17 Ngày và giờ
17.1 Giới thiệu
Chương này sẽ hướng dẫn bạn cách làm việc với ngày và giờ trong R. Thoạt nhìn, ngày và giờ có vẻ đơn giản. Bạn sử dụng chúng row ngày trong cuộc sống, và chúng dường như không gây ra nhiều rắc rối. Tuy nhiên, bạn càng tìm hiểu về ngày và giờ, mọi thứ càng trở nên phức tạp hơn!
Để khởi động, hãy nghĩ xem một năm có bao nhiêu ngày, và một ngày có bao nhiêu giờ. Bạn có thể nhớ rằng hầu hết các năm có 365 ngày, nhưng năm nhuận có 366. Bạn có biết quy tắc đầy đủ để xác định một năm có phải là năm nhuận không1? Số giờ trong một ngày thì ít rõ ràng hơn: hầu hết các ngày có 24 giờ, nhưng ở những nơi sử dụng giờ mùa hè (DST), mỗi năm có một ngày chỉ có 23 giờ và một ngày có 25 giờ.
Ngày và giờ khó xử lý vì chúng phải dung hòa hai hiện tượng vật lý (sự tự quay của Trái Đất và quỹ đạo quay quanh Mặt Trời) với row loạt hiện tượng địa chính trị bao gồm tháng, múi giờ (time zone), và giờ mùa hè (DST). Chương này sẽ không dạy bạn mọi chi tiết cuối cùng về ngày và giờ, nhưng sẽ cung cấp cho bạn nền tảng vững chắc về các kỹ năng thực tế giúp bạn giải quyết các thách thức phân tích dữ liệu thường gặp.
Chúng ta sẽ bắt đầu bằng cách hướng dẫn bạn tạo date-time từ nhiều đầu vào khác nhau, và sau khi bạn đã có một date-time, cách trích xuất các thành phần như năm, tháng, và ngày. Tiếp theo, chúng ta sẽ đi sâu vào theme phức tạp là làm việc với khoảng thời gian (time span), có nhiều dạng khác nhau tùy thuộc vào mục đích của bạn. Chúng ta sẽ kết thúc với một cuộc thảo luận ngắn về các thách thức bổ sung do múi giờ gây ra.
17.1.1 Điều kiện tiên quyết
Chương này sẽ tập trung vào package lubridate, giúp bạn làm việc với ngày và giờ trong R dễ dàng hơn. Kể từ phiên bản tidyverse mới nhất, lubridate là một phần của tidyverse cốt lõi. Chúng ta cũng sẽ cần nycflights13 để có dữ liệu thực hành.
17.2 Tạo date/time
Có ba kiểu dữ liệu date/time tham chiếu đến một thời điểm cụ thể:
Một date (ngày). Tibble hiển thị kiểu này là
<date>.Một time (giờ) trong ngày. Tibble hiển thị kiểu này là
<time>.Một date-time là ngày kết hợp với giờ: nó xác định duy nhất một thời điểm (thường chính xác đến giây). Tibble hiển thị kiểu này là
<dttm>. base R gọi chúng là POSIXct, nhưng cái tên đó không dễ nhớ cho lắm.
Trong chương này chúng ta sẽ tập trung vào date và date-time vì R không có lớp (class) riêng để lưu trữ time. Nếu bạn cần, bạn có thể sử dụng package hms.
Bạn nên luôn sử dụng kiểu dữ liệu đơn giản nhất phù hợp với nhu cầu của mình. Điều đó có nghĩa là nếu bạn có thể dùng date thay vì date-time, bạn nên làm vậy. Date-time phức tạp hơn đáng kể vì cần xử lý múi giờ, điều mà chúng ta sẽ quay lại ở cuối chương.
Để lấy ngày hoặc date-time hiện tại, bạn có thể dùng today() hoặc now():
Ngoài ra, các phần tiếp theo mô tả bốn cách bạn thường tạo date/time:
- Khi đọc file bằng readr.
- Từ string (string).
- Từ các thành phần date-time riêng lẻ.
- Từ một đối tượng date/time đã có.
17.2.1 Khi nhập dữ liệu
Nếu file CSV của bạn chứa date hoặc date-time theo chuẩn ISO8601, bạn không cần làm gì thêm; readr sẽ tự động nhận diện:
csv <- "
date,datetime
2022-01-02,2022-01-02 05:12
"
read_csv(csv)
#> Warning: The `file` argument of `read_csv()` should use `I()` for literal data as of
#> readr 2.2.0.
#>
#> # Bad (for example):
#> read_csv("x,y\n1,2")
#>
#> # Good:
#> read_csv(I("x,y\n1,2"))
#> # A tibble: 1 × 2
#> date datetime
#> <date> <dttm>
#> 1 2022-01-02 2022-01-02 05:12:00Nếu bạn chưa nghe về ISO8601, đây là một tiêu chuẩn quốc tế2 để viết ngày trong đó các thành phần của ngày được sắp xếp từ lớn nhất đến nhỏ nhất, ngăn cách bởi -. Ví dụ, trong ISO8601 ngày 3 tháng 5 năm 2022 được viết là 2022-05-03. Ngày ISO8601 cũng có thể bao gồm giờ, trong đó giờ, phút, và giây được ngăn cách bởi :, và thành phần ngày và giờ được ngăn cách bởi T hoặc dấu cách. Ví dụ, bạn có thể viết 4:26 chiều ngày 3 tháng 5 năm 2022 là 2022-05-03 16:26 hoặc 2022-05-03T16:26.
Đối với các định dạng date-time khác, bạn sẽ cần sử dụng col_types cùng với col_date() hoặc col_datetime() kèm theo định dạng date-time. Định dạng date-time được readr sử dụng là một tiêu chuẩn phổ biến trong nhiều ngôn ngữ lập trình, mô tả thành phần ngày bằng ký tự % theo sau bởi một ký tự đơn. Ví dụ, %Y-%m-%d chỉ định một ngày gồm năm, -, tháng (dạng số) -, ngày. Bảng 17.1 liệt kê tất cả các tùy chọn.
| Loại | Mã | Ý nghĩa | Ví dụ |
|---|---|---|---|
| Năm | %Y |
Năm 4 chữ số | 2021 |
%y |
Năm 2 chữ số | 21 | |
| Tháng | %m |
Số | 2 |
%b |
Tên viết tắt | Feb | |
%B |
Tên đầy đủ | February | |
| Ngày | %d |
Một hoặc hai chữ số | 2 |
%e |
Hai chữ số | 02 | |
| Giờ | %H |
Giờ dạng 24 giờ | 13 |
%I |
Giờ dạng 12 giờ | 1 | |
%p |
AM/PM | pm | |
%M |
Phút | 35 | |
%S |
Giây | 45 | |
%OS |
Giây với phần thập phân | 45.35 | |
%Z |
Tên múi giờ | America/Chicago | |
%z |
Độ lệch so với UTC | +0800 | |
| Khác | %. |
Bỏ qua một ký tự không phải số | : |
%* |
Bỏ qua bất kỳ số ký tự không phải số |
Và đoạn mã này cho thấy một vài tùy chọn áp dụng cho một ngày rất mơ hồ:
csv <- "
date
01/02/15
"
read_csv(csv, col_types = cols(date = col_date("%m/%d/%y")))
#> # A tibble: 1 × 1
#> date
#> <date>
#> 1 2015-01-02
read_csv(csv, col_types = cols(date = col_date("%d/%m/%y")))
#> # A tibble: 1 × 1
#> date
#> <date>
#> 1 2015-02-01
read_csv(csv, col_types = cols(date = col_date("%y/%m/%d")))
#> # A tibble: 1 × 1
#> date
#> <date>
#> 1 2001-02-15Lưu ý rằng dù bạn chỉ định định dạng ngày theo cách nào, ngày luôn được hiển thị theo cùng một cách khi đã nằm trong R.
