library(tidyverse)
#> ── Attaching core tidyverse packages ───────────────────── tidyverse 2.0.0 ──
#> ✔ dplyr 1.2.0 ✔ readr 2.2.0
#> ✔ forcats 1.0.1 ✔ stringr 1.6.0
#> ✔ ggplot2 4.0.2 ✔ tibble 3.3.1
#> ✔ lubridate 1.9.5 ✔ tidyr 1.3.2
#> ✔ purrr 1.2.1
#> ── Conflicts ─────────────────────────────────────── tidyverse_conflicts() ──
#> ✖ dplyr::filter() masks stats::filter()
#> ✖ dplyr::lag() masks stats::lag()
#> ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors1 Trực quan hóa dữ liệu
1.1 Giới thiệu
“Đồ thị đơn giản đã mang lại nhiều thông tin cho tâm trí của nhà phân tích dữ liệu hơn bất kỳ công cụ nào khác.” — John Tukey
R có nhiều hệ thống để tạo đồ thị, nhưng ggplot2 là một trong những hệ thống thanh lịch và linh hoạt nhất. ggplot2 triển khai ngữ pháp đồ họa (grammar of graphics), một hệ thống nhất quán để mô tả và xây dựng đồ thị. Với ggplot2, bạn có thể làm được nhiều hơn và nhanh hơn bằng cách học một hệ thống và áp dụng nó ở nhiều nơi.
Chương này sẽ dạy bạn cách visualization dữ liệu bằng ggplot2. Chúng ta sẽ bắt đầu bằng việc tạo một biểu đồ phân tán (scatterplot) đơn giản và sử dụng nó để giới thiệu các mapping thuộc tính đồ họa (aesthetic mappings) và các đối tượng đồ họa (geoms) – những khối xây dựng cơ bản của ggplot2. Sau đó, chúng ta sẽ hướng dẫn bạn cách visualization phân phối (distribution) của các biến đơn lẻ cũng như visualization mối quan hệ giữa hai hoặc nhiều biến. Chúng ta sẽ kết thúc với việc lưu biểu đồ và các mẹo xử lý sự cố.
1.1.1 Điều kiện tiên quyết
Chương này tập trung vào ggplot2, một trong những package cốt lõi của tidyverse. Để truy cập các bộ dữ liệu, trang trợ giúp và function được sử dụng trong chương này, hãy tải tidyverse bằng cách chạy:
Một dòng mã đó tải các package cốt lõi của tidyverse; các package mà bạn sẽ sử dụng trong hầu hết mọi phân tích dữ liệu. Nó cũng cho bạn biết những function nào từ tidyverse xung đột với các function trong base R (hoặc từ các package khác mà bạn có thể đã tải)1.
Nếu bạn chạy mã này và nhận được thông báo lỗi there is no package called 'tidyverse', bạn cần cài đặt nó trước, sau đó chạy library() một lần nữa.
install.packages("tidyverse")
library(tidyverse)Bạn chỉ cần cài đặt một package một lần, nhưng bạn cần tải nó mỗi khi bắt đầu một phiên làm việc mới.
Ngoài tidyverse, chúng ta cũng sẽ sử dụng package palmerpenguins, bao gồm bộ dữ liệu penguins chứa các phép đo cơ thể của chim cánh cụt trên ba hòn đảo trong Quần đảo Palmer, và package ggthemes, cung cấp bảng màu an toàn cho người mù màu.
library(palmerpenguins)
#>
#> Attaching package: 'palmerpenguins'
#> The following objects are masked from 'package:datasets':
#>
#> penguins, penguins_raw
library(ggthemes)1.2 Những bước đầu tiên
Chim cánh cụt có chân chèo dài hơn nặng hơn hay nhẹ hơn so với chim cánh cụt có chân chèo ngắn hơn? Có lẽ bạn đã có câu trả lời, nhưng hãy thử làm cho câu trả lời của bạn chính xác hơn. Mối quan hệ giữa chiều dài chân chèo và khối lượng cơ thể trông như thế nào? Nó là dương? Âm? Tuyến tính? Phi tuyến? Mối quan hệ có thay đổi theo loài chim cánh cụt không? Còn theo hòn đảo nơi chim cánh cụt sống thì sao? Hãy tạo các biểu đồ trực quan mà chúng ta có thể sử dụng để trả lời những câu hỏi này.
