library(nycflights13)
library(tidyverse)
#> ── Attaching core tidyverse packages ───────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.2.0 ✔ readr 2.2.0
#> ✔ forcats 1.0.1 ✔ stringr 1.6.0
#> ✔ ggplot2 4.0.2 ✔ tibble 3.3.1
#> ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
#> ✔ purrr 1.2.1
#> ── Conflicts ─────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors3 Biến đổi dữ liệu
3.1 Giới thiệu
Trực quan hóa (visualization) là một công cụ quan trọng để tạo ra những hiểu biết sâu sắc, nhưng hiếm khi bạn có được dữ liệu ở đúng dạng mà bạn cần để tạo biểu đồ mong muốn. Thường thì bạn sẽ cần tạo một số biến (variable) mới hoặc các bảng tóm tắt để trả lời câu hỏi của mình bằng dữ liệu, hoặc có thể bạn chỉ muốn đổi tên các biến hoặc sắp xếp lại các quan sát (observation) để dữ liệu dễ làm việc hơn. Bạn sẽ học cách làm tất cả những điều đó (và nhiều hơn nữa!) trong chương này, chương sẽ giới thiệu cho bạn về biến đổi dữ liệu (data transformation) bằng package dplyr và một tập dữ liệu mới về các chuyến bay khởi hành từ Thành phố New York năm 2013.
Mục tiêu của chương này là cung cấp cho bạn cái nhìn tổng quan về tất cả các công cụ chính để biến đổi một data frame. Chúng ta sẽ bắt đầu với các function thao tác trên row (row) rồi đến column (column) của data frame, sau đó quay lại nói thêm về pipe (pipe), một công cụ quan trọng mà bạn sử dụng để kết hợp các động từ. Tiếp theo, chúng ta sẽ giới thiệu khả năng làm việc với nhóm (group). Chúng ta sẽ kết thúc chương với một nghiên cứu tình huống (case study) minh họa các function này trong thực tế. Trong các chương sau, chúng ta sẽ quay lại các function này chi tiết hơn khi bắt đầu đào sâu vào các loại dữ liệu cụ thể (ví dụ: số, string, ngày tháng).
3.1.1 Điều kiện tiên quyết
Trong chương này, chúng ta sẽ tập trung vào package dplyr, một thành viên cốt lõi khác của tidyverse. Chúng ta sẽ minh họa các ý tưởng chính bằng dữ liệu từ package nycflights13 và sử dụng ggplot2 để giúp hiểu dữ liệu.
Hãy chú ý kỹ thông báo xung đột (conflicts) được in ra khi bạn tải tidyverse. Nó cho bạn biết rằng dplyr ghi đè một số function trong base R. Nếu bạn muốn sử dụng phiên bản base của các function này sau khi tải dplyr, bạn sẽ cần sử dụng tên đầy đủ của chúng: stats::filter() và stats::lag(). Cho đến nay, chúng ta hầu như đã bỏ qua việc một function đến từ package nào vì điều đó thường không quan trọng. Tuy nhiên, biết package nào có thể giúp bạn tìm trợ giúp và tìm các function liên quan, vì vậy khi cần chính xác về package mà một function đến từ đó, chúng ta sẽ sử dụng cùng cú pháp như R: packagename::functionname().
3.1.2 nycflights13
Để khám phá các động từ cơ bản của dplyr, chúng ta sẽ sử dụng nycflights13::flights. Tập dữ liệu này chứa tất cả 336,776 chuyến bay khởi hành từ Thành phố New York năm 2013. Dữ liệu đến từ Cục Thống kê Giao thông Vận tải Hoa Kỳ và được ghi chú trong ?flights.
flights
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …flights là một tibble, một loại data frame đặc biệt được tidyverse sử dụng để tránh một số lỗi phổ biến. Sự khác biệt quan trọng nhất giữa tibble và data frame là cách tibble in ra; chúng được thiết kế cho các tập dữ liệu lớn, nên chỉ hiển thị một vài row đầu tiên và chỉ các column vừa với một màn hình. Có một vài tùy chọn để xem mọi thứ. Nếu bạn đang sử dụng RStudio, cách thuận tiện nhất có lẽ là View(flights), mở một chế độ xem tương tác, có thể cuộn và lọc. Nếu không, bạn có thể sử dụng print(flights, width = Inf) để hiển thị tất cả các column, hoặc sử dụng glimpse():
glimpse(flights)
#> Rows: 336,776
#> Columns: 19
#> $ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013…
#> $ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558, 55…
#> $ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600, 60…
#> $ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2, -2,…
#> $ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 753, 8…
#> $ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 745, 8…
#> $ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3, 7,…
#> $ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6"…
#> $ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79, 301…
#> $ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N…
#> $ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LG…
#> $ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IA…
#> $ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138, 149…
#> $ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944, 73…
#> $ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6…
#> $ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59…
#> $ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-01-0…Trong cả hai chế độ xem, tên biến được theo sau bởi các chữ viết tắt cho biết kiểu của mỗi biến: <int> là viết tắt của số nguyên (integer), <dbl> là viết tắt của số thực (double), <chr> cho ký tự (character, hay string), và <dttm> cho ngày-giờ (date-time). Những kiểu này rất quan trọng vì các thao tác bạn có thể thực hiện trên một column phụ thuộc rất nhiều vào “kiểu” của nó.
3.1.3 Cơ bản về dplyr
Bạn sắp học các động từ (function) chính của dplyr, cho phép bạn giải quyết phần lớn các thách thức trong thao tác dữ liệu. Nhưng trước khi thảo luận về sự khác biệt riêng lẻ của chúng, đáng nói rằng chúng có điểm chung:
Đối số đầu tiên luôn là một data frame.
