20 Bảng tính
20.1 Giới thiệu
Trong Chương 7, bạn đã học cách nhập dữ liệu từ các tệp văn bản thuần túy như .csv và .tsv. Bây giờ là lúc học cách lấy dữ liệu từ spreadsheet (spreadsheet), dù đó là spreadsheet Excel hay Google Sheet. Phần này sẽ dựa trên nhiều kiến thức bạn đã học trong Chương 7, nhưng chúng ta cũng sẽ thảo luận thêm các lưu ý và sự phức tạp khi làm việc với dữ liệu từ spreadsheet.
Nếu bạn hoặc cộng tác viên đang sử dụng spreadsheet để tổ chức dữ liệu, chúng tôi khuyến khích bạn đọc bài báo “Data Organization in Spreadsheets” của Karl Broman và Kara Woo: https://doi.org/10.1080/00031305.2017.1375989. Các phương pháp tốt nhất được trình bày trong bài báo này sẽ giúp bạn tránh nhiều rắc rối khi nhập dữ liệu từ spreadsheet vào R để phân tích và visualization.
20.2 Excel
Microsoft Excel là một phần mềm spreadsheet được sử dụng rộng rãi, trong đó dữ liệu được tổ chức theo các trang tính (worksheet) bên trong các tệp spreadsheet.
20.2.1 Điều kiện tiên quyết
Trong phần này, bạn sẽ học cách tải dữ liệu từ spreadsheet Excel vào R bằng package readxl. Gói mở rộng này không thuộc tidyverse cốt lõi, vì vậy bạn cần tải nó một cách rõ ràng, nhưng nó được cài đặt tự động khi bạn cài package tidyverse. Sau đó, chúng ta cũng sẽ sử dụng package writexl, cho phép tạo các spreadsheet Excel.
20.2.2 Bắt đầu
Hầu hết các function của readxl cho phép bạn tải spreadsheet Excel vào R:
-
read_xls()đọc tệp Excel có định dạngxls. -
read_xlsx()đọc tệp Excel có định dạngxlsx. -
read_excel()có thể đọc tệp có cả định dạngxlsvàxlsx. Function này đoán loại tệp dựa trên đầu vào.
Các function này đều có cú pháp tương tự như các function khác mà chúng ta đã giới thiệu trước đó để đọc các loại tệp khác, ví dụ: read_csv(), read_table(), v.v. Trong phần còn lại của chương, chúng ta sẽ tập trung sử dụng read_excel().
20.2.3 Đọc spreadsheet Excel
Hình 20.1 cho thấy spreadsheet mà chúng ta sẽ đọc vào R trông như thế nào trong Excel. Bảng tính này có thể tải xuống dưới dạng tệp Excel từ https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w/.
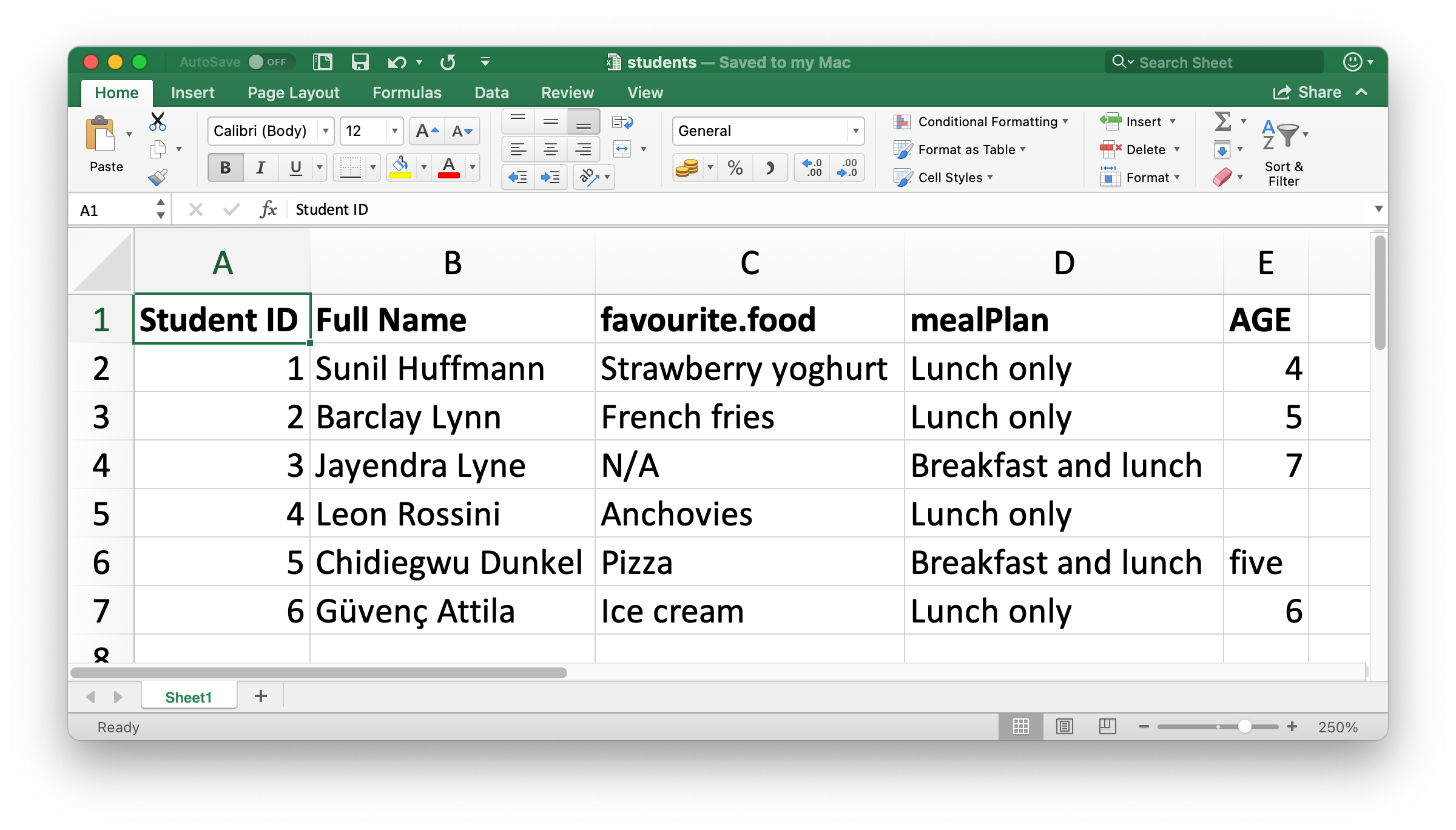
Đối số đầu tiên của read_excel() là đường dẫn đến tệp cần đọc.
students <- read_excel("data/students.xlsx")read_excel() sẽ đọc tệp vào dưới dạng tibble.