1.2.1 Khung dữ liệu penguins
Bạn có thể kiểm tra câu trả lời của mình cho những câu hỏi trên với data frame penguins có trong palmerpenguins (hay còn gọi là palmerpenguins::penguins). Khung dữ liệu là một tập hợp hình chữ nhật gồm các biến (variable) (trong các column) và các quan sát (observation) (trong các row). penguins chứa 344 quan sát được thu thập và cung cấp bởi Tiến sĩ Kristen Gorman và Trạm Palmer, LTER Nam Cực2.
Để cuộc thảo luận dễ dàng hơn, hãy định nghĩa một số thuật ngữ:
Một biến (variable) là một đại lượng, chất lượng, hoặc thuộc tính mà bạn có thể đo lường.
Một giá trị (value) là trạng thái của một biến khi bạn đo nó. Giá trị của một biến có thể thay đổi từ phép đo này sang phép đo khác.
Một quan sát (observation) là một tập hợp các phép đo được thực hiện trong các điều kiện tương tự (bạn thường thực hiện tất cả các phép đo trong một quan sát cùng một lúc và trên cùng một đối tượng). Một quan sát sẽ chứa nhiều giá trị, mỗi giá trị liên kết với một biến khác nhau. Đôi khi chúng ta sẽ gọi một quan sát là một điểm dữ liệu.
Dữ liệu dạng bảng (tabular data) là một tập hợp các giá trị, mỗi giá trị liên kết với một biến và một quan sát. Dữ liệu dạng bảng là gọn gàng (tidy) nếu mỗi giá trị được đặt trong “ô” riêng của nó, mỗi biến trong column riêng, và mỗi quan sát trong row riêng.
Trong ngữ cảnh này, một biến đề cập đến một thuộc tính của tất cả chim cánh cụt, và một quan sát đề cập đến tất cả các thuộc tính của một con chim cánh cụt.
Gõ tên data frame vào console và R sẽ in bản xem trước nội dung của nó. Lưu ý rằng nó hiển thị tibble ở đầu bản xem trước này. Trong tidyverse, chúng ta sử dụng các data frame đặc biệt gọi là tibble mà bạn sẽ tìm hiểu thêm sớm thôi.
penguins
#> # A tibble: 344 × 8
#> species island bill_length_mm bill_depth_mm flipper_length_mm
#> <fct> <fct> <dbl> <dbl> <int>
#> 1 Adelie Torgersen 39.1 18.7 181
#> 2 Adelie Torgersen 39.5 17.4 186
#> 3 Adelie Torgersen 40.3 18 195
#> 4 Adelie Torgersen NA NA NA
#> 5 Adelie Torgersen 36.7 19.3 193
#> 6 Adelie Torgersen 39.3 20.6 190
#> # ℹ 338 more rows
#> # ℹ 3 more variables: body_mass_g <int>, sex <fct>, year <int>Khung dữ liệu này chứa 8 column. Để có một góc nhìn khác, nơi bạn có thể thấy tất cả các biến và một vài quan sát đầu tiên của mỗi biến, hãy sử dụng glimpse(). Hoặc, nếu bạn đang ở trong RStudio, hãy chạy View(penguins) để mở trình xem dữ liệu tương tác.
glimpse(penguins)
#> Rows: 344
#> Columns: 8
#> $ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, A…
#> $ island <fct> Torgersen, Torgersen, Torgersen, Torgersen, Torge…
#> $ bill_length_mm <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34.…
#> $ bill_depth_mm <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18.…
#> $ flipper_length_mm <int> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190, …
#> $ body_mass_g <int> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 347…
#> $ sex <fct> male, female, female, NA, female, male, female, m…
#> $ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2…Trong số các biến trong penguins có:
species: loài chim cánh cụt (Adelie, Chinstrap, hoặc Gentoo).flipper_length_mm: chiều dài chân chèo của chim cánh cụt, tính bằng milimét.body_mass_g: khối lượng cơ thể của chim cánh cụt, tính bằng gam.