Các argument tiếp theo thường mô tả column nào cần thao tác bằng cách sử dụng tên biến (không có dấu ngoặc kép).
Đầu ra luôn là một data frame mới.
Vì mỗi động từ làm tốt một việc, giải quyết các vấn đề phức tạp thường đòi hỏi kết hợp nhiều động từ, và chúng ta sẽ làm điều đó với pipe, |>. Chúng ta sẽ thảo luận thêm về pipe trong Phần 3.4, nhưng tóm lại, pipe lấy thứ ở bên trái và chuyển nó cho function ở bên phải sao cho x |> f(y) tương đương với f(x, y), và x |> f(y) |> g(z) tương đương với g(f(x, y), z). Cách dễ nhất để đọc pipe là “rồi” (then). Điều đó giúp bạn có thể nắm được ý nghĩa của đoạn mã sau dù chưa học chi tiết:
Các động từ của dplyr được tổ chức thành bốn nhóm dựa trên đối tượng chúng thao tác: hàng, cột, nhóm, hoặc bảng. Trong các phần tiếp theo, bạn sẽ học các động từ quan trọng nhất cho row, column và nhóm. Sau đó, chúng ta sẽ quay lại các động từ nối (join) thao tác trên bảng trong Chương 19. Hãy bắt đầu nào!
3.2 Hàng
Các động từ quan trọng nhất thao tác trên row của tập dữ liệu là filter(), thay đổi những row nào xuất hiện mà không thay đổi thứ tự của chúng, và arrange(), thay đổi thứ tự các row mà không thay đổi những row nào xuất hiện. Cả hai function chỉ ảnh hưởng đến row, còn column không bị thay đổi. Chúng ta cũng sẽ thảo luận về distinct() để tìm các row có giá trị duy nhất. Khác với arrange() và filter(), nó cũng có thể tùy chọn thay đổi các column.
3.2.1 filter()
filter() cho phép bạn giữ lại các row dựa trên giá trị của các column1. Đối số đầu tiên là data frame. Đối số thứ hai và các argument tiếp theo là các điều kiện phải đúng để giữ lại row. Ví dụ, chúng ta có thể tìm tất cả các chuyến bay khởi hành trễ hơn 120 phút (hai giờ):
flights |>
filter(dep_delay > 120)
#> # A tibble: 9,723 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 848 1835 853 1001 1950
#> 2 2013 1 1 957 733 144 1056 853
#> 3 2013 1 1 1114 900 134 1447 1222
#> 4 2013 1 1 1540 1338 122 2020 1825
#> 5 2013 1 1 1815 1325 290 2120 1542
#> 6 2013 1 1 1842 1422 260 1958 1535
#> # ℹ 9,717 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Ngoài > (lớn hơn), bạn có thể sử dụng >= (lớn hơn hoặc bằng), < (nhỏ hơn), <= (nhỏ hơn hoặc bằng), == (bằng), và != (không bằng). Bạn cũng có thể kết hợp các điều kiện với & hoặc , để chỉ “và” (kiểm tra cả hai điều kiện) hoặc với | để chỉ “hoặc” (kiểm tra một trong hai điều kiện):
# Các chuyến bay khởi hành vào ngày 1 tháng 1
flights |>
filter(month == 1 & day == 1)
#> # A tibble: 842 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 836 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …
# Các chuyến bay khởi hành vào tháng 1 hoặc tháng 2
flights |>
filter(month == 1 | month == 2)
#> # A tibble: 51,955 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 51,949 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Có một phím tắt hữu ích khi bạn kết hợp | và ==: %in%. Nó giữ lại các row mà biến bằng một trong các giá trị ở bên phải:
# Cách ngắn hơn để chọn các chuyến bay khởi hành vào tháng 1 hoặc tháng 2
flights |>
filter(month %in% c(1, 2))
#> # A tibble: 51,955 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 51,949 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Chúng ta sẽ quay lại các phép so sánh và toán tử logic (logical operator) này chi tiết hơn trong Chương 12.
Khi bạn chạy filter(), dplyr thực hiện phép lọc, tạo ra một data frame mới, và sau đó in nó ra. Nó không sửa đổi tập dữ liệu flights hiện có vì các function dplyr không bao giờ sửa đổi đầu vào của chúng. Để lưu kết quả, bạn cần sử dụng toán tử gán, <-:
jan1 <- flights |>
filter(month == 1 & day == 1)3.2.2 Các lỗi phổ biến
Khi bạn mới bắt đầu với R, lỗi dễ mắc nhất là sử dụng = thay vì == khi kiểm tra bằng nhau. filter() sẽ thông báo cho bạn khi điều này xảy ra:
flights |>
filter(month = 1)
#> Error in `filter()`:
#> ! We detected a named input.
#> ℹ This usually means that you've used `=` instead of `==`.
#> ℹ Did you mean `month == 1`?Một lỗi khác là bạn viết câu lệnh “hoặc” giống như trong tiếng Anh:
flights |>
filter(month == 1 | 2)Điều này “hoạt động”, theo nghĩa nó không báo lỗi, nhưng nó không làm điều bạn muốn vì | đầu tiên kiểm tra điều kiện month == 1 và sau đó kiểm tra điều kiện 2, đây không phải là một điều kiện hợp lý để kiểm tra. Chúng ta sẽ tìm hiểu thêm về điều gì đang xảy ra ở đây và tại sao trong Phần 12.3.2.
