5 Chỉnh trang dữ liệu
5.1 Giới thiệu
“Mọi gia đình hạnh phúc đều giống nhau; mỗi gia đình bất hạnh thì bất hạnh theo cách riêng của mình.”
— Leo Tolstoy
“Mọi tập tidy data đều giống nhau, nhưng mỗi tập dữ liệu lộn xộn thì lộn xộn theo cách riêng của nó.”
— Hadley Wickham
Trong chương này, bạn sẽ học một cách nhất quán để tổ chức dữ liệu trong R bằng một hệ thống gọi là tidy data (tidy data). Việc đưa dữ liệu vào định dạng này đòi hỏi một chút công sức ban đầu, nhưng công sức đó sẽ được đền đáp về lâu dài. Khi bạn đã có tidy data và các công cụ gọn gàng được cung cấp bởi các package trong tidyverse, bạn sẽ tốn ít thời gian hơn nhiều để chuyển đổi dữ liệu từ dạng biểu diễn này sang dạng khác, cho phép bạn dành nhiều thời gian hơn cho những câu hỏi về dữ liệu mà bạn quan tâm.
Trong chương này, đầu tiên bạn sẽ tìm hiểu định nghĩa của tidy data và xem nó được áp dụng vào một tập dữ liệu đồ chơi đơn giản. Sau đó chúng ta sẽ đi sâu vào công cụ chính mà bạn sẽ sử dụng để chỉnh trang dữ liệu: xoay (pivoting). Xoay cho phép bạn thay đổi hình dạng dữ liệu mà không thay đổi bất kỳ giá trị nào.
5.1.1 Điều kiện tiên quyết
Trong chương này, chúng ta sẽ tập trung vào tidyr, một package cung cấp row loạt công cụ giúp chỉnh trang các tập dữ liệu lộn xộn. tidyr là một thành viên của tidyverse cốt lõi.
Từ chương này trở đi, chúng ta sẽ ẩn thông báo tải từ library(tidyverse).
5.2 Dữ liệu gọn gàng
Bạn có thể biểu diễn cùng một dữ liệu cơ bản theo nhiều cách khác nhau. Ví dụ bên dưới cho thấy cùng một dữ liệu được tổ chức theo ba cách khác nhau. Mỗi tập dữ liệu đều hiển thị cùng các giá trị (value) của bốn biến (variable): country, year, population, và số ca cases được ghi nhận của TB (bệnh lao), nhưng mỗi tập dữ liệu tổ chức các giá trị theo cách khác nhau.
table1
#> # A tibble: 6 × 4
#> country year cases population
#> <chr> <dbl> <dbl> <dbl>
#> 1 Afghanistan 1999 745 19987071
#> 2 Afghanistan 2000 2666 20595360
#> 3 Brazil 1999 37737 172006362
#> 4 Brazil 2000 80488 174504898
#> 5 China 1999 212258 1272915272
#> 6 China 2000 213766 1280428583
table2
#> # A tibble: 12 × 4
#> country year type count
#> <chr> <dbl> <chr> <dbl>
#> 1 Afghanistan 1999 cases 745
#> 2 Afghanistan 1999 population 19987071
#> 3 Afghanistan 2000 cases 2666
#> 4 Afghanistan 2000 population 20595360
#> 5 Brazil 1999 cases 37737
#> 6 Brazil 1999 population 172006362
#> # ℹ 6 more rows
table3
#> # A tibble: 6 × 3
#> country year rate
#> <chr> <dbl> <chr>
#> 1 Afghanistan 1999 745/19987071
#> 2 Afghanistan 2000 2666/20595360
#> 3 Brazil 1999 37737/172006362
#> 4 Brazil 2000 80488/174504898
#> 5 China 1999 212258/1272915272
#> 6 China 2000 213766/1280428583Đây đều là các cách biểu diễn cùng một dữ liệu cơ bản, nhưng chúng không dễ sử dụng như nhau. Một trong số đó, table1, sẽ dễ làm việc hơn nhiều trong tidyverse vì nó là tidy data.
Có ba quy tắc liên quan với nhau tạo nên một tập tidy data:
- Mỗi biến là một column (column); mỗi column là một biến.
- Mỗi quan sát (observation) là một row (row); mỗi row là một quan sát.
- Mỗi giá trị là một ô; mỗi ô là một giá trị duy nhất.
Hình 5.1 minh họa các quy tắc này một cách trực quan.

Tại sao phải đảm bảo dữ liệu của bạn là gọn gàng? Có hai lợi thế chính:
Có một lợi thế chung khi chọn một cách nhất quán để lưu trữ dữ liệu. Nếu bạn có một cấu trúc dữ liệu nhất quán, sẽ dễ dàng hơn để học các công cụ làm việc với nó vì chúng có sự đồng nhất cơ bản.
Có một lợi thế cụ thể khi đặt các biến vào các column vì nó cho phép bản chất vector hóa của R tỏa sáng. Như bạn đã học trong Phần 3.3.1 và Phần 3.5.2, hầu hết các function tích hợp sẵn trong R đều hoạt động với các vector giá trị. Điều đó làm cho việc biến đổi tidy data trở nên đặc biệt tự nhiên.
dplyr, ggplot2, và tất cả các package khác trong tidyverse đều được thiết kế để hoạt động với tidy data. Dưới đây là một vài ví dụ nhỏ cho thấy cách bạn có thể làm việc với table1.