Nếu bạn sử dụng %b hoặc %B và làm việc với ngày không phải tiếng Anh, bạn cũng cần cung cấp locale(). Xem list các ngôn ngữ được hỗ trợ sẵn trong date_names_langs(), hoặc tạo ngôn ngữ riêng với date_names(),
17.2.2 Từ string
Ngôn ngữ đặc tả định dạng date-time rất mạnh mẽ, nhưng đòi hỏi phân tích cẩn thận định dạng ngày. Một cách tiếp cận thay thế là sử dụng các function hỗ trợ của lubridate, tự động xác định định dạng khi bạn chỉ định thứ tự các thành phần. Để sử dụng chúng, hãy xác định thứ tự xuất hiện của năm, tháng, và ngày trong dữ liệu ngày của bạn, rồi sắp xếp “y”, “m”, và “d” theo cùng thứ tự đó. Kết quả cho bạn tên của function lubridate sẽ phân tích ngày của bạn. Ví dụ:
ymd() và các function tương tự tạo ra date. Để tạo date-time, thêm dấu gạch dưới và một hoặc nhiều ký tự “h”, “m”, “s” vào tên function phân tích:
Bạn cũng có thể ép tạo date-time từ date bằng cách cung cấp múi giờ:
ymd("2017-01-31", tz = "UTC")
#> [1] "2017-01-31 UTC"Ở đây tôi dùng múi giờ UTC3, bạn có thể cũng biết nó với tên GMT, hay Giờ Trung bình Greenwich, là giờ tại kinh tuyến 0°4 . Múi giờ này không sử dụng giờ mùa hè, giúp việc tính toán dễ dàng hơn một chút .
17.2.3 Từ các thành phần riêng lẻ
Thay vì một string duy nhất, đôi khi bạn sẽ có các thành phần riêng lẻ của date-time nằm rải rác trên nhiều column. Đây là những gì chúng ta có trong dữ liệu flights:
flights |>
select(year, month, day, hour, minute)
#> # A tibble: 336,776 × 5
#> year month day hour minute
#> <int> <int> <int> <dbl> <dbl>
#> 1 2013 1 1 5 15
#> 2 2013 1 1 5 29
#> 3 2013 1 1 5 40
#> 4 2013 1 1 5 45
#> 5 2013 1 1 6 0
#> 6 2013 1 1 5 58
#> # ℹ 336,770 more rowsĐể tạo date/time từ dạng đầu vào này, dùng make_date() cho date, hoặc make_datetime() cho date-time:
flights |>
select(year, month, day, hour, minute) |>
mutate(departure = make_datetime(year, month, day, hour, minute))
#> # A tibble: 336,776 × 6
#> year month day hour minute departure
#> <int> <int> <int> <dbl> <dbl> <dttm>
#> 1 2013 1 1 5 15 2013-01-01 05:15:00
#> 2 2013 1 1 5 29 2013-01-01 05:29:00
#> 3 2013 1 1 5 40 2013-01-01 05:40:00
#> 4 2013 1 1 5 45 2013-01-01 05:45:00
#> 5 2013 1 1 6 0 2013-01-01 06:00:00
#> 6 2013 1 1 5 58 2013-01-01 05:58:00
#> # ℹ 336,770 more rowsHãy làm tương tự cho mỗi column thời gian trong bốn column thời gian của flights. Các giá trị thời gian được biểu diễn ở định dạng hơi đặc biệt, nên chúng ta dùng phép toán chia lấy phần nguyên và chia lấy dư để tách thành phần giờ và phút. Sau khi tạo xong các biến date-time, chúng ta tập trung vào các biến mà ta sẽ khám phá trong phần còn lại của chương.
make_datetime_100 <- function(year, month, day, time) {
make_datetime(year, month, day, time %/% 100, time %% 100)
}
flights_dt <- flights |>
filter(!is.na(dep_time), !is.na(arr_time)) |>
mutate(
dep_time = make_datetime_100(year, month, day, dep_time),
arr_time = make_datetime_100(year, month, day, arr_time),
sched_dep_time = make_datetime_100(year, month, day, sched_dep_time),
sched_arr_time = make_datetime_100(year, month, day, sched_arr_time)