3.2.3 arrange()
arrange() thay đổi thứ tự các row dựa trên giá trị của các column. Nó nhận một data frame và một tập hợp tên column (hoặc các biểu thức phức tạp hơn) để sắp xếp theo. Nếu bạn cung cấp nhiều hơn một tên column, mỗi column bổ sung sẽ được sử dụng để phá vỡ các giá trị bằng nhau trong các column trước. Ví dụ, đoạn mã sau sắp xếp theo thời gian khởi hành, được phân bố trên bốn column. Chúng ta có được các năm sớm nhất trước, sau đó trong một năm, các tháng sớm nhất, v.v.
flights |>
arrange(year, month, day, dep_time)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Bạn có thể sử dụng desc() trên một column bên trong arrange() để sắp xếp lại data frame dựa trên column đó theo thứ tự giảm dần (từ lớn đến nhỏ). Ví dụ, đoạn mã này sắp xếp các chuyến bay từ trễ nhất đến ít trễ nhất:
flights |>
arrange(desc(dep_delay))
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 9 641 900 1301 1242 1530
#> 2 2013 6 15 1432 1935 1137 1607 2120
#> 3 2013 1 10 1121 1635 1126 1239 1810
#> 4 2013 9 20 1139 1845 1014 1457 2210
#> 5 2013 7 22 845 1600 1005 1044 1815
#> 6 2013 4 10 1100 1900 960 1342 2211
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Lưu ý rằng số row không thay đổi – chúng ta chỉ sắp xếp dữ liệu, không lọc nó.
3.2.4 distinct()
distinct() tìm tất cả các row duy nhất trong một tập dữ liệu, vì vậy về mặt kỹ thuật, nó chủ yếu thao tác trên các row. Tuy nhiên, phần lớn thời gian bạn sẽ muốn tìm tổ hợp duy nhất của một số biến, vì vậy bạn cũng có thể tùy chọn cung cấp tên column:
# Xóa các row trùng iterate, nếu có
flights |>
distinct()
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …
# Tìm tất cả các cặp điểm đi và điểm đến duy nhất
flights |>
distinct(origin, dest)
#> # A tibble: 224 × 2
#> origin dest
#> <chr> <chr>
#> 1 EWR IAH
#> 2 LGA IAH
#> 3 JFK MIA
#> 4 JFK BQN
#> 5 LGA ATL
#> 6 EWR ORD
#> # ℹ 218 more rowsNgoài ra, nếu bạn muốn giữ các column khác khi lọc các row duy nhất, bạn có thể sử dụng tùy chọn .keep_all = TRUE.
flights |>
distinct(origin, dest, .keep_all = TRUE)
#> # A tibble: 224 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 218 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Không phải ngẫu nhiên mà tất cả các chuyến bay duy nhất này đều vào ngày 1 tháng 1: distinct() sẽ tìm lần xuất hiện đầu tiên của một row duy nhất trong tập dữ liệu và loại bỏ phần còn lại.
Nếu bạn muốn tìm số lần xuất hiện thay vào đó, tốt hơn là thay distinct() bằng count(). Với argument sort = TRUE, bạn có thể sắp xếp chúng theo thứ tự giảm dần của số lần xuất hiện. Bạn sẽ tìm hiểu thêm về count trong Phần 13.3.
flights |>
count(origin, dest, sort = TRUE)
#> # A tibble: 224 × 3
#> origin dest n
#> <chr> <chr> <int>
#> 1 JFK LAX 11262
#> 2 LGA ATL 10263
#> 3 LGA ORD 8857
#> 4 JFK SFO 8204
#> 5 LGA CLT 6168
#> 6 EWR ORD 6100
#> # ℹ 218 more rows3.2.5 Bài tập
-
Trong một pipeline đơn lẻ cho mỗi điều kiện, tìm tất cả các chuyến bay thỏa mãn điều kiện:
- Đến trễ hai giờ hoặc hơn
- Bay đến Houston (
IAHhoặcHOU) - Được vận hành bởi United, American, hoặc Delta
- Khởi hành vào mùa hè (tháng 7, tháng 8 và tháng 9)
- Đến trễ hơn hai giờ nhưng không khởi hành trễ
- Bị trễ ít nhất một giờ, nhưng bù lại hơn 30 phút trên chuyến bay
Sắp xếp
flightsđể tìm các chuyến bay có độ trễ khởi hành dài nhất. Tìm các chuyến bay khởi hành sớm nhất vào buổi sáng.Sắp xếp
flightsđể tìm các chuyến bay nhanh nhất. (Gợi ý: Thử đưa một phép tính toán học vào bên trong function của bạn.)Có chuyến bay vào mỗi ngày trong năm 2013 không?
Chuyến bay nào đi xa nhất? Chuyến bay nào đi gần nhất?
Thứ tự sử dụng
filter()vàarrange()có quan trọng không nếu bạn sử dụng cả hai? Tại sao/tại sao không? Hãy nghĩ về kết quả và khối lượng công việc mà các function phải thực hiện.
3.3 Cột
Có bốn động từ quan trọng ảnh hưởng đến column mà không thay đổi row: mutate() tạo các column mới được tính từ các column hiện có, select() thay đổi những column nào xuất hiện, rename() thay đổi tên của các column, và relocate() thay đổi vị trí của các column.
