27 Cẩm nang về base R
27.1 Giới thiệu
Để kết thúc phần lập trình, chúng tôi sẽ giới thiệu nhanh cho bạn những function base R (base R) quan trọng nhất mà chúng tôi không đề cập ở những phần khác trong cuốn sách. Những công cụ này đặc biệt hữu ích khi bạn lập trình nhiều hơn và sẽ giúp bạn đọc được mã mà bạn gặp ngoài thực tế.
Đây là lúc thích hợp để nhắc bạn rằng tidyverse không phải là cách duy nhất để giải quyết các bài toán khoa học dữ liệu (data science). Chúng tôi dạy tidyverse trong cuốn sách này vì các package tidyverse chia sẻ chung triết lý thiết kế, tăng tính nhất quán giữa các function, và khiến mỗi function hay package mới dễ học dễ dùng hơn một chút. Không thể dùng tidyverse mà không dùng base R, nên thực ra chúng tôi đã dạy bạn rất nhiều function base R: từ library() để tải package, đến sum() và mean() để tóm tắt số, đến kiểu dữ liệu factor (factor), ngày tháng (date), và POSIXct, và tất nhiên là tất cả các toán tử cơ bản như +, -, /, *, |, &, và !. Điều mà chúng tôi chưa tập trung cho đến giờ là workflow với base R, nên chúng tôi sẽ giới thiệu một số workflow trong chương này.
Sau khi đọc cuốn sách này, bạn sẽ học các cách tiếp cận khác cho cùng những bài toán đó bằng base R, data.table, và các package khác. Chắc chắn bạn sẽ gặp các cách tiếp cận khác này khi bạn bắt đầu đọc mã R do người khác viết, đặc biệt nếu bạn đang dùng Stack Overflow. Việc viết mã kết hợp nhiều cách tiếp cận là hoàn toàn bình thường, và đừng để ai nói khác với bạn!
Trong chương này, chúng tôi sẽ tập trung vào bốn theme lớn: lấy tập con (subsetting) bằng [, lấy tập con bằng [[ và $, họ function apply, và loop for. Để kết thúc, chúng tôi sẽ giới thiệu ngắn gọn hai function vẽ biểu đồ thiết yếu.
27.1.1 Điều kiện tiên quyết
Chương này tập trung vào base R nên không thực sự có điều kiện tiên quyết nào, nhưng chúng tôi sẽ tải tidyverse để giải thích một số điểm khác biệt.
27.2 Chọn nhiều phần tử bằng [
[ được dùng để trích xuất các thành phần con từ vector và data frame (data frame), và được gọi dưới dạng x[i] hoặc x[i, j]. Trong phần này, chúng tôi sẽ giới thiệu cho bạn sức mạnh của [, bắt đầu bằng cách cho bạn thấy cách dùng nó với vector, rồi cách những nguyên tắc tương tự mở rộng một cách trực tiếp sang cấu trúc hai chiều (2d) như data frame. Sau đó, chúng tôi sẽ giúp bạn củng cố kiến thức bằng cách cho thấy các verb khác nhau của dplyr là trường hợp đặc biệt của [.
27.2.1 Lấy tập con vector
Có năm loại chính mà bạn có thể dùng để lấy tập con vector, tức là i trong x[i]:
-
Một vector số nguyên dương. Lấy tập con bằng số nguyên dương sẽ giữ lại các phần tử ở các vị trí đó:
Bằng cách iterate lại một vị trí, bạn thực ra có thể tạo đầu ra dài hơn đầu vào, khiến thuật ngữ “lấy tập con” hơi không chính xác.
x[c(1, 1, 5, 5, 5, 2)] #> [1] "one" "one" "five" "five" "five" "two" -
Một vector số nguyên âm. Giá trị âm loại bỏ các phần tử ở các vị trí được chỉ định:
x[c(-1, -3, -5)] #> [1] "two" "four" -
Một vector logic (logical vector). Lấy tập con bằng vector logic sẽ giữ lại tất cả giá trị tương ứng với giá trị
TRUE. Điều này thường hữu ích nhất khi kết hợp với các function so sánh.Khác với
filter(), các chỉ sốNAsẽ được bao gồm trong đầu ra dưới dạngNA. -
Một vector ký tự (character vector). Nếu bạn có một vector được đặt tên, bạn có thể lấy tập con bằng vector ký tự:
Tương tự như lấy tập con bằng số nguyên dương, bạn có thể dùng vector ký tự để iterate lại các phần tử riêng lẻ.