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne N/A Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6Chúng ta có sáu sinh viên trong dữ liệu và năm biến (variable) cho mỗi sinh viên. Tuy nhiên, có một vài điều chúng ta có thể muốn xử lý trong tập dữ liệu này:
-
Tên column không nhất quán. Bạn có thể cung cấp tên column theo một định dạng nhất quán; chúng tôi khuyến nghị
snake_casebằng cách sử dụng argumentcol_names.read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age") ) #> # A tibble: 7 × 5 #> student_id full_name favourite_food meal_plan age #> <chr> <chr> <chr> <chr> <chr> #> 1 Student ID Full Name favourite.food mealPlan AGE #> 2 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 3 2 Barclay Lynn French fries Lunch only 5 #> 4 3 Jayendra Lyne N/A Breakfast and lunch 7 #> 5 4 Leon Rossini Anchovies Lunch only <NA> #> 6 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 7 6 Güvenç Attila Ice cream Lunch only 6Thật không may, cách này chưa hoàn toàn giải quyết vấn đề. Bây giờ chúng ta đã có tên biến mong muốn, nhưng row tiêu đề trước đó giờ hiển thị như quan sát (observation) đầu tiên trong dữ liệu. Bạn có thể bỏ qua row đó một cách rõ ràng bằng argument
skip.read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1 ) #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne N/A Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only <NA> #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 6 6 Güvenç Attila Ice cream Lunch only 6 -
Trong column
favourite_food, một trong các quan sát làN/A, viết tắt của “not available” nhưng hiện tại nó không được nhận diện làNA(hãy lưu ý sự khác biệt giữaN/Anày và tuổi của sinh viên thứ tư trong list). Bạn có thể chỉ định các string nào nên được nhận diện làNAbằng argumentna. Theo mặc định, chỉ""(string rỗng, hoặc trong trường hợp đọc từ spreadsheet, một ô trống hoặc ô có công thức=NA()) được nhận diện làNA.read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A") ) #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <chr> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only <NA> #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five #> 6 6 Güvenç Attila Ice cream Lunch only 6 -
Một vấn đề còn lại khác là
ageđược đọc vào như một biến ký tự, nhưng thực ra nó nên là biến số. Giống như vớiread_csv()và các function tương tự để đọc dữ liệu từ tệp phẳng, bạn có thể cung cấp argumentcol_typeschoread_excel()và chỉ định kiểu column cho các biến bạn đọc vào. Tuy nhiên, cú pháp hơi khác một chút. Các tùy chọn của bạn là"skip","guess","logical","numeric","date","text"hoặc"list".read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "numeric") ) #> Warning: Expecting numeric in E6 / R6C5: got 'five' #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only NA #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch NA #> 6 6 Güvenç Attila Ice cream Lunch only 6Tuy nhiên, cách này cũng chưa tạo ra kết quả mong muốn. Bằng cách chỉ định rằng
agelà số, chúng ta đã chuyển ô có giá trị không phải số (có giá trịfive) thànhNA. Trong trường hợp này, chúng ta nên đọc age vào dưới dạng"text"và sau đó thực hiện thay đổi sau khi dữ liệu đã được tải vào R.students <- read_excel( "data/students.xlsx", col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"), skip = 1, na = c("", "N/A"), col_types = c("numeric", "text", "text", "text", "text") ) students <- students |> mutate( age = if_else(age == "five", "5", age), age = parse_number(age) ) students #> # A tibble: 6 × 5 #> student_id full_name favourite_food meal_plan age #> <dbl> <chr> <chr> <chr> <dbl> #> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4 #> 2 2 Barclay Lynn French fries Lunch only 5 #> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7 #> 4 4 Leon Rossini Anchovies Lunch only NA #> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch 5 #> 6 6 Güvenç Attila Ice cream Lunch only 6
Chúng ta đã cần nhiều bước và thử-sai để tải dữ liệu đúng định dạng mong muốn, và điều này không có gì bất ngờ. Khoa học dữ liệu là một quá trình iterate (iterative), và quá trình iterate này có thể còn tẻ nhạt hơn khi đọc dữ liệu từ spreadsheet so với các tệp dữ liệu hình chữ nhật văn bản thuần túy khác, vì con người thường nhập dữ liệu vào spreadsheet và sử dụng chúng không chỉ để lưu trữ dữ liệu mà còn để chia sẻ và truyền đạt thông tin.
Không có cách nào biết chính xác dữ liệu sẽ trông như thế nào cho đến khi bạn tải nó và xem qua. Thực ra, có một cách. Bạn có thể mở tệp trong Excel và xem trước. Nếu bạn định làm vậy, chúng tôi khuyến nghị tạo một bản sao của tệp Excel để mở và duyệt tương tác, trong khi giữ nguyên tệp dữ liệu gốc và đọc vào R từ tệp chưa bị chỉnh sửa. Điều này sẽ đảm bảo bạn không vô tình ghi đè bất kỳ thứ gì trong spreadsheet khi kiểm tra nó. Bạn cũng đừng ngại làm những gì chúng ta đã làm ở đây: tải dữ liệu, xem qua, điều chỉnh mã, tải lại, và iterate lại cho đến khi bạn hài lòng với kết quả.
20.2.4 Đọc các trang tính
Một tính năng quan trọng phân biệt spreadsheet với tệp phẳng là khái niệm nhiều trang (sheet), được gọi là trang tính (worksheet). Hình 20.2 cho thấy một spreadsheet Excel có nhiều trang tính. Dữ liệu lấy từ package palmerpenguins, và bạn có thể tải spreadsheet này dưới dạng tệp Excel từ https://docs.google.com/spreadsheets/d/1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY/. Mỗi trang tính chứa thông tin về chim cánh cụt từ một hòn đảo khác nhau nơi dữ liệu được thu thập.
