23 Dữ liệu phân cấp
23.1 Giới thiệu
Trong chương này, bạn sẽ học nghệ thuật chuyển đổi thành dạng bảng (rectangling): lấy dữ liệu vốn có cấu trúc phân cấp (hierarchical), hay dạng cây, và chuyển đổi nó thành data frame hình chữ nhật gồm các row và column. Điều này quan trọng vì dữ liệu phân cấp phổ biến đến đáng ngạc nhiên, đặc biệt khi làm việc với dữ liệu đến từ web.
Để học về rectangling, trước tiên bạn cần tìm hiểu về list (list), cấu trúc dữ liệu giúp dữ liệu phân cấp trở nên khả thi. Sau đó bạn sẽ tìm hiểu về hai function quan trọng của tidyr: tidyr::unnest_longer() và tidyr::unnest_wider(). Tiếp theo, chúng tôi sẽ cho bạn xem một vài nghiên cứu tình huống, áp dụng những function đơn giản này iterate đi iterate lại để giải quyết các bài toán thực tế. Cuối cùng, chúng tôi sẽ nói về JSON, nguồn phổ biến nhất của các tập dữ liệu phân cấp và định dạng thông dụng để trao đổi dữ liệu trên web.
23.1.1 Điều kiện tiên quyết
Trong chương này, chúng ta sẽ sử dụng nhiều function từ tidyr, một thành viên cốt lõi của tidyverse. Chúng ta cũng sẽ dùng repurrrsive để cung cấp một số tập dữ liệu thú vị cho việc thực hành rectangling, và cuối cùng sẽ dùng jsonlite để đọc các tệp JSON vào list R.
23.2 Danh sách
Cho đến nay bạn đã làm việc với các data frame chứa các vector đơn giản như số nguyên (integer), số thực, ký tự, ngày giờ, và factor (factor). Những vector này đơn giản vì chúng đồng nhất: mọi phần tử đều cùng kiểu dữ liệu. Nếu bạn muốn lưu trữ các phần tử có kiểu khác nhau trong cùng một vector, bạn sẽ cần một list (list), được tạo bằng list():
x1 <- list(1:4, "a", TRUE)
x1
#> [[1]]
#> [1] 1 2 3 4
#>
#> [[2]]
#> [1] "a"
#>
#> [[3]]
#> [1] TRUEViệc đặt tên cho các thành phần, hay phần tử con (children), của một list thường rất tiện lợi, và bạn có thể làm tương tự cách đặt tên cho các column của một tibble:
x2 <- list(a = 1:2, b = 1:3, c = 1:4)
x2
#> $a
#> [1] 1 2
#>
#> $b
#> [1] 1 2 3
#>
#> $c
#> [1] 1 2 3 4Ngay cả với những list rất đơn giản, việc in ra cũng chiếm khá nhiều không gian. Một cách thay thế hữu ích là str(), hiển thị một bản tóm tắt ngắn gọn về cấu trúc (structure), giảm nhấn mạnh vào nội dung:
Như bạn thấy, str() hiển thị mỗi phần tử con của list trên dòng riêng. Nó hiển thị tên (nếu có), sau đó là viết tắt của kiểu dữ liệu, rồi đến vài giá trị đầu tiên.
23.2.1 Phân cấp
Danh sách có thể chứa bất kỳ loại đối tượng nào, bao gồm cả các list khác. Điều này khiến chúng phù hợp để biểu diễn các cấu trúc phân cấp (dạng cây):
Điều này khác biệt rõ rệt so với c(), function tạo ra một vector phẳng:
Khi list trở nên phức tạp hơn, str() càng trở nên hữu ích, vì nó cho bạn thấy cấu trúc phân cấp trong nháy mắt:
Khi list trở nên lớn và phức tạp hơn nữa, str() cuối cùng sẽ không đủ dùng, và bạn sẽ cần chuyển sang View()1. Hình 23.1 cho thấy kết quả của việc gọi View(x5). Trình xem bắt đầu bằng cách chỉ hiển thị cấp cao nhất của list, nhưng bạn có thể mở rộng tương tác bất kỳ thành phần nào để xem thêm, như trong Hình 23.2. RStudio cũng sẽ hiển thị cho bạn mã cần thiết để truy cập phần tử đó, như trong Hình 23.3. Chúng ta sẽ quay lại cách mã này hoạt động trong Phần 27.3.
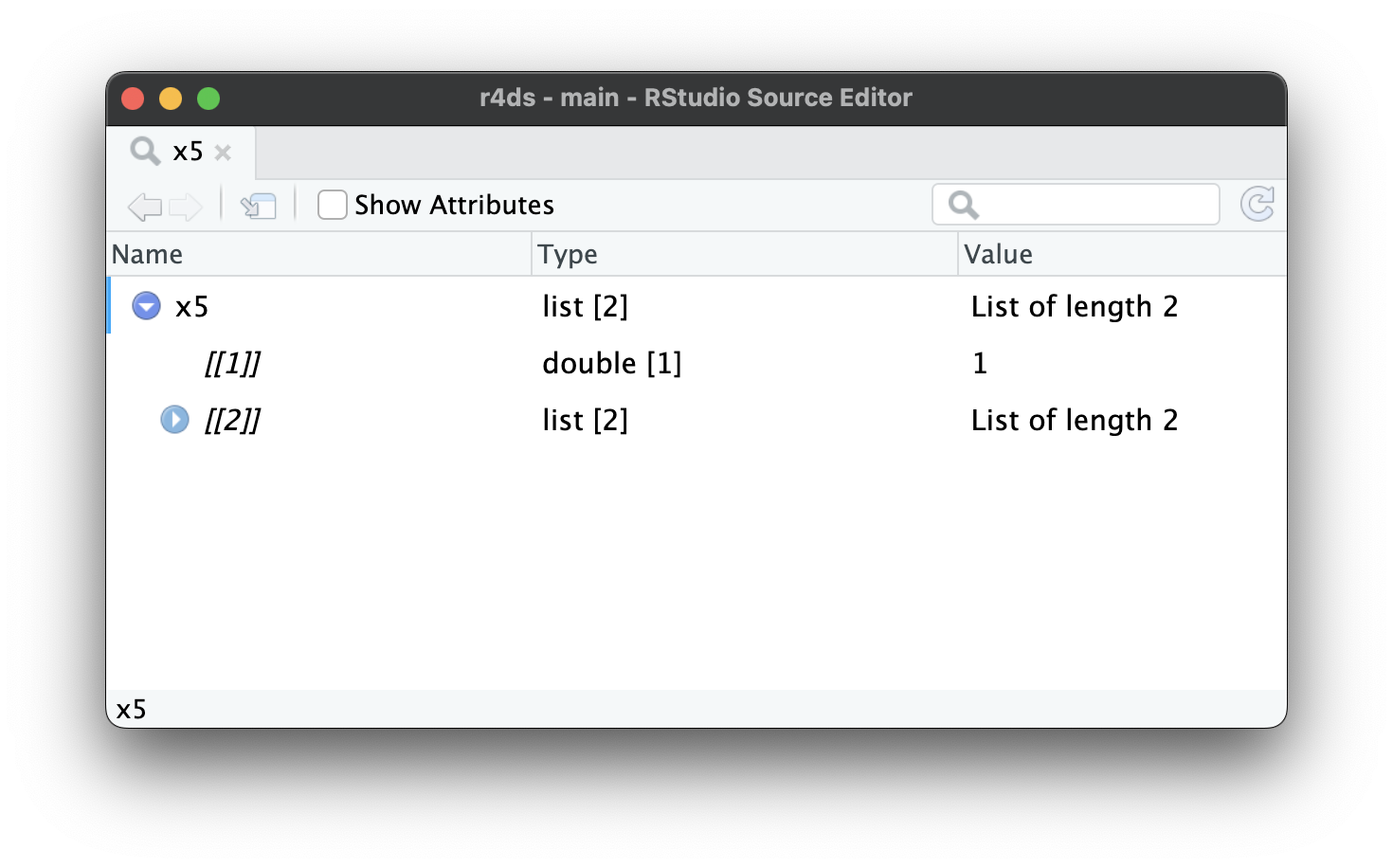
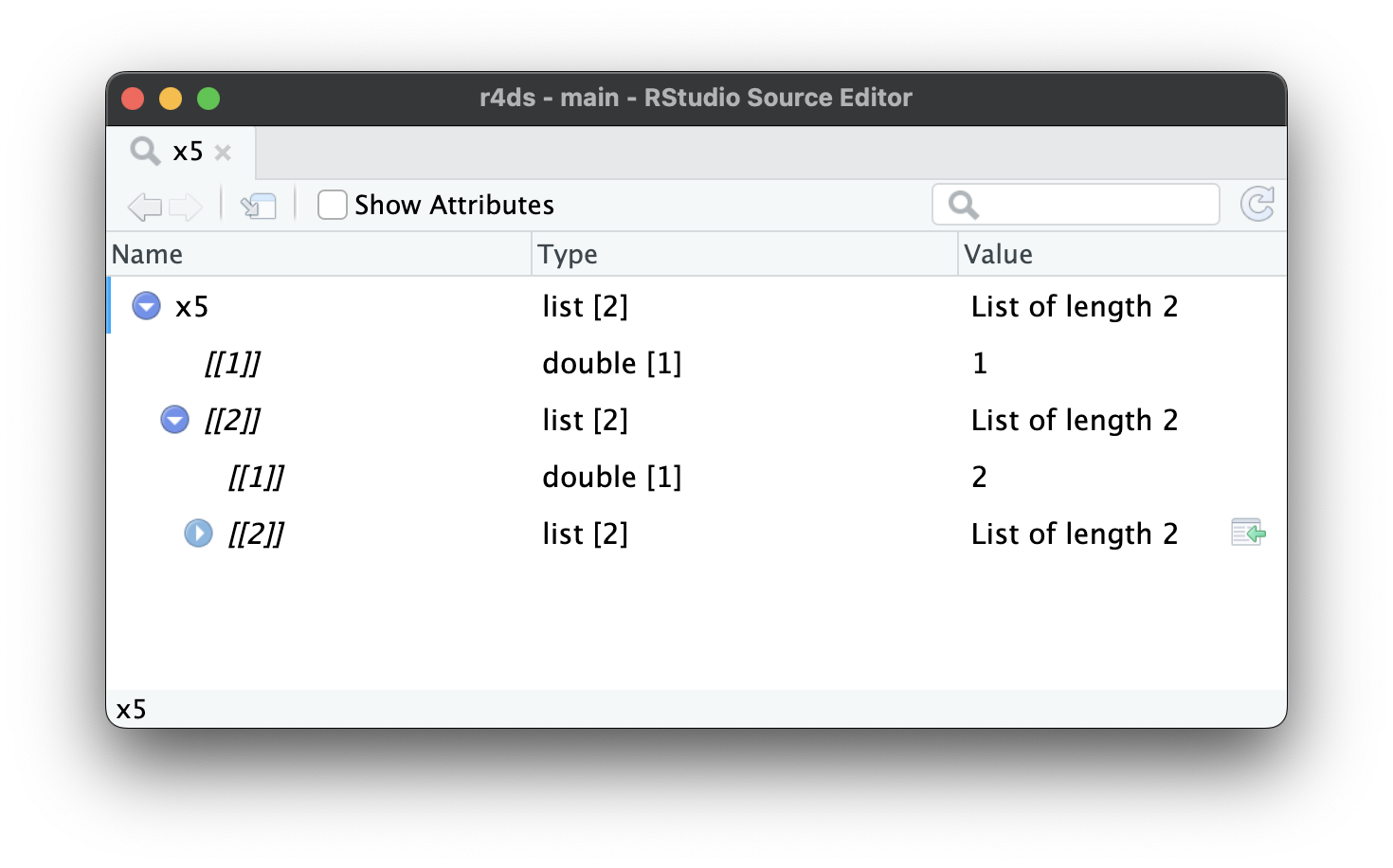
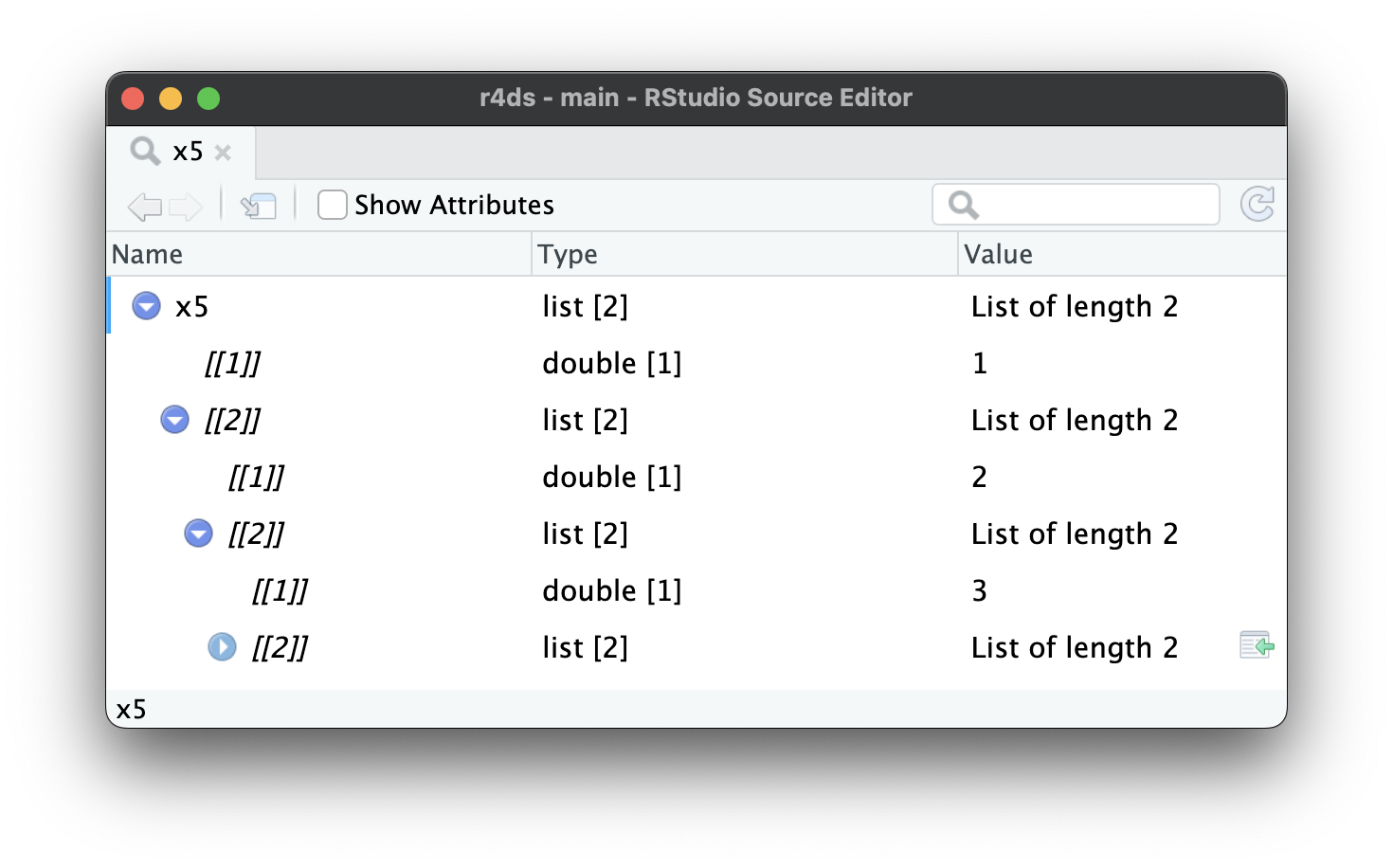
x5[[2]][[2]][[2]].
23.2.2 Cột list
Danh sách cũng có thể nằm bên trong một tibble, nơi chúng ta gọi chúng là column list (list-column). Cột list hữu ích vì chúng cho phép bạn đặt các đối tượng vào tibble mà thông thường không thuộc về đó. Cụ thể, column list được sử dụng rất nhiều trong hệ sinh thái tidymodels, vì chúng cho phép bạn lưu trữ những thứ như kết quả mô hình hoặc các mẫu iterate lại trong một data frame.
Đây là một ví dụ đơn giản về column list:
Không có gì đặc biệt về list trong tibble; chúng hoạt động như bất kỳ column nào khác:
df |>
filter(x == 1)
#> # A tibble: 1 × 3
#> x y z
#> <int> <chr> <list>
#> 1 1 a <list [2]>Tính toán với column list khó hơn, nhưng đó là vì tính toán với list nói chung là khó hơn; chúng ta sẽ quay lại vấn đề này trong Chương 26. Trong chương này, chúng ta sẽ tập trung vào việc mở rộng column list thành các biến thông thường để bạn có thể sử dụng các công cụ hiện có trên chúng.