# Tính tỷ lệ trên 10.000 người
table1 |>
mutate(rate = cases / population * 10000)
#> # A tibble: 6 × 5
#> country year cases population rate
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 Afghanistan 1999 745 19987071 0.373
#> 2 Afghanistan 2000 2666 20595360 1.29
#> 3 Brazil 1999 37737 172006362 2.19
#> 4 Brazil 2000 80488 174504898 4.61
#> 5 China 1999 212258 1272915272 1.67
#> 6 China 2000 213766 1280428583 1.67
# Tính tổng số ca bệnh theo năm
table1 |>
group_by(year) |>
summarize(total_cases = sum(cases))
#> # A tibble: 2 × 2
#> year total_cases
#> <dbl> <dbl>
#> 1 1999 250740
#> 2 2000 296920
# Trực quan hóa sự thay đổi theo thời gian
ggplot(table1, aes(x = year, y = cases)) +
geom_line(aes(group = country), color = "grey50") +
geom_point(aes(color = country, shape = country)) +
scale_x_continuous(breaks = c(1999, 2000)) # Các mốc trục x tại 1999 và 2000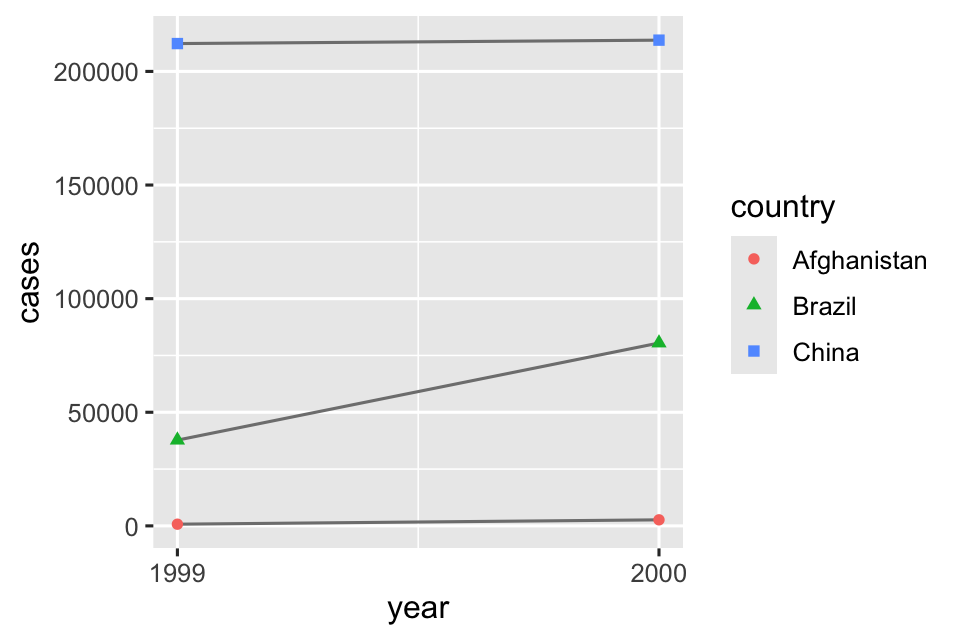
5.2.1 Bài tập
Đối với mỗi bảng mẫu, hãy mô tả mỗi quan sát và mỗi column đại diện cho điều gì.
-
Hãy phác thảo workflow bạn sẽ sử dụng để tính
ratechotable2vàtable3. Bạn sẽ cần thực hiện bốn thao tác:- Trích xuất số ca TB theo từng quốc gia theo từng năm.
- Trích xuất dân số tương ứng theo từng quốc gia theo từng năm.
- Chia số ca bệnh cho dân số, và nhân với 10000.
- Lưu lại vào vị trí thích hợp.
Bạn chưa học tất cả các function cần thiết để thực sự thực hiện các thao tác này, nhưng bạn vẫn nên có thể suy nghĩ về các phép biến đổi mà bạn cần.
5.3 Kéo dài dữ liệu
Các nguyên tắc của tidy data có thể hiển nhiên đến mức bạn tự hỏi liệu bạn có bao giờ gặp một tập dữ liệu không gọn gàng không. Tuy nhiên, thật không may, hầu hết dữ liệu thực tế đều không gọn gàng. Có hai lý do chính:
Dữ liệu thường được tổ chức để phục vụ một mục tiêu khác ngoài phân tích. Ví dụ, việc cấu trúc dữ liệu để giúp nhập liệu dễ dàng, chứ không phải phân tích, là rất phổ biến.
Hầu hết mọi người không quen thuộc với các nguyên tắc của tidy data, và rất khó để tự suy ra chúng trừ khi bạn dành nhiều thời gian làm việc với dữ liệu.
Điều này có nghĩa là hầu hết các phân tích thực tế sẽ đòi hỏi ít nhất một chút chỉnh trang. Bạn sẽ bắt đầu bằng cách tìm hiểu các biến và quan sát cơ bản là gì. Đôi khi điều này dễ dàng; lúc khác bạn sẽ cần tham khảo ý kiến của những người tạo ra dữ liệu ban đầu. Tiếp theo, bạn sẽ xoay dữ liệu thành dạng gọn gàng, với các biến trong các column và các quan sát trong các row.
tidyr cung cấp hai function để xoay dữ liệu: pivot_longer() và pivot_wider(). Chúng ta sẽ bắt đầu với pivot_longer() trước vì đây là trường hợp phổ biến nhất. Hãy cùng đi vào một số ví dụ.
5.3.1 Dữ liệu trong tên column
Tập dữ liệu billboard ghi lại thứ hạng billboard của các bài hát trong năm 2000:
billboard
#> # A tibble: 317 × 79
#> artist track date.entered wk1 wk2 wk3 wk4 wk5
#> <chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 2 Pac Baby Don't Cry (Ke… 2000-02-26 87 82 72 77 87
#> 2 2Ge+her The Hardest Part O… 2000-09-02 91 87 92 NA NA
#> 3 3 Doors Down Kryptonite 2000-04-08 81 70 68 67 66
#> 4 3 Doors Down Loser 2000-10-21 76 76 72 69 67
#> 5 504 Boyz Wobble Wobble 2000-04-15 57 34 25 17 17
#> 6 98^0 Give Me Just One N… 2000-08-19 51 39 34 26 26
#> # ℹ 311 more rows
#> # ℹ 71 more variables: wk6 <dbl>, wk7 <dbl>, wk8 <dbl>, wk9 <dbl>, …Trong tập dữ liệu này, mỗi quan sát là một bài hát. Ba column đầu tiên (artist, track và date.entered) là các biến mô tả bài hát. Sau đó chúng ta có 76 column (wk1-wk76) mô tả thứ hạng của bài hát trong mỗi tuần1. Ở đây, tên column là một biến (week - tuần) và các giá trị trong ô là một biến khác (rank - thứ hạng).
Để chỉnh trang dữ liệu này, chúng ta sẽ sử dụng pivot_longer():
billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank"
)
#> # A tibble: 24,092 × 5
#> artist track date.entered week rank
#> <chr> <chr> <date> <chr> <dbl>
#> 1 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk1 87
#> 2 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk2 82
#> 3 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk3 72
#> 4 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk4 77
#> 5 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk5 87
#> 6 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk6 94
#> 7 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk7 99
#> 8 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk8 NA
#> 9 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk9 NA
#> 10 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk10 NA
#> # ℹ 24,082 more rowsSau dữ liệu, có ba argument quan trọng:
-
colschỉ định column nào cần được xoay, tức là column nào không phải là biến. Đối số này sử dụng cùng cú pháp vớiselect()nên ở đây chúng ta có thể dùng!c(artist, track, date.entered)hoặcstarts_with("wk"). -
names_tođặt tên cho biến được lưu trong tên column, chúng ta đặt tên biến đó làweek. -
values_tođặt tên cho biến được lưu trong giá trị của các ô, chúng ta đặt tên biến đó làrank.
Lưu ý rằng trong mã, "week" và "rank" được đặt trong dấu ngoặc kép vì đó là các biến mới chúng ta đang tạo, chúng chưa tồn tại trong dữ liệu khi chúng ta chạy lệnh pivot_longer().