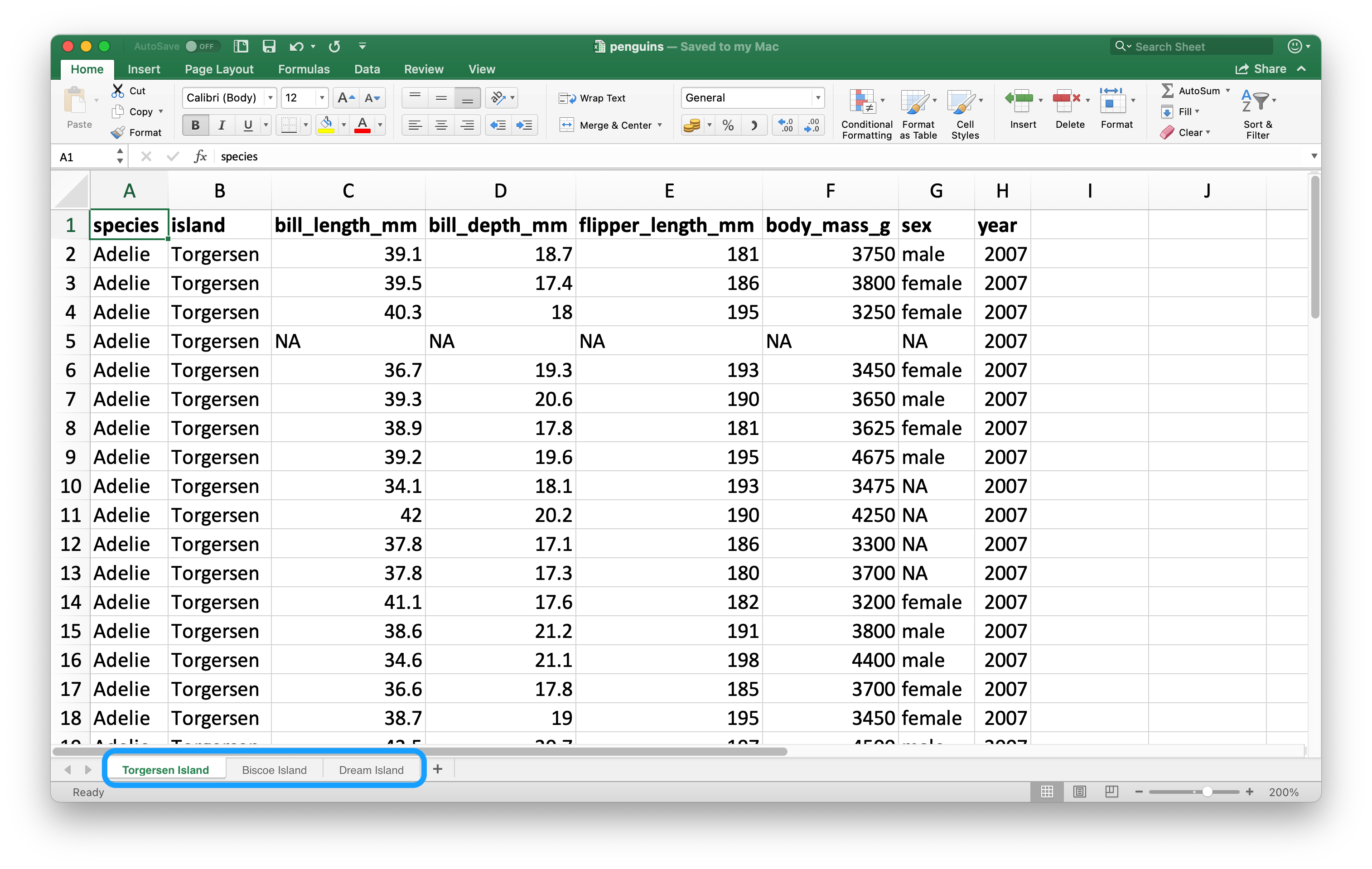
Bạn có thể đọc một trang tính đơn lẻ từ spreadsheet bằng argument sheet trong read_excel(). Mặc định, mà chúng ta đã dựa vào cho đến giờ, là trang tính đầu tiên.
read_excel("data/penguins.xlsx", sheet = "Torgersen Island")
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <chr> <chr> <chr>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.399999999999999 186
#> 3 Adelie Torgersen 40.299999999999997 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.700000000000003 19.3 193
#> 6 Adelie Torgersen 39.299999999999997 20.6 190
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <chr>, sex <chr>, year <dbl>Một số biến có vẻ chứa dữ liệu số lại được đọc vào dưới dạng ký tự do string "NA" không được nhận diện là giá trị NA thực sự.
penguins_torgersen <- read_excel("data/penguins.xlsx", sheet = "Torgersen Island", na = "NA")
penguins_torgersen
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.4 186
#> 3 Adelie Torgersen 40.3 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193
#> 6 Adelie Torgersen 39.3 20.6 190
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <dbl>, sex <chr>, year <dbl>Ngoài ra, bạn có thể sử dụng excel_sheets() để lấy thông tin về tất cả các trang tính trong spreadsheet Excel, rồi đọc trang bạn quan tâm.
excel_sheets("data/penguins.xlsx")
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"Khi bạn đã biết tên các trang tính, bạn có thể đọc chúng riêng lẻ bằng read_excel().
penguins_biscoe <- read_excel("data/penguins.xlsx", sheet = "Biscoe Island", na = "NA")
penguins_dream <- read_excel("data/penguins.xlsx", sheet = "Dream Island", na = "NA")Trong trường hợp này, toàn bộ tập dữ liệu penguins được phân bố trên ba trang tính trong spreadsheet. Mỗi trang tính có cùng số column nhưng số row khác nhau.
Chúng ta có thể ghép chúng lại với bind_rows().
penguins <- bind_rows(penguins_torgersen, penguins_biscoe, penguins_dream)
penguins
#> # A tibble: 344 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.4 186
#> 3 Adelie Torgersen 40.3 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193
#> 6 Adelie Torgersen 39.3 20.6 190
#> # ℹ 338 more rows
#> # ℹ 3 more variables: body_mass_g <dbl>, sex <chr>, year <dbl>Trong Chương 26, chúng ta sẽ nói về các cách thực hiện loại tác vụ này mà không cần mã iterate lại.
20.2.5 Đọc một phần trang tính
Vì nhiều người sử dụng spreadsheet Excel để trình bày cũng như lưu trữ dữ liệu, nên khá phổ biến khi gặp các ô trong spreadsheet không phải là phần dữ liệu bạn muốn đọc vào R. Hình 20.3 cho thấy một spreadsheet như vậy: ở giữa trang là thứ trông giống như một data frame nhưng có văn bản thừa trong các ô phía trên và phía dưới dữ liệu.