) |>
select(origin, dest, ends_with("delay"), ends_with("time"))
flights_dt
#> # A tibble: 328,063 × 9
#> origin dest dep_delay arr_delay dep_time sched_dep_time
#> <chr> <chr> <dbl> <dbl> <dttm> <dttm>
#> 1 EWR IAH 2 11 2013-01-01 05:17:00 2013-01-01 05:15:00
#> 2 LGA IAH 4 20 2013-01-01 05:33:00 2013-01-01 05:29:00
#> 3 JFK MIA 2 33 2013-01-01 05:42:00 2013-01-01 05:40:00
#> 4 JFK BQN -1 -18 2013-01-01 05:44:00 2013-01-01 05:45:00
#> 5 LGA ATL -6 -25 2013-01-01 05:54:00 2013-01-01 06:00:00
#> 6 EWR ORD -4 12 2013-01-01 05:54:00 2013-01-01 05:58:00
#> # ℹ 328,057 more rows
#> # ℹ 3 more variables: arr_time <dttm>, sched_arr_time <dttm>, …Với dữ liệu này, chúng ta có thể visualization phân phối thời gian khởi hành trong suốt cả năm:
flights_dt |>
ggplot(aes(x = dep_time)) +
geom_freqpoly(binwidth = 86400) # 86400 giây = 1 ngày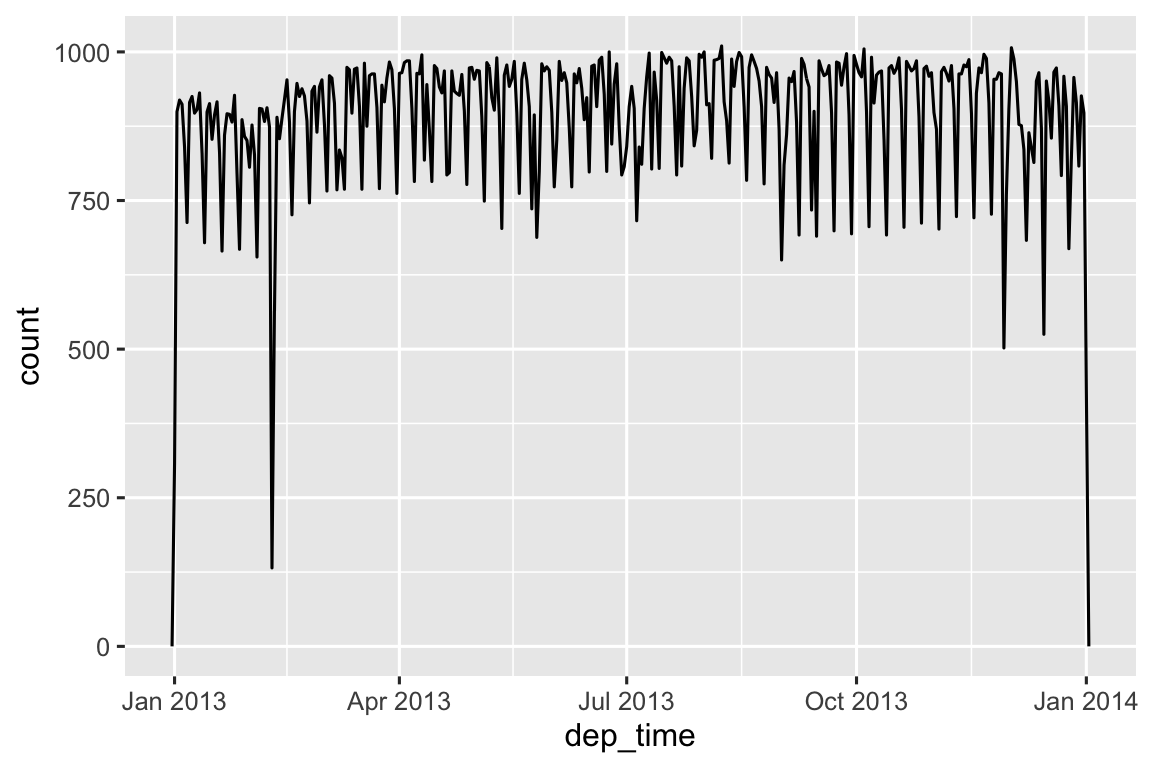
Hoặc trong một ngày đơn lẻ:
flights_dt |>
filter(dep_time < ymd(20130102)) |>
ggplot(aes(x = dep_time)) +
geom_freqpoly(binwidth = 600) # 600 giây = 10 phút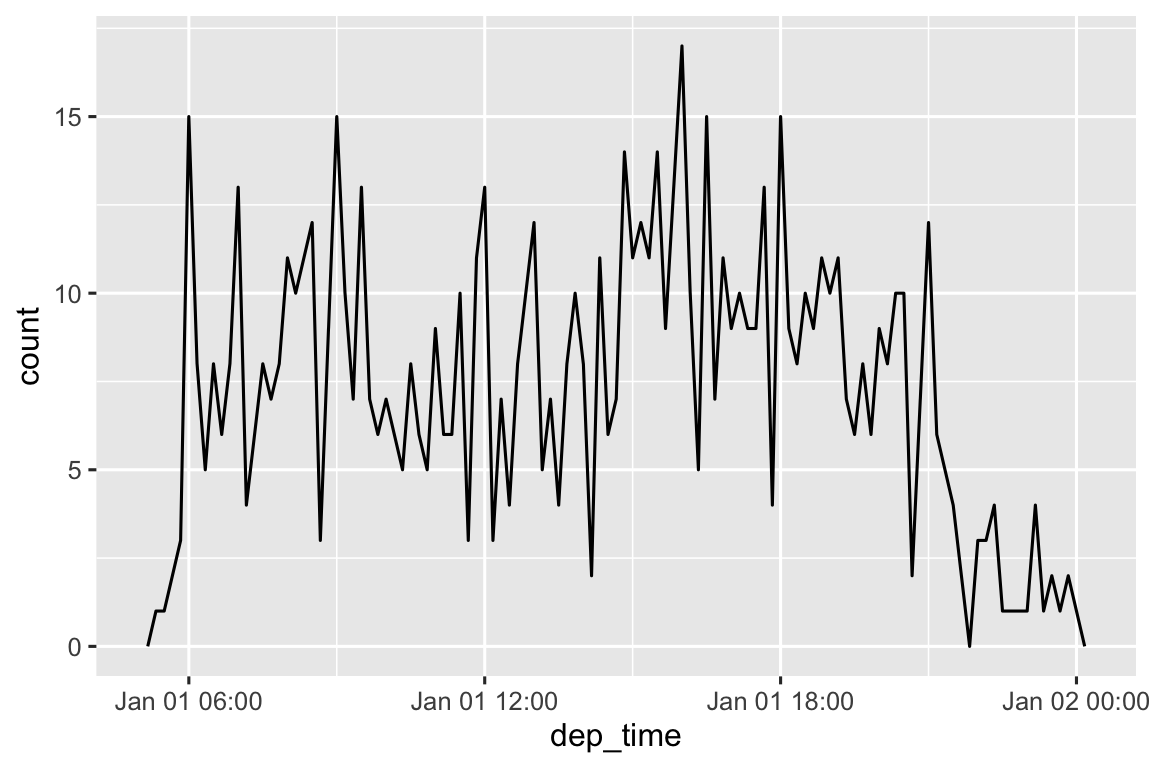
Lưu ý rằng khi bạn sử dụng date-time trong ngữ cảnh số (như trong biểu đồ tần suất), 1 có nghĩa là 1 giây, nên binwidth bằng 86400 có nghĩa là một ngày. Đối với date, 1 có nghĩa là 1 ngày.
17.2.4 Từ các kiểu khác
Bạn có thể muốn chuyển đổi giữa date-time và date. Đó là công việc của as_datetime() và as_date():
as_datetime(today())
#> [1] "2026-04-09 UTC"
as_date(now())
#> [1] "2026-04-09"Đôi khi bạn sẽ nhận được date/time dưới dạng độ lệch số từ “Kỷ nguyên Unix” (Unix Epoch), 1970-01-01. Nếu độ lệch tính bằng giây, dùng as_datetime(); nếu tính bằng ngày, dùng as_date().
as_datetime(60 * 60 * 10)
#> [1] "1970-01-01 10:00:00 UTC"
as_date(365 * 10 + 2)
#> [1] "1980-01-01"17.2.5 Bài tập
-
Điều gì xảy ra nếu bạn phân tích một string chứa ngày không hợp lệ?
Đối số
tzonecủatoday()làm gì? Tại sao nó quan trọng?-
Với mỗi date-time sau đây, hãy cho thấy cách bạn phân tích nó bằng đặc tả column readr và function lubridate.
d1 <- "January 1, 2010" d2 <- "2015-Mar-07" d3 <- "06-Jun-2017" d4 <- c("August 19 (2015)", "July 1 (2015)") d5 <- "12/30/14" # Dec 30, 2014 t1 <- "1705" t2 <- "11:15:10.12 PM"
17.3 Các thành phần date-time
Bây giờ bạn đã biết cách đưa dữ liệu date-time vào các cấu trúc dữ liệu date-time của R, hãy khám phá những gì bạn có thể làm với chúng. Phần này sẽ tập trung vào các function truy cập (accessor function) cho phép bạn lấy và thiết lập các thành phần riêng lẻ. Phần tiếp theo sẽ xem xét cách phép toán số học hoạt động với date-time.
17.3.1 Trích xuất thành phần
Bạn có thể trích xuất các phần riêng lẻ của date bằng các function truy cập year(), month(), mday() (ngày trong tháng), yday() (ngày trong năm), wday() (ngày trong tuần), hour(), minute(), và second(). Về cơ bản, chúng là các function ngược lại của make_datetime().
Đối với month() và wday(), bạn có thể đặt label = TRUE để trả về tên viết tắt của tháng hoặc ngày trong tuần. Đặt abbr = FALSE để trả về tên đầy đủ.