Bây giờ hãy chú ý đến data frame kết quả, dài hơn. Điều gì xảy ra nếu một bài hát nằm trong top 100 ít hơn 76 tuần? Lấy ví dụ bài “Baby Don’t Cry” của 2 Pac. Kết quả ở trên cho thấy nó chỉ nằm trong top 100 trong 7 tuần, và tất cả các tuần còn lại được điền bằng missing value. Những giá trị NA này không thực sự đại diện cho các quan sát chưa biết; chúng bị buộc phải tồn tại bởi cấu trúc của tập dữ liệu2, nên chúng ta có thể yêu cầu pivot_longer() loại bỏ chúng bằng cách đặt values_drop_na = TRUE:
billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank",
values_drop_na = TRUE
)
#> # A tibble: 5,307 × 5
#> artist track date.entered week rank
#> <chr> <chr> <date> <chr> <dbl>
#> 1 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk1 87
#> 2 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk2 82
#> 3 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk3 72
#> 4 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk4 77
#> 5 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk5 87
#> 6 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk6 94
#> # ℹ 5,301 more rowsSố row bây giờ ít hơn nhiều, cho thấy nhiều row chứa NA đã bị loại bỏ.
Bạn cũng có thể tự hỏi điều gì xảy ra nếu một bài hát nằm trong top 100 hơn 76 tuần? Chúng ta không thể biết từ dữ liệu này, nhưng bạn có thể đoán rằng các column bổ sung wk77, wk78, … sẽ được thêm vào tập dữ liệu.
Dữ liệu này giờ đã gọn gàng, nhưng chúng ta có thể làm cho việc tính toán trong tương lai dễ dàng hơn một chút bằng cách chuyển đổi các giá trị của week từ string sang số bằng mutate() và readr::parse_number(). parse_number() là một function tiện lợi sẽ trích xuất số đầu tiên từ một string, bỏ qua tất cả các văn bản khác.
billboard_longer <- billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank",
values_drop_na = TRUE
) |>
mutate(
week = parse_number(week)
)
billboard_longer
#> # A tibble: 5,307 × 5
#> artist track date.entered week rank
#> <chr> <chr> <date> <dbl> <dbl>
#> 1 2 Pac Baby Don't Cry (Keep... 2000-02-26 1 87
#> 2 2 Pac Baby Don't Cry (Keep... 2000-02-26 2 82
#> 3 2 Pac Baby Don't Cry (Keep... 2000-02-26 3 72
#> 4 2 Pac Baby Don't Cry (Keep... 2000-02-26 4 77
#> 5 2 Pac Baby Don't Cry (Keep... 2000-02-26 5 87
#> 6 2 Pac Baby Don't Cry (Keep... 2000-02-26 6 94
#> # ℹ 5,301 more rowsBây giờ tất cả các số tuần đều nằm trong một biến và tất cả các giá trị thứ hạng nằm trong một biến khác, chúng ta đang ở vị trí tốt để visualization cách thứ hạng bài hát thay đổi theo thời gian. Mã được hiển thị bên dưới và kết quả nằm trong Hình 5.2. Chúng ta có thể thấy rằng rất ít bài hát nằm trong top 100 hơn 20 tuần.