Để tìm hiểu thêm về penguins, hãy mở trang trợ giúp của nó bằng cách chạy ?penguins.
1.2.2 Mục tiêu cuối cùng
Mục tiêu cuối cùng của chúng ta trong chương này là tái tạo biểu đồ trực quan sau đây, hiển thị mối quan hệ giữa chiều dài chân chèo và khối lượng cơ thể của những con chim cánh cụt này, có tính đến loài chim cánh cụt.
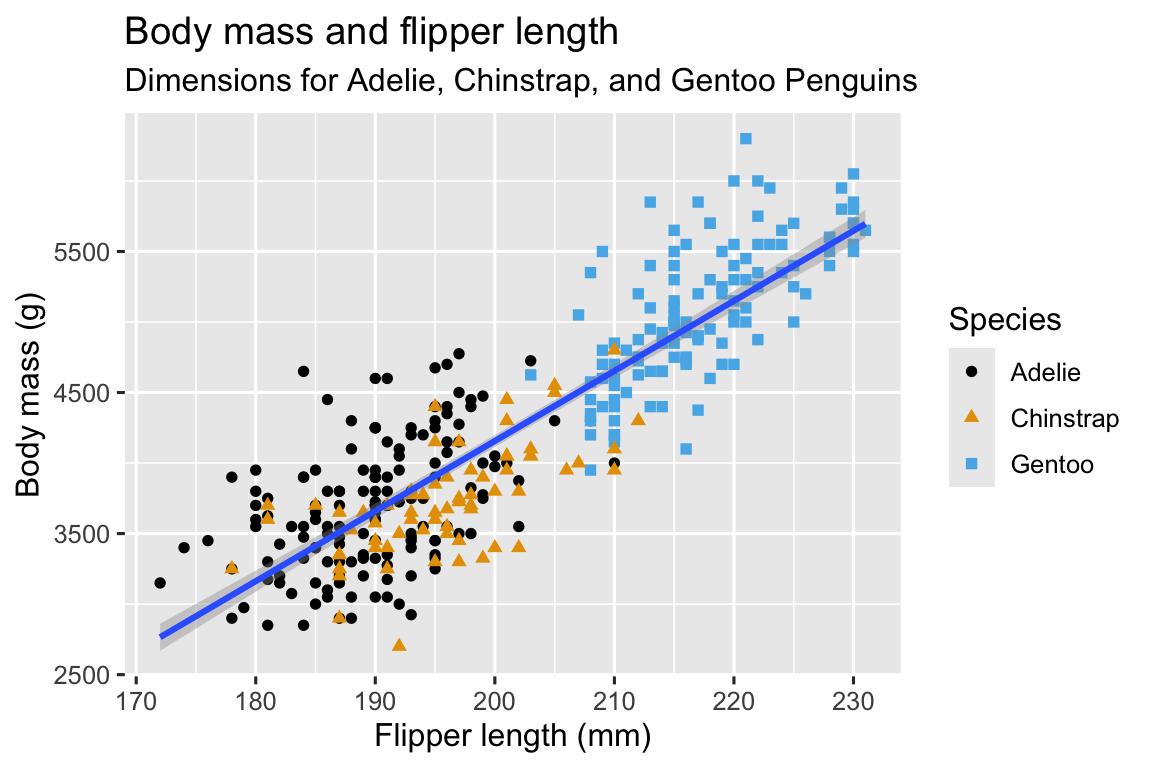
1.2.3 Tạo một ggplot
Hãy tái tạo biểu đồ này từng bước một.
Với ggplot2, bạn bắt đầu một biểu đồ với function ggplot(), định nghĩa một đối tượng biểu đồ mà sau đó bạn thêm các lớp (layer) vào. Đối số đầu tiên của ggplot() là bộ dữ liệu để sử dụng trong đồ thị và vì vậy ggplot(data = penguins) tạo một đồ thị trống được chuẩn bị sẵn để hiển thị dữ liệu penguins, nhưng vì chúng ta chưa cho nó biết cách visualization nó, nên hiện tại nó trống. Đây không phải là một biểu đồ thú vị lắm, nhưng bạn có thể nghĩ về nó như một khung vẽ trống mà bạn sẽ vẽ các lớp còn lại của biểu đồ lên đó.