Không có gì. Loại lấy tập con cuối cùng là không có gì,
x[], trả về toàn bộx. Điều này không hữu ích cho việc lấy tập con vector, nhưng như chúng ta sẽ thấy ngay, nó hữu ích khi lấy tập con cấu trúc 2d như tibble.
27.2.2 Lấy tập con data frame
Có khá nhiều cách khác nhau1 để bạn dùng [ với data frame, nhưng cách quan trọng nhất là chọn row và column độc lập bằng df[rows, cols]. Ở đây rows và cols là các vector như đã mô tả ở trên. Ví dụ, df[rows, ] và df[, cols] chỉ chọn row hoặc chỉ chọn column, sử dụng tập con rỗng để giữ nguyên chiều còn lại.
Đây là một vài ví dụ:
df <- tibble(
x = 1:3,
y = c("a", "e", "f"),
z = runif(3)
)
# Chọn row đầu tiên và column thứ hai
df[1, 2]
#> # A tibble: 1 × 1
#> y
#> <chr>
#> 1 a
# Chọn tất cả row và column x, y
df[, c("x" , "y")]
#> # A tibble: 3 × 2
#> x y
#> <int> <chr>
#> 1 1 a
#> 2 2 e
#> 3 3 f
# Chọn các row có `x` lớn hơn 1 và tất cả cột
df[df$x > 1, ]
#> # A tibble: 2 × 3
#> x y z
#> <int> <chr> <dbl>
#> 1 2 e 0.834
#> 2 3 f 0.601Chúng tôi sẽ quay lại $ ngay, nhưng bạn có thể đoán được df$x làm gì từ ngữ cảnh: nó trích xuất biến x từ df. Chúng ta cần dùng nó ở đây vì [ không sử dụng tidy evaluation, nên bạn cần chỉ rõ nguồn của biến x.
Có một điểm khác biệt quan trọng giữa tibble và data frame khi dùng [. Trong cuốn sách này, chúng tôi chủ yếu sử dụng tibble, vốn là data frame, nhưng chúng điều chỉnh một số hành vi để giúp cuộc sống của bạn dễ dàng hơn một chút. Ở hầu hết các nơi, bạn có thể dùng “tibble” và “data frame” thay thế cho nhau, nên khi chúng tôi muốn đặc biệt chú ý đến data frame tích hợp của R, chúng tôi sẽ viết data.frame. Nếu df là data.frame, thì df[, cols] sẽ trả về vector nếu cols chọn một column duy nhất và trả về data frame nếu chọn nhiều hơn một column. Nếu df là tibble, thì [ sẽ luôn trả về tibble.
df1 <- data.frame(x = 1:3)
df1[, "x"]
#> [1] 1 2 3
df2 <- tibble(x = 1:3)
df2[, "x"]
#> # A tibble: 3 × 1
#> x
#> <int>
#> 1 1
#> 2 2
#> 3 3Một cách để tránh sự mơ hồ này với data.frame là chỉ định rõ drop = FALSE:
df1[, "x" , drop = FALSE]
#> x
#> 1 1
#> 2 2
#> 3 327.2.3 Các function dplyr tương đương
Một số verb dplyr là trường hợp đặc biệt của [:
-
filter()tương đương với lấy tập con các row bằng vector logic, chú ý loại trừ missing value (missing value):Một kỹ thuật phổ biến khác ngoài thực tế là dùng
which()với tác dụng phụ là loại bỏ missing value:df[which(df$x > 1), ]. -
arrange()tương đương với lấy tập con các row bằng vector số nguyên, thường được tạo bằngorder():Bạn có thể dùng
order(decreasing = TRUE)để sắp xếp tất cả column theo thứ tự giảm dần hoặc-rank(col)để sắp xếp từng column riêng lẻ theo thứ tự giảm dần. -
Cả
select()vàrelocate()đều tương tự lấy tập con các column bằng vector ký tự:
base R cũng cung cấp một function kết hợp các tính năng của filter() và select()2 gọi là subset():
Function này là nguồn cảm hứng cho phần lớn cú pháp của dplyr.