Phương thức in mặc định chỉ hiển thị một bản tóm tắt sơ bộ về nội dung. Cột list có thể phức tạp tùy ý, nên không có cách tốt nào để in nó. Nếu bạn muốn xem nó, bạn sẽ cần lấy riêng column list đó ra và áp dụng một trong các kỹ thuật bạn đã học ở trên, như df |> pull(z) |> str() hoặc df |> pull(z) |> View().
Có thể đặt một list vào column của data.frame, nhưng phức tạp hơn nhiều vì data.frame() coi list như một list các column:
data.frame(x = list(1:3, 3:5))
#> x.1.3 x.3.5
#> 1 1 3
#> 2 2 4
#> 3 3 5Bạn có thể buộc data.frame() coi list như một list các row bằng cách bọc nó trong I(), nhưng kết quả in ra không được đẹp lắm:
data.frame(
x = I(list(1:2, 3:5)),
y = c("1, 2", "3, 4, 5")
)
#> x y
#> 1 1, 2 1, 2
#> 2 3, 4, 5 3, 4, 5Sử dụng column list với tibble dễ hơn vì tibble() coi list như vector và phương thức in được thiết kế có tính đến list.
23.3 Mở rộng
Bây giờ bạn đã học những kiến thức cơ bản về list và column list, hãy khám phá cách chuyển chúng trở lại thành các row và column thông thường. Ở đây chúng ta sẽ sử dụng dữ liệu mẫu rất đơn giản để bạn nắm được ý tưởng cơ bản; trong phần tiếp theo chúng ta sẽ chuyển sang dữ liệu thực.
Cột list thường có hai dạng cơ bản: có tên và không có tên. Khi các phần tử con có tên (named), chúng thường có cùng tên ở mọi row. Ví dụ, trong df1, mỗi phần tử của column list y đều có hai phần tử được đặt tên là a và b. Cột list có tên tự nhiên được mở rộng thành các column: mỗi phần tử có tên trở thành một column mới có tên.
Khi các phần tử con không có tên (unnamed), số lượng phần tử thường thay đổi từ row này sang row khác. Ví dụ, trong df2, các phần tử của column list y không có tên và có độ dài thay đổi từ một đến ba. Cột list không có tên tự nhiên được mở rộng thành các row: bạn sẽ nhận được một row cho mỗi phần tử con.
tidyr cung cấp hai function cho hai trường hợp này: unnest_wider() và unnest_longer(). Các phần sau giải thích cách chúng hoạt động.