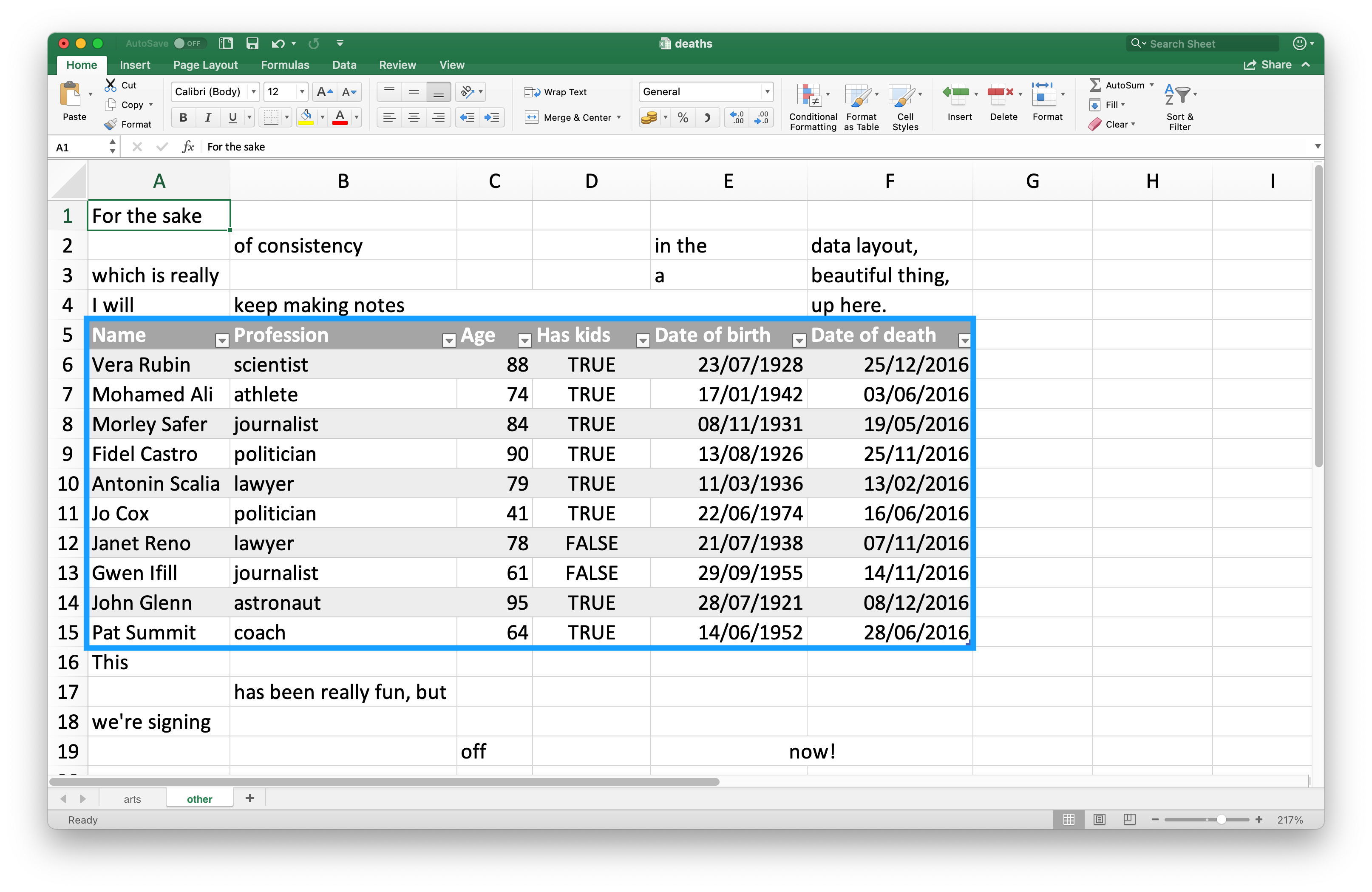
Bảng tính này là một trong các spreadsheet mẫu được cung cấp trong package readxl. Bạn có thể sử dụng function readxl_example() để tìm spreadsheet trên hệ thống của bạn trong thư mục nơi package được cài đặt. Function này trả về đường dẫn đến spreadsheet, bạn có thể sử dụng trong read_excel() như bình thường.
deaths_path <- readxl_example("deaths.xlsx")
deaths <- read_excel(deaths_path)
#> New names:
#> • `` -> `...2`
#> • `` -> `...3`
#> • `` -> `...4`
#> • `` -> `...5`
#> • `` -> `...6`
deaths
#> # A tibble: 18 × 6
#> `Lots of people` ...2 ...3 ...4 ...5 ...6
#> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 simply cannot resi… <NA> <NA> <NA> <NA> some notes
#> 2 at the top <NA> of their spreadsh…
#> 3 or merging <NA> <NA> <NA> cells
#> 4 Name Profession Age Has kids Date of birth Date of death
#> 5 David Bowie musician 69 TRUE 17175 42379
#> 6 Carrie Fisher actor 60 TRUE 20749 42731
#> # ℹ 12 more rowsBa row trên cùng và bốn row dưới cùng không phải là phần của data frame. Có thể loại bỏ các row thừa này bằng argument skip và n_max, nhưng chúng tôi khuyến nghị sử dụng phạm vi ô (cell range). Trong Excel, ô trên cùng bên trái là A1. Khi bạn di chuyển sang phải qua các column, nhãn ô đi theo thứ tự bảng chữ cái, tức là B1, C1, v.v. Và khi bạn di chuyển xuống một column, số trong nhãn ô tăng lên, tức là A2, A3, v.v.
Ở đây dữ liệu chúng ta muốn đọc bắt đầu từ ô A5 và kết thúc ở ô F15. Trong ký hiệu spreadsheet, đây là A5:F15, mà chúng ta cung cấp cho argument range:
read_excel(deaths_path, range = "A5:F15")
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.2.6 Kiểu dữ liệu
Trong tệp CSV, tất cả giá trị đều là string (string). Điều này không thực sự phản ánh đúng dữ liệu, nhưng nó đơn giản: mọi thứ đều là string.
Dữ liệu bên dưới trong spreadsheet Excel phức tạp hơn. Một ô có thể là một trong bốn thứ:
Giá trị logic (boolean), như
TRUE,FALSE, hoặcNA.Một số, như “10” hoặc “10.5”.
Ngày giờ (datetime), cũng có thể bao gồm thời gian như “11/1/21” hoặc “11/1/21 3:00 PM”.
Một string, như “ten”.
Khi làm việc với dữ liệu spreadsheet, điều quan trọng cần nhớ là dữ liệu bên dưới có thể rất khác so với những gì bạn thấy trong ô. Ví dụ, Excel không có khái niệm số nguyên (integer). Tất cả các số được lưu trữ dưới dạng số thực dấu phẩy động (floating point), nhưng bạn có thể chọn hiển thị dữ liệu với số chữ số thập phân tùy chỉnh. Tương tự, ngày thực ra được lưu trữ dưới dạng số, cụ thể là số ngày kể từ ngày 1 tháng 1 năm 1900. Bạn có thể tùy chỉnh cách hiển thị ngày bằng cách áp dụng định dạng trong Excel. Điều dễ gây nhầm lẫn là cũng có thể có thứ trông giống số nhưng thực ra là string (ví dụ: gõ '10 vào một ô trong Excel).
Những khác biệt giữa cách dữ liệu được lưu trữ bên dưới và cách chúng được hiển thị có thể gây bất ngờ khi dữ liệu được tải vào R. Theo mặc định, readxl sẽ đoán kiểu dữ liệu trong một column cho trước. Quy trình được khuyến nghị là để readxl đoán kiểu column, xác nhận rằng bạn hài lòng với các kiểu column được đoán, và nếu không, quay lại và nhập lại với chỉ định col_types như đã trình bày trong Phần 20.2.3.