27.2.4 Bài tập
-
Tạo các function nhận vector làm đầu vào và trả về:
- Các phần tử ở vị trí chẵn.
- Mọi phần tử trừ giá trị cuối cùng.
- Chỉ các giá trị chẵn (và không có missing value).
Tại sao
x[-which(x > 0)]không giống vớix[x <= 0]? Đọc tài liệu hướng dẫn củawhich()và thử nghiệm để tìm ra câu trả lời.
27.3 Chọn một phần tử bằng $ và [[
[, chọn nhiều phần tử, đi cùng với [[ và $, trích xuất một phần tử duy nhất. Trong phần này, chúng tôi sẽ cho bạn thấy cách dùng [[ và $ để rút column ra khỏi data frame, thảo luận thêm một vài điểm khác biệt giữa data.frame và tibble, và nhấn mạnh một số khác biệt quan trọng giữa [ và [[ khi dùng với list (list).
27.3.1 Khung dữ liệu
[[ và $ có thể dùng để trích xuất column từ data frame. [[ có thể truy cập theo vị trí hoặc theo tên, và $ chuyên dùng để truy cập theo tên:
Chúng cũng có thể dùng để tạo column mới, tương đương base R của mutate():
tb$z <- tb$x + tb$y
tb
#> # A tibble: 4 × 3
#> x y z
#> <int> <dbl> <dbl>
#> 1 1 10 11
#> 2 2 4 6
#> 3 3 1 4
#> 4 4 21 25Có một số cách tiếp cận base R khác để tạo column mới bao gồm transform(), with(), và within(). Hadley đã tổng hợp một số ví dụ tại https://gist.github.com/hadley/1986a273e384fb2d4d752c18ed71bedf.
Dùng $ trực tiếp rất tiện khi thực hiện tóm tắt nhanh. Ví dụ, nếu bạn chỉ muốn tìm kích thước viên kim cương lớn nhất hoặc các giá trị có thể của cut, không cần dùng summarize():
dplyr cũng cung cấp một function tương đương với [[/$ mà chúng tôi chưa đề cập trong Chương 3: pull(). pull() nhận tên biến hoặc vị trí biến và trả về chỉ column đó. Điều đó có nghĩa là chúng ta có thể viết lại đoạn mã ở trên để dùng pipe:
27.3.2 Tibble
Có một vài điểm khác biệt quan trọng giữa tibble và data.frame cơ bản khi dùng $. Khung dữ liệu khớp tiền tố của bất kỳ tên biến nào (gọi là khớp một phần (partial matching)) và không báo lỗi nếu column không tồn tại:
df <- data.frame(x1 = 1)
df$x
#> [1] 1
df$z
#> NULLTibble nghiêm ngặt hơn: chúng chỉ khớp chính xác tên biến và sẽ tạo cảnh báo nếu column bạn đang cố truy cập không tồn tại:
tb <- tibble(x1 = 1)
tb$x
#> Warning: Unknown or uninitialised column: `x`.
#> NULL
tb$z
#> Warning: Unknown or uninitialised column: `z`.
#> NULLVì lý do này, đôi khi chúng tôi đùa rằng tibble lười và khó tính: chúng làm ít hơn và phàn nàn nhiều hơn.
27.3.3 Danh sách
[[ và $ cũng rất quan trọng khi làm việc với list, và việc hiểu chúng khác [ như thế nào là quan trọng. Hãy minh họa sự khác biệt bằng list tên l:
-
[trích xuất một list con. Bất kể bạn trích xuất bao nhiêu phần tử, kết quả sẽ luôn là list.Giống như với vector, bạn có thể lấy tập con bằng vector logic, số nguyên, hoặc ký tự.
-
[[và$trích xuất một thành phần duy nhất từ list. Chúng loại bỏ một cấp phân cấp khỏi list.
Sự khác biệt giữa [ và [[ đặc biệt quan trọng đối với list vì [[ đào sâu vào list trong khi [ trả về một list mới nhỏ hơn. Để giúp bạn nhớ sự khác biệt, hãy xem lọ tiêu bất thường trong Hình 27.1. Nếu lọ tiêu này là list pepper của bạn, thì pepper[1] là một lọ tiêu chứa một gói tiêu duy nhất. pepper[2] sẽ trông giống vậy, nhưng sẽ chứa gói thứ hai. pepper[1:2] sẽ là một lọ tiêu chứa hai gói tiêu. pepper[[1]] sẽ trích xuất chính gói tiêu đó.