Chúng ta có thể dùng wday() để thấy rằng có nhiều chuyến bay khởi hành trong tuần hơn vào cuối tuần:
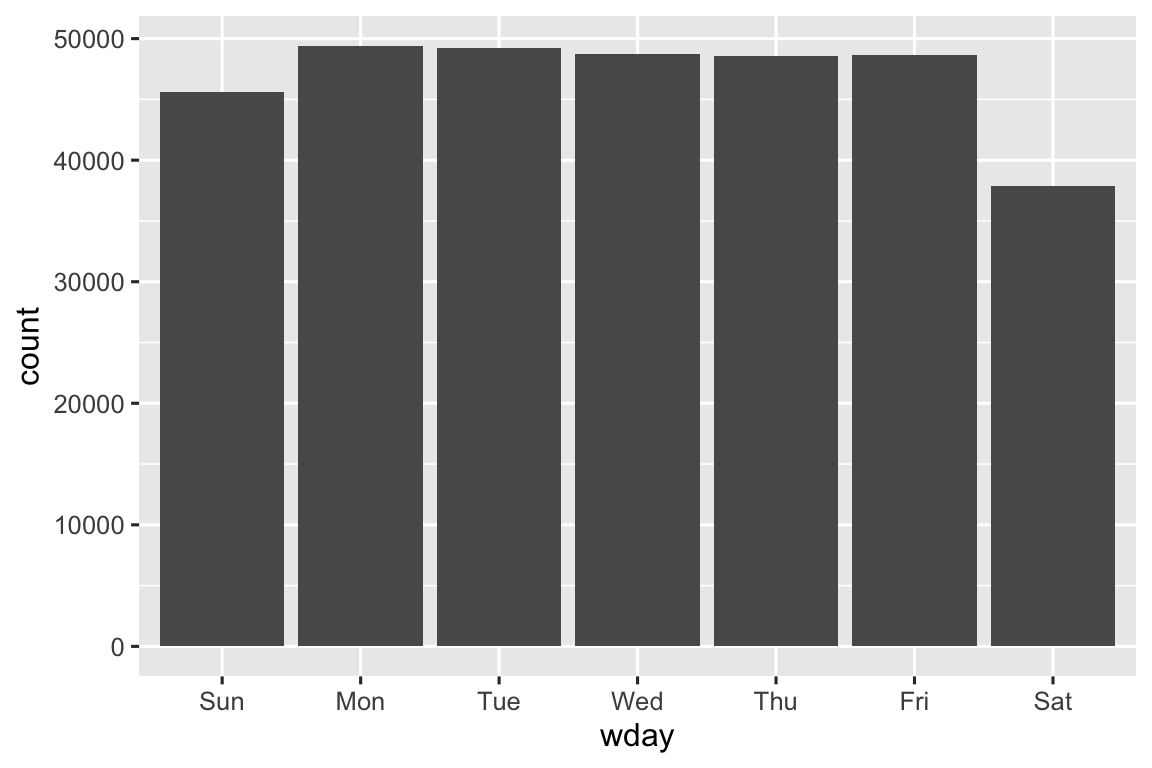
Chúng ta cũng có thể xem độ trễ khởi hành trung bình theo từng phút trong giờ. Có một mẫu hình thú vị: các chuyến bay khởi hành trong phút 20-30 và 50-60 có độ trễ thấp hơn nhiều so với phần còn lại của giờ!
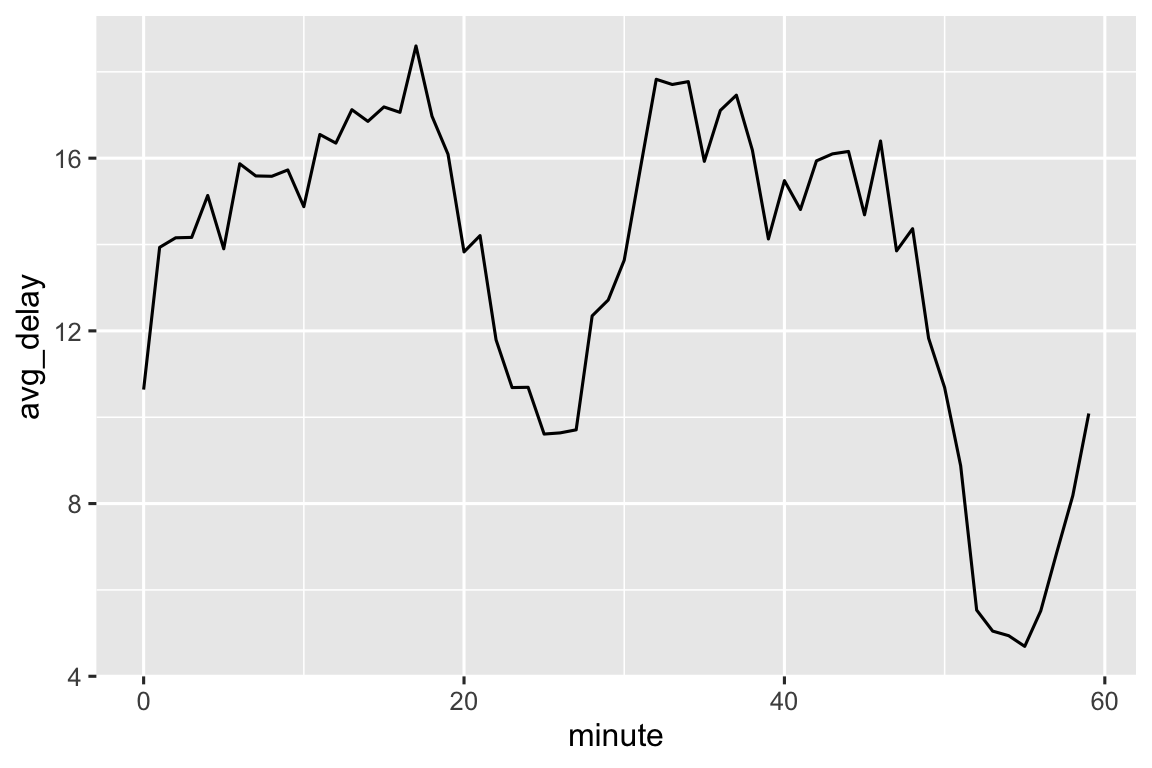
Thú vị là nếu chúng ta nhìn vào thời gian khởi hành theo lịch, chúng ta không thấy mẫu hình rõ rệt như vậy:
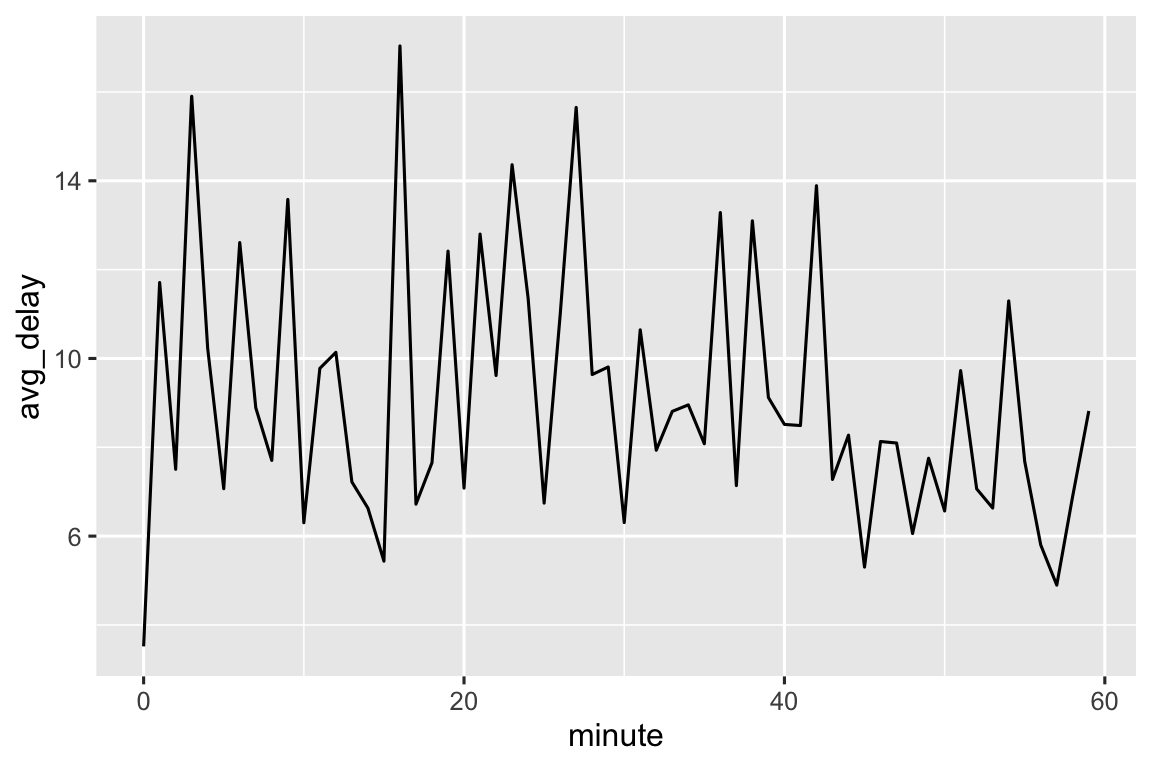
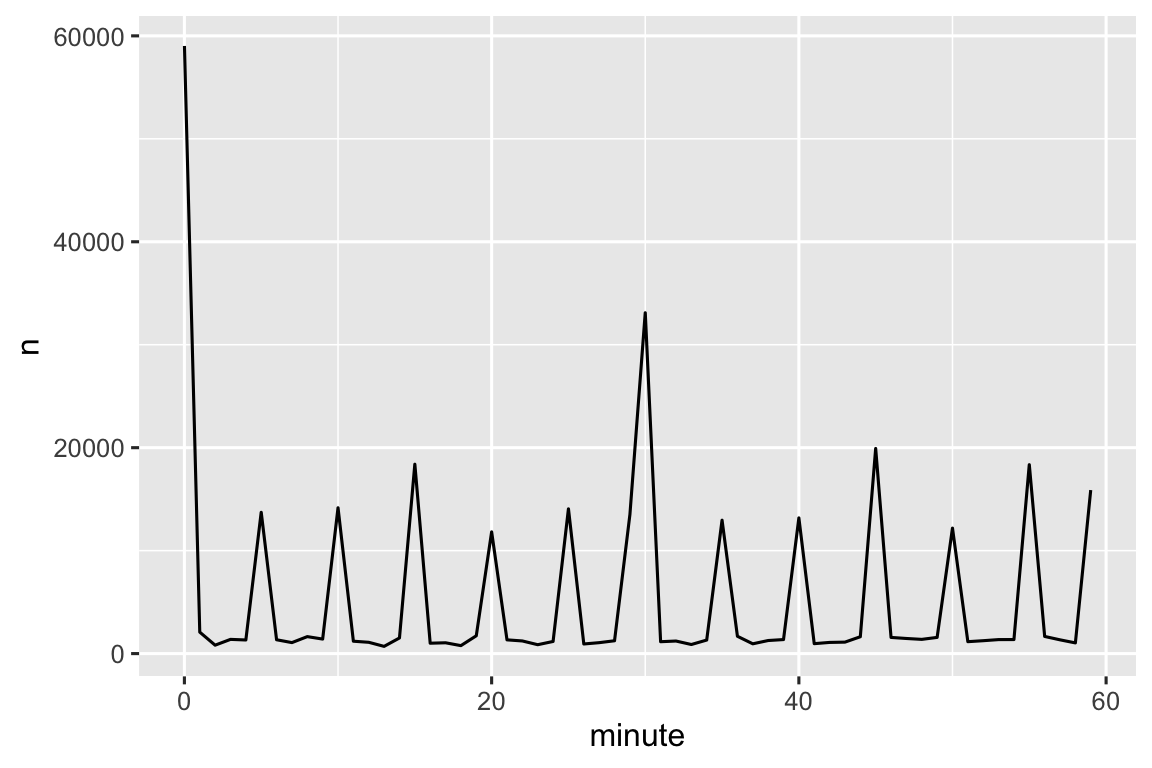
Vậy tại sao chúng ta thấy mẫu hình đó với thời gian khởi hành thực tế? À, giống như phần lớn dữ liệu được con người thu thập, có xu hướng thiên lệch mạnh về các chuyến bay khởi hành vào thời điểm “đẹp”, như Hình 17.1 cho thấy. Hãy luôn cảnh giác với loại mẫu hình này mỗi khi bạn làm việc với dữ liệu liên quan đến phán đoán của con người!