23.3.1 unnest_wider()
Khi mỗi row có cùng số lượng phần tử với cùng tên, như df1, thì việc đặt mỗi thành phần vào column riêng với unnest_wider() là tự nhiên:
df1 |>
unnest_wider(y)
#> # A tibble: 3 × 3
#> x a b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32Mặc định, tên của các column mới chỉ lấy từ tên của các phần tử list, nhưng bạn có thể dùng argument names_sep để yêu cầu kết hợp tên column và tên phần tử. Điều này hữu ích để phân biệt các tên bị trùng.
df1 |>
unnest_wider(y, names_sep = "_")
#> # A tibble: 3 × 3
#> x y_a y_b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32
23.3.2 unnest_longer()
Khi mỗi row chứa một list không có tên, cách tự nhiên nhất là đặt mỗi phần tử vào row riêng với unnest_longer():
df2 |>
unnest_longer(y)
#> # A tibble: 6 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 11
#> 2 1 12
#> 3 1 13
#> 4 2 21
#> 5 3 31
#> 6 3 32Lưu ý cách x được nhân bản cho mỗi phần tử bên trong y: chúng ta nhận được một row đầu ra cho mỗi phần tử bên trong column list. Nhưng điều gì xảy ra nếu một trong các phần tử rỗng, như trong ví dụ sau?
df6 <- tribble(
~x, ~y,
"a", list(1, 2),
"b", list(3),
"c", list()
)
df6 |> unnest_longer(y)
#> # A tibble: 3 × 2
#> x y
#> <chr> <dbl>
#> 1 a 1
#> 2 a 2
#> 3 b 3Chúng ta nhận được không row nào trong đầu ra, nên row đó thực tế biến mất. Nếu bạn muốn giữ lại row đó, thêm NA vào y, hãy đặt keep_empty = TRUE.
23.3.3 Kiểu dữ liệu không nhất quán
Điều gì xảy ra nếu bạn mở rộng một column list chứa các kiểu vector khác nhau? Ví dụ, lấy tập dữ liệu sau trong đó column list y chứa hai số, một ký tự, và một giá trị logic (logical), những thứ thông thường không thể trộn lẫn trong một column đơn.
unnest_longer() luôn giữ nguyên tập hợp các column, trong khi thay đổi số lượng row. Vậy điều gì xảy ra? Làm thế nào unnest_longer() tạo ra năm row trong khi giữ mọi thứ trong y?
df4 |>
unnest_longer(y)
#> # A tibble: 4 × 2
#> x y
#> <chr> <list>
#> 1 a <dbl [1]>
#> 2 b <chr [1]>
#> 3 b <lgl [1]>
#> 4 b <dbl [1]>Như bạn thấy, đầu ra chứa một column list, nhưng mỗi phần tử của column list chỉ chứa một phần tử duy nhất. Vì unnest_longer() không tìm được kiểu vector chung, nó giữ nguyên các kiểu gốc trong một column list. Bạn có thể thắc mắc liệu điều này có vi phạm quy tắc rằng mọi phần tử của một column phải cùng kiểu không. Không hề: mọi phần tử đều là một list, dù nội dung bên trong có kiểu khác nhau.
Xử lý các kiểu không nhất quán là một thách thức và chi tiết phụ thuộc vào bản chất chính xác của vấn đề cùng mục tiêu của bạn, nhưng rất có thể bạn sẽ cần các công cụ từ Chương 26.
23.3.4 Các function khác
tidyr có một vài function rectangling hữu ích khác mà chúng ta sẽ không đề cập trong cuốn sách này:
-
unnest_auto()tự động chọn giữaunnest_longer()vàunnest_wider()dựa trên cấu trúc của column list. Nó rất tốt cho việc khám phá nhanh, nhưng cuối cùng đây là một ý tưởng không tốt vì nó không buộc bạn hiểu cấu trúc dữ liệu của mình, và làm mã của bạn khó hiểu hơn. -
unnest()mở rộng cả row và column. Nó hữu ích khi bạn có column list chứa cấu trúc 2 chiều như data frame, thứ bạn không gặp trong cuốn sách này, nhưng có thể gặp nếu bạn sử dụng hệ sinh thái tidymodels.
Những function này nên biết vì bạn có thể gặp chúng khi đọc mã của người khác hoặc tự giải quyết các thách thức rectangling ít phổ biến hơn.
23.3.5 Bài tập
Điều gì xảy ra khi bạn sử dụng
unnest_wider()với column list không có tên nhưdf2? Đối số nào bây giờ là cần thiết? Điều gì xảy ra với các missing value?Điều gì xảy ra khi bạn sử dụng
unnest_longer()với column list có tên nhưdf1? Bạn nhận được thông tin bổ sung gì trong đầu ra? Làm thế nào bạn có thể ẩn chi tiết thêm đó?-
Thỉnh thoảng bạn gặp các data frame có nhiều column list với các giá trị được căn chỉnh. Ví dụ, trong data frame sau, các giá trị của
yvàzđược căn chỉnh (tức làyvàzsẽ luôn có cùng độ dài trong một row, và giá trị đầu tiên củaytương ứng với giá trị đầu tiên củaz). Điều gì xảy ra nếu bạn áp dụng hai lệnh gọiunnest_longer()cho data frame này? Làm thế nào bạn có thể bảo toàn mối quan hệ giữaxvày? (Gợi ý: đọc kỹ tài liệu).
23.4 Nghiên cứu tình huống
Sự khác biệt chính giữa các ví dụ đơn giản chúng ta đã dùng ở trên và dữ liệu thực là dữ liệu thực thường chứa nhiều cấp lồng nhau đòi hỏi nhiều lệnh gọi unnest_longer() và/hoặc unnest_wider(). Để minh họa điều đó, phần này sẽ đi qua ba thách thức rectangling thực tế sử dụng các tập dữ liệu từ package repurrrsive.
23.4.1 Dữ liệu rất rộng
Chúng ta sẽ bắt đầu với gh_repos. Đây là một list chứa dữ liệu về một tập hợp các kho lưu trữ (repository) GitHub được lấy bằng GitHub API. Đây là một list lồng rất sâu nên khó hiển thị cấu trúc trong cuốn sách này; chúng tôi khuyên bạn nên tự khám phá một chút với View(gh_repos) trước khi tiếp tục.
gh_repos là một list, nhưng các công cụ của chúng ta hoạt động với column list, nên chúng ta sẽ bắt đầu bằng cách đặt nó vào một tibble. Chúng ta đặt tên column này là json vì lý do chúng ta sẽ nói sau.