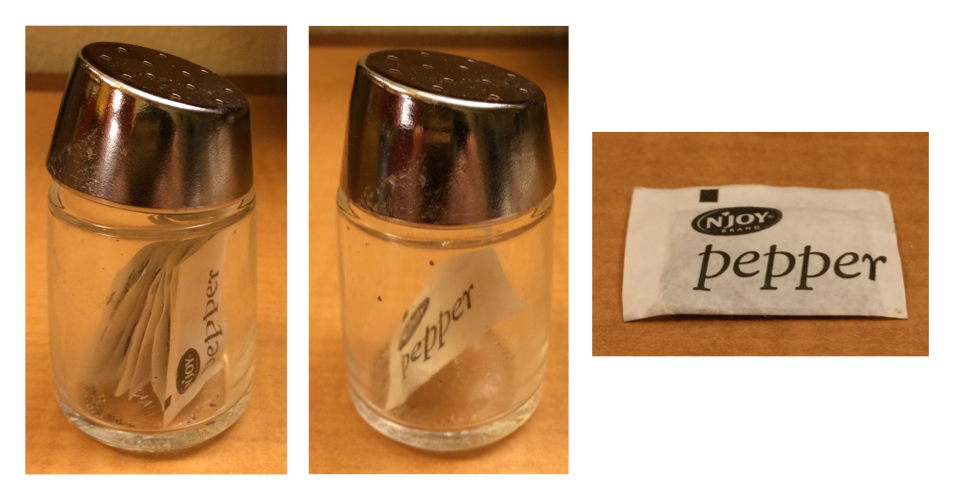
pepper[1]. (Phải) pepper[[1]]
Nguyên tắc tương tự cũng áp dụng khi bạn dùng [ 1d với data frame: df["x"] trả về data frame một column và df[["x"]] trả về vector.
27.3.4 Bài tập
Điều gì xảy ra khi bạn dùng
[[với số nguyên dương lớn hơn độ dài của vector? Điều gì xảy ra khi bạn lấy tập con bằng tên không tồn tại?pepper[[1]][1]sẽ là gì? Cònpepper[[1]][[1]]thì sao?
27.4 Họ function apply
Trong Chương 26, bạn đã học các kỹ thuật tidyverse cho việc iterate (iteration) như dplyr::across() và họ function map. Trong phần này, bạn sẽ học về các function tương đương trong base R, họ function apply. Trong ngữ cảnh này apply và map là đồng nghĩa vì cách nói khác của “map một function lên mỗi phần tử của vector” là “apply một function lên mỗi phần tử của vector”. Ở đây chúng tôi sẽ giới thiệu tổng quan nhanh về họ function này để bạn có thể nhận ra chúng ngoài thực tế.
Thành viên quan trọng nhất của họ này là lapply(), rất giống với purrr::map()3. Thực tế, vì chúng ta chưa dùng bất kỳ tính năng nâng cao nào của map(), bạn có thể thay thế mọi lệnh gọi map() trong Chương 26 bằng lapply().
Không có function base R nào tương đương chính xác với across() nhưng bạn có thể xấp xỉ bằng cách dùng [ với lapply(). Điều này hoạt động vì ẩn bên dưới, data frame là list các column, nên gọi lapply() trên data frame sẽ áp dụng function lên mỗi column.
df <- tibble(a = 1, b = 2, c = "a", d = "b", e = 4)
# Đầu tiên tìm các column số
num_cols <- sapply(df, is.numeric)
num_cols
#> a b c d e
#> TRUE TRUE FALSE FALSE TRUE
# Sau đó biến đổi mỗi column bằng lapply() rồi thay thế các giá trị gốc
df[, num_cols] <- lapply(df[, num_cols, drop = FALSE], \(x) x * 2)
df
#> # A tibble: 1 × 5
#> a b c d e
#> <dbl> <dbl> <chr> <chr> <dbl>
#> 1 2 4 a b 8Đoạn mã ở trên dùng một function mới, sapply(). Nó tương tự lapply() nhưng luôn cố đơn giản hóa kết quả, do đó có chữ s trong tên, ở đây tạo ra vector logic thay vì list. Chúng tôi không khuyến khích dùng nó khi lập trình, vì việc đơn giản hóa có thể thất bại và cho bạn kiểu không mong đợi, nhưng thường ổn cho sử dụng tương tác. purrr có một function tương tự gọi là map_vec() mà chúng tôi chưa đề cập trong Chương 26.