billboard_longer |>
ggplot(aes(x = week, y = rank, group = track)) +
geom_line(alpha = 0.25) +
scale_y_reverse()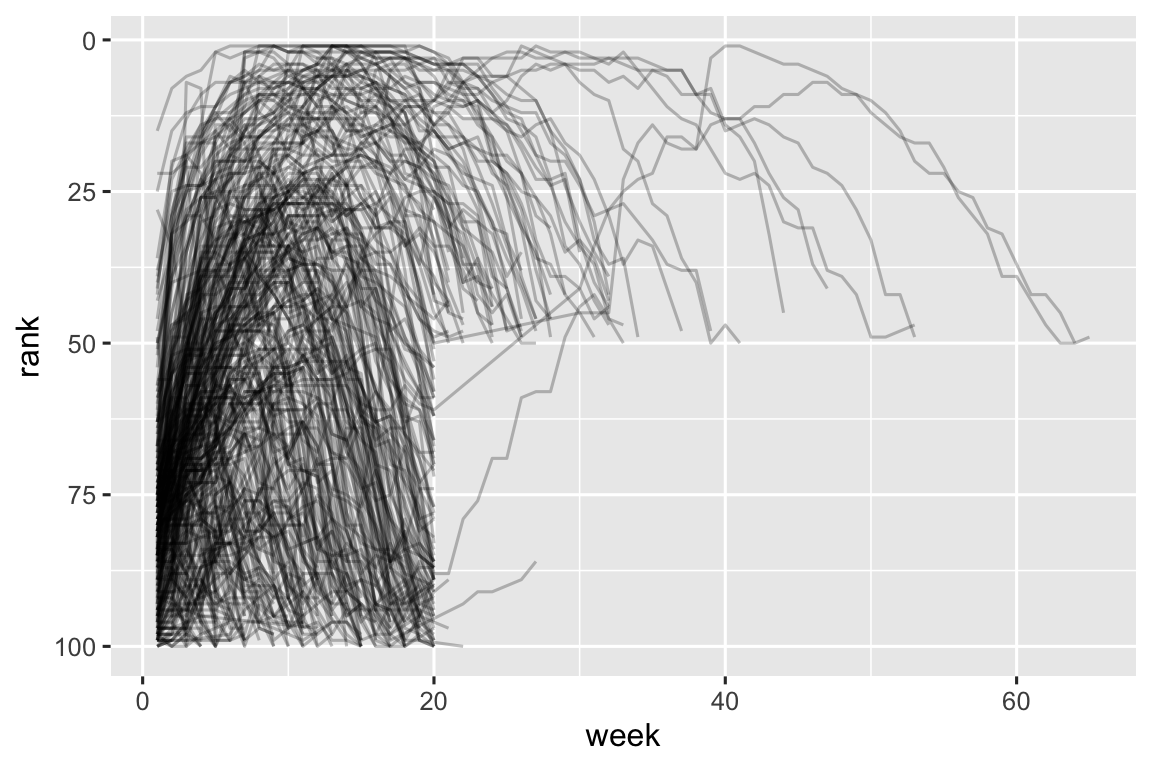
5.3.2 Xoay hoạt động như thế nào?
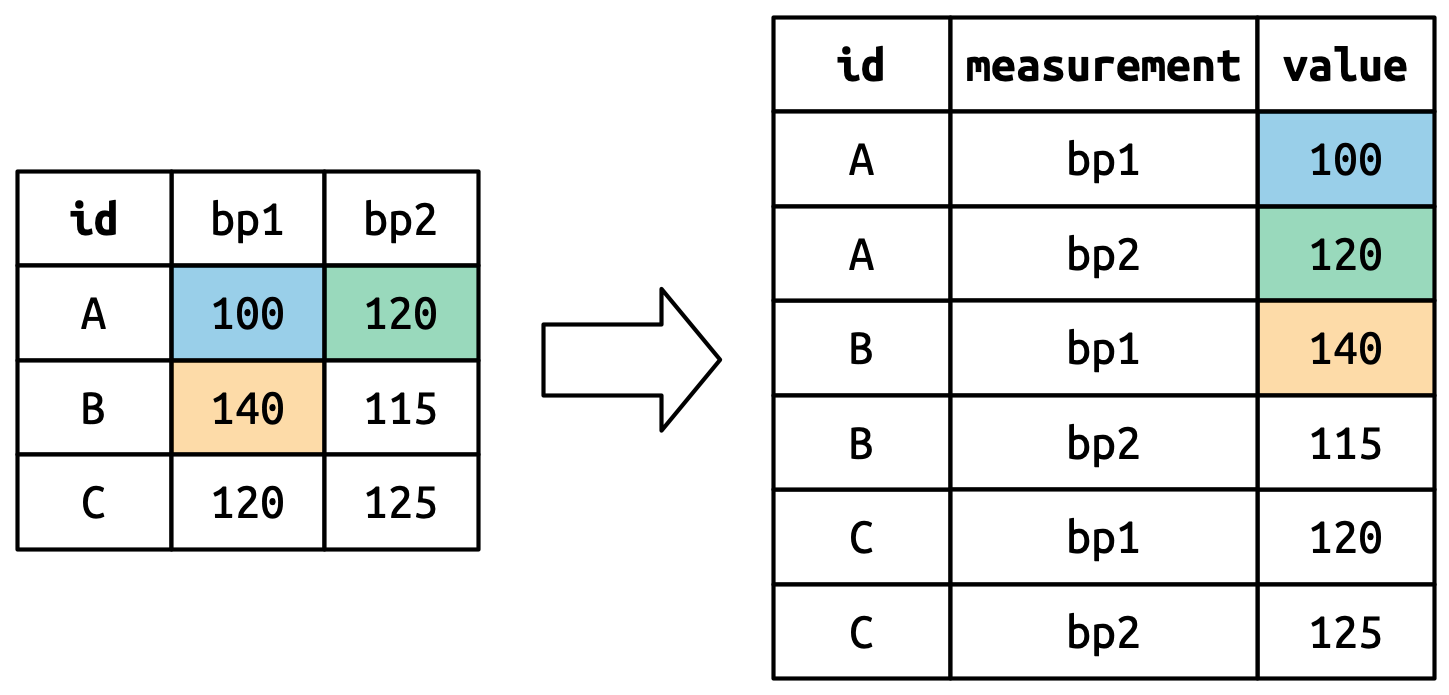
Bây giờ bạn đã thấy cách chúng ta có thể sử dụng xoay để định hình lại dữ liệu, hãy dành chút thời gian để hiểu trực giác về những gì xoay làm với dữ liệu. Hãy bắt đầu với một tập dữ liệu rất đơn giản để dễ thấy điều gì đang xảy ra. Giả sử chúng ta có ba bệnh nhân với id là A, B, và C, và chúng ta thực hiện hai lần đo huyết áp trên mỗi bệnh nhân. Chúng ta sẽ tạo dữ liệu với tribble(), một function tiện lợi để xây dựng các tibble nhỏ bằng tay:
df <- tribble(
~id, ~bp1, ~bp2,
"A", 100, 120,
"B", 140, 115,
"C", 120, 125
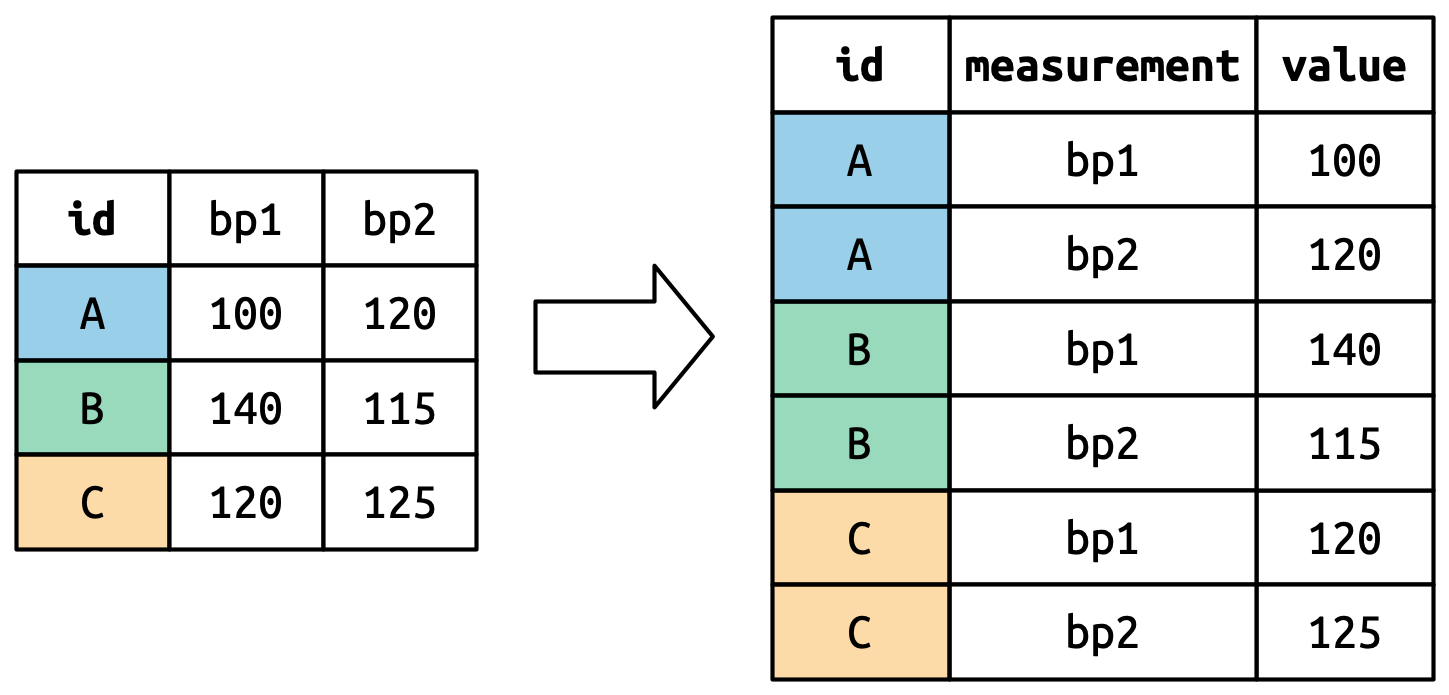
)Chúng ta muốn tập dữ liệu mới có ba biến: id (đã tồn tại), measurement (tên cột), và value (giá trị trong ô). Để đạt được điều này, chúng ta cần xoay df dài hơn:
df |>
pivot_longer(
cols = bp1:bp2,
names_to = "measurement",
values_to = "value"
)
#> # A tibble: 6 × 3
#> id measurement value
#> <chr> <chr> <dbl>
#> 1 A bp1 100
#> 2 A bp2 120
#> 3 B bp1 140
#> 4 B bp2 115
#> 5 C bp1 120
#> 6 C bp2 125Việc định hình lại hoạt động như thế nào? Sẽ dễ hơn nếu chúng ta nghĩ theo từng column. Như minh họa trong Hình 5.3, các giá trị trong một column đã là biến trong tập dữ liệu ban đầu (id) cần được iterate lại, một lần cho mỗi column được xoay.