Một thách thức khác là khi bạn có một column trong spreadsheet Excel chứa hỗn hợp các kiểu này, ví dụ: một số ô là số, một số là văn bản, một số là ngày. Khi nhập dữ liệu vào R, readxl phải đưa ra một số quyết định. Trong những trường hợp này, bạn có thể đặt kiểu cho column này thành "list", điều này sẽ tải column dưới dạng list (list) các vector có độ dài 1, trong đó kiểu của mỗi phần tử trong vector được đoán.
Đôi khi dữ liệu được lưu trữ theo những cách kỳ lạ hơn, như màu nền của ô, hoặc liệu văn bản có được in đậm hay không. Trong những trường hợp như vậy, bạn có thể thấy package tidyxl hữu ích. Xem https://nacnudus.github.io/spreadsheet-munging-strategies/ để biết thêm về các chiến lược làm việc với dữ liệu không dạng bảng từ Excel.
20.2.7 Ghi vào Excel
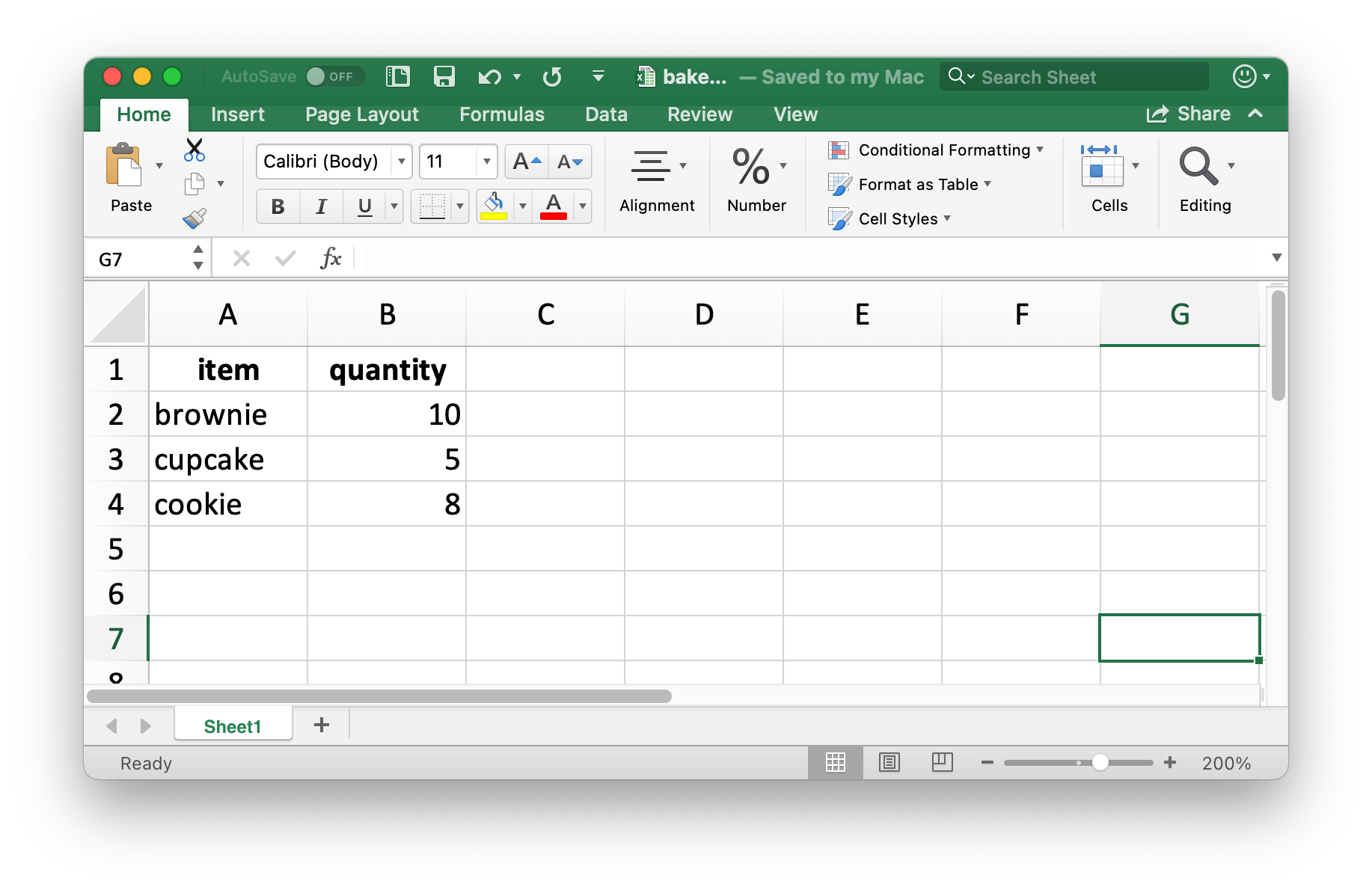
Hãy tạo một data frame nhỏ mà sau đó chúng ta có thể ghi ra. Lưu ý rằng item là factor (factor) và quantity là số nguyên (integer).
Bạn có thể ghi dữ liệu trở lại đĩa dưới dạng tệp Excel bằng function write_xlsx() từ package writexl:
write_xlsx(bake_sale, path = "data/bake-sale.xlsx")Hình 20.4 cho thấy dữ liệu trông như thế nào trong Excel. Lưu ý rằng tên column được bao gồm và in đậm. Các tùy chọn này có thể tắt bằng cách đặt argument col_names và format_headers thành FALSE.
Giống như khi đọc từ CSV, thông tin về kiểu dữ liệu bị mất khi chúng ta đọc dữ liệu trở lại. Điều này khiến tệp Excel không đáng tin cậy để lưu trữ tạm thời các kết quả trung gian. Để biết các giải pháp thay thế, xem Phần 7.5.
read_excel("data/bake-sale.xlsx")
#> # A tibble: 3 × 2
#> item quantity
#> <chr> <dbl>
#> 1 brownie 10
#> 2 cupcake 5
#> 3 cookie 820.2.8 Đầu ra có định dạng
Gói mở rộng writexl là giải pháp nhẹ để ghi một spreadsheet Excel đơn giản, nhưng nếu bạn quan tâm đến các tính năng bổ sung như ghi vào các trang tính bên trong spreadsheet và định dạng, bạn sẽ muốn sử dụng package openxlsx. Chúng tôi sẽ không đi vào chi tiết việc sử dụng package này ở đây, nhưng chúng tôi khuyến nghị đọc https://ycphs.github.io/openxlsx/articles/Formatting.html để thảo luận chuyên sâu về chức năng định dạng thêm cho dữ liệu được ghi từ R vào Excel bằng openxlsx.