base R cung cấp phiên bản nghiêm ngặt hơn của sapply() gọi là vapply(), viết tắt của vector apply. Nó nhận thêm một argument (argument) chỉ định kiểu mong đợi, đảm bảo việc đơn giản hóa xảy ra giống nhau bất kể đầu vào. Ví dụ, chúng ta có thể thay thế lệnh sapply() ở trên bằng vapply() này, trong đó chúng ta chỉ định rằng chúng ta mong đợi is.numeric() trả về vector logic có độ dài 1:
Sự khác biệt giữa sapply() và vapply() thực sự quan trọng khi chúng ở bên trong một function (vì nó tạo ra khác biệt lớn cho tính mạnh mẽ của function với đầu vào bất thường), nhưng thường không quan trọng trong phân tích dữ liệu.
Một thành viên quan trọng khác của họ apply là tapply(), tính toán một tóm tắt nhóm đơn lẻ:
diamonds |>
group_by(cut) |>
summarize(price = mean(price))
#> # A tibble: 5 × 2
#> cut price
#> <ord> <dbl>
#> 1 Fair 4359.
#> 2 Good 3929.
#> 3 Very Good 3982.
#> 4 Premium 4584.
#> 5 Ideal 3458.
tapply(diamonds$price, diamonds$cut, mean)
#> Fair Good Very Good Premium Ideal
#> 4358.758 3928.864 3981.760 4584.258 3457.542Thật không may, tapply() trả kết quả dưới dạng vector có tên, đòi hỏi một số thao tác phức tạp nếu bạn muốn gom nhiều bảng tóm tắt và biến nhóm vào một data frame (chắc chắn bạn có thể không làm điều này và chỉ làm việc với các vector rời, nhưng theo kinh nghiệm của chúng tôi, điều đó chỉ trì hoãn công việc). Nếu bạn muốn xem cách dùng tapply() hoặc các kỹ thuật base R khác để thực hiện các tóm tắt nhóm khác, Hadley đã tổng hợp một số kỹ thuật trong một gist.
Thành viên cuối cùng của họ apply là chính function apply(), hoạt động với ma trận (matrix) và mảng (array). Đặc biệt, hãy cẩn thận với apply(df, 2, something), đây là cách chậm và có thể nguy hiểm để làm lapply(df, something). Điều này hiếm khi xảy ra trong khoa học dữ liệu vì chúng ta thường làm việc với data frame chứ không phải ma trận.
27.5 Vòng iterate for
Vòng iterate for là khối xây dựng cơ bản của phép iterate mà cả họ apply và map đều sử dụng ở bên dưới. Vòng iterate for là công cụ mạnh mẽ và đa năng, quan trọng để học khi bạn trở thành lập trình viên R có kinh nghiệm hơn. Cấu trúc cơ bản của loop for trông như thế này:
for (element in vector) {
# thực hiện gì đó với element
}Cách sử dụng trực tiếp nhất của loop for là đạt được hiệu quả tương tự như walk(): gọi một function có tác dụng phụ (side-effect) trên mỗi phần tử của list. Ví dụ, trong Phần 26.4.1 thay vì dùng walk():
paths |> walk(append_file)Chúng ta có thể dùng loop for:
for (path in paths) {
append_file(path)
}Mọi thứ trở nên phức tạp hơn một chút nếu bạn muốn lưu đầu ra của loop for, ví dụ đọc tất cả các file excel trong một thư mục như chúng ta đã làm trong Chương 26:
paths <- dir("data/gapminder", pattern = "\\.xlsx$", full.names = TRUE)
files <- map(paths, readxl::read_excel)Có một số kỹ thuật khác nhau bạn có thể dùng, nhưng chúng tôi khuyến khích bạn nên rõ ràng ngay từ đầu về đầu ra sẽ trông như thế nào. Trong trường hợp này, chúng ta sẽ muốn một list có cùng độ dài với paths, mà chúng ta có thể tạo bằng vector():
Rồi thay vì iterate qua các phần tử của paths, chúng ta sẽ iterate qua các chỉ số của chúng, dùng seq_along() để tạo một chỉ số cho mỗi phần tử của paths:
seq_along(paths)
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12Sử dụng chỉ số là quan trọng vì nó cho phép chúng ta liên kết mỗi vị trí trong đầu vào với vị trí tương ứng trong đầu ra:
for (i in seq_along(paths)) {
files[[i]] <- readxl::read_excel(paths[[i]])
}Để gộp list các tibble thành một tibble duy nhất, bạn có thể dùng do.call() + rbind():
do.call(rbind, files)
#> # A tibble: 1,704 × 5
#> country continent lifeExp pop gdpPercap
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Afghanistan Asia 28.8 8425333 779.
