Giới thiệu
Khoa học dữ liệu (data science) là một lĩnh vực thú vị cho phép bạn biến đổi dữ liệu thô thành tri thức. Mục tiêu của “R cho Khoa học Dữ liệu” là giúp bạn học những công cụ quan trọng nhất trong R để thực hiện khoa học dữ liệu một cách hiệu quả và có tính tái lập, đồng thời có chút vui vẻ trên hành trình này 😃. Sau khi đọc xong cuốn sách này, bạn sẽ có các công cụ để giải quyết nhiều thách thức khoa học dữ liệu đa dạng bằng những phần tốt nhất của R.
Bạn sẽ học được gì
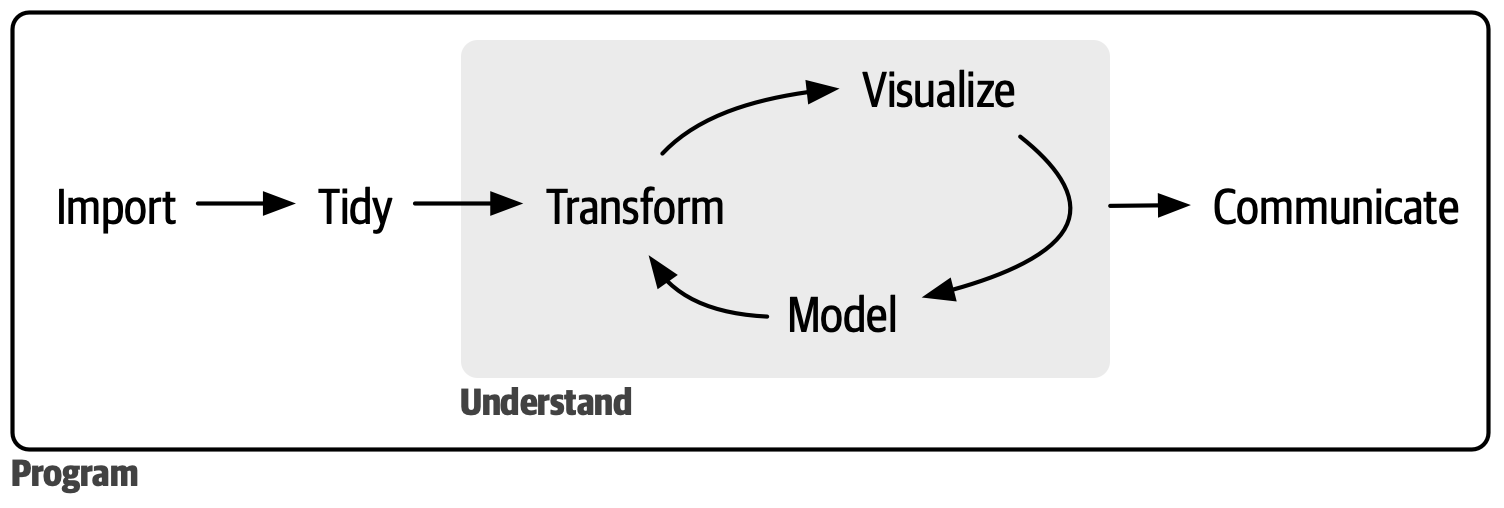
Khoa học dữ liệu là một lĩnh vực rộng lớn, và không có cách nào bạn có thể thành thạo tất cả chỉ bằng việc đọc một cuốn sách duy nhất. Cuốn sách này nhằm cung cấp cho bạn nền tảng vững chắc về các công cụ quan trọng nhất và đủ kiến thức để tìm thêm tài nguyên học hỏi khi cần thiết. Mô hình của chúng tôi về các bước của một dự án khoa học dữ liệu điển hình trông giống như Hình 1.
Đầu tiên, bạn phải nhập dữ liệu vào R. Điều này thường có nghĩa là bạn lấy dữ liệu được lưu trữ trong một file, database, hoặc giao diện lập trình ứng dụng (API) và tải nó vào một data frame trong R. Nếu bạn không thể đưa dữ liệu vào R, bạn không thể thực hiện khoa học dữ liệu trên nó!