repos <- tibble(json = gh_repos)
repos
#> # A tibble: 6 × 1
#> json
#> <list>
#> 1 <list [30]>
#> 2 <list [30]>
#> 3 <list [30]>
#> 4 <list [26]>
#> 5 <list [30]>
#> 6 <list [30]>Tibble này chứa 6 row, mỗi row cho mỗi phần tử con của gh_repos. Mỗi row chứa một list không có tên với 26 hoặc 30 row. Vì chúng không có tên, chúng ta sẽ bắt đầu với unnest_longer() để đặt mỗi phần tử con vào row riêng:
repos |>
unnest_longer(json)
#> # A tibble: 176 × 1
#> json
#> <list>
#> 1 <named list [68]>
#> 2 <named list [68]>
#> 3 <named list [68]>
#> 4 <named list [68]>
#> 5 <named list [68]>
#> 6 <named list [68]>
#> # ℹ 170 more rowsThoạt nhìn, có vẻ như chúng ta chưa cải thiện tình hình: mặc dù có nhiều row hơn (176 thay vì 6) mỗi phần tử của json vẫn là một list. Tuy nhiên, có một khác biệt quan trọng: bây giờ mỗi phần tử là một list có tên nên chúng ta có thể dùng unnest_wider() để đặt mỗi phần tử vào column riêng:
repos |>
unnest_longer(json) |>
unnest_wider(json)
#> # A tibble: 176 × 68
#> id name full_name owner private html_url
#> <int> <chr> <chr> <list> <lgl> <chr>
#> 1 61160198 after gaborcsardi/after <named list> FALSE https://github…
#> 2 40500181 argufy gaborcsardi/argu… <named list> FALSE https://github…
#> 3 36442442 ask gaborcsardi/ask <named list> FALSE https://github…
#> 4 34924886 baseimports gaborcsardi/base… <named list> FALSE https://github…
#> 5 61620661 citest gaborcsardi/cite… <named list> FALSE https://github…
#> 6 33907457 clisymbols gaborcsardi/clis… <named list> FALSE https://github…
#> # ℹ 170 more rows
#> # ℹ 62 more variables: description <chr>, fork <lgl>, url <chr>, …Cách này đã hoạt động nhưng kết quả hơi choáng ngợp: có quá nhiều column đến nỗi tibble thậm chí không in hết tất cả! Chúng ta có thể xem tất cả bằng names(); và ở đây chúng ta xem 10 column đầu tiên:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
names() |>
head(10)
#> [1] "id" "name" "full_name" "owner" "private"
#> [6] "html_url" "description" "fork" "url" "forks_url"Hãy lấy ra một vài column trông thú vị:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description)
#> # A tibble: 176 × 4
#> id full_name owner description
#> <int> <chr> <list> <chr>
#> 1 61160198 gaborcsardi/after <named list [17]> Run Code in the Backgro…
#> 2 40500181 gaborcsardi/argufy <named list [17]> Declarative function ar…
#> 3 36442442 gaborcsardi/ask <named list [17]> Friendly CLI interactio…
#> 4 34924886 gaborcsardi/baseimports <named list [17]> Do we get warnings for …
#> 5 61620661 gaborcsardi/citest <named list [17]> Test R package and repo…
#> 6 33907457 gaborcsardi/clisymbols <named list [17]> Unicode symbols for CLI…
#> # ℹ 170 more rowsBạn có thể dùng điều này để hiểu ngược lại cấu trúc của gh_repos: mỗi phần tử con là một người dùng GitHub chứa list lên đến 30 kho lưu trữ GitHub mà họ đã tạo.
owner là một column list khác, và vì nó chứa một list có tên, chúng ta có thể dùng unnest_wider() để lấy các giá trị:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner)
#> Error in `unnest_wider()`:
#> ! Can't duplicate names between the affected columns and the original
#> data.
#> ✖ These names are duplicated:
#> ℹ `id`, from `owner`.
#> ℹ Use `names_sep` to disambiguate using the column name.
#> ℹ Or use `names_repair` to specify a repair strategy.Ối, column list này cũng chứa một column id và chúng ta không thể có hai column id trong cùng một data frame. Như gợi ý, hãy dùng names_sep để giải quyết vấn đề:
repos |>
unnest_longer(json) |>
unnest_wider(json) |>
select(id, full_name, owner, description) |>
unnest_wider(owner, names_sep = "_")
#> # A tibble: 176 × 20
#> id full_name owner_login owner_id owner_avatar_url
#> <int> <chr> <chr> <int> <chr>
#> 1 61160198 gaborcsardi/after gaborcsardi 660288 https://avatars.gith…
#> 2 40500181 gaborcsardi/argufy gaborcsardi 660288 https://avatars.gith…
#> 3 36442442 gaborcsardi/ask gaborcsardi 660288 https://avatars.gith…
#> 4 34924886 gaborcsardi/baseimports gaborcsardi 660288 https://avatars.gith…
#> 5 61620661 gaborcsardi/citest gaborcsardi 660288 https://avatars.gith…
#> 6 33907457 gaborcsardi/clisymbols gaborcsardi 660288 https://avatars.gith…
#> # ℹ 170 more rows
#> # ℹ 15 more variables: owner_gravatar_id <chr>, owner_url <chr>, …Điều này cho ra một tập dữ liệu rộng khác, nhưng bạn có thể cảm nhận rằng owner dường như chứa rất nhiều dữ liệu bổ sung về người “sở hữu” kho lưu trữ.