Tên column trở thành giá trị trong một biến mới, có tên được xác định bởi names_to, như minh họa trong Hình 5.4. Chúng cần được iterate lại một lần cho mỗi row trong tập dữ liệu ban đầu.
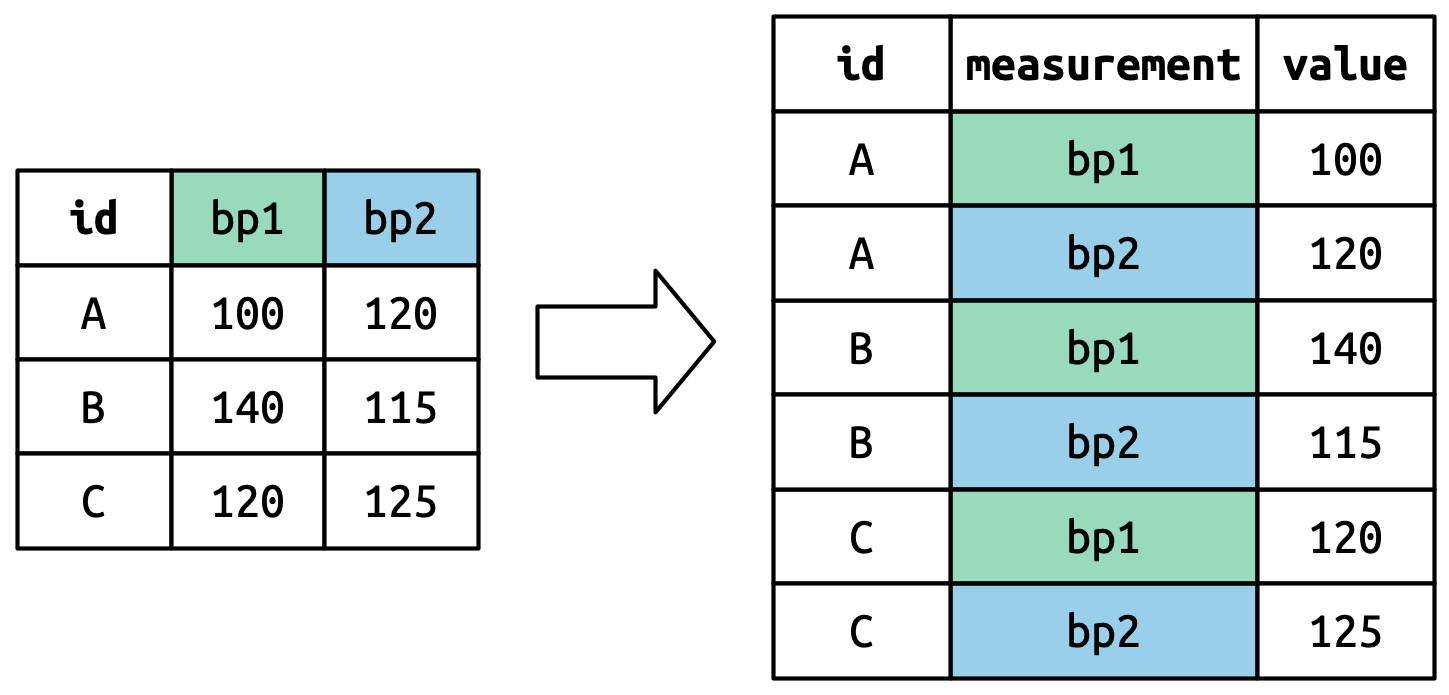
Các giá trị trong ô cũng trở thành giá trị trong một biến mới, với tên được xác định bởi values_to. Chúng được tháo ra theo từng row. Hình 5.5 minh họa quá trình này.
5.3.3 Nhiều biến trong tên cột
Một tình huống thách thức hơn xảy ra khi bạn có nhiều mẩu thông tin được nhồi nhét vào tên column, và bạn muốn lưu trữ chúng trong các biến mới riêng biệt. Ví dụ, hãy xem tập dữ liệu who2, nguồn của table1 và các bảng bạn bè mà bạn đã thấy ở trên:
who2
#> # A tibble: 7,240 × 58
#> country year sp_m_014 sp_m_1524 sp_m_2534 sp_m_3544 sp_m_4554
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 Afghanistan 1980 NA NA NA NA NA
#> 2 Afghanistan 1981 NA NA NA NA NA
#> 3 Afghanistan 1982 NA NA NA NA NA
#> 4 Afghanistan 1983 NA NA NA NA NA
#> 5 Afghanistan 1984 NA NA NA NA NA
#> 6 Afghanistan 1985 NA NA NA NA NA
#> # ℹ 7,234 more rows
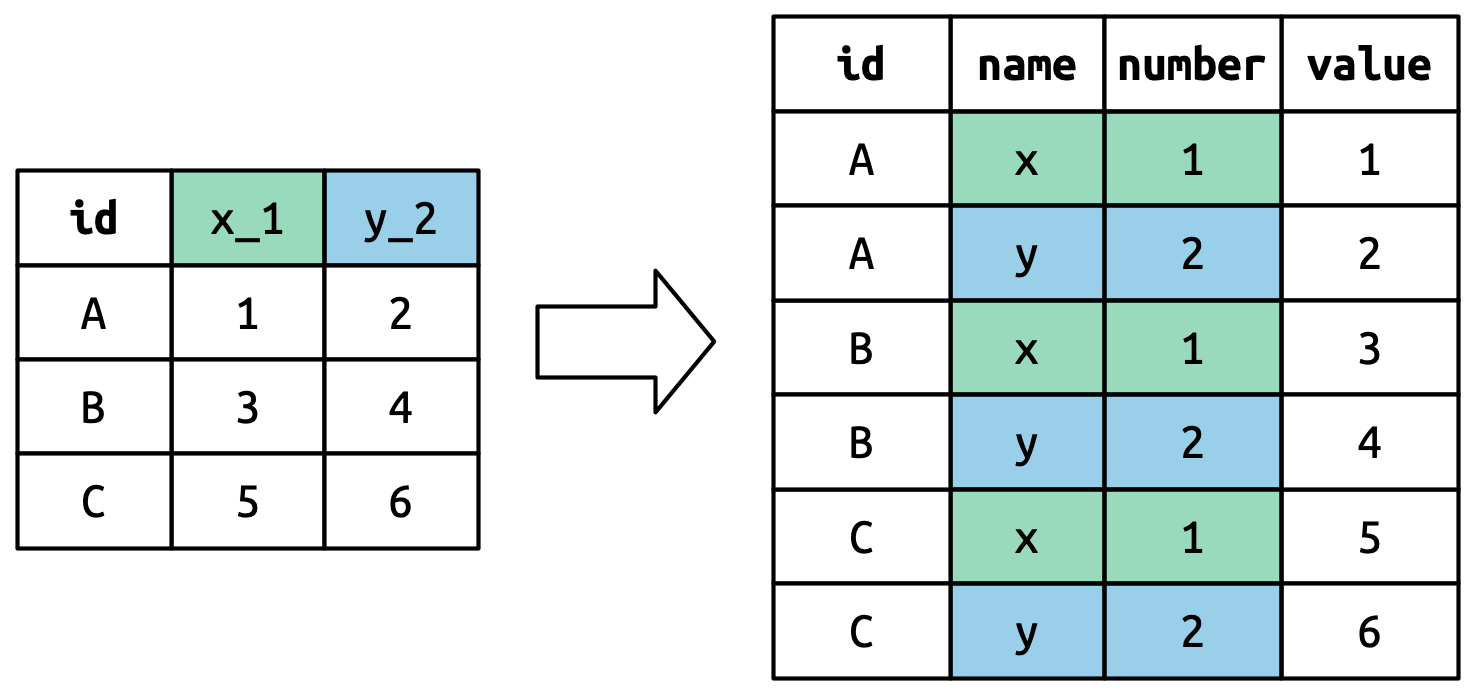
#> # ℹ 51 more variables: sp_m_5564 <dbl>, sp_m_65 <dbl>, sp_f_014 <dbl>, …Tập dữ liệu này, được thu thập bởi Tổ chức Y tế Thế giới, ghi nhận thông tin về chẩn đoán bệnh lao. Có hai column đã là biến và dễ diễn giải: country và year. Theo sau là 56 column như sp_m_014, ep_m_4554, và rel_m_3544. Nếu bạn nhìn chăm chú vào các column này đủ lâu, bạn sẽ nhận ra có một mô hình. Mỗi tên column được tạo thành từ ba phần được phân tách bởi _. Phần đầu tiên, sp/rel/ep, mô tả phương pháp chẩn đoán, phần thứ hai, m/f là gender (giới tính, được mã hóa như biến nhị phân trong tập dữ liệu này), và phần thứ ba, 014/1524/2534/3544/4554/5564/65 là nhóm age (tuổi) (014 đại diện cho 0-14, ví dụ).
Vậy trong trường hợp này chúng ta có sáu mẩu thông tin được ghi nhận trong who2: quốc gia và năm (đã là các column); phương pháp chẩn đoán, nhóm giới tính, và nhóm tuổi (chứa trong tên các column khác); và số bệnh nhân trong nhóm đó (giá trị trong ô). Để tổ chức sáu mẩu thông tin này thành sáu column riêng biệt, chúng ta sử dụng pivot_longer() với một vector tên column cho names_to và hướng dẫn tách tên biến ban đầu thành các phần cho names_sep cũng như tên column cho values_to:
who2 |>
pivot_longer(
cols = !(country:year),
names_to = c("diagnosis", "gender", "age"),
names_sep = "_",
values_to = "count"
)
#> # A tibble: 405,440 × 6
#> country year diagnosis gender age count
#> <chr> <dbl> <chr> <chr> <chr> <dbl>
#> 1 Afghanistan 1980 sp m 014 NA
#> 2 Afghanistan 1980 sp m 1524 NA