3.3.1 mutate()
Nhiệm vụ của mutate() là thêm các column mới được tính từ các column hiện có. Trong các chương biến đổi, bạn sẽ học một tập hợp lớn các function mà bạn có thể sử dụng để thao tác với các loại biến khác nhau. Hiện tại, chúng ta sẽ sử dụng đại số cơ bản, cho phép tính gain, lượng thời gian mà một chuyến bay trễ bù lại trên không, và speed tính bằng dặm trên giờ:
flights |>
mutate(
gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)
#> # A tibble: 336,776 × 21
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 13 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Theo mặc định, mutate() thêm các column mới ở phía bên phải của tập dữ liệu, điều này khiến khó nhìn thấy điều gì đang xảy ra ở đây. Chúng ta có thể sử dụng argument .before để thay vào đó thêm các biến vào phía bên trái2:
flights |>
mutate(
gain = dep_delay - arr_delay,
speed = distance / air_time * 60,
.before = 1
)
#> # A tibble: 336,776 × 21
#> gain speed year month day dep_time sched_dep_time dep_delay arr_time
#> <dbl> <dbl> <int> <int> <int> <int> <int> <dbl> <int>
#> 1 -9 370. 2013 1 1 517 515 2 830
#> 2 -16 374. 2013 1 1 533 529 4 850
#> 3 -31 408. 2013 1 1 542 540 2 923
#> 4 17 517. 2013 1 1 544 545 -1 1004
#> 5 19 394. 2013 1 1 554 600 -6 812
#> 6 -16 288. 2013 1 1 554 558 -4 740
#> # ℹ 336,770 more rows
#> # ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>, …Dấu . chỉ ra rằng .before là một argument của function, không phải tên của biến mới thứ ba mà chúng ta đang tạo. Bạn cũng có thể sử dụng .after để thêm sau một biến, và trong cả .before và .after bạn có thể sử dụng tên biến thay vì vị trí. Ví dụ, chúng ta có thể thêm các biến mới sau day:
flights |>
mutate(
gain = dep_delay - arr_delay,
speed = distance / air_time * 60,
.after = day
)Ngoài ra, bạn có thể kiểm soát những biến nào được giữ lại với argument .keep. Một argument đặc biệt hữu ích là "used" chỉ định rằng chúng ta chỉ giữ các column có liên quan hoặc được tạo trong bước mutate(). Ví dụ, đầu ra sau sẽ chỉ chứa các biến dep_delay, arr_delay, air_time, gain, hours, và gain_per_hour.
flights |>
mutate(
gain = dep_delay - arr_delay,
hours = air_time / 60,
gain_per_hour = gain / hours,
.keep = "used"
)Lưu ý rằng vì chúng ta chưa gán kết quả của phép tính trên lại cho flights, các biến mới gain, hours, và gain_per_hour sẽ chỉ được in ra nhưng không được lưu trong data frame. Và nếu muốn chúng có sẵn trong data frame để sử dụng trong tương lai, chúng ta nên cân nhắc kỹ liệu kết quả nên được gán lại cho flights, ghi đè data frame gốc với nhiều biến hơn, hay cho một đối tượng mới. Thường thì câu trả lời đúng là một đối tượng mới được đặt tên có ý nghĩa để chỉ ra nội dung của nó, ví dụ, delay_gain, nhưng bạn cũng có thể có lý do chính đáng để ghi đè flights.
3.3.2 select()
Không hiếm khi bạn nhận được tập dữ liệu với row trăm hoặc thậm chí row nghìn biến. Trong tình huống này, thách thức đầu tiên thường chỉ là tập trung vào các biến bạn quan tâm. select() cho phép bạn nhanh chóng thu hẹp vào một tập con hữu ích bằng các thao tác dựa trên tên của các biến:
-
Chọn column theo tên:
flights |> select(year, month, day) -
Chọn tất cả các column từ year đến day (bao gồm cả hai):
flights |> select(year:day) -
Chọn tất cả các column ngoại trừ từ year đến day (bao gồm cả hai):
flights |> select(!year:day)Trước đây, thao tác này được thực hiện bằng
-thay vì!, vì vậy bạn có thể thấy cách đó ngoài thực tế. Hai toán tử này phục vụ cùng mục đích nhưng với sự khác biệt tinh tế trong hành vi. Chúng tôi khuyên dùng!vì nó đọc như “không” (not) và kết hợp tốt với&và|. -
Chọn tất cả các column là kiểu ký tự:
Có một số function trợ giúp bạn có thể sử dụng bên trong select():
-
starts_with("abc"): khớp các tên bắt đầu bằng “abc”. -
ends_with("xyz"): khớp các tên kết thúc bằng “xyz”. -
contains("ijk"): khớp các tên chứa “ijk”. -
num_range("x", 1:3): khớpx1,x2vàx3.
Xem ?select để biết thêm chi tiết. Khi bạn biết regular expression (regular expression) (theme của Chương 15), bạn cũng sẽ có thể sử dụng matches() để chọn các biến khớp với một mẫu.
Bạn có thể đổi tên biến khi select() bằng cách sử dụng =. Tên mới xuất hiện ở bên trái của =, và biến cũ xuất hiện ở bên phải:
flights |>
select(tail_num = tailnum)
#> # A tibble: 336,776 × 1
#> tail_num
#> <chr>
#> 1 N14228
#> 2 N24211
#> 3 N619AA
#> 4 N804JB
#> 5 N668DN
#> 6 N39463
#> # ℹ 336,770 more rows
3.3.3 rename()
Nếu bạn muốn giữ tất cả các biến hiện có và chỉ muốn đổi tên một vài, bạn có thể sử dụng rename() thay vì select():
flights |>
rename(tail_num = tailnum)
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Nếu bạn có nhiều column được đặt tên không nhất quán và việc sửa tất cả bằng tay sẽ rất khó khăn, hãy xem janitor::clean_names() cung cấp một số chức năng dọn dẹp tự động hữu ích.