23.4.2 Dữ liệu quan hệ
Dữ liệu lồng nhau đôi khi được dùng để biểu diễn dữ liệu mà chúng ta thường trải ra trên nhiều data frame. Ví dụ, lấy got_chars chứa dữ liệu về các nhân vật xuất hiện trong loạt sách và phim Game of Thrones. Giống như gh_repos, nó là một list, nên chúng ta bắt đầu bằng cách biến nó thành column list của một tibble:
chars <- tibble(json = got_chars)
chars
#> # A tibble: 30 × 1
#> json
#> <list>
#> 1 <named list [18]>
#> 2 <named list [18]>
#> 3 <named list [18]>
#> 4 <named list [18]>
#> 5 <named list [18]>
#> 6 <named list [18]>
#> # ℹ 24 more rowsCột json chứa các phần tử có tên, nên chúng ta sẽ bắt đầu bằng cách mở rộng nó:
chars |>
unnest_wider(json)
#> # A tibble: 30 × 18
#> url id name gender culture born
#> <chr> <int> <chr> <chr> <chr> <chr>
#> 1 https://www.anapio… 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or …
#> 2 https://www.anapio… 1052 Tyrion Lannist… Male "" "In 273 AC, at…
#> 3 https://www.anapio… 1074 Victarion Grey… Male "Ironborn" "In 268 AC or …
#> 4 https://www.anapio… 1109 Will Male "" ""
#> 5 https://www.anapio… 1166 Areo Hotah Male "Norvoshi" "In 257 AC or …
#> 6 https://www.anapio… 1267 Chett Male "" "At Hag's Mire"
#> # ℹ 24 more rows
#> # ℹ 12 more variables: died <chr>, alive <lgl>, titles <list>, …Và chọn một vài column để dễ đọc hơn:
characters <- chars |>
unnest_wider(json) |>
select(id, name, gender, culture, born, died, alive)
characters
#> # A tibble: 30 × 7
#> id name gender culture born died
#> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1022 Theon Greyjoy Male "Ironborn" "In 278 AC or 27… ""
#> 2 1052 Tyrion Lannister Male "" "In 273 AC, at C… ""
#> 3 1074 Victarion Greyjoy Male "Ironborn" "In 268 AC or be… ""
#> 4 1109 Will Male "" "" "In 297 AC, at…
#> 5 1166 Areo Hotah Male "Norvoshi" "In 257 AC or be… ""
#> 6 1267 Chett Male "" "At Hag's Mire" "In 299 AC, at…
#> # ℹ 24 more rows
#> # ℹ 1 more variable: alive <lgl>Tập dữ liệu này cũng chứa nhiều column list:
chars |>
unnest_wider(json) |>
select(id, where(is.list))
#> # A tibble: 30 × 8
#> id titles aliases allegiances books povBooks tvSeries playedBy
#> <int> <list> <list> <list> <list> <list> <list> <list>
#> 1 1022 <chr [2]> <chr [4]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 2 1052 <chr [2]> <chr [11]> <chr [1]> <chr [2]> <chr> <chr> <chr>
#> 3 1074 <chr [2]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 4 1109 <chr [1]> <chr [1]> <NULL> <chr [1]> <chr> <chr> <chr>
#> 5 1166 <chr [1]> <chr [1]> <chr [1]> <chr [3]> <chr> <chr> <chr>
#> 6 1267 <chr [1]> <chr [1]> <NULL> <chr [2]> <chr> <chr> <chr>
#> # ℹ 24 more rowsHãy khám phá column titles. Đây là column list không có tên, nên chúng ta sẽ mở rộng nó thành các row:
chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles)
#> # A tibble: 59 × 2
#> id titles
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 53 more rowsBạn có thể muốn thấy dữ liệu này trong bảng riêng vì sẽ dễ nối (join) với dữ liệu nhân vật khi cần. Hãy làm điều đó, việc này cần một chút dọn dẹp: loại bỏ các row chứa string rỗng và đổi tên titles thành title vì mỗi row giờ chỉ chứa một tiêu đề duy nhất.
titles <- chars |>
unnest_wider(json) |>
select(id, titles) |>
unnest_longer(titles) |>
filter(titles != "") |>
rename(title = titles)
titles
#> # A tibble: 52 × 2
#> id title
#> <int> <chr>
#> 1 1022 Prince of Winterfell
#> 2 1022 Lord of the Iron Islands (by law of the green lands)
#> 3 1052 Acting Hand of the King (former)
#> 4 1052 Master of Coin (former)
#> 5 1074 Lord Captain of the Iron Fleet
#> 6 1074 Master of the Iron Victory
#> # ℹ 46 more rowsBạn có thể tưởng tượng việc tạo một bảng như thế này cho mỗi column list, sau đó sử dụng các phép nối để kết hợp chúng với dữ liệu nhân vật khi cần.
23.4.3 Lồng sâu
Chúng ta sẽ kết thúc các nghiên cứu tình huống này với một column list được lồng rất sâu và đòi hỏi nhiều vòng unnest_wider() và unnest_longer() để gỡ ra: gmaps_cities. Đây là một tibble hai column chứa năm tên thành phố và kết quả của việc sử dụng API mã hóa địa lý của Google để xác định vị trí của chúng:
gmaps_cities
#> # A tibble: 5 × 2
#> city json
#> <chr> <list>
#> 1 Houston <named list [2]>
#> 2 Washington <named list [2]>
#> 3 New York <named list [2]>
#> 4 Chicago <named list [2]>
#> 5 Arlington <named list [2]>json là column list với tên bên trong, nên chúng ta bắt đầu với unnest_wider():
gmaps_cities |>
unnest_wider(json)
#> # A tibble: 5 × 3
#> city results status
#> <chr> <list> <chr>
#> 1 Houston <list [1]> OK
#> 2 Washington <list [2]> OK
#> 3 New York <list [1]> OK
#> 4 Chicago <list [1]> OK
#> 5 Arlington <list [2]> OKĐiều này cho chúng ta status và results. Chúng ta sẽ bỏ column status vì tất cả đều là OK; trong phân tích thực tế, bạn cũng sẽ muốn nắm bắt tất cả các row có status != "OK" và tìm hiểu xem có gì sai. results là một list không có tên, với một hoặc hai phần tử (chúng ta sẽ sớm thấy tại sao) nên chúng ta sẽ mở rộng nó thành các row:
gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results)
#> # A tibble: 7 × 2
#> city results
#> <chr> <list>
#> 1 Houston <named list [5]>
#> 2 Washington <named list [5]>
#> 3 Washington <named list [5]>
#> 4 New York <named list [5]>
#> 5 Chicago <named list [5]>
#> 6 Arlington <named list [5]>
#> # ℹ 1 more rowBây giờ results là một list có tên, nên chúng ta sẽ dùng unnest_wider():
locations <- gmaps_cities |>
unnest_wider(json) |>
select(-status) |>
unnest_longer(results) |>
unnest_wider(results)
locations
#> # A tibble: 7 × 6
#> city address_components formatted_address geometry
#> <chr> <list> <chr> <list>
#> 1 Houston <list [4]> Houston, TX, USA <named list [4]>
#> 2 Washington <list [2]> Washington, USA <named list [4]>
#> 3 Washington <list [4]> Washington, DC, USA <named list [4]>
#> 4 New York <list [3]> New York, NY, USA <named list [4]>
#> 5 Chicago <list [4]> Chicago, IL, USA <named list [4]>
#> 6 Arlington <list [4]> Arlington, TX, USA <named list [4]>
#> # ℹ 1 more row
#> # ℹ 2 more variables: place_id <chr>, types <list>Bây giờ chúng ta có thể thấy tại sao hai thành phố có hai kết quả: Washington khớp với cả bang Washington và Washington, DC, và Arlington khớp với Arlington, Virginia và Arlington, Texas.