Sau khi đã nhập dữ liệu, bạn nên sắp xếp nó cho gọn gàng. Sắp xếp tidy data (tidying) có nghĩa là lưu trữ nó theo một dạng nhất quán, trong đó ngữ nghĩa của tập dữ liệu tương ứng với cách nó được lưu trữ. Nói ngắn gọn, khi dữ liệu của bạn gọn gàng (tidy), mỗi column là một biến (variable) và mỗi row là một quan sát (observation). Dữ liệu gọn gàng (tidy data) rất quan trọng vì cấu trúc nhất quán cho phép bạn tập trung nỗ lực vào việc trả lời các câu hỏi về dữ liệu, thay vì phải vật lộn để đưa dữ liệu vào đúng dạng cho các function khác nhau.
Khi đã có tidy data, bước tiếp theo phổ biến là biến đổi nó. Biến đổi (transformation) bao gồm thu hẹp phạm vi vào các quan sát mà bạn quan tâm (như tất cả người dân trong một thành phố hoặc tất cả dữ liệu từ năm trước), tạo các biến mới là function của các biến hiện có (như tính tốc độ từ khoảng cách và thời gian), và tính toán một tập hợp thống kê tóm tắt (như số đếm hoặc giá trị trung bình). Kết hợp lại, sắp xếp và biến đổi được gọi là xử lý dữ liệu (wrangling) vì việc đưa dữ liệu vào dạng tự nhiên để làm việc thường cảm thấy như một cuộc chiến!
Khi đã có tidy data với các biến bạn cần, có hai động cơ chính để tạo ra tri thức: visualization và mô hình hóa. Chúng có những điểm mạnh và điểm yếu bổ sung cho nhau, vì vậy bất kỳ phân tích dữ liệu thực tế nào cũng sẽ iterate đi iterate lại giữa chúng nhiều lần.
Trực quan hóa (visualization) về cơ bản là một hoạt động của con người. Một hình trực quan tốt sẽ cho bạn thấy những điều bạn không ngờ đến hoặc đặt ra những câu hỏi mới về dữ liệu. Một hình trực quan tốt cũng có thể gợi ý rằng bạn đang đặt sai câu hỏi hoặc bạn cần thu thập dữ liệu khác. Trực quan hóa có thể mang đến bất ngờ, nhưng chúng không mở rộng quy mô tốt lắm vì chúng cần con người để diễn giải.
Mô hình (model) là công cụ bổ sung cho visualization. Khi bạn đã làm cho câu hỏi của mình đủ chính xác, bạn có thể sử dụng mô hình để trả lời chúng. Mô hình về cơ bản là công cụ toán học hoặc thuật toán, vì vậy chúng thường mở rộng quy mô tốt. Ngay cả khi không, thường thì mua thêm máy tính rẻ hơn mua thêm bộ não! Nhưng mọi mô hình đều đưa ra giả định, và theo bản chất, mô hình không thể tự đặt câu hỏi về giả định của mình. Điều đó có nghĩa là mô hình không thể mang đến bất ngờ cho bạn một cách căn bản.
Bước cuối cùng của khoa học dữ liệu là truyền đạt (communication), một phần vô cùng quan trọng của bất kỳ dự án phân tích dữ liệu nào. Dù mô hình và visualization đã giúp bạn hiểu dữ liệu tốt đến đâu, điều đó cũng không quan trọng nếu bạn không thể truyền đạt kết quả đến người khác.
Bao quanh tất cả các công cụ này là lập trình (programming). Lập trình là một công cụ xuyên suốt mà bạn sử dụng trong hầu hết mọi phần của dự án khoa học dữ liệu. Bạn không cần phải là một lập trình viên chuyên gia để trở thành một nhà khoa học dữ liệu thành công, nhưng việc học thêm về lập trình sẽ mang lại lợi ích vì trở thành lập trình viên giỏi hơn cho phép bạn tự động hóa các tác vụ phổ biến và giải quyết vấn đề mới dễ dàng hơn.
Bạn sẽ sử dụng các công cụ này trong mọi dự án khoa học dữ liệu, nhưng chúng chưa đủ cho hầu hết các dự án. Có một quy tắc 80/20 ở đây: bạn có thể giải quyết khoảng 80% mỗi dự án bằng các công cụ bạn sẽ học trong cuốn sách này, nhưng bạn sẽ cần các công cụ khác để giải quyết 20% còn lại. Xuyên suốt cuốn sách, chúng tôi sẽ chỉ cho bạn các tài nguyên để bạn có thể tìm hiểu thêm.