ggplot(data = penguins)
Tiếp theo, chúng ta cần cho ggplot() biết thông tin từ dữ liệu sẽ được biểu diễn trực quan như thế nào. Đối số mapping của function ggplot() định nghĩa cách các biến trong bộ dữ liệu của bạn được mapping (mapping) đến các thuộc tính trực quan (thuộc tính đồ họa (aesthetic)) của biểu đồ. Đối số mapping luôn được định nghĩa trong function aes(), và các argument x và y của aes() chỉ định biến nào được mapping đến trục x và y. Hiện tại, chúng ta sẽ chỉ mapping chiều dài chân chèo đến thuộc tính đồ họa x và khối lượng cơ thể đến thuộc tính đồ họa y. ggplot2 tìm kiếm các biến được mapping trong argument data, trong trường hợp này là penguins.
Biểu đồ sau đây cho thấy kết quả của việc thêm các mapping này.
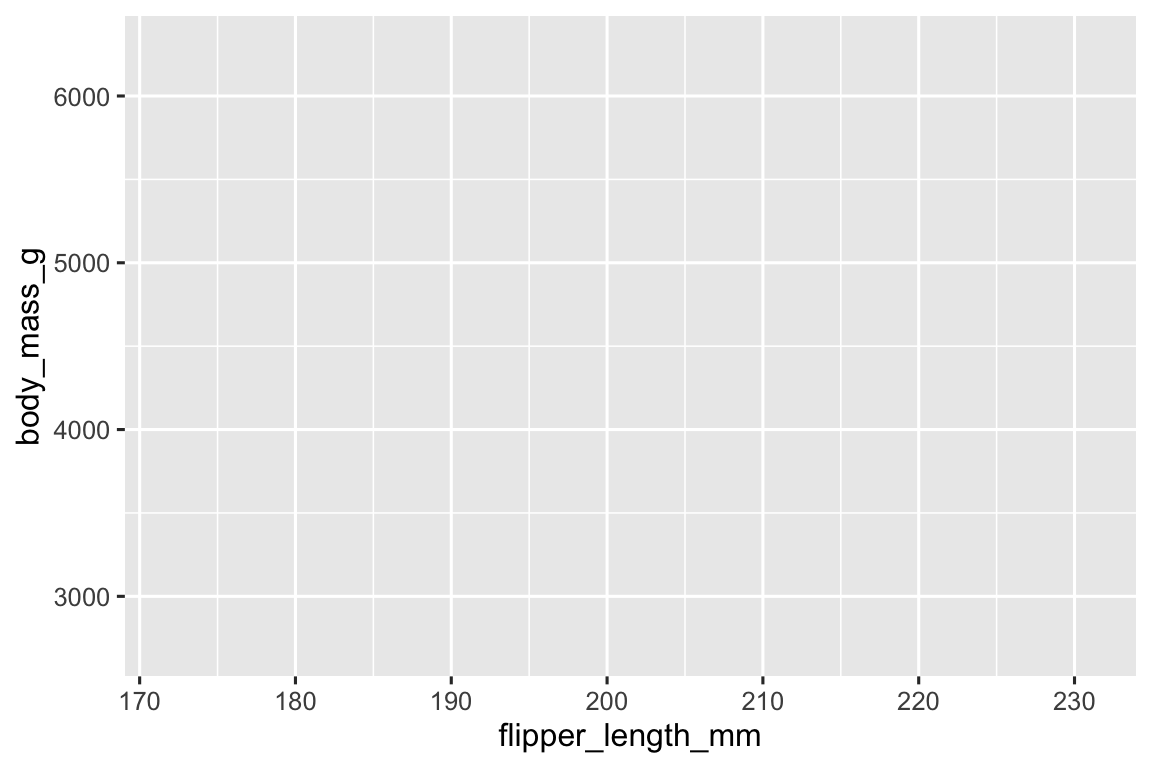
Khung vẽ trống của chúng ta bây giờ đã có thêm cấu trúc – rõ ràng nơi chiều dài chân chèo sẽ được hiển thị (trên trục x) và nơi khối lượng cơ thể sẽ được hiển thị (trên trục y