#> 3 Afghanistan 1980 sp m 2534 NA
#> 4 Afghanistan 1980 sp m 3544 NA
#> 5 Afghanistan 1980 sp m 4554 NA
#> 6 Afghanistan 1980 sp m 5564 NA
#> # ℹ 405,434 more rowsMột phương án thay thế cho names_sep là names_pattern, mà bạn có thể sử dụng để trích xuất các biến từ các tình huống đặt tên phức tạp hơn, khi bạn đã học về regular expression trong Chương 15.
Về mặt khái niệm, đây chỉ là một biến thể nhỏ so với trường hợp đơn giản hơn mà bạn đã thấy. Hình 5.6 minh họa ý tưởng cơ bản: bây giờ, thay vì tên column được xoay vào một column duy nhất, chúng được xoay vào nhiều column. Bạn có thể tưởng tượng điều này xảy ra trong hai bước (xoay trước rồi tách sau) nhưng bên trong nó diễn ra trong một bước duy nhất vì như vậy nhanh hơn.
5.3.4 Dữ liệu và tên biến trong tiêu đề cột
Bước phức tạp tiếp theo là khi tên column bao gồm sự kết hợp giữa giá trị biến và tên biến. Ví dụ, hãy xem tập dữ liệu household:
household
#> # A tibble: 5 × 5
#> family dob_child1 dob_child2 name_child1 name_child2
#> <int> <date> <date> <chr> <chr>
#> 1 1 1998-11-26 2000-01-29 Susan Jose
#> 2 2 1996-06-22 NA Mark <NA>
#> 3 3 2002-07-11 2004-04-05 Sam Seth
#> 4 4 2004-10-10 2009-08-27 Craig Khai
#> 5 5 2000-12-05 2005-02-28 Parker GracieTập dữ liệu này chứa dữ liệu về năm gia đình, với tên và ngày sinh của tối đa hai con. Thách thức mới trong tập dữ liệu này là tên column chứa tên của hai biến (dob, name) và giá trị của một biến khác (child, với giá trị 1 hoặc 2). Để giải quyết vấn đề này, chúng ta lại cần cung cấp một vector cho names_to nhưng lần này chúng ta sử dụng giá trị đặc biệt ".value"; đây không phải tên của một biến mà là một giá trị đặc biệt cho pivot_longer() biết phải làm điều gì đó khác. Điều này ghi đè argument values_to thông thường để sử dụng thành phần đầu tiên của tên column được xoay làm tên biến trong đầu ra.
household |>
pivot_longer(
cols = !family,
names_to = c(".value", "child"),
names_sep = "_",
values_drop_na = TRUE
)
#> # A tibble: 9 × 4
#> family child dob name
#> <int> <chr> <date> <chr>
#> 1 1 child1 1998-11-26 Susan
#> 2 1 child2 2000-01-29 Jose
#> 3 2 child1 1996-06-22 Mark
#> 4 3 child1 2002-07-11 Sam
#> 5 3 child2 2004-04-05 Seth
#> 6 4 child1 2004-10-10 Craig
#> # ℹ 3 more rowsChúng ta lại sử dụng values_drop_na = TRUE, vì hình dạng của dữ liệu đầu vào buộc phải tạo ra các missing value rõ ràng (ví dụ, cho các gia đình chỉ có một con).
Hình 5.7 minh họa ý tưởng cơ bản với một ví dụ đơn giản hơn. Khi bạn sử dụng ".value" trong names_to, tên column trong đầu vào đóng góp vào cả giá trị và tên biến trong đầu ra.