Cuốn sách này được tổ chức như thế nào
Phần mô tả trước đó về các công cụ khoa học dữ liệu được tổ chức đại khái theo thứ tự mà bạn sử dụng chúng trong một phân tích (mặc dù, tất nhiên, bạn sẽ iterate qua chúng nhiều lần). Tuy nhiên, theo kinh nghiệm của chúng tôi, việc học nhập và sắp xếp dữ liệu trước không phải là cách tốt nhất vì 80% thời gian, nó nhàm chán và iterate đi iterate lại, còn 20% thời gian còn lại thì kỳ lạ và khó chịu. Đó không phải là nơi tốt để bắt đầu học một theme mới! Thay vào đó, chúng ta sẽ bắt đầu với visualization và biến đổi dữ liệu đã được nhập và sắp xếp sẵn. Bằng cách đó, khi bạn nhập và sắp xếp dữ liệu của riêng mình, động lực của bạn sẽ vẫn cao vì bạn biết rằng nỗi vất vả đó xứng đáng.
Trong mỗi chương, chúng tôi cố gắng tuân theo một mô hình nhất quán: bắt đầu với một số ví dụ tạo động lực để bạn có thể thấy bức tranh lớn hơn, sau đó đi vào chi tiết. Mỗi phần của cuốn sách đi kèm với các bài tập để giúp bạn thực hành những gì đã học. Mặc dù có thể hấp dẫn khi bỏ qua các bài tập, không có cách nào tốt hơn để học ngoài việc thực hành trên các vấn đề thực tế.
Những gì bạn sẽ không học
Có một số theme quan trọng mà cuốn sách này không đề cập. Chúng tôi tin rằng điều quan trọng là phải tập trung vào những điều cốt lõi để bạn có thể bắt đầu nhanh nhất có thể. Điều đó có nghĩa là cuốn sách này không thể đề cập mọi theme quan trọng.
Mô hình hóa
Mô hình hóa (modeling) cực kỳ quan trọng cho khoa học dữ liệu, nhưng đó là một theme lớn, và thật không may, chúng tôi không có đủ không gian để trình bày nó xứng đáng ở đây. Để tìm hiểu thêm về mô hình hóa, chúng tôi rất khuyến nghị Tidy Modeling with R của các đồng nghiệp Max Kuhn và Julia Silge. Cuốn sách này sẽ dạy bạn họ package tidymodels, mà như bạn có thể đoán từ tên gọi, chia sẻ nhiều quy ước với các package tidyverse mà chúng ta sử dụng trong cuốn sách này.
Dữ liệu lớn
Cuốn sách này tự hào tập trung chủ yếu vào các tập dữ liệu nhỏ, nằm trong bộ nhớ. Đây là nơi đúng đắn để bắt đầu vì bạn không thể xử lý dữ liệu lớn (big data) trừ khi bạn có kinh nghiệm với dữ liệu nhỏ. Các công cụ bạn sẽ học trong phần lớn cuốn sách này có thể dễ dàng xử lý row trăm megabyte dữ liệu, và với một chút cẩn thận, bạn thường có thể dùng chúng để làm việc với vài gigabyte dữ liệu. Chúng tôi cũng sẽ chỉ cho bạn cách lấy dữ liệu từ database và file parquet, cả hai thường được dùng để lưu trữ dữ liệu lớn. Bạn không nhất thiết phải làm việc với toàn bộ tập dữ liệu, nhưng đó không phải vấn đề vì bạn chỉ cần một tập con hoặc mẫu con để trả lời câu hỏi mà bạn quan tâm.
Nếu bạn thường xuyên làm việc với dữ liệu lớn hơn (10–100 GB chẳng hạn), chúng tôi khuyến nghị tìm hiểu thêm về data.table. Chúng tôi không dạy nó ở đây vì nó sử dụng giao diện khác với tidyverse và yêu cầu bạn học một số quy ước khác nhau. Tuy nhiên, nó nhanh đến kinh ngạc, và lợi ích về hiệu suất xứng đáng để đầu tư thời gian học nếu bạn đang làm việc với dữ liệu lớn.
Python, Julia, và những ngôn ngữ khác
Trong cuốn sách này, bạn sẽ không học bất cứ điều gì về Python, Julia, hay bất kỳ ngôn ngữ lập trình nào khác hữu ích cho khoa học dữ liệu. Điều này không phải vì chúng tôi nghĩ những công cụ đó không tốt. Chúng rất tốt! Và trong thực tế, hầu hết các nhóm khoa học dữ liệu sử dụng kết hợp nhiều ngôn ngữ, thường ít nhất là R và Python. Nhưng chúng tôi tin chắc rằng tốt nhất là thành thạo một công cụ tại một thời điểm, và R là nơi tuyệt vời để bắt đầu.
