên hãy loại bỏ các biến thể có đánh số:
cols <- colors()
cols <- cols[!str_detect(cols, "\\d")]
str_view(cols)
#> [1] │ white
#> [2] │ aliceblue
#> [3] │ antiquewhite
#> [4] │ aquamarine
#> [5] │ azure
#> [6] │ beige
#> ... and 137 moreSau đó chúng ta có thể biến list này thành một mẫu khổng lồ. Chúng ta sẽ không hiển thị mẫu ở đây vì nó quá lớn, nhưng bạn có thể thấy nó hoạt động:
pattern <- str_c("\\b(", str_flatten(cols, "|"), ")\\b")
str_view(sentences, pattern)
#> [2] │ Glue the sheet to the dark <blue> background.
#> [12] │ A rod is used to catch <pink> <salmon>.
#> [26] │ Two <blue> fish swam in the tank.
#> [66] │ Cars and busses stalled in <snow> drifts.
#> [92] │ A wisp of cloud hung in the <blue> air.
#> [112] │ Leaves turn <brown> and <yellow> in the fall.
#> ... and 57 moreTrong ví dụ này, cols chỉ chứa số và chữ cái nên bạn không cần lo lắng về siêu ký tự. Nhưng nói chung, bất cứ khi nào bạn tạo mẫu từ các string có sẵn, tốt nhất nên chạy chúng qua str_escape() để đảm bảo chúng khớp theo nghĩa đen.
15.6.4 Bài tập
-
Đối với mỗi thách thức sau, hãy thử giải bằng cả một regular expression duy nhất và kết hợp nhiều lời gọi
str_detect().- Tìm tất cả
wordsbắt đầu hoặc kết thúc bằngx. - Tìm tất cả
wordsbắt đầu bằng nguyên âm và kết thúc bằng phụ âm. - Có
wordsnào chứa ít nhất một trong mỗi nguyên âm khác nhau không?
- Tìm tất cả
Xây dựng các mẫu để tìm bằng chứng ủng hộ và phản bác quy tắc “i trước e ngoại trừ sau c”?
colors()chứa một số từ bổ nghĩa như “lightgray” và “darkblue”. Làm thế nào bạn có thể tự động nhận diện các từ bổ nghĩa này? (Hãy nghĩ về cách bạn có thể phát hiện rồi loại bỏ các màu đã được bổ nghĩa).Tạo một regular expression tìm bất kỳ tập dữ liệu nào trong base R. Bạn có thể lấy list các tập dữ liệu này qua một cách sử dụng đặc biệt của function
data():data(package = "datasets")$results[, "Item"]. Lưu ý rằng một số tập dữ liệu cũ là các vector riêng lẻ; chúng chứa tên “data frame” nhóm trong dấu ngoặc đơn, nên bạn sẽ cần loại bỏ phần đó.
15.7 Biểu thức chính quy ở những nơi khác
Giống như trong các function stringr và tidyr, có rất nhiều nơi khác trong R mà bạn có thể sử dụng regular expression. Các phần sau mô tả một số function hữu ích khác trong tidyverse mở rộng và base R.
15.7.1 tidyverse
Có ba nơi đặc biệt hữu ích khác mà bạn có thể muốn sử dụng regular expression
matches(pattern)sẽ chọn tất cả các biến có tên khớp với mẫu được cung cấp. Đây là function “tidyselect” mà bạn có thể sử dụng ở bất kỳ đâu trong bất kỳ function tidyverse nào chọn biến (ví dụselect(),rename_with()vàacross()).Đối số
names_patterncủapivot_longer()nhận một vector regular expression, giống nhưseparate_wider_regex(). Nó hữu ích khi trích xuất dữ liệu từ tên biến có cấu trúc phức tạpĐối số
delimtrongseparate_longer_delim()vàseparate_wider_delim()thường khớp với string cố định, nhưng bạn có thể sử dụngregex()để làm cho nó khớp với một mẫu. Điều này hữu ích, ví dụ, nếu bạn muốn khớp dấu phẩy tùy chọn theo sau bởi khoảng trắng, tức làregex(", ?").