17.3.2 Làm tròn
Một cách tiếp cận thay thế để vẽ biểu đồ các thành phần riêng lẻ là làm tròn ngày đến đơn vị thời gian gần nhất, với floor_date(), round_date(), và ceiling_date(). Mỗi function nhận một vector các ngày cần điều chỉnh và tên đơn vị thời gian để làm tròn xuống (floor), làm tròn lên (ceiling), hoặc làm tròn đến. Ví dụ, điều này cho phép chúng ta vẽ số chuyến bay mỗi tuần:
flights_dt |>
count(week = floor_date(dep_time, "week")) |>
ggplot(aes(x = week, y = n)) +
geom_line() +
geom_point()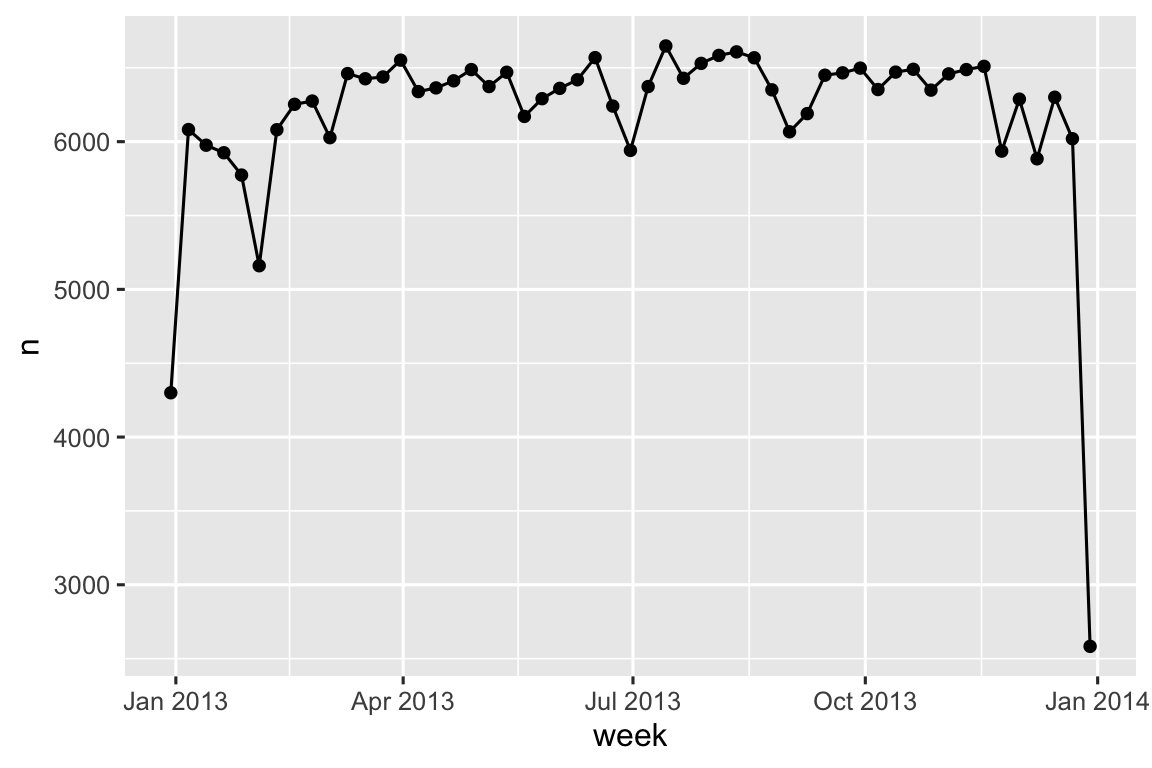
Bạn có thể sử dụng làm tròn để hiển thị phân phối chuyến bay trong suốt một ngày bằng cách tính chênh lệch giữa dep_time và thời điểm sớm nhất của ngày đó:
flights_dt |>
mutate(dep_hour = dep_time - floor_date(dep_time, "day")) |>
ggplot(aes(x = dep_hour)) +
geom_freqpoly(binwidth = 60 * 30)
#> Don't know how to automatically pick scale for object of type <difftime>.