Điều kiện tiên quyết
Chúng tôi đã đưa ra một số giả định về những gì bạn đã biết để tận dụng tốt nhất cuốn sách này. Bạn nên có kiến thức số học cơ bản, và sẽ hữu ích nếu bạn đã có chút kinh nghiệm lập trình. Nếu bạn chưa bao giờ lập trình, bạn có thể thấy Hands on Programming with R của Garrett là một tài liệu bổ trợ quý giá cho cuốn sách này.
Bạn cần bốn thứ để chạy mã trong cuốn sách này: R, RStudio, một bộ sưu tập các package R gọi là tidyverse, và một số package khác. Gói mở rộng (package) là đơn vị cơ bản của mã R có tính tái lập. Chúng bao gồm các function có thể tái sử dụng, tài liệu mô tả cách sử dụng chúng, và dữ liệu mẫu.
R
Để tải R, hãy truy cập CRAN, mạng lưu trữ R toàn diện (comprehensive R archive network), https://cloud.r-project.org. Một phiên bản chính mới của R được phát hành mỗi năm một lần, và có 2-3 bản cập nhật phụ mỗi năm. Nên cập nhật thường xuyên. Việc nâng cấp có thể hơi phiền phức, đặc biệt với các phiên bản chính yêu cầu bạn cài đặt lại tất cả các package, nhưng trì hoãn chỉ làm mọi thứ tệ hơn. Chúng tôi khuyến nghị R 4.2.0 trở lên cho cuốn sách này.
RStudio
RStudio là một environment phát triển tích hợp (IDE) cho lập trình R, bạn có thể tải từ https://posit.co/download/rstudio-desktop/. RStudio được cập nhật vài lần mỗi năm, và nó sẽ tự động thông báo cho bạn khi có phiên bản mới, vì vậy không cần phải kiểm tra lại. Nên nâng cấp thường xuyên để tận dụng các tính năng mới nhất và tốt nhất. Cho cuốn sách này, hãy đảm bảo bạn có ít nhất RStudio 2022.02.0.
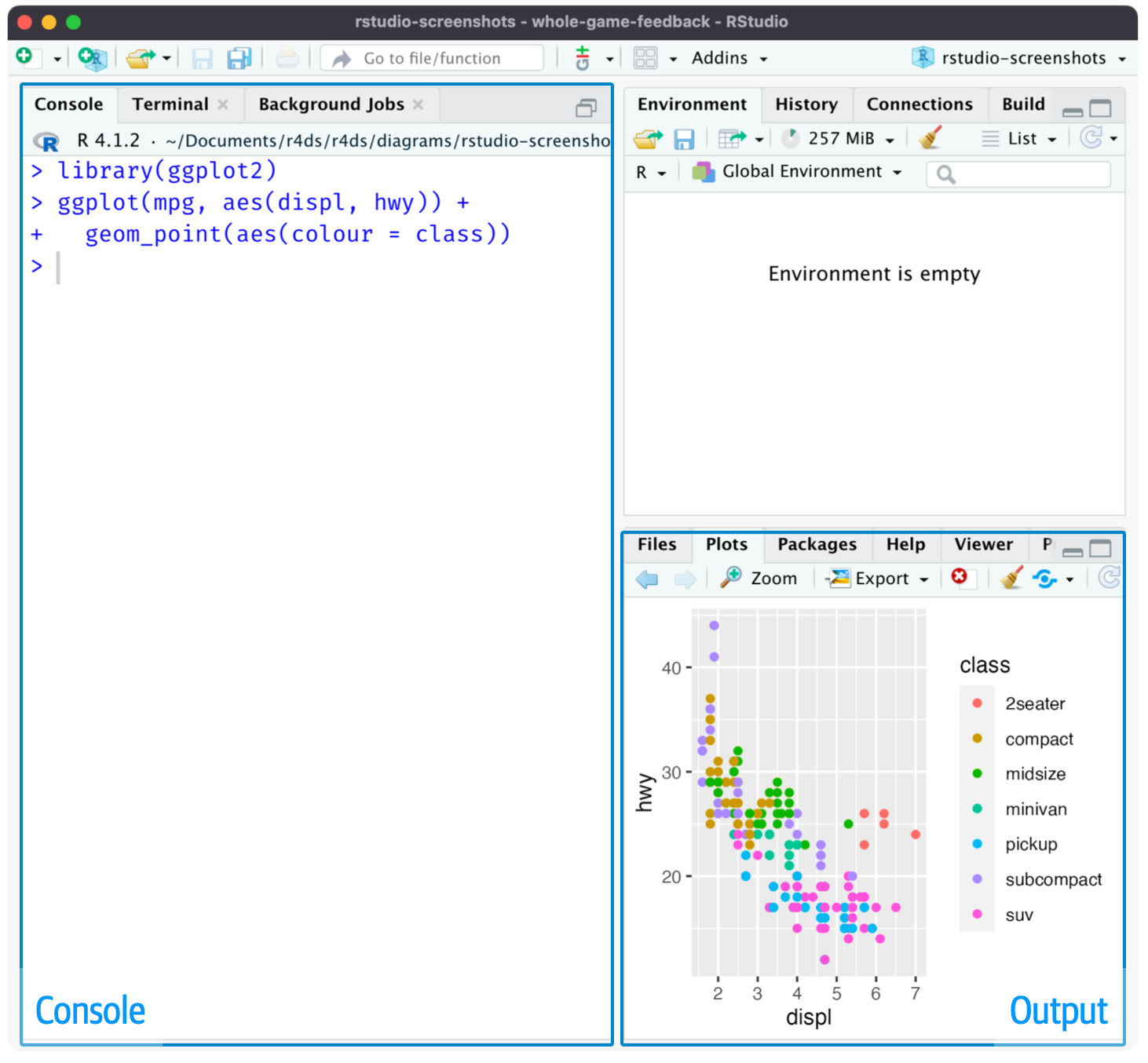
Khi bạn khởi động RStudio, Hình 2, bạn sẽ thấy hai vùng chính trong giao diện: console (console pane) và bảng đầu ra (output pane). Hiện tại, tất cả những gì bạn cần biết là bạn gõ mã R vào console và nhấn enter để chạy. Bạn sẽ tìm hiểu thêm khi chúng ta tiếp tục!1
Tidyverse