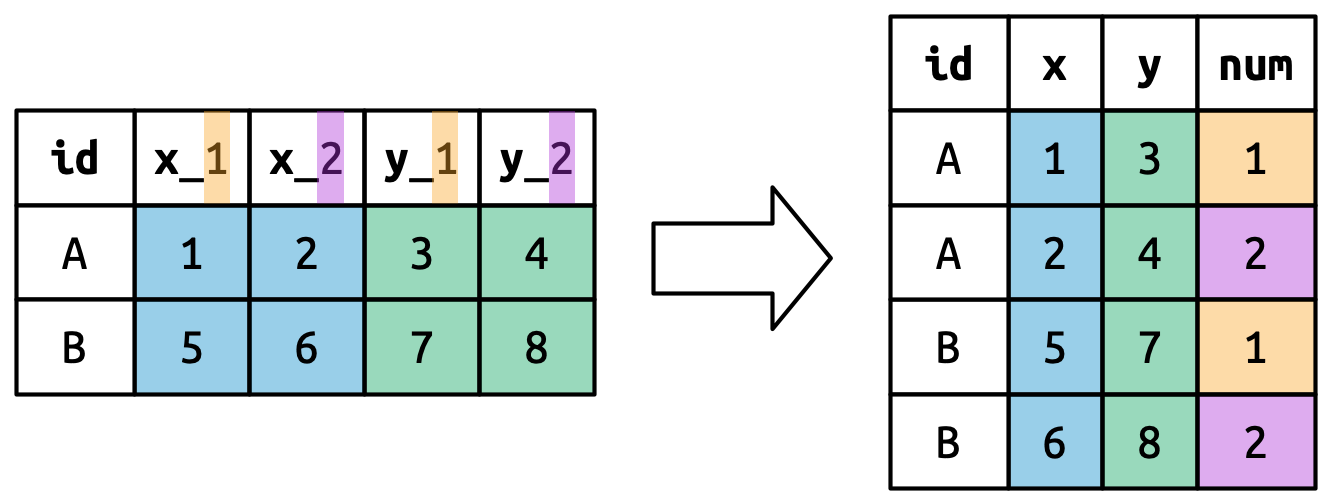
names_to = c(".value", "num") tách tên cột thành hai thành phần: phần đầu tiên xác định tên cột đầu ra (x hoặc y), và phần thứ hai xác định giá trị của column num.
5.4 Mở rộng dữ liệu
Cho đến nay chúng ta đã sử dụng pivot_longer() để giải quyết lớp vấn đề phổ biến khi các giá trị nằm trong tên column. Tiếp theo chúng ta sẽ xoay (HA HA) sang pivot_wider(), function làm tập dữ liệu rộng hơn bằng cách tăng số column và giảm số row và hữu ích khi một quan sát bị trải rộng trên nhiều row. Điều này dường như ít phổ biến hơn ngoài thực tế, nhưng nó có vẻ xuất hiện nhiều khi làm việc với dữ liệu chính phủ.
Chúng ta sẽ bắt đầu bằng cách xem cms_patient_experience, một tập dữ liệu từ Trung tâm Dịch vụ Medicare và Medicaid thu thập dữ liệu về trải nghiệm bệnh nhân:
cms_patient_experience
#> # A tibble: 500 × 5
#> org_pac_id org_nm measure_cd measure_title prf_rate
#> <chr> <chr> <chr> <chr> <dbl>
#> 1 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP_1 CAHPS for MIPS… 63
#> 2 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP_2 CAHPS for MIPS… 87
#> 3 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP_3 CAHPS for MIPS… 86
#> 4 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP_5 CAHPS for MIPS… 57
#> 5 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP_8 CAHPS for MIPS… 85
#> 6 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP_12 CAHPS for MIPS… 24
#> # ℹ 494 more rowsĐơn vị cốt lõi được nghiên cứu là một tổ chức, nhưng mỗi tổ chức được trải rộng trên sáu row, với một row cho mỗi phép đo được thực hiện trong khảo sát tổ chức. Chúng ta có thể xem tập đầy đủ các giá trị của measure_cd và measure_title bằng cách sử dụng distinct():
cms_patient_experience |>
distinct(measure_cd, measure_title)
#> # A tibble: 6 × 2
#> measure_cd measure_title
#> <chr> <chr>
#> 1 CAHPS_GRP_1 CAHPS for MIPS SSM: Getting Timely Care, Appointments, and In…
#> 2 CAHPS_GRP_2 CAHPS for MIPS SSM: How Well Providers Communicate
#> 3 CAHPS_GRP_3 CAHPS for MIPS SSM: Patient's Rating of Provider
#> 4 CAHPS_GRP_5 CAHPS for MIPS SSM: Health Promotion and Education
#> 5 CAHPS_GRP_8 CAHPS for MIPS SSM: Courteous and Helpful Office Staff
#> 6 CAHPS_GRP_12 CAHPS for MIPS SSM: Stewardship of Patient ResourcesKhông column nào trong hai column này sẽ tạo ra tên biến đặc biệt tốt: measure_cd không gợi ý về ý nghĩa của biến và measure_title là một câu dài chứa khoảng trắng. Chúng ta sẽ sử dụng measure_cd làm nguồn cho tên column mới của chúng ta hiện tại, nhưng trong một phân tích thực tế bạn có thể muốn tạo tên biến riêng vừa ngắn vừa có ý nghĩa.
pivot_wider() có giao diện ngược lại với pivot_longer(): thay vì chọn tên column mới, chúng ta cần cung cấp các column hiện có xác định giá trị (values_from) và tên column (names_from):
cms_patient_experience |>
pivot_wider(
names_from = measure_cd,
values_from = prf_rate
)
#> # A tibble: 500 × 9
#> org_pac_id org_nm measure_title CAHPS_GRP_1 CAHPS_GRP_2
#> <chr> <chr> <chr> <dbl> <dbl>
#> 1 0446157747 USC CARE MEDICAL GROUP … CAHPS for MIPS… 63 NA
#> 2 0446157747 USC CARE MEDICAL GROUP … CAHPS for MIPS… NA 87
#> 3 0446157747 USC CARE MEDICAL GROUP … CAHPS for MIPS… NA NA
#> 4 0446157747 USC CARE MEDICAL GROUP … CAHPS for MIPS… NA NA
#> 5 0446157747 USC CARE MEDICAL GROUP … CAHPS for MIPS… NA NA
#> 6 0446157747 USC CARE MEDICAL GROUP … CAHPS for MIPS… NA NA
#> # ℹ 494 more rows
#> # ℹ 4 more variables: CAHPS_GRP_3 <dbl>, CAHPS_GRP_5 <dbl>, …Kết quả đầu ra trông không hoàn toàn đúng; chúng ta vẫn dường như có nhiều row cho mỗi tổ chức. Đó là vì chúng ta cũng cần cho pivot_wider() biết column hoặc các column nào có giá trị xác định duy nhất mỗi hàng; trong trường hợp này đó là các biến bắt đầu bằng "org":
cms_patient_experience |>
pivot_wider(
id_cols = starts_with("org"),
names_from = measure_cd,
values_from = prf_rate
)
#> # A tibble: 95 × 8
#> org_pac_id org_nm CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3 CAHPS_GRP_5
#> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 0446157747 USC CARE MEDICA… 63 87 86 57
#> 2 0446162697 ASSOCIATION OF … 59 85 83 63
#> 3 0547164295 BEAVER MEDICAL … 49 NA 75 44
#> 4 0749333730 CAPE PHYSICIANS… 67 84 85 65
#> 5 0840104360 ALLIANCE PHYSIC… 66 87 87 64
#> 6 0840109864 REX HOSPITAL INC 73 87 84 67
#> # ℹ 89 more rows
#> # ℹ 2 more variables: CAHPS_GRP_8 <dbl>, CAHPS_GRP_12 <dbl>Điều này cho chúng ta kết quả đầu ra mà chúng ta mong muốn.