15.7.2 base R
apropos(pattern) tìm kiếm tất cả các đối tượng có sẵn từ environment toàn cục khớp với mẫu đã cho. Điều này hữu ích nếu bạn không nhớ chính xác tên function:
apropos("replace")
#> [1] "%+replace%" "replace" "replace_na"
#> [4] "replace_theme" "replace_values" "replace_when"
#> [7] "setReplaceMethod" "str_replace" "str_replace_all"
#> [10] "str_replace_na" "theme_replace"list.files(path, pattern) liệt kê tất cả file trong path khớp với regular expression pattern. Ví dụ, bạn có thể tìm tất cả file R Markdown trong thư mục hiện tại với:
head(list.files(pattern = "\\.Rmd$"))
#> character(0)Đáng lưu ý rằng ngôn ngữ mẫu được sử dụng bởi base R hơi khác một chút so với stringr. Đó là vì stringr được xây dựng trên package stringi, và package này được xây dựng trên ICU engine, trong khi các function base R sử dụng TRE engine hoặc PCRE engine, tùy thuộc vào việc bạn có đặt perl = TRUE hay không. May mắn là những kiến thức cơ bản về regular expression đã được thiết lập vững chắc đến mức bạn sẽ gặp ít biến thể khi làm việc với các mẫu bạn học trong cuốn sách này. Bạn chỉ cần lưu ý sự khác biệt khi bạn bắt đầu dựa vào các tính năng nâng cao như phạm vi ký tự Unicode phức tạp hoặc các tính năng đặc biệt sử dụng cú pháp (?…).
15.8 Tóm tắt
Với mỗi ký tự dấu câu đều có thể mang nhiều ý nghĩa, regular expression là một trong những ngôn ngữ cô đọng nhất. Ban đầu chúng chắc chắn gây bối rối nhưng khi bạn rèn luyện mắt để đọc chúng và não bộ để hiểu chúng, bạn sẽ mở khóa một kỹ năng mạnh mẽ có thể sử dụng trong R và nhiều nơi khác.
Trong chương này, bạn đã bắt đầu hành trình để trở thành bậc thầy regular expression bằng cách học các function stringr hữu ích nhất và các thành phần quan trọng nhất của ngôn ngữ regular expression. Và vẫn còn rất nhiều tài nguyên để học thêm.
Một nơi tốt để bắt đầu là vignette("regular-expressions", package = "stringr"): nó ghi chép đầy đủ các cú pháp được hỗ trợ bởi stringr. Một tài liệu tham khảo hữu ích khác là https://www.regular-expressions.info/. Nó không dành riêng cho R, nhưng bạn có thể sử dụng nó để tìm hiểu về các tính năng nâng cao nhất của regex và cách chúng hoạt động đằng sau hậu trường.
Cũng tốt khi biết rằng stringr được xây dựng trên package stringi của Marek Gagolewski. Nếu bạn gặp khó khăn khi tìm một function thực hiện những gì bạn cần trong stringr, đừng ngại tìm kiếm trong stringi. Bạn sẽ thấy stringi rất dễ tiếp cận vì nó tuân theo nhiều quy ước giống như stringr.
Trong chương tiếp theo, chúng ta sẽ nói về một cấu trúc dữ liệu liên quan chặt chẽ đến string: factor (factor). Nhân tố được sử dụng để biểu diễn dữ liệu phân loại trong R, tức là dữ liệu với một tập hợp cố định và đã biết các giá trị có thể được xác định bởi một vector string.
Bạn có thể phát âm với g cứng (reg-x) hoặc g mềm (rej-x).↩︎
Bạn sẽ học cách thoát các ý nghĩa đặc biệt này trong Phần 15.4.1.↩︎
Chính xác hơn, bất kỳ ký tự nào ngoại trừ
\n.↩︎Điều này cho chúng ta tỷ lệ tên chứa “x”; nếu bạn muốn tỷ lệ em bé có tên chứa x, bạn sẽ cần thực hiện trung bình có trọng số.↩︎
Chúng tôi ước gì có thể trấn an bạn rằng bạn sẽ không bao giờ gặp thứ gì kỳ lạ như thế này trong thực tế, nhưng đáng tiếc là trong suốt sự nghiệp bạn có thể sẽ gặp những thứ kỳ lạ hơn nhiều!↩︎
Tập hợp đầy đủ các siêu ký tự là
.^$\|*+?{}[]()↩︎Hãy nhớ rằng, để tạo regular expression chứa
\dhoặc\s, bạn sẽ cần thoát\cho string, nên bạn sẽ gõ"\\d"hoặc"\\s".↩︎Chủ yếu vì chúng ta chưa bao giờ thảo luận về ma trận trong cuốn sách này!↩︎
comments = TRUEđặc biệt hiệu quả khi kết hợp với string thô, như chúng ta sử dụng ở đây.↩︎