#> 2 Albania Europe 55.2 1282697 1601.
#> 3 Algeria Africa 43.1 9279525 2449.
#> 4 Angola Africa 30.0 4232095 3521.
#> 5 Argentina Americas 62.5 17876956 5911.
#> 6 Australia Oceania 69.1 8691212 10040.
#> # ℹ 1,698 more rowsThay vì tạo list và lưu kết quả khi đi, cách đơn giản hơn là xây dựng data frame từng phần một:
out <- NULL
for (path in paths) {
out <- rbind(out, readxl::read_excel(path))
}Chúng tôi khuyến khích tránh mẫu này vì nó có thể trở nên rất chậm khi vector rất dài. Đây là nguồn gốc của quan niệm sai dai dẳng rằng loop for chậm: chúng không chậm, nhưng việc tăng dần vector thì có.
27.6 Biểu đồ
Nhiều người dùng R không dùng tidyverse cho việc khác vẫn thích ggplot2 để vẽ biểu đồ nhờ các tính năng hữu ích như giá trị mặc định hợp lý, chú giải tự động, và giao diện hiện đại. Tuy nhiên, các function vẽ biểu đồ base R vẫn có thể hữu ích vì chúng rất ngắn gọn — chỉ cần gõ rất ít để tạo một biểu đồ khám phá cơ bản.
Có hai loại biểu đồ base R chính mà bạn sẽ thấy ngoài thực tế: biểu đồ phân tán (scatter plot) và biểu đồ tần suất (histogram), được tạo lần lượt bằng plot() và hist(). Đây là ví dụ nhanh từ tập dữ liệu diamonds:
Lưu ý rằng các function vẽ biểu đồ base R làm việc với vector, nên bạn cần rút column ra khỏi data frame bằng $ hoặc kỹ thuật khác.
27.7 Tóm tắt
Trong chương này, chúng tôi đã cho bạn thấy một số function base R hữu ích cho việc lấy tập con và iterate. So với các cách tiếp cận được thảo luận ở những nơi khác trong sách, các function này có xu hướng mang “hương vị vector” nhiều hơn “hương vị data frame” vì các function base R thường nhận các vector riêng lẻ, thay vì data frame và đặc tả column nào đó. Điều này thường giúp cuộc sống dễ dàng hơn khi lập trình và do đó trở nên quan trọng hơn khi bạn viết nhiều function hơn và bắt đầu viết package của riêng mình.
Chương này kết thúc phần lập trình của cuốn sách. Bạn đã có một khởi đầu vững chắc trên hành trình trở thành không chỉ nhà khoa học dữ liệu sử dụng R, mà là nhà khoa học dữ liệu có thể lập trình bằng R. Chúng tôi hy vọng những chương này đã khơi dậy sự quan tâm của bạn đối với lập trình và bạn đang mong chờ học thêm bên ngoài cuốn sách này.
Đọc https://adv-r.hadley.nz/subsetting.html#subset-multiple để xem cách bạn cũng có thể lấy tập con data frame như đối tượng 1d và cách bạn có thể lấy tập con bằng ma trận.↩︎
Nhưng nó không xử lý data frame đã nhóm khác biệt và không hỗ trợ các function trợ giúp chọn lọc như
starts_with().↩︎Nó chỉ thiếu các tính năng tiện lợi như thanh tiến trình và báo cáo phần tử nào gây ra lỗi nếu có lỗi xảy ra.↩︎