Lưu ý rằng package này không thuộc tidyverse nên các function và workflow có thể cảm thấy xa lạ. Ví dụ, tên function sử dụng camelCase, nhiều function không thể kết hợp trong pipeline, và các argument có thứ tự khác so với trong tidyverse. Tuy nhiên, điều này không sao. Khi việc học và sử dụng R của bạn mở rộng ra ngoài cuốn sách này, bạn sẽ gặp nhiều phong cách mã hóa khác nhau được sử dụng trong các package R khác nhau mà bạn có thể dùng để hoàn thành các mục tiêu cụ thể trong R. Một cách tốt để làm quen với phong cách mã hóa trong một package mới là chạy các ví dụ được cung cấp trong tài liệu function để nắm được cú pháp và định dạng đầu ra cũng như đọc bất kỳ vignette nào đi kèm với package.
20.2.9 Bài tập
-
Trong một tệp Excel, tạo tập dữ liệu sau và lưu nó dưới dạng
survey.xlsx. Ngoài ra, bạn có thể tải nó dưới dạng tệp Excel từ đây.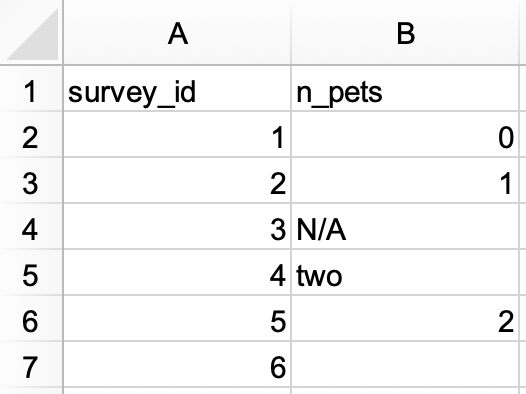
Sau đó, đọc nó vào R, với
survey_idlà biến ký tự vàn_petslà biến số.#> # A tibble: 6 × 2 #> survey_id n_pets #> <chr> <dbl> #> 1 1 0 #> 2 2 1 #> 3 3 NA #> 4 4 2 #> 5 5 2 #> 6 6 NA -
Trong một tệp Excel khác, tạo tập dữ liệu sau và lưu nó dưới dạng
roster.xlsx. Ngoài ra, bạn có thể tải nó dưới dạng tệp Excel từ đây.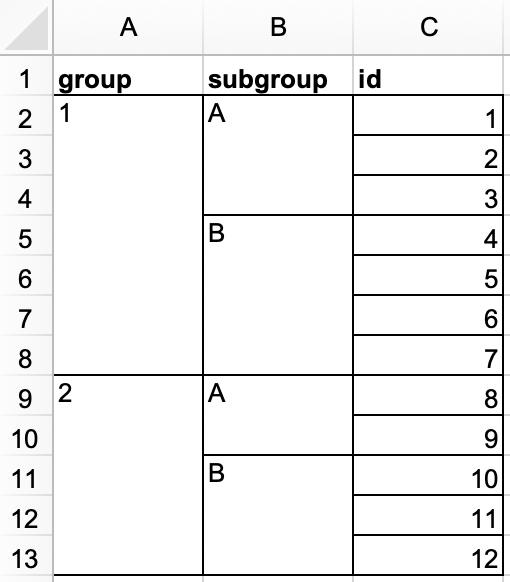
Sau đó, đọc nó vào R. Khung dữ liệu kết quả nên có tên
rostervà trông giống như sau.#> # A tibble: 12 × 3 #> group subgroup id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12 -
Trong một tệp Excel mới, tạo tập dữ liệu sau và lưu nó dưới dạng
sales.xlsx. Ngoài ra, bạn có thể tải nó dưới dạng tệp Excel từ đây.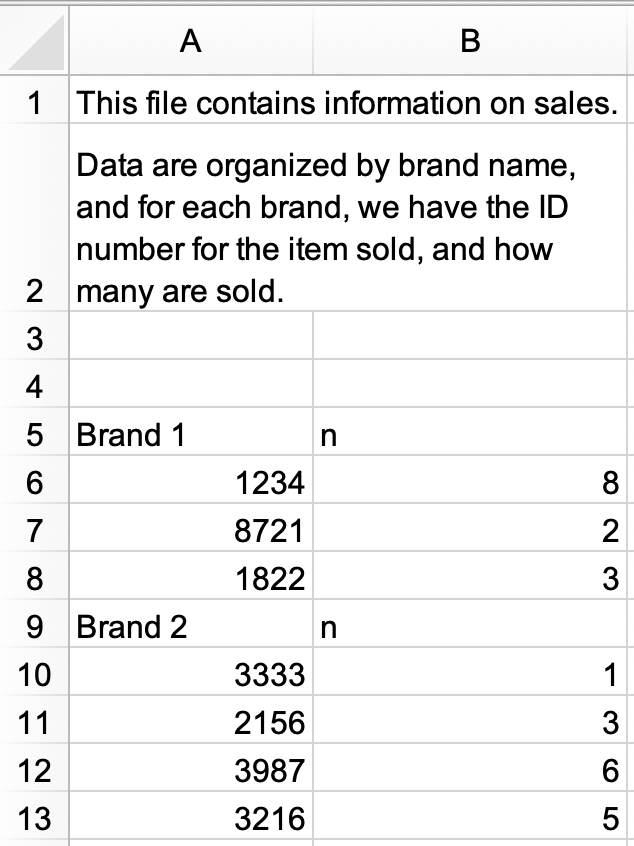
a. Đọc
sales.xlsxvào và lưu dưới dạngsales. Khung dữ liệu nên trông giống như sau, vớiidvànlà tên column và có 9 row.#> # A tibble: 9 × 2 #> id n #> <chr> <chr> #> 1 Brand 1 n #> 2 1234 8 #> 3 8721 2 #> 4 1822 3 #> 5 Brand 2 n #> 6 3333 1 #> 7 2156 3 #> 8 3987 6 #> 9 3216 5b. Chỉnh sửa thêm
salesđể đưa về định dạng gọn gàng (tidy) sau với ba column (brand,id, vàn) và 7 row dữ liệu. Lưu ý rằngidvànlà số,brandlà biến ký tự.#> # A tibble: 7 × 3 #> brand id n #> <chr> <dbl> <dbl> #> 1 Brand 1 1234 8 #> 2 Brand 1 8721 2 #> 3 Brand 1 1822 3 #> 4 Brand 2 3333 1 #> 5 Brand 2 2156 3 #> 6 Brand 2 3987 6 #> 7 Brand 2 3216 5 Tạo lại data frame
bake_sale, ghi nó ra tệp Excel bằng functionwrite.xlsx()từ package openxlsx.Trong Chương 7, bạn đã học về function
janitor::clean_names()để chuyển tên column sang snake case. Đọc tệpstudents.xlsxmà chúng ta đã giới thiệu trước đó trong phần này và sử dụng function này để “làm sạch” tên column.Điều gì xảy ra nếu bạn cố đọc một tệp có phần mở rộng
.xlsxbằngread_xls()?