3.3.4 relocate()
Sử dụng relocate() để di chuyển các biến. Bạn có thể muốn tập hợp các biến liên quan lại với nhau hoặc di chuyển các biến quan trọng lên phía trước. Theo mặc định, relocate() di chuyển các biến lên phía trước:
flights |>
relocate(time_hour, air_time)
#> # A tibble: 336,776 × 19
#> time_hour air_time year month day dep_time sched_dep_time
#> <dttm> <dbl> <int> <int> <int> <int> <int>
#> 1 2013-01-01 05:00:00 227 2013 1 1 517 515
#> 2 2013-01-01 05:00:00 227 2013 1 1 533 529
#> 3 2013-01-01 05:00:00 160 2013 1 1 542 540
#> 4 2013-01-01 05:00:00 183 2013 1 1 544 545
#> 5 2013-01-01 06:00:00 116 2013 1 1 554 600
#> 6 2013-01-01 05:00:00 150 2013 1 1 554 558
#> # ℹ 336,770 more rows
#> # ℹ 12 more variables: dep_delay <dbl>, arr_time <int>, …Bạn cũng có thể chỉ định vị trí đặt chúng bằng các argument .before và .after, giống như trong mutate():
flights |>
relocate(year:dep_time, .after = time_hour)
flights |>
relocate(starts_with("arr"), .before = dep_time)3.3.5 Bài tập
So sánh
dep_time,sched_dep_time, vàdep_delay. Bạn mong đợi ba con số này liên quan với nhau như thế nào?Nghĩ ra càng nhiều cách càng tốt để chọn
dep_time,dep_delay,arr_time, vàarr_delaytừflights.Điều gì xảy ra nếu bạn chỉ định tên của cùng một biến nhiều lần trong lệnh gọi
select()?-
Function
any_of()làm gì? Tại sao nó có thể hữu ích khi kết hợp với vector này?variables <- c("year", "month", "day", "dep_delay", "arr_delay") -
Kết quả chạy đoạn mã sau có làm bạn ngạc nhiên không? Các function trợ giúp select xử lý chữ hoa và chữ thường theo mặc định như thế nào? Bạn có thể thay đổi mặc định đó bằng cách nào?
Đổi tên
air_timethànhair_time_minđể chỉ đơn vị đo và di chuyển nó lên đầu data frame.-
Tại sao đoạn mã sau không hoạt động, và thông báo lỗi có nghĩa gì?
3.4 Toán tử pipe
Chúng ta đã cho bạn thấy các ví dụ đơn giản về pipe ở trên, nhưng sức mạnh thực sự của nó phát sinh khi bạn bắt đầu kết hợp nhiều động từ. Ví dụ, hãy tưởng tượng rằng bạn muốn tìm các chuyến bay nhanh nhất đến sân bay IAH ở Houston: bạn cần kết hợp filter(), mutate(), select(), và arrange():
flights |>
filter(dest == "IAH") |>
mutate(speed = distance / air_time * 60) |>
select(year:day, dep_time, carrier, flight, speed) |>
arrange(desc(speed))
#> # A tibble: 7,198 × 7
#> year month day dep_time carrier flight speed
#> <int> <int> <int> <int> <chr> <int> <dbl>
#> 1 2013 7 9 707 UA 226 522.
#> 2 2013 8 27 1850 UA 1128 521.
#> 3 2013 8 28 902 UA 1711 519.
#> 4 2013 8 28 2122 UA 1022 519.
#> 5 2013 6 11 1628 UA 1178 515.
#> 6 2013 8 27 1017 UA 333 515.
#> # ℹ 7,192 more rowsMặc dù pipeline này có bốn bước, nhưng rất dễ lướt qua vì các động từ nằm ở đầu mỗi dòng: bắt đầu với dữ liệu flights, rồi lọc, rồi tạo biến mới, rồi chọn, rồi sắp xếp.
Điều gì sẽ xảy ra nếu chúng ta không có pipe? Chúng ta có thể lồng mỗi lệnh gọi function vào bên trong lệnh gọi trước:
Hoặc chúng ta có thể sử dụng một loạt các đối tượng trung gian:
Mặc dù cả hai dạng đều có lúc và nơi phù hợp, pipe thường tạo ra mã phân tích dữ liệu dễ viết và đọc hơn.
Để thêm pipe vào mã của bạn, chúng tôi khuyên sử dụng phím tắt tích hợp Ctrl/Cmd + Shift + M. Bạn sẽ cần thay đổi một thiết lập trong tùy chọn RStudio để sử dụng |> thay vì %>% như trong Hình 3.1; sẽ nói thêm về %>% ngay sau.
|>, hãy đảm bảo tùy chọn “Use native pipe operator” được chọn.
Ghi chúmagrittr
Nếu bạn đã sử dụng tidyverse một thời gian, bạn có thể quen thuộc với pipe %>% do package magrittr cung cấp. Gói mở rộng magrittr được bao gồm trong tidyverse cốt lõi, vì vậy bạn có thể sử dụng %>% bất cứ khi nào bạn tải tidyverse:
Đối với các trường hợp đơn giản, |> và %>% hoạt động giống hệt nhau. Vậy tại sao chúng tôi khuyên dùng pipe cơ bản? Thứ nhất, vì nó là một phần của base R, nó luôn sẵn có cho bạn sử dụng, ngay cả khi bạn không dùng tidyverse. Thứ hai, |> đơn giản hơn %>% khá nhiều: trong khoảng thời gian từ khi %>% được phát minh năm 2014 đến khi |> được đưa vào R 4.1.0 năm 2021, chúng ta đã hiểu rõ hơn về pipe. Điều này cho phép phiên bản base loại bỏ các tính năng ít sử dụng và kém quan trọng hơn.
3.5 Nhóm
Cho đến giờ bạn đã học về các function làm việc với row và column. dplyr trở nên mạnh mẽ hơn nữa khi bạn thêm khả năng làm việc với nhóm. Trong phần này, chúng ta sẽ tập trung vào các function quan trọng nhất: group_by(), summarize(), và họ function slice.