#> Defaulting to continuous.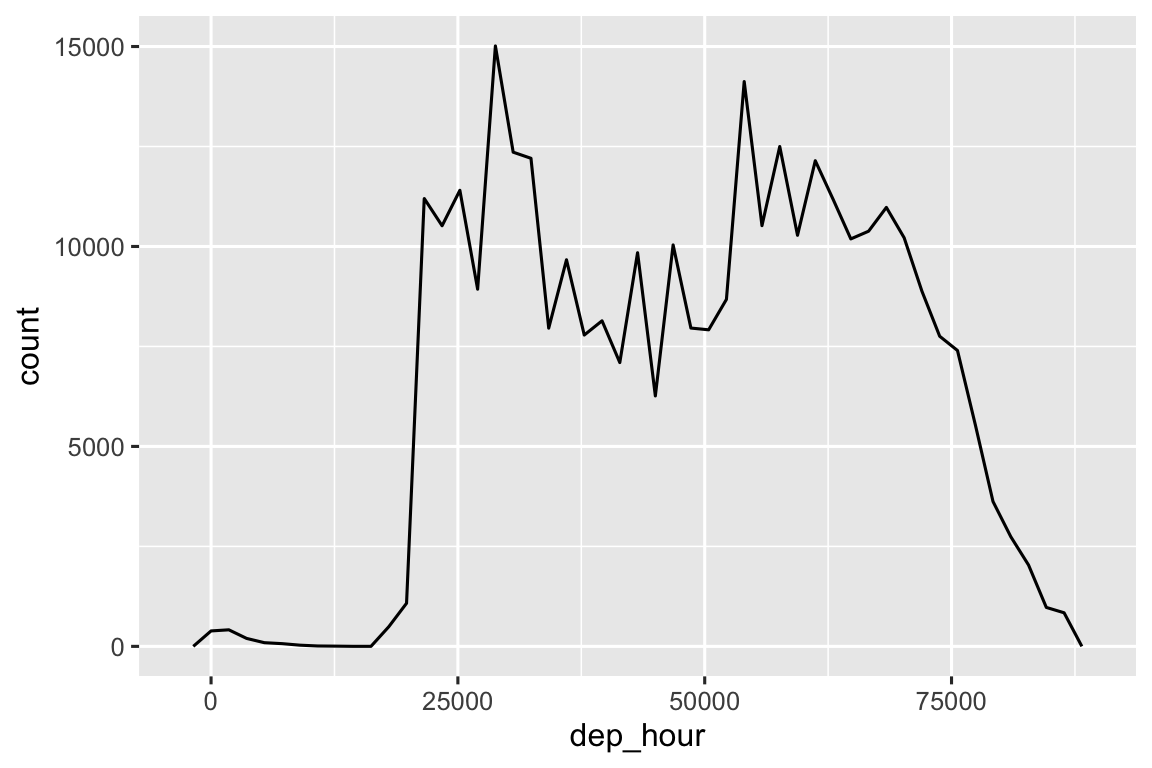
Tính chênh lệch giữa một cặp date-time cho ra một difftime (chi tiết hơn ở Phần 17.4.3). Chúng ta có thể chuyển đổi nó thành đối tượng hms để có trục x hữu ích hơn:
flights_dt |>
mutate(dep_hour = hms::as_hms(dep_time - floor_date(dep_time, "day"))) |>
ggplot(aes(x = dep_hour)) +
geom_freqpoly(binwidth = 60 * 30)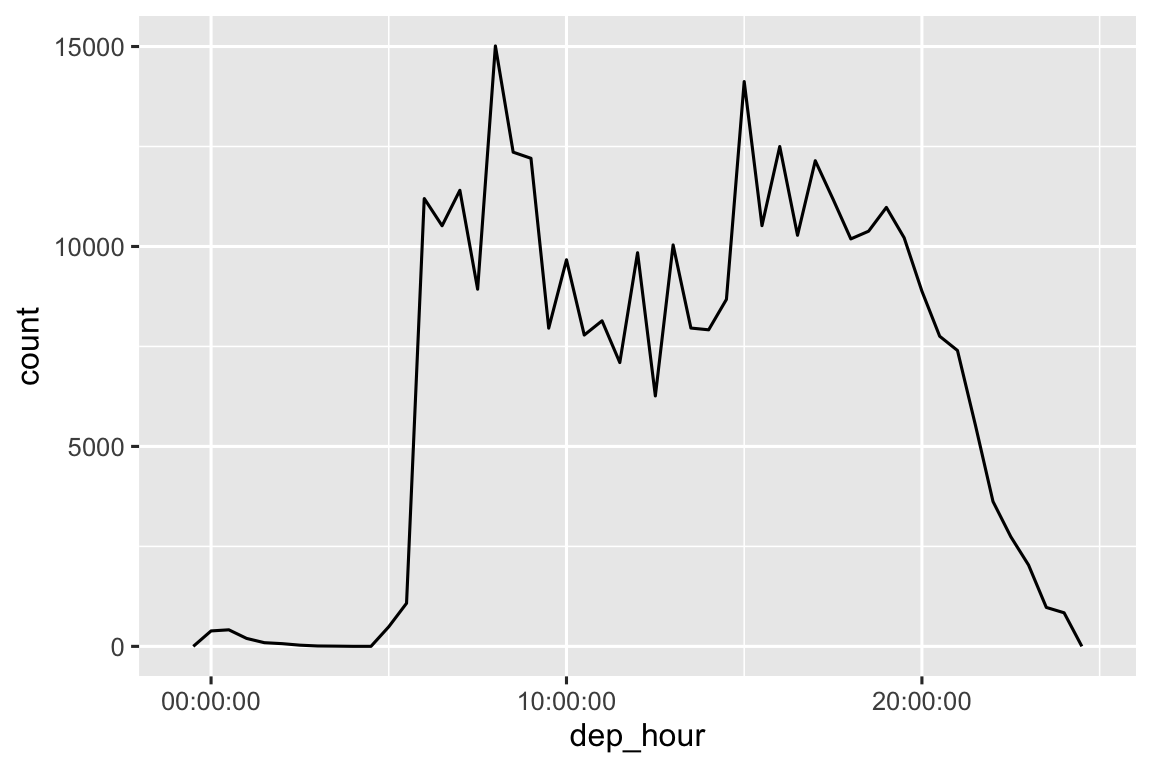
17.3.3 Chỉnh sửa thành phần
Bạn cũng có thể dùng mỗi function truy cập để chỉnh sửa các thành phần của date/time. Điều này không thường gặp trong phân tích dữ liệu, nhưng có thể hữu ích khi làm sạch dữ liệu có ngày rõ ràng không chính xác.
Ngoài ra, thay vì chỉnh sửa biến hiện có, bạn có thể tạo date-time mới với update(). Function này cũng cho phép bạn thiết lập nhiều giá trị cùng lúc:
update(datetime, year = 2030, month = 2, mday = 2, hour = 2)
#> [1] "2030-02-02 02:34:56 UTC"Nếu giá trị quá lớn, chúng sẽ tự động chuyển sang:
17.3.4 Bài tập
Phân phối thời gian bay trong ngày thay đổi như thế nào theo thời gian trong năm?