5.4.1 pivot_wider() hoạt động như thế nào?
Để hiểu cách pivot_wider() hoạt động, hãy bắt đầu lại với một tập dữ liệu rất đơn giản. Lần này chúng ta có hai bệnh nhân với id là A và B, chúng ta có ba lần đo huyết áp trên bệnh nhân A và hai trên bệnh nhân B:
df <- tribble(
~id, ~measurement, ~value,
"A", "bp1", 100,
"B", "bp1", 140,
"B", "bp2", 115,
"A", "bp2", 120,
"A", "bp3", 105
)Chúng ta sẽ lấy giá trị từ column value và tên từ column measurement:
df |>
pivot_wider(
names_from = measurement,
values_from = value
)
#> # A tibble: 2 × 4
#> id bp1 bp2 bp3
#> <chr> <dbl> <dbl> <dbl>
#> 1 A 100 120 105
#> 2 B 140 115 NAĐể bắt đầu quá trình, pivot_wider() cần tìm ra trước cái gì sẽ nằm trong các row và column. Tên column mới sẽ là các giá trị duy nhất của measurement.
Theo mặc định, các row trong đầu ra được xác định bởi tất cả các biến không đi vào tên hoặc giá trị mới. Chúng được gọi là id_cols. Ở đây chỉ có một column, nhưng nói chung có thể có bất kỳ số lượng nào.
pivot_wider() sau đó kết hợp các kết quả này để tạo ra một data frame rỗng:
Sau đó nó điền tất cả các missing value bằng dữ liệu trong đầu vào. Trong trường hợp này, không phải mọi ô trong đầu ra đều có giá trị tương ứng trong đầu vào vì không có lần đo huyết áp thứ ba cho bệnh nhân B, nên ô đó vẫn là khuyết. Chúng ta sẽ quay lại ý tưởng rằng pivot_wider() có thể “tạo ra” missing value trong Chương 18.
Bạn cũng có thể tự hỏi điều gì xảy ra nếu có nhiều row trong đầu vào tương ứng với một ô trong đầu ra. Ví dụ bên dưới có hai row tương ứng với id “A” và measurement “bp1”:
df <- tribble(
~id, ~measurement, ~value,
"A", "bp1", 100,
"A", "bp1", 102,
"A", "bp2", 120,
"B", "bp1", 140,
"B", "bp2", 115
)Nếu chúng ta cố gắng xoay dữ liệu này, chúng ta nhận được đầu ra chứa các column list (list-columns), mà bạn sẽ tìm hiểu thêm trong Chương 23:
df |>
pivot_wider(
names_from = measurement,
values_from = value
)
#> Warning: Values from `value` are not uniquely identified; output will contain
#> list-cols.
#> • Use `values_fn = list` to suppress this warning.
#> • Use `values_fn = {summary_fun}` to summarise duplicates.
#> • Use the following dplyr code to identify duplicates.
#> {data} |>
#> dplyr::summarise(n = dplyr::n(), .by = c(id, measurement)) |>
#> dplyr::filter(n > 1L)
#> # A tibble: 2 × 3
#> id bp1 bp2
#> <chr> <list> <list>
#> 1 A <dbl [2]> <dbl [1]>
#> 2 B <dbl [1]> <dbl [1]>Vì bạn chưa biết cách làm việc với loại dữ liệu này, bạn sẽ muốn làm theo gợi ý trong cảnh báo để tìm ra vấn đề ở đâu:
Sau đó tùy bạn tìm ra điều gì đã sai với dữ liệu và sửa chữa lỗi cơ bản hoặc sử dụng kỹ năng nhóm và tổng hợp của bạn để đảm bảo rằng mỗi tổ hợp giá trị row và column chỉ có một row duy nhất.
5.5 Tóm tắt
Trong chương này bạn đã học về tidy data: dữ liệu có các biến trong các column và các quan sát trong các row. Dữ liệu gọn gàng giúp làm việc trong tidyverse dễ dàng hơn, vì nó là một cấu trúc nhất quán được hiểu bởi hầu hết các function, thách thức chính là biến đổi dữ liệu từ bất kỳ cấu trúc nào bạn nhận được thành định dạng gọn gàng. Để đạt được mục đích đó, bạn đã học về pivot_longer() và pivot_wider() cho phép bạn chỉnh trang nhiều tập dữ liệu không gọn gàng. Các ví dụ chúng ta trình bày ở đây là một phần chọn lọc từ vignette("pivot", package = "tidyr"), vì vậy nếu bạn gặp một vấn đề mà chương này không giúp được, vignette đó là nơi tốt để thử tiếp theo.
Một thách thức khác là, đối với một tập dữ liệu cho trước, có thể không xác định được phiên bản dài hơn hay rộng hơn là phiên bản “gọn gàng”. Điều này một phần phản ánh định nghĩa của chúng ta về tidy data, khi chúng ta nói tidy data có một biến trong mỗi column, nhưng thực ra chúng ta chưa định nghĩa biến là gì (và điều này khó một cách đáng ngạc nhiên). Hoàn toàn ổn khi thực dụng và nói rằng một biến là bất cứ thứ gì giúp phân tích của bạn dễ dàng nhất. Vì vậy nếu bạn bị mắc kẹt khi tìm cách thực hiện một phép tính nào đó, hãy cân nhắc thay đổi cách tổ chức dữ liệu; đừng ngại làm cho dữ liệu không gọn gàng, biến đổi, và chỉnh trang lại khi cần!
Nếu bạn thích chương này và muốn tìm hiểu thêm về lý thuyết cơ bản, bạn có thể đọc thêm về lịch sử và nền tảng lý thuyết trong bài báo Tidy Data được xuất bản trên Journal of Statistical Software.
Bây giờ bạn đang viết một lượng đáng kể mã R, đã đến lúc tìm hiểu thêm về cách tổ chức mã của bạn thành các tệp và thư mục. Trong chương tiếp theo, bạn sẽ tìm hiểu tất cả về những lợi thế của script và dự án, và một số trong nhiều công cụ mà chúng cung cấp để giúp cuộc sống của bạn dễ dàng hơn.