3.5.1 group_by()
Sử dụng group_by() để chia tập dữ liệu thành các nhóm có ý nghĩa cho phân tích của bạn:
flights |>
group_by(month)
#> # A tibble: 336,776 × 19
#> # Groups: month [12]
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …group_by() không thay đổi dữ liệu nhưng, nếu bạn nhìn kỹ đầu ra, bạn sẽ thấy rằng đầu ra chỉ ra nó được “nhóm theo” month (Groups: month [12]). Điều này có nghĩa là các thao tác tiếp theo sẽ hoạt động “theo tháng”. group_by() thêm tính năng nhóm này (được gọi là lớp - class) vào data frame, thay đổi hành vi của các động từ tiếp theo được áp dụng cho dữ liệu.
3.5.2 summarize()
Thao tác nhóm quan trọng nhất là tóm tắt, nếu được sử dụng để tính một thống kê tóm tắt đơn lẻ, sẽ giảm data frame xuống còn một row cho mỗi nhóm. Trong dplyr, thao tác này được thực hiện bởi summarize()3, như ví dụ sau đây tính độ trễ khởi hành trung bình theo tháng:
Ồ không! Có gì đó sai, và tất cả kết quả của chúng ta đều là NA (đọc là “N-A”), ký hiệu của R cho missing value (missing value). Điều này xảy ra vì một số chuyến bay có dữ liệu khuyết trong column delay, và khi chúng ta tính trung bình bao gồm những giá trị đó, chúng ta nhận được kết quả NA. Chúng ta sẽ quay lại thảo luận chi tiết về missing value trong Chương 18, nhưng bây giờ, chúng ta sẽ bảo function mean() bỏ qua tất cả missing value bằng cách đặt argument na.rm thành TRUE:
Bạn có thể tạo bất kỳ số lượng tóm tắt nào trong một lệnh gọi summarize() duy nhất. Bạn sẽ học các phép tóm tắt hữu ích khác nhau trong các chương sắp tới, nhưng một phép tóm tắt rất hữu ích là n(), trả về số row trong mỗi nhóm:
Giá trị trung bình và số đếm có thể đưa bạn đi xa một cách đáng ngạc nhiên trong khoa học dữ liệu!
3.5.3 Các function slice_
Có năm function tiện dụng cho phép bạn trích xuất các row cụ thể trong mỗi nhóm:
-
df |> slice_head(n = 1)lấy row đầu tiên từ mỗi nhóm. -
df |> slice_tail(n = 1)lấy row cuối cùng trong mỗi nhóm. -
df |> slice_min(x, n = 1)lấy row có giá trị nhỏ nhất của columnx. -
df |> slice_max(x, n = 1)lấy row có giá trị lớn nhất của columnx. -
df |> slice_sample(n = 1)lấy một row ngẫu nhiên.
Bạn có thể thay đổi n để chọn nhiều hơn một row, hoặc thay vì n =, bạn có thể sử dụng prop = 0.1 để chọn (ví dụ) 10% số row trong mỗi nhóm. Ví dụ, đoạn mã sau tìm các chuyến bay bị trễ nhất khi đến tại mỗi điểm đến:
flights |>
group_by(dest) |>
slice_max(arr_delay, n = 1) |>
relocate(dest)
#> # A tibble: 108 × 19
#> # Groups: dest [105]
#> dest year month day dep_time sched_dep_time dep_delay arr_time
#> <chr> <int> <int> <int> <int> <int> <dbl> <int>
#> 1 ABQ 2013 7 22 2145 2007 98 132
#> 2 ACK 2013 7 23 1139 800 219 1250
#> 3 ALB 2013 1 25 123 2000 323 229
#> 4 ANC 2013 8 17 1740 1625 75 2042
#> 5 ATL 2013 7 22 2257 759 898 121
#> 6 AUS 2013 7 10 2056 1505 351 2347
#> # ℹ 102 more rows
#> # ℹ 11 more variables: sched_arr_time <int>, arr_delay <dbl>, …Lưu ý rằng có 105 điểm đến nhưng chúng ta nhận được 108 row. Sao vậy? slice_min() và slice_max() giữ lại các giá trị bằng nhau nên n = 1 có nghĩa là cho chúng ta tất cả các row có giá trị cao nhất. Nếu bạn muốn chính xác một row cho mỗi nhóm, bạn có thể đặt with_ties = FALSE.
Điều này tương tự với việc tính độ trễ tối đa bằng summarize(), nhưng bạn nhận được toàn bộ row tương ứng (hoặc các row nếu có giá trị bằng nhau) thay vì chỉ một thống kê tóm tắt đơn lẻ.
3.5.4 Nhóm theo nhiều biến
Bạn có thể tạo nhóm bằng nhiều hơn một biến. Ví dụ, chúng ta có thể tạo một nhóm cho mỗi ngày.
daily <- flights |>
group_by(year, month, day)
daily
#> # A tibble: 336,776 × 19
#> # Groups: year, month, day [365]
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Khi bạn tóm tắt một tibble được nhóm theo nhiều hơn một biến, mỗi phép tóm tắt sẽ bóc bỏ nhóm cuối cùng. Nhìn lại, đây không phải là cách tốt nhất để function này hoạt động, nhưng rất khó thay đổi mà không phá vỡ mã hiện có. Để cho rõ ràng điều gì đang xảy ra, dplyr hiển thị một thông báo cho bạn biết cách thay đổi hành vi này:
daily_flights <- daily |>
summarize(n = n())
#> `summarise()` has regrouped the output.
#> ℹ Summaries were computed grouped by year, month, and day.
#> ℹ Output is grouped by year and month.
#> ℹ Use `summarise(.groups = "drop_last")` to silence this message.
#> ℹ Use `summarise(.by = c(year, month, day))` for per-operation grouping
#> (`?dplyr::dplyr_by`) instead.Nếu bạn hài lòng với hành vi này, bạn có thể yêu cầu rõ ràng để ngăn thông báo:
Ngoài ra, thay đổi hành vi mặc định bằng cách đặt một giá trị khác, ví dụ, "drop" để bỏ tất cả nhóm hoặc "keep" để giữ nguyên các nhóm.