20.3 Google Sheets
Google Sheets là một chương trình spreadsheet phổ biến khác. Nó miễn phí và hoạt động trên web. Giống như Excel, trong Google Sheets dữ liệu được tổ chức trong các trang tính (worksheet, còn gọi là sheet) bên trong các tệp spreadsheet.
20.3.1 Điều kiện tiên quyết
Phần này cũng sẽ tập trung vào spreadsheet, nhưng lần này bạn sẽ tải dữ liệu từ Google Sheet bằng package googlesheets4. Gói mở rộng này cũng không thuộc tidyverse cốt lõi, bạn cần tải nó một cách rõ ràng.
Một lưu ý nhanh về tên package: googlesheets4 sử dụng v4 của Sheets API v4 để cung cấp giao diện R cho Google Sheets, vì thế có tên như vậy.
20.3.2 Bắt đầu
Function chính của package googlesheets4 là read_sheet(), đọc một Google Sheet từ URL hoặc ID tệp. Function này cũng có tên khác là range_read().
Bạn cũng có thể tạo một sheet hoàn toàn mới bằng gs4_create() hoặc ghi vào sheet hiện có bằng sheet_write() và các function liên quan.
Trong phần này, chúng ta sẽ làm việc với cùng các tập dữ liệu như trong phần Excel để nhấn mạnh sự tương đồng và khác biệt giữa workflow đọc dữ liệu từ Excel và Google Sheets. Gói mở rộng readxl và googlesheets4 đều được thiết kế để mô phỏng chức năng của package readr, cung cấp function read_csv() mà bạn đã thấy trong Chương 7. Do đó, nhiều tác vụ có thể hoàn thành đơn giản bằng cách thay read_excel() bằng read_sheet(). Tuy nhiên, bạn cũng sẽ thấy rằng Excel và Google Sheets không hoạt động hoàn toàn giống nhau, do đó các tác vụ khác có thể cần cập nhật thêm cho các lệnh gọi function.
20.3.3 Đọc Google Sheets
Hình 20.5 cho thấy spreadsheet mà chúng ta sẽ đọc vào R trông như thế nào trong Google Sheets. Đây là cùng tập dữ liệu như trong Hình 20.1, ngoại trừ việc nó được lưu trong Google Sheet thay vì Excel.
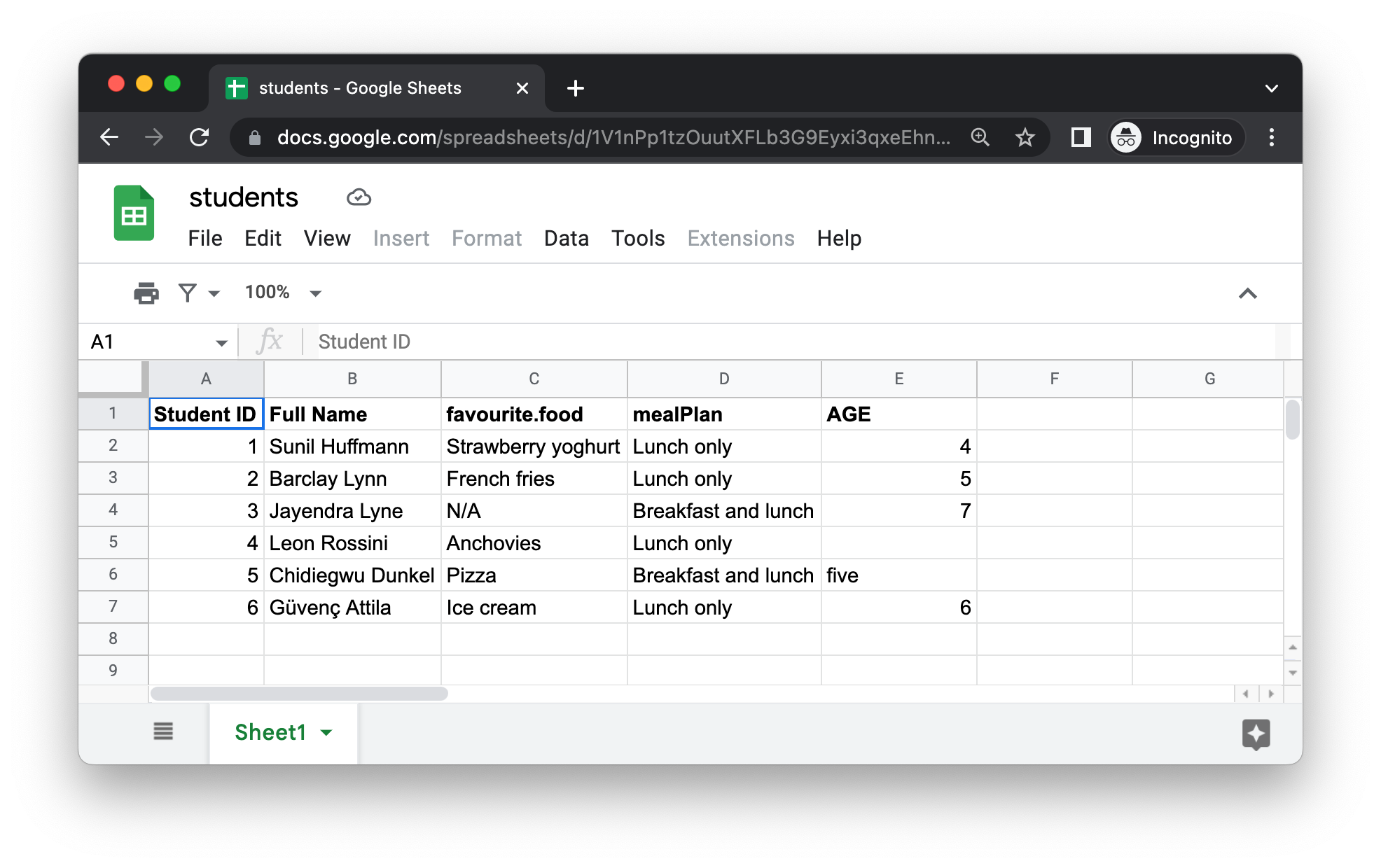
Đối số đầu tiên của read_sheet() là URL của tệp cần đọc, và nó trả về một tibble:
https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w. Các URL này không dễ làm việc, vì vậy bạn thường sẽ muốn xác định sheet bằng ID của nó.
students_sheet_id <- "1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w"
students <- read_sheet(students_sheet_id)
#> ✔ Reading from students.
#> ✔ Range Sheet1.