Bạn cũng cần cài đặt một số package R. Một package (package) R là một bộ sưu tập các function, dữ liệu, và tài liệu mở rộng khả năng của base R (Base R là tập hợp các function và công cụ cốt lõi được cài đặt sẵn mặc định trong ngôn ngữ lập trình R mà không cần phải tải thêm bất kỳ package nào khác). Sử dụng package là chìa khóa để sử dụng R thành công. Phần lớn các package bạn sẽ học trong cuốn sách này thuộc về cái gọi là tidyverse. Tất cả các package trong tidyverse chia sẻ một triết lý chung về dữ liệu và lập trình R, và được thiết kế để hoạt động cùng nhau.
Bạn có thể cài đặt toàn bộ tidyverse bằng một dòng mã:
install.packages("tidyverse")Trên máy tính của bạn, gõ dòng mã đó vào console, rồi nhấn enter để chạy. R sẽ tải các package từ CRAN và cài đặt chúng trên máy tính của bạn.
Bạn sẽ không thể sử dụng các function, đối tượng, hay file trợ giúp trong một package cho đến khi bạn tải nó bằng library(). Sau khi đã cài đặt một package, bạn có thể tải nó bằng function library():
library(tidyverse)
#> ── Attaching core tidyverse packages ───────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.2.0 ✔ readr 2.2.0
#> ✔ forcats 1.0.1 ✔ stringr 1.6.0
#> ✔ ggplot2 4.0.2 ✔ tibble 3.3.1
#> ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
#> ✔ purrr 1.2.1
#> ── Conflicts ─────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsĐiều này cho bạn biết rằng tidyverse tải chín package: dplyr, forcats, ggplot2, lubridate, purrr, readr, stringr, tibble, tidyr. Chúng được coi là lõi của tidyverse vì bạn sẽ sử dụng chúng trong hầu hết mọi phân tích.
Các package trong tidyverse thay đổi khá thường xuyên. Bạn có thể kiểm tra xem có bản cập nhật nào không bằng cách chạy tidyverse_update().
Các package khác
Có nhiều package xuất sắc khác không thuộc tidyverse vì chúng giải quyết vấn đề trong lĩnh vực khác hoặc được thiết kế với bộ nguyên tắc cơ bản khác. Điều này không làm chúng tốt hơn hay tệ hơn; nó chỉ làm chúng khác biệt. Nói cách khác, phần bổ sung cho tidyverse không phải là messyverse mà là nhiều vũ trụ khác của các package liên quan. Khi bạn giải quyết thêm nhiều dự án khoa học dữ liệu với R, bạn sẽ học các package mới và cách tư duy mới về dữ liệu.