So sánh
dep_time,sched_dep_timevàdep_delay. Chúng có nhất quán không? Giải thích phát hiện của bạn.So sánh
air_timevới khoảng thời gian giữa khởi hành và đến nơi. Giải thích phát hiện của bạn. (Gợi ý: xem xét vị trí của sân bay.)Thời gian trễ trung bình thay đổi như thế nào trong suốt một ngày? Bạn nên dùng
dep_timehaysched_dep_time? Tại sao?Bạn nên khởi hành vào ngày nào trong tuần nếu muốn giảm thiểu khả năng bị trễ?
Điều gì làm cho phân phối của
diamonds$caratvàflights$sched_dep_timegiống nhau?Xác nhận giả thuyết của chúng ta rằng các chuyến bay khởi hành sớm trong phút 20-30 và 50-60 là do các chuyến bay theo lịch khởi hành sớm. Gợi ý: tạo một biến nhị phân cho biết chuyến bay có bị trễ hay không.
17.4 Khoảng thời gian
Tiếp theo bạn sẽ học cách phép toán số học với ngày hoạt động, bao gồm phép trừ, phép cộng, và phép chia. Trong quá trình đó, bạn sẽ tìm hiểu về ba lớp quan trọng đại diện cho khoảng thời gian (time span):
- Duration (khoảng kéo dài), đại diện cho một số giây chính xác.
- Period (chu kỳ), đại diện cho các đơn vị thời gian con người như tuần và tháng.
- Interval (khoảng), đại diện cho một điểm bắt đầu và kết thúc.
Làm sao chọn giữa duration, period, và interval? Như thường lệ, hãy chọn cấu trúc dữ liệu đơn giản nhất giải quyết được vấn đề của bạn. Nếu bạn chỉ quan tâm đến thời gian vật lý, dùng duration; nếu bạn cần cộng thời gian theo cách con người, dùng period; nếu bạn cần tìm xem một khoảng thời gian dài bao nhiêu theo đơn vị con người, dùng interval.
17.4.1 Duration
Trong R, khi bạn trừ hai date, bạn nhận được một đối tượng difftime:
Một đối tượng lớp difftime ghi lại khoảng thời gian tính bằng giây, phút, giờ, ngày, hoặc tuần. Sự mơ hồ này có thể khiến difftime hơi khó làm việc, nên lubridate cung cấp một lựa chọn thay thế luôn sử dụng giây: duration (khoảng kéo dài).
as.duration(h_age)
#> [1] "1466985600s (~46.49 years)"Duration đi kèm với một loạt function khởi tạo tiện lợi:
dseconds(15)
#> [1] "15s"
dminutes(10)
#> [1] "600s (~10 minutes)"
dhours(c(12, 24))
#> [1] "43200s (~12 hours)" "86400s (~1 days)"
ddays(0:5)
#> [1] "0s" "86400s (~1 days)" "172800s (~2 days)"
#> [4] "259200s (~3 days)" "345600s (~4 days)" "432000s (~5 days)"
dweeks(3)
#> [1] "1814400s (~3 weeks)"
dyears(1)
#> [1] "31557600s (~1 years)"Duration luôn ghi lại khoảng thời gian bằng giây. Các đơn vị lớn hơn được tạo bằng cách chuyển đổi phút, giờ, ngày, tuần, và năm sang giây: 60 giây trong một phút, 60 phút trong một giờ, 24 giờ trong một ngày, và 7 ngày trong một tuần. Các đơn vị thời gian lớn hơn thì phức tạp hơn. Một năm sử dụng số ngày “trung bình” trong một năm, tức là 365,25. Không có cách nào chuyển đổi tháng sang duration, vì có quá nhiều biến thiên.
Bạn có thể cộng và nhân các duration:
Bạn có thể cộng và trừ duration với ngày:
Tuy nhiên, vì duration đại diện cho một số giây chính xác, đôi khi bạn có thể nhận được kết quả bất ngờ:
Tại sao một ngày sau 1 giờ sáng ngày 8 tháng 3 lại là 2 giờ sáng ngày 9 tháng 3? Nếu bạn nhìn kỹ ngày, bạn cũng có thể nhận thấy múi giờ đã thay đổi. Ngày 8 tháng 3 chỉ có 23 giờ vì đó là khi giờ mùa hè (DST) bắt đầu, nên nếu chúng ta cộng thêm đúng một ngày tính bằng giây, chúng ta sẽ kết thúc ở một thời điểm khác.
17.4.2 Period
Để giải quyết vấn đề này, lubridate cung cấp period (chu kỳ). Period là khoảng thời gian nhưng không có độ dài cố định tính bằng giây, thay vào đó chúng hoạt động với thời gian “con người”, như ngày và tháng. Điều đó cho phép chúng hoạt động theo cách trực quan hơn:
one_am
#> [1] "2026-03-08 01:00:00 EST"
one_am + days(1)
#> [1] "2026-03-09 01:00:00 EDT"Giống như duration, period có thể được tạo bằng một số function khởi tạo thân thiện.
Bạn có thể cộng và nhân các period:
Và tất nhiên, cộng chúng vào ngày. So với duration, period có khả năng cao hơn sẽ làm đúng như bạn mong đợi:
Hãy dùng period để sửa một điểm bất thường liên quan đến ngày bay của chúng ta. Một số máy bay dường như đã đến đích trước khi chúng khởi hành từ thành phố New York.
flights_dt |>
filter(arr_time < dep_time)
#> # A tibble: 10,633 × 9
#> origin dest dep_delay arr_delay dep_time sched_dep_time
#> <chr> <chr> <dbl> <dbl> <dttm> <dttm>
#> 1 EWR BQN 9 -4 2013-01-01 19:29:00 2013-01-01 19:20:00
#> 2 JFK DFW 59 NA 2013-01-01 19:39:00 2013-01-01 18:40:00
#> 3 EWR TPA -2 9 2013-01-01 20:58:00 2013-01-01 21:00:00
#> 4 EWR SJU -6 -12 2013-01-01 21:02:00 2013-01-01 21:08:00
#> 5 EWR SFO 11 -14 2013-01-01 21:08:00 2013-01-01 20:57:00
#> 6 LGA FLL -10 -2 2013-01-01 21:20:00 2013-01-01 21:30:00
#> # ℹ 10,627 more rows
#> # ℹ 3 more variables: arr_time <dttm>, sched_arr_time <dttm>, …Đây là các chuyến bay qua đêm. Chúng ta đã dùng cùng thông tin ngày cho cả thời gian khởi hành và đến nơi, nhưng các chuyến bay này thực tế đến vào ngày hôm sau. Chúng ta có thể sửa điều này bằng cách cộng days(1) vào thời gian đến của mỗi chuyến bay qua đêm.
Bây giờ tất cả chuyến bay của chúng ta đều tuân theo các định luật vật lý.
flights_dt |>
filter(arr_time < dep_time)
#> # A tibble: 0 × 10
#> # ℹ 10 variables: origin <chr>, dest <chr>, dep_delay <dbl>,
#> # arr_delay <dbl>, dep_time <dttm>, sched_dep_time <dttm>, …17.4.3 Interval
dyears(1) / ddays(365) trả về gì? Không hoàn toàn bằng một, vì dyears() được định nghĩa là số giây trong một năm trung bình, tức là 365,25 ngày.
years(1) / days(1) trả về gì? Nếu năm đó là 2015 thì kết quả nên là 365, nhưng nếu là 2016, nó nên trả về 366! Không có đủ thông tin để lubridate đưa ra một câu trả lời rõ ràng duy nhất. Thay vào đó, nó đưa ra một ước tính:
Nếu bạn muốn một phép đo chính xác hơn, bạn cần sử dụng interval (khoảng). Một interval là một cặp date-time bắt đầu và kết thúc, hoặc bạn có thể nghĩ nó như một duration có điểm bắt đầu.