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <list>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only <dbl>
#> 2 2 Barclay Lynn French fries Lunch only <dbl>
#> 3 3 Jayendra Lyne N/A Breakfast and lunch <dbl>
#> 4 4 Leon Rossini Anchovies Lunch only <NULL>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch <chr>
#> 6 6 Güvenç Attila Ice cream Lunch only <dbl>Giống như chúng ta đã làm với read_excel(), chúng ta có thể cung cấp tên column, string NA, và kiểu column cho read_sheet().
students <- read_sheet(
students_sheet_id,
col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"),
skip = 1,
na = c("", "N/A"),
col_types = "dcccc"
)
#> ✔ Reading from students.
#> ✔ Range 2:10000000.
students
#> # A tibble: 6 × 5
#> student_id full_name favourite_food meal_plan age
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6Lưu ý rằng chúng ta định nghĩa kiểu column hơi khác ở đây, sử dụng mã viết tắt. Ví dụ, “dcccc” viết tắt cho “double, character, character, character, character”.
Cũng có thể đọc từng trang tính riêng lẻ từ Google Sheets. Hãy đọc trang “Torgersen Island” từ Google Sheet penguins:
penguins_sheet_id <- "1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY"
read_sheet(penguins_sheet_id, sheet = "Torgersen Island")
#> ✔ Reading from penguins.
#> ✔ Range ''Torgersen Island''.
#> # A tibble: 52 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <chr> <chr> <list> <list> <list>
#> 1 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 2 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 3 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 4 Adelie Torgersen <chr [1]> <chr [1]> <chr [1]>
#> 5 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> 6 Adelie Torgersen <dbl [1]> <dbl [1]> <dbl [1]>
#> # ℹ 46 more rows
#> # ℹ 3 more variables: body_mass_g <list>, sex <chr>, year <dbl>Bạn có thể lấy list tất cả các trang tính trong Google Sheet bằng sheet_names():
sheet_names(penguins_sheet_id)
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"Cuối cùng, giống như với read_excel(), chúng ta có thể đọc một phần của Google Sheet bằng cách xác định range trong read_sheet(). Lưu ý rằng chúng ta cũng đang sử dụng function gs4_example() bên dưới để tìm một Google Sheet mẫu đi kèm với package googlesheets4.
deaths_url <- gs4_example("deaths")
deaths <- read_sheet(deaths_url, range = "A5:F15")
#> ✔ Reading from deaths.
#> ✔ Range A5:F15.
deaths
#> # A tibble: 10 × 6
#> Name Profession Age `Has kids` `Date of birth`
#> <chr> <chr> <dbl> <lgl> <dttm>
#> 1 David Bowie musician 69 TRUE 1947-01-08 00:00:00
#> 2 Carrie Fisher actor 60 TRUE 1956-10-21 00:00:00
#> 3 Chuck Berry musician 90 TRUE 1926-10-18 00:00:00
#> 4 Bill Paxton actor 61 TRUE 1955-05-17 00:00:00
#> 5 Prince musician 57 TRUE 1958-06-07 00:00:00
#> 6 Alan Rickman actor 69 FALSE 1946-02-21 00:00:00
#> # ℹ 4 more rows
#> # ℹ 1 more variable: `Date of death` <dttm>20.3.4 Ghi vào Google Sheets
Bạn có thể ghi từ R vào Google Sheets bằng write_sheet(). Đối số đầu tiên là data frame cần ghi, và argument thứ hai là tên (hoặc định danh khác) của Google Sheet cần ghi vào:
write_sheet(bake_sale, ss = "bake-sale")Nếu bạn muốn ghi dữ liệu vào một trang tính cụ thể bên trong Google Sheet, bạn cũng có thể chỉ định điều đó bằng argument sheet.
write_sheet(bake_sale, ss = "bake-sale", sheet = "Sales")20.3.5 Xác thực
Mặc dù bạn có thể đọc từ Google Sheet công khai mà không cần xác thực (authentication) với tài khoản Google và bằng gs4_deauth(), việc đọc sheet riêng tư hoặc ghi vào sheet yêu cầu xác thực để googlesheets4 có thể xem và quản lý Google Sheets của bạn.
Khi bạn cố đọc một sheet yêu cầu xác thực, googlesheets4 sẽ chuyển bạn đến trình duyệt web với yêu cầu đăng nhập tài khoản Google và cấp quyền hoạt động thay mặt bạn với Google Sheets. Tuy nhiên, nếu bạn muốn chỉ định một tài khoản Google cụ thể, phạm vi xác thực, v.v., bạn có thể làm điều đó bằng gs4_auth(), ví dụ: gs4_auth(email = "mine@example.com"), sẽ buộc sử dụng token liên kết với một email cụ thể. Để biết thêm chi tiết về xác thực, chúng tôi khuyến nghị đọc tài liệu vignette xác thực của googlesheets4: https://googlesheets4.tidyverse.org/articles/auth.html.
20.3.6 Bài tập
Đọc tập dữ liệu
studentstừ phần trước trong chương từ Excel và cả từ Google Sheets, không cung cấp thêm argument nào cho functionread_excel()vàread_sheet(). Các data frame kết quả trong R có hoàn toàn giống nhau không? Nếu không, chúng khác nhau ở đâu?Đọc Google Sheet có tiêu đề survey từ https://pos.it/r4ds-survey, với
survey_idlà biến ký tự vàn_petslà biến số.-
Đọc Google Sheet có tiêu đề roster từ https://pos.it/r4ds-roster. Khung dữ liệu kết quả nên có tên
rostervà trông giống như sau.#> # A tibble: 12 × 3 #> group subgroup id #> <dbl> <chr> <dbl> #> 1 1 A 1 #> 2 1 A 2 #> 3 1 A 3 #> 4 1 B 4 #> 5 1 B 5 #> 6 1 B 6 #> 7 1 B 7 #> 8 2 A 8 #> 9 2 A 9 #> 10 2 B 10 #> 11 2 B 11 #> 12 2 B 12
20.4 Tóm tắt
Microsoft Excel và Google Sheets là hai trong số các hệ thống spreadsheet phổ biến nhất. Khả năng tương tác với dữ liệu được lưu trong tệp Excel và Google Sheets trực tiếp từ R là một siêu năng lực! Trong chương này, bạn đã học cách đọc dữ liệu vào R từ spreadsheet Excel bằng read_excel() từ package readxl và từ Google Sheets bằng read_sheet() từ package googlesheets4. Các function này hoạt động rất giống nhau và có các argument tương tự để chỉ định tên column, string NA, số row bỏ qua ở đầu tệp bạn đang đọc, v.v. Ngoài ra, cả hai function đều cho phép đọc một trang tính đơn lẻ từ spreadsheet.
Mặt khác, ghi vào tệp Excel yêu cầu một package và function khác (writexl::write_xlsx()) trong khi bạn có thể ghi vào Google Sheet bằng package googlesheets4, với write_sheet().
Trong chương tiếp theo, bạn sẽ tìm hiểu về một nguồn dữ liệu khác và cách đọc dữ liệu từ nguồn đó vào R: cơ sở dữ liệu (database).