3.5.5 Bỏ nhóm
Bạn cũng có thể muốn xóa nhóm khỏi data frame mà không sử dụng summarize(). Bạn có thể làm điều này với ungroup().
daily |>
ungroup()
#> # A tibble: 336,776 × 19
#> year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
#> <int> <int> <int> <int> <int> <dbl> <int> <int>
#> 1 2013 1 1 517 515 2 830 819
#> 2 2013 1 1 533 529 4 850 830
#> 3 2013 1 1 542 540 2 923 850
#> 4 2013 1 1 544 545 -1 1004 1022
#> 5 2013 1 1 554 600 -6 812 837
#> 6 2013 1 1 554 558 -4 740 728
#> # ℹ 336,770 more rows
#> # ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>, …Bây giờ hãy xem điều gì xảy ra khi bạn tóm tắt một data frame không được nhóm.
Bạn nhận lại một row duy nhất vì dplyr coi tất cả các row trong một data frame không được nhóm là thuộc về một nhóm.
3.5.6 .by
dplyr 1.1.0 bao gồm một cú pháp mới, thử nghiệm, cho nhóm theo từng thao tác, argument .by. group_by() và ungroup() không biến mất, nhưng giờ bạn cũng có thể sử dụng argument .by để nhóm trong một thao tác đơn lẻ:
Hoặc nếu bạn muốn nhóm theo nhiều biến:
.by hoạt động với tất cả các động từ và có lợi thế là bạn không cần sử dụng argument .groups để ngăn thông báo nhóm hoặc ungroup() khi hoàn thành.
Chúng tôi không tập trung vào cú pháp này trong chương này vì nó rất mới khi chúng tôi viết cuốn sách. Chúng tôi muốn đề cập đến nó vì nghĩ rằng nó rất triển vọng và có khả năng sẽ khá phổ biến. Bạn có thể tìm hiểu thêm về nó trong bài blog dplyr 1.1.0.
3.5.7 Bài tập
Hãng bay nào có độ trễ trung bình tệ nhất? Thách thức: bạn có thể tách biệt ảnh hưởng của sân bay xấu so với hãng bay xấu không? Tại sao/tại sao không? (Gợi ý: nghĩ về
flights |> group_by(carrier, dest) |> summarize(n()))Tìm các chuyến bay bị trễ nhất khi khởi hành đến mỗi điểm đến.
Độ trễ thay đổi như thế nào trong suốt một ngày? Minh họa câu trả lời của bạn bằng một biểu đồ.
Điều gì xảy ra nếu bạn cung cấp một
nâm choslice_min()và các function tương tự?Giải thích
count()làm gì dưới dạng các động từ dplyr bạn vừa học. Đối sốsortcủacount()làm gì?-
Giả sử chúng ta có data frame nhỏ sau:
-
Viết ra những gì bạn nghĩ đầu ra sẽ trông như thế nào, sau đó kiểm tra xem bạn có đúng không, và mô tả
group_by()làm gì.df |> group_by(y) -
Viết ra những gì bạn nghĩ đầu ra sẽ trông như thế nào, sau đó kiểm tra xem bạn có đúng không, và mô tả
arrange()làm gì. Ngoài ra, hãy bình luận về sự khác biệt của nó so vớigroup_by()ở phần (a).df |> arrange(y) -
Viết ra những gì bạn nghĩ đầu ra sẽ trông như thế nào, sau đó kiểm tra xem bạn có đúng không, và mô tả pipeline làm gì.
-
Viết ra những gì bạn nghĩ đầu ra sẽ trông như thế nào, sau đó kiểm tra xem bạn có đúng không, và mô tả pipeline làm gì. Sau đó, bình luận về thông báo nói gì.
-
Viết ra những gì bạn nghĩ đầu ra sẽ trông như thế nào, sau đó kiểm tra xem bạn có đúng không, và mô tả pipeline làm gì. Đầu ra khác với phần (d) như thế nào?
-
Viết ra những gì bạn nghĩ đầu ra sẽ trông như thế nào, sau đó kiểm tra xem bạn có đúng không, và mô tả mỗi pipeline làm gì. Đầu ra của hai pipeline khác nhau như thế nào?
-
3.6 Nghiên cứu tình huống: tổng hợp và kích thước mẫu
Bất cứ khi nào bạn thực hiện bất kỳ phép tổng hợp (aggregation) nào, luôn là ý tưởng tốt để bao gồm số đếm (n()). Bằng cách đó, bạn có thể đảm bảo rằng mình không rút ra kết luận dựa trên lượng dữ liệu rất nhỏ. Chúng ta sẽ minh họa điều này với một số dữ liệu bóng chày từ package Lahman. Cụ thể, chúng ta sẽ so sánh tỷ lệ đánh trúng bóng (H) so với số lần cố gắng đưa bóng vào cuộc chơi (AB):
batters <- Lahman::Batting |>
group_by(playerID) |>
summarize(
performance = sum(H, na.rm = TRUE) / sum(AB, na.rm = TRUE),
n = sum(AB, na.rm = TRUE)
)
batters
#> # A tibble: 24,011 × 3
#> playerID performance n
#> <chr> <dbl> <int>
#> 1 aardsda01 0 4
#> 2 aaronha01 0.305 12364
#> 3 aaronto01 0.229 944
#> 4 aasedo01 0 5
#> 5 abadan01 0.0952 21
#> 6 abadfe01 0.111 9
#> # ℹ 24,005 more rowsKhi chúng ta vẽ biểu đồ kỹ năng của người đánh bóng (đo bằng tỷ lệ đánh bóng trung bình, performance) so với số cơ hội đánh bóng (đo bằng số lần đánh, n), bạn thấy hai mô hình:
Biến thiên trong
performancelớn hơn ở những người chơi có ít lần đánh hơn. Hình dạng của biểu đồ này rất đặc trưng: bất cứ khi nào bạn vẽ biểu đồ giá trị trung bình (hoặc thống kê tóm tắt khác) so với kích thước nhóm, bạn sẽ thấy biến thiên giảm khi kích thước mẫu (sample size) tăng4.Có mối tương quan dương giữa kỹ năng (
performance) và cơ hội đánh bóng (n) vì các đội muốn cho những người đánh bóng giỏi nhất nhiều cơ hội đánh bóng nhất.