Có một vài hướng khác nhau chúng ta có thể đi từ đây. Chúng ta có thể muốn xác định vị trí chính xác của kết quả khớp, được lưu trong column list geometry:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry)
#> # A tibble: 7 × 6
#> city formatted_address bounds location location_type
#> <chr> <chr> <list> <list> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> <named list> APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> <named list> APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> <named list> APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> <named list> APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list> APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list> APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>Điều đó cho chúng ta bounds (một vùng hình chữ nhật) và location (một điểm) mới. Chúng ta có thể mở rộng location để xem vĩ độ (lat) và kinh độ (lng):
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
unnest_wider(location)
#> # A tibble: 7 × 7
#> city formatted_address bounds lat lng location_type
#> <chr> <chr> <list> <dbl> <dbl> <chr>
#> 1 Houston Houston, TX, USA <named list [2]> 29.8 -95.4 APPROXIMATE
#> 2 Washington Washington, USA <named list [2]> 47.8 -121. APPROXIMATE
#> 3 Washington Washington, DC, USA <named list [2]> 38.9 -77.0 APPROXIMATE
#> 4 New York New York, NY, USA <named list [2]> 40.7 -74.0 APPROXIMATE
#> 5 Chicago Chicago, IL, USA <named list [2]> 41.9 -87.6 APPROXIMATE
#> 6 Arlington Arlington, TX, USA <named list [2]> 32.7 -97.1 APPROXIMATE
#> # ℹ 1 more row
#> # ℹ 1 more variable: viewport <list>Trích xuất bounds đòi hỏi thêm vài bước nữa:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
# tập trung vào các biến quan tâm
select(!location:viewport) |>
unnest_wider(bounds)
#> # A tibble: 7 × 4
#> city formatted_address northeast southwest
#> <chr> <chr> <list> <list>
#> 1 Houston Houston, TX, USA <named list [2]> <named list [2]>
#> 2 Washington Washington, USA <named list [2]> <named list [2]>
#> 3 Washington Washington, DC, USA <named list [2]> <named list [2]>
#> 4 New York New York, NY, USA <named list [2]> <named list [2]>
#> 5 Chicago Chicago, IL, USA <named list [2]> <named list [2]>
#> 6 Arlington Arlington, TX, USA <named list [2]> <named list [2]>
#> # ℹ 1 more rowSau đó chúng ta đổi tên southwest và northeast (các góc của hình chữ nhật) để có thể dùng names_sep tạo ra các tên ngắn nhưng gợi nhớ:
locations |>
select(city, formatted_address, geometry) |>
unnest_wider(geometry) |>
select(!location:viewport) |>
unnest_wider(bounds) |>
rename(ne = northeast, sw = southwest) |>
unnest_wider(c(ne, sw), names_sep = "_")
#> # A tibble: 7 × 6
#> city formatted_address ne_lat ne_lng sw_lat sw_lng
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Houston Houston, TX, USA 30.1 -95.0 29.5 -95.8
#> 2 Washington Washington, USA 49.0 -117. 45.5 -125.
#> 3 Washington Washington, DC, USA 39.0 -76.9 38.8 -77.1
#> 4 New York New York, NY, USA 40.9 -73.7 40.5 -74.3
#> 5 Chicago Chicago, IL, USA 42.0 -87.5 41.6 -87.9
#> 6 Arlington Arlington, TX, USA 32.8 -97.0 32.6 -97.2
#> # ℹ 1 more rowLưu ý cách chúng ta mở rộng hai column cùng lúc bằng cách cung cấp một vector tên biến cho unnest_wider().
Khi bạn đã tìm được đường dẫn đến các thành phần mà bạn quan tâm, bạn có thể trích xuất chúng trực tiếp bằng một function tidyr khác, hoist():
Nếu các nghiên cứu tình huống này đã kích thích sự tò mò của bạn về rectangling với dữ liệu thực tế, bạn có thể xem thêm một vài ví dụ trong vignette("rectangling", package = "tidyr").
23.4.4 Bài tập
Ước lượng sơ bộ thời điểm
gh_reposđược tạo. Tại sao bạn chỉ có thể ước lượng sơ bộ ngày?Cột
ownercủagh_reposchứa rất nhiều thông tin trùng iterate vì mỗi chủ sở hữu có thể có nhiều kho lưu trữ. Bạn có thể xây dựng một data frameownerschứa một row cho mỗi chủ sở hữu không? (Gợi ý:distinct()có hoạt động vớilist-colskhông?)Làm theo các bước đã dùng cho
titlesđể tạo các bảng tương tự cho biệt danh, phe phái, sách, và phim truyền hình cho các nhân vật Game of Thrones.-
Giải thích đoạn mã sau từng dòng một. Tại sao nó thú vị? Tại sao nó hoạt động cho
got_charsnhưng có thể không hoạt động nói chung?tibble(json = got_chars) |> unnest_wider(json) |> select(id, where(is.list)) |> pivot_longer( where(is.list), names_to = "name", values_to = "value" ) |> unnest_longer(value) Trong
gmaps_cities,address_componentschứa gì? Tại sao độ dài thay đổi giữa các row? Mở rộng nó một cách phù hợp để tìm hiểu. (Gợi ý:typesdường như luôn chứa hai phần tử.unnest_wider()có giúp làm việc dễ hơn so vớiunnest_longer()không?) .
23.5 JSON
Tất cả các nghiên cứu tình huống trong phần trước đều được lấy từ dữ liệu JSON thực tế. JSON là viết tắt của JavaScript Object Notation và là cách mà hầu hết các web API trả về dữ liệu. Việc hiểu nó rất quan trọng vì mặc dù các kiểu dữ liệu của JSON và R khá giống nhau, không có sự tương ứng 1-1 hoàn hảo, nên tốt nhất bạn nên hiểu một chút về JSON phòng khi có vấn đề.
23.5.1 Các kiểu dữ liệu
JSON là một định dạng đơn giản được thiết kế để máy tính dễ dàng đọc và viết, chứ không phải con người. Nó có sáu kiểu dữ liệu chính. Bốn trong số đó là vô hướng (scalar):
- Kiểu đơn giản nhất là null (
null) đóng vai trò giống nhưNAtrong R. Nó biểu diễn sự vắng mặt của dữ liệu. - Chuỗi ký tự (string) rất giống string trong R, nhưng phải luôn sử dụng dấu ngoặc kép.
-
Số (number) tương tự như số trong R: chúng có thể dùng ký hiệu số nguyên (ví dụ: 123), thập phân (ví dụ: 123.45), hoặc khoa học (ví dụ: 1.23e3). JSON không hỗ trợ
Inf,-Inf, hoặcNaN. -
Giá trị boolean tương tự như
TRUEvàFALSEtrong R, nhưng sử dụng chữ thườngtruevàfalse.
Chuỗi ký tự, số, và boolean của JSON khá giống với các vector ký tự, số, và logic của R. Sự khác biệt chính là các giá trị vô hướng của JSON chỉ có thể biểu diễn một giá trị duy nhất. Để biểu diễn nhiều giá trị, bạn cần sử dụng một trong hai kiểu còn lại: mảng (array) và đối tượng (object).