Chúng tôi sẽ sử dụng nhiều package ngoài tidyverse trong cuốn sách này. Ví dụ, chúng tôi sẽ sử dụng các package sau đây vì chúng cung cấp các tập dữ liệu thú vị để chúng ta làm việc trong quá trình học R:
install.packages(
c("arrow", "babynames", "curl", "duckdb", "gapminder",
"ggrepel", "ggridges", "ggthemes", "hexbin", "janitor", "Lahman",
"leaflet", "maps", "nycflights13", "openxlsx", "palmerpenguins",
"repurrrsive", "tidymodels", "writexl")
)Chúng tôi cũng sẽ sử dụng một số package khác cho các ví dụ đơn lẻ. Bạn không cần cài đặt chúng ngay bây giờ, chỉ cần nhớ rằng bất cứ khi nào bạn thấy lỗi như thế này:
Bạn cần chạy install.packages("ggrepel") để cài đặt package đó.
Chạy mã R
Phần trước đã cho bạn thấy một số ví dụ về việc chạy mã R. Mã trong cuốn sách trông như thế này:
1 + 2
#> [1] 3Nếu bạn chạy cùng đoạn mã trong console của mình, nó sẽ trông như thế này:
> 1 + 2
[1] 3Có hai khác biệt chính. Trong console của bạn, bạn gõ sau dấu >, gọi là dấu nhắc (prompt); chúng tôi không hiển thị dấu nhắc trong sách. Trong sách, đầu ra được comment bằng #>; trong console của bạn, nó xuất hiện trực tiếp sau mã của bạn. Hai khác biệt này có nghĩa là nếu bạn đang làm việc với phiên bản điện tử của cuốn sách, bạn có thể dễ dàng sao chép mã từ sách và dán vào console.
Xuyên suốt cuốn sách, chúng tôi sử dụng một bộ quy ước nhất quán để tham chiếu đến mã:
Function được hiển thị bằng phông chữ mã và theo sau bởi dấu ngoặc đơn, như
sum()hoặcmean().Các đối tượng R khác (như dữ liệu hoặc argument của hàm) được hiển thị bằng phông chữ mã, không có dấu ngoặc đơn, như
flightshoặcx.Đôi khi, để làm rõ một đối tượng đến từ package nào, chúng tôi sẽ dùng tên package theo sau bởi hai dấu hai chấm, như
dplyr::mutate()hoặcnycflights13::flights. Đây cũng là mã R hợp lệ.
Lời cảm ơn
Cuốn sách này không chỉ là sản phẩm của Hadley, Mine, và Garrett mà là kết quả của nhiều cuộc trò chuyện (trực tiếp và trực tuyến) mà chúng tôi đã có với nhiều người trong cộng đồng R. Chúng tôi vô cùng biết ơn tất cả các cuộc trò chuyện mà chúng tôi đã có với các bạn; cảm ơn rất nhiều!
Cuốn sách này được viết công khai, và nhiều người đã đóng góp qua pull request. Xin gửi lời cảm ơn đặc biệt đến tất cả 259 bạn đã đóng góp cải tiến qua GitHub pull request (theo thứ tự bảng chữ cái theo tên người dùng): @a-rosenberg, Tim Becker (@a2800276), Abinash Satapathy (@Abinashbunty), Adam Gruer (@adam-gruer), adi pradhan (@adidoit), A. s. (@Adrianzo), Aep Hidyatuloh (@aephidayatuloh), Andrea Gilardi (@agila5), Ajay Deonarine (@ajay-d), @AlanFeder, Daihe Sui (@alansuidaihe), @alberto-agudo, @AlbertRapp, @aleloi, pete (@alonzi), Alex (@ALShum), Andrew M. (@amacfarland), Andrew Landgraf (@andland), @andyhuynh92, Angela Li (@angela-li), Antti Rask (@AnttiRask), LOU Xun (@aquarhead), @ariespirgel, @august-18, Michael Henry (@aviast), Azza Ahmed (@azzaea), Steven Moran (@bambooforest), Brian G. Barkley (@BarkleyBG), Mara Averick (@batpigandme), Oluwafemi OYEDELE (@BB1464), Brent Brewington (@bbrewington), Bill Behrman (@behrman), Ben Herbertson (@benherbertson), Ben Marwick (@benmarwick), Ben Steinberg (@bensteinberg), Benjamin Yeh (@bentyeh), Betul Turkoglu (@betulturkoglu), Brandon