batters |>
filter(n > 100) |>
ggplot(aes(x = n, y = performance)) +
geom_point(alpha = 1 / 10) +
geom_smooth(se = FALSE)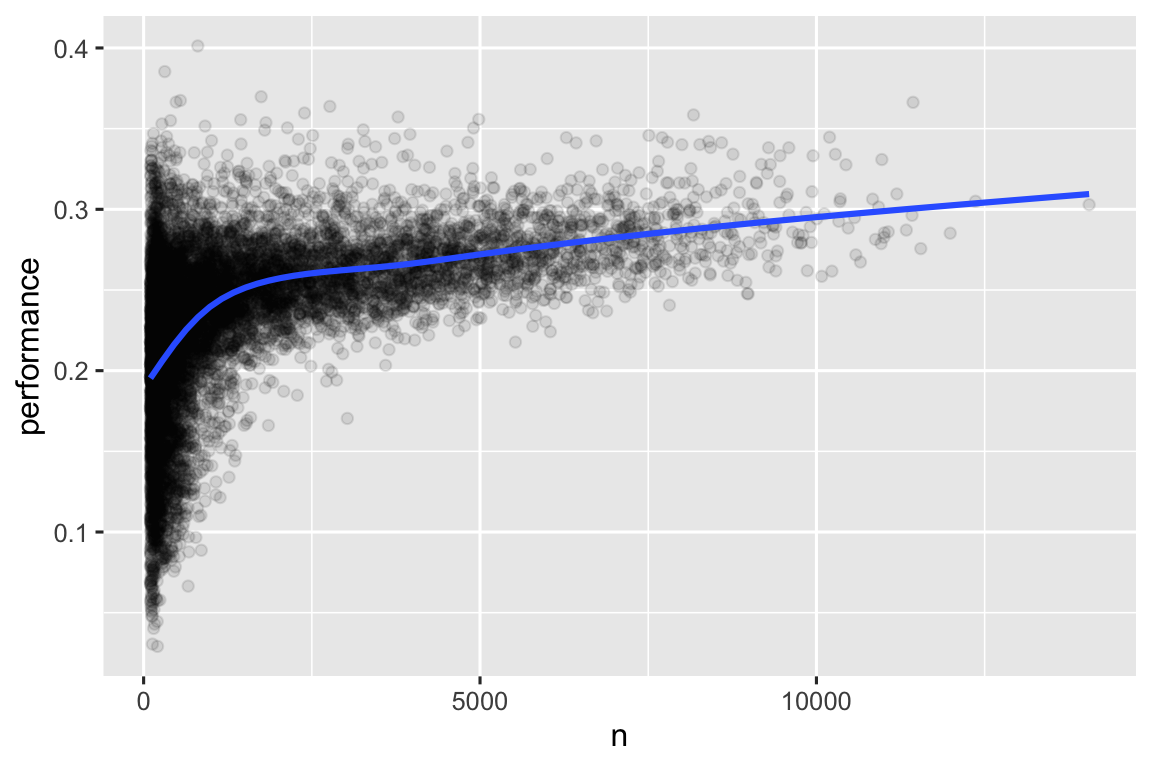
Hãy lưu ý mẫu tiện dụng để kết hợp ggplot2 và dplyr. Bạn chỉ cần nhớ chuyển từ |>, cho xử lý tập dữ liệu, sang + để thêm lớp vào biểu đồ.
Điều này cũng có ý nghĩa quan trọng cho xếp hạng. Nếu bạn sắp xếp đơn giản theo desc(performance), những người có tỷ lệ đánh bóng tốt nhất rõ ràng là những người chỉ cố đưa bóng vào cuộc chơi rất ít lần và tình cờ đánh trúng, họ không nhất thiết là những người chơi giỏi nhất:
Bạn có thể tìm giải thích tốt về vấn đề này và cách khắc phục tại http://varianceexplained.org/r/empirical_bayes_baseball/ và https://www.evanmiller.org/how-not-to-sort-by-average-rating.html.
3.7 Tóm tắt
Trong chương này, bạn đã học các công cụ mà dplyr cung cấp để làm việc với data frame. Các công cụ được chia thành ba nhóm đại khái: những công cụ thao tác trên row (như filter() và arrange()), những công cụ thao tác trên column (như select() và mutate()), và những công cụ thao tác trên nhóm (như group_by() và summarize()). Trong chương này, chúng ta đã tập trung vào các công cụ “toàn bộ data frame” này, nhưng bạn chưa học nhiều về những gì bạn có thể làm với từng biến riêng lẻ. Chúng ta sẽ quay lại điều đó trong phần Biến đổi của cuốn sách, nơi mỗi chương cung cấp các công cụ cho một loại biến cụ thể.
Trong chương tiếp theo, chúng ta sẽ quay lại workflow để thảo luận về tầm quan trọng của phong cách mã và giữ cho mã của bạn được tổ chức tốt để bạn và người khác dễ đọc và hiểu.