Cả mảng và đối tượng đều giống với list trong R; sự khác biệt là chúng có tên hay không. Một mảng giống như một list không có tên, và được viết bằng []. Ví dụ [1, 2, 3] là một mảng chứa 3 số, và [null, 1, "string", false] là một mảng chứa một null, một số, một string, và một boolean. Một đối tượng giống như một list có tên, và được viết bằng {}. Các tên (gọi là key trong thuật ngữ JSON) là string, nên phải được bao quanh bởi dấu ngoặc kép. Ví dụ, {"x": 1, "y": 2} là một đối tượng mapping x thành 1 và y thành 2.
Lưu ý rằng JSON không có cách gốc nào để biểu diễn ngày hoặc ngày giờ, nên chúng thường được lưu dưới dạng string, và bạn sẽ cần dùng readr::parse_date() hoặc readr::parse_datetime() để chuyển chúng thành cấu trúc dữ liệu đúng. Tương tự, các quy tắc biểu diễn số dấu phẩy động trong JSON hơi thiếu chính xác, nên đôi khi bạn cũng sẽ gặp số được lưu dưới dạng string. Hãy áp dụng readr::parse_double() khi cần để có được kiểu biến đúng.
23.5.2 jsonlite
Để chuyển đổi JSON thành cấu trúc dữ liệu R, chúng tôi khuyên dùng package jsonlite, do Jeroen Ooms phát triển. Chúng ta sẽ chỉ dùng hai function jsonlite: read_json() và parse_json(). Trong thực tế, bạn sẽ dùng read_json() để đọc tệp JSON từ ổ đĩa. Ví dụ, package repurrsive cũng cung cấp nguồn của gh_user dưới dạng tệp JSON và bạn có thể đọc nó bằng read_json():
# Đường dẫn đến tệp json bên trong package:
gh_users_json()
#> [1] "/Library/Frameworks/R.framework/Versions/4.5-arm64/Resources/library/repurrrsive/extdata/gh_users.json"
# Đọc bằng read_json()
gh_users2 <- read_json(gh_users_json())
# Kiểm tra xem nó có giống với dữ liệu chúng ta đã dùng trước đó không
identical(gh_users, gh_users2)
#> [1] TRUETrong cuốn sách này, chúng ta cũng sẽ dùng parse_json(), vì nó nhận một string chứa JSON, rất tốt cho việc tạo các ví dụ đơn giản. Để bắt đầu, đây là ba tập dữ liệu JSON đơn giản, bắt đầu với một số, sau đó đặt vài số vào một mảng, rồi đặt mảng đó vào một đối tượng:
str(parse_json('1'))
#> int 1
str(parse_json('[1, 2, 3]'))
#> List of 3
#> $ : int 1
#> $ : int 2
#> $ : int 3
str(parse_json('{"x": [1, 2, 3]}'))
#> List of 1
#> $ x:List of 3
#> ..$ : int 1
#> ..$ : int 2
#> ..$ : int 3jsonlite có một function quan trọng khác là fromJSON(). Chúng ta không dùng nó ở đây vì nó thực hiện đơn giản hóa tự động (simplifyVector = TRUE). Điều này thường hoạt động tốt, đặc biệt trong các trường hợp đơn giản, nhưng chúng tôi nghĩ bạn nên tự thực hiện rectangling để biết chính xác điều gì đang xảy ra và có thể xử lý dễ dàng hơn các cấu trúc lồng nhau phức tạp nhất.
23.5.3 Bắt đầu quá trình rectangling
Trong hầu hết các trường hợp, tệp JSON chứa một mảng cấp cao nhất duy nhất, vì chúng được thiết kế để cung cấp dữ liệu về nhiều “thứ”, ví dụ: nhiều trang, hoặc nhiều bản ghi, hoặc nhiều kết quả. Trong trường hợp này, bạn sẽ bắt đầu rectangling với tibble(json) để mỗi phần tử trở thành một row:
json <- '[
{"name": "John", "age": 34},
{"name": "Susan", "age": 27}
]'
df <- tibble(json = parse_json(json))
df
#> # A tibble: 2 × 1
#> json
#> <list>
#> 1 <named list [2]>
#> 2 <named list [2]>
df |>
unnest_wider(json)
#> # A tibble: 2 × 2
#> name age
#> <chr> <int>
#> 1 John 34
#> 2 Susan 27Trong các trường hợp ít phổ biến hơn, tệp JSON bao gồm một đối tượng JSON cấp cao nhất duy nhất, biểu diễn một “thứ”. Trong trường hợp này, bạn sẽ cần khởi động quá trình rectangling bằng cách bọc nó trong một list, trước khi đặt vào tibble.
json <- '{
"status": "OK",
"results": [
{"name": "John", "age": 34},
{"name": "Susan", "age": 27}
]
}
'
df <- tibble(json = list(parse_json(json)))
df
#> # A tibble: 1 × 1
#> json
#> <list>
#> 1 <named list [2]>
df |>
unnest_wider(json) |>
unnest_longer(results) |>
unnest_wider(results)
#> # A tibble: 2 × 3
#> status name age
#> <chr> <chr> <int>
#> 1 OK John 34
#> 2 OK Susan 27Cách khác, bạn có thể truy cập vào bên trong JSON đã phân tích và bắt đầu với phần mà bạn thực sự quan tâm:
df <- tibble(results = parse_json(json)$results)
df |>
unnest_wider(results)
#> # A tibble: 2 × 2
#> name age
#> <chr> <int>
#> 1 John 34
#> 2 Susan 2723.5.4 Bài tập
-
Chuyển đổi
df_colvàdf_rowbên dưới thành dạng bảng. Chúng biểu diễn hai cách mã hóa một data frame trong JSON.json_col <- parse_json(' { "x": ["a", "x", "z"], "y": [10, null, 3] } ') json_row <- parse_json(' [ {"x": "a", "y": 10}, {"x": "x", "y": null}, {"x": "z", "y": 3} ] ') df_col <- tibble(json = list(json_col)) df_row <- tibble(json = json_row)
23.6 Tóm tắt
Trong chương này, bạn đã học list là gì, cách tạo chúng từ tệp JSON, và cách chuyển chúng thành data frame hình chữ nhật. Đáng ngạc nhiên là chúng ta chỉ cần hai function mới: unnest_longer() để đặt các phần tử list vào row và unnest_wider() để đặt các phần tử list vào column. Không quan trọng column list lồng sâu đến mức nào; tất cả những gì bạn cần làm là gọi iterate đi iterate lại hai function này.
JSON là định dạng dữ liệu phổ biến nhất được trả về bởi các web API. Điều gì xảy ra nếu trang web không có API, nhưng bạn có thể thấy dữ liệu mình muốn trên trang web? Đó là theme của chương tiếp theo: thu thập dữ liệu web (web scraping), trích xuất dữ liệu từ các trang web HTML.
Đây là tính năng của RStudio.↩︎