Greenwell (@bgreenwell), Bianca Peterson (@BinxiePeterson), Birger Niklas (@BirgerNi), Brett Klamer (@bklamer), @boardtc, Christian (@c-hoh), Caddy (@caddycarine), Camille V Leonard (@camillevleonard), @canovasjm, Cedric Batailler (@cedricbatailler), Christina Wei (@christina-wei), Christian Mongeau (@chrMongeau), Cooper Morris (@coopermor), Colin Gillespie (@csgillespie), Rademeyer Vermaak (@csrvermaak), Chloe Thierstein (@cthierst), Chris Saunders (@ctsa), Abhinav Singh (@curious-abhinav), Curtis Alexander (@curtisalexander), Christian G. Warden (@cwarden), Charlotte Wickham (@cwickham), Kenny Darrell (@darrkj), David Kane (@davidkane9), David (@davidrsch), David Rubinger (@davidrubinger), David Clark (@DDClark), Derwin McGeary (@derwinmcgeary), Daniel Gromer (@dgromer), @Divider85, @djbirke, Danielle Navarro (@djnavarro), Russell Shean (@DOH-RPS1303), Zhuoer Dong (@dongzhuoer), Devin Pastoor (@dpastoor), @DSGeoff, Devarshi Thakkar (@dthakkar09), Julian During (@duju211), Dylan Cashman (@dylancashman), Dirk Eddelbuettel (@eddelbuettel), Edwin Thoen (@EdwinTh), Ahmed El-Gabbas (@elgabbas), Henry Webel (@enryH), Ercan Karadas (@ercan7), Eric Kitaif (@EricKit), Eric Watt (@ericwatt), Erik Erhardt (@erikerhardt), Etienne B. Racine (@etiennebr), Everett Robinson (@evjrob), @fellennert, Flemming Miguel (@flemmingmiguel), Floris Vanderhaeghe (@florisvdh), @funkybluehen, @gabrivera, Garrick Aden-Buie (@gadenbuie), Peter Ganong (@ganong123), Gerome Meyer (@GeroVanMi), Gleb Ebert (@gl-eb), Josh Goldberg (@GoldbergData), bahadir cankardes (@gridgrad), Gustav W Delius (@gustavdelius), Hao Chen (@hao-trivago), Harris McGehee (@harrismcgehee), @hendrikweisser, Hengni Cai (@hengnicai), Iain (@Iain-S), Ian Sealy (@iansealy), Ian Lyttle (@ijlyttle), Ivan Krukov (@ivan-krukov), Jacob Kaplan (@jacobkap), Jazz Weisman (@jazzlw), John Blischak (@jdblischak), John D. Storey (@jdstorey), Gregory Jefferis (@jefferis), Jeffrey Stevens (@JeffreyRStevens), 蒋雨蒙 (@JeldorPKU), Jennifer (Jenny) Bryan (@jennybc), Jen Ren (@jenren), Jeroen Janssens (@jeroenjanssens), @jeromecholewa, Janet Wesner (@jilmun), Jim Hester (@jimhester), JJ Chen (@jjchern), Jacek Kolacz (@jkolacz), Joanne Jang (@joannejang), @johannes4998, John Sears (@johnsears), @jonathanflint, Jon Calder (@jonmcalder), Jonathan Page (@jonpage), Jon Harmon (@jonthegeek), JooYoung Seo (@jooyoungseo), Justinas Petuchovas (@jpetuchovas), Jordan (@jrdnbradford), Jeffrey Arnold (@jrnold), Jose Roberto Ayala Solares (@jroberayalas), Joyce Robbins (@jtr13), @juandering, Julia Stewart Lowndes (@jules32), Sonja (@kaetschap), Kara Woo (@karawoo), Katrin Leinweber (@katrinleinweber), Karandeep Singh (@kdpsingh), Kevin Perese (@kevinxperese), Kevin Ferris (@kferris10), Kirill Sevastyanenko (@kirillseva), Jonathan Kitt (@KittJonathan), @koalabearski, Kirill Müller (@krlmlr), Rafał Kucharski (@kucharsky), Kevin Wright (@kwstat), Noah Landesberg (@landesbergn), Lawrence Wu (@lawwu), @lindbrook, Luke W Johnston (@lwjohnst86), Kara de la Marck (@MarckK), Kunal Marwaha (@marwahaha), Matan Hakim (@matanhakim), Matthias Liew (@MatthiasLiew), Matt Wittbrodt (@MattWittbrodt), Mauro Lepore (@maurolepore), Mark Beveridge (@mbeveridge), @mcewenkhundi, mcsnowface, PhD (@mcsnowface), Matt Herman (@mfherman), Michael Boerman (@michaelboerman), Mitsuo Shiota (@mitsuoxv), Matthew Hendrickson (@mjhendrickson), @MJMarshall, Misty Knight-Finley (@mkfin7), Mohammed Hamdy (@mmhamdy), Maxim Nazarov (@mnazarov), Maria Paula Caldas (@mpaulacaldas), Mustafa Ascha (@mustafaascha), Nelson Areal (@nareal), Nate Olson (@nate-d-olson), Nathanael (@nateaff), @nattalides, Ned Western (@NedJWestern), Nick Clark (@nickclark1000), @nickelas, Nirmal Patel (@nirmalpatel), Nischal Shrestha (@nischalshrestha), Nicholas Tierney (@njtierney), Jakub Nowosad (@Nowosad), Nick Pullen (@nstjhp), @olivier6088, Olivier Cailloux (@oliviercailloux), Robin Penfold (@p0bs), Pablo E. Garcia (@pabloedug), Paul Adamson (@padamson), Penelope Y (@penelopeysm), Peter Hurford (@peterhurford), Peter Baumgartner (@petzi53), Patrick Kennedy (@pkq), Pooya Taherkhani (@pooyataher), Y. Yu (@PursuitOfDataScience), Radu Grosu (@radugrosu), Ranae Dietzel (@Ranae), Ralph Straumann (@rastrau), Rayna M Harris (@raynamharris), @ReeceGoding, Robin Gertenbach (@rgertenbach), Jajo (@RIngyao), Riva Quiroga (@rivaquiroga), Richard Knight (@RJHKnight), Richard Zijdeman (@rlzijdeman), @robertchu03, Robin Kohrs (@RobinKohrs), Robin (@Robinlovelace), Emily Robinson (@robinsones), Rob Tenorio (@robtenorio), Rod Mazloomi (@RodAli), Rohan Alexander (@RohanAlexander), Romero Morais (@RomeroBarata), Albert Y. Kim (@rudeboybert), Saghir (@saghirb), Hojjat Salmasian (@salmasian), Jonas (@sauercrowd), Vebash Naidoo (@sciencificity), Seamus McKinsey (@seamus-mckinsey), @seanpwilliams, Luke Smith (@seasmith), Matthew Sedaghatfar (@sedaghatfar), Sebastian Kraus (@sekR4), Sam Firke (@sfirke), Shannon Ellis (@ShanEllis), @shoili, Christian Heinrich (@Shurakai), S’busiso Mkhondwane (@sibusiso16), SM Raiyyan (@sm-raiyyan), Jakob Krigovsky (@sonicdoe), Stephan Koenig (@stephan-koenig), Stephen Balogun (@stephenbalogun), Steven M. Mortimer (@StevenMMortimer), Stéphane Guillou (@stragu), Sulgi Kim (@sulgik), Sergiusz Bleja (@svenski), Tal Galili (@talgalili), Alec Fisher (@Taurenamo), Todd Gerarden (@tgerarden), Tom Godfrey (@thomasggodfrey), Tim Broderick (@timbroderick), Tim Waterhouse (@timwaterhouse), TJ Mahr (@tjmahr), Thomas Klebel (@tklebel), Tom Prior (@tomjamesprior), Terence Teo (@tteo), @twgardner2, Ulrik Lyngs (@ulyngs), Shinya Uryu (@uribo), Martin Van der Linden (@vanderlindenma), Walter Somerville (@waltersom), @werkstattcodes, Will Beasley (@wibeasley), Yihui Xie (@yihui), Yiming (Paul) Li (@yimingli), @yingxingwu, Hiroaki Yutani (@yutannihilation), Yu Yu Aung (@yuyu-aung), Zach Bogart (@zachbogart), @zeal626, Zeki Akyol (@zekiakyol).
Thông tin xuất bản
Phiên bản trực tuyến của cuốn sách này có tại https://r4ds.hadley.nz. Nó sẽ tiếp tục được cập nhật giữa các lần tái bản sách in. Mã nguồn của cuốn sách có tại https://github.com/hadley/r4ds. Cuốn sách được hỗ trợ bởi Quarto, giúp dễ dàng viết sách kết hợp văn bản và mã thực thi.
Nếu bạn muốn có cái nhìn tổng quan toàn diện về tất cả các tính năng của RStudio, xem Hướng dẫn Sử dụng RStudio tại https://docs.posit.co/ide/user.↩︎