Bạn có thể tạo interval bằng cách viết start %--% end:
Sau đó bạn có thể chia nó cho days() để tìm xem có bao nhiêu ngày trong năm:
17.4.4 Bài tập
Giải thích
days(!overnight)vàdays(overnight)cho một người mới bắt đầu học R. Sự kiện chính bạn cần biết là gì?Tạo một vector các ngày cho ngày đầu tiên của mỗi tháng trong năm 2015. Tạo một vector các ngày cho ngày đầu tiên của mỗi tháng trong năm hiện tại.
Viết một function nhận ngày sinh của bạn (dạng date), trả về bạn bao nhiêu tuổi tính theo năm.
17.5 Múi giờ
Múi giờ là một theme cực kỳ phức tạp do tương tác với các thực thể địa chính trị. May mắn là chúng ta không cần đào sâu vào mọi chi tiết vì không phải tất cả đều quan trọng cho phân tích dữ liệu, nhưng có một vài thách thức mà chúng ta cần giải quyết trực tiếp.
Thách thức đầu tiên là tên thường ngày của múi giờ hay bị mơ hồ. Ví dụ, nếu bạn là người Mỹ, bạn có thể quen thuộc với EST, hay Giờ Chuẩn Miền Đông. Tuy nhiên, cả Úc và Canada cũng có EST! Để tránh nhầm lẫn, R sử dụng tiêu chuẩn quốc tế múi giờ IANA. Các múi giờ này sử dụng quy ước đặt tên nhất quán {khu vực}/{địa điểm}, thường theo dạng {châu lục}/{thành phố} hoặc {đại dương}/{thành phố}. Ví dụ: “America/New_York”, “Europe/Paris”, và “Pacific/Auckland”.
Bạn có thể thắc mắc tại sao múi giờ dùng tên thành phố, trong khi thông thường bạn nghĩ múi giờ gắn với một quốc gia hoặc vùng trong quốc gia. Đó là vì database IANA phải ghi lại row thập kỷ quy tắc múi giờ. Trong suốt nhiều thập kỷ, các quốc gia đổi tên (hoặc tách ra) khá thường xuyên, nhưng tên thành phố có xu hướng giữ nguyên. Một vấn đề khác là tên cần phản ánh không chỉ hành vi hiện tại, mà còn toàn bộ lịch sử. Ví dụ, có múi giờ cho cả “America/New_York” và “America/Detroit”. Cả hai thành phố hiện tại đều sử dụng Giờ Chuẩn Miền Đông nhưng trong giai đoạn 1969-1972, Michigan (tiểu bang nơi Detroit tọa lạc) không tuân theo giờ mùa hè (DST), nên nó cần một tên riêng. Rất đáng để đọc database múi giờ thô (có sẵn tại https://www.iana.org/time-zones) chỉ để đọc một số câu chuyện này!
Bạn có thể tìm hiểu R nghĩ múi giờ hiện tại của bạn là gì bằng Sys.timezone():
Sys.timezone()
#> [1] "Asia/Ho_Chi_Minh"(Nếu R không biết, bạn sẽ nhận được NA.)
Và xem list đầy đủ tất cả tên múi giờ với OlsonNames():
length(OlsonNames())
#> [1] 598
head(OlsonNames())
#> [1] "Africa/Abidjan" "Africa/Accra" "Africa/Addis_Ababa"
#> [4] "Africa/Algiers" "Africa/Asmara" "Africa/Asmera"Trong R, múi giờ là một thuộc tính của date-time chỉ kiểm soát cách hiển thị. Ví dụ, ba đối tượng sau đại diện cho cùng một thời điểm:
Bạn có thể xác minh chúng cùng thời điểm bằng phép trừ:
x1 - x2
#> Time difference of 0 secs
x1 - x3
#> Time difference of 0 secsTrừ khi có chỉ định khác, lubridate luôn sử dụng UTC. UTC (Coordinated Universal Time - Giờ Phối hợp Quốc tế) là múi giờ tiêu chuẩn được cộng đồng khoa học sử dụng và gần tương đương với GMT (Greenwich Mean Time - Giờ Trung bình Greenwich). Nó không có giờ mùa hè (DST), nên là dạng biểu diễn thuận tiện cho tính toán. Các phép toán kết hợp date-time, như c(), thường sẽ bỏ múi giờ. Trong trường hợp đó, date-time sẽ được hiển thị theo múi giờ của phần tử đầu tiên:
x4 <- c(x1, x2, x3)
x4
#> [1] "2024-06-01 12:00:00 EDT" "2024-06-01 12:00:00 EDT"
#> [3] "2024-06-01 12:00:00 EDT"Bạn có thể thay đổi múi giờ theo hai cách:
-
Giữ nguyên thời điểm, và thay đổi cách hiển thị. Dùng cách này khi thời điểm đã đúng, nhưng bạn muốn hiển thị tự nhiên hơn.
x4a <- with_tz(x4, tzone = "Australia/Lord_Howe") x4a #> [1] "2024-06-02 02:30:00 +1030" "2024-06-02 02:30:00 +1030" #> [3] "2024-06-02 02:30:00 +1030" x4a - x4 #> Time differences in secs #> [1] 0 0 0(Điều này cũng minh họa một thách thức khác của múi giờ: không phải tất cả đều lệch theo giờ nguyên!)
-
Thay đổi thời điểm gốc. Dùng cách này khi bạn có một thời điểm đã bị gắn nhãn múi giờ sai, và bạn cần sửa lại.
x4b <- force_tz(x4, tzone = "Australia/Lord_Howe") x4b #> [1] "2024-06-01 12:00:00 +1030" "2024-06-01 12:00:00 +1030" #> [3] "2024-06-01 12:00:00 +1030" x4b - x4 #> Time differences in hours #> [1] -14.5 -14.5 -14.5
17.6 Tóm tắt
Chương này đã giới thiệu cho bạn các công cụ mà lubridate cung cấp để giúp bạn làm việc với dữ liệu date-time. Làm việc với ngày và giờ có vẻ khó hơn mức cần thiết, nhưng hy vọng chương này đã giúp bạn hiểu tại sao — date-time phức tạp hơn vẻ ngoài ban đầu, và việc xử lý mọi tình huống có thể xảy ra sẽ tăng thêm độ phức tạp. Ngay cả khi dữ liệu của bạn không bao giờ vượt qua ranh giới giờ mùa hè hay liên quan đến năm nhuận, các function vẫn cần có khả năng xử lý chúng.
Chương tiếp theo tổng hợp về missing value. Bạn đã gặp chúng ở một vài nơi và chắc chắn đã gặp trong phân tích của riêng mình, và bây giờ là lúc cung cấp một bộ sưu tập các kỹ thuật hữu ích để xử lý chúng.
Một năm là năm nhuận nếu chia hết cho 4, trừ khi nó cũng chia hết cho 100, ngoại trừ nếu nó cũng chia hết cho 400. Nói cách khác, trong mỗi chu kỳ 400 năm, có 97 năm nhuận.↩︎
Bạn có thể thắc mắc UTC là viết tắt của gì. Đây là sự thỏa hiệp giữa tiếng Anh “Coordinated Universal Time” và tiếng Pháp “Temps Universel Coordonné”.↩︎
Không có giải thưởng nào cho việc đoán quốc gia nào đã nghĩ ra hệ thống kinh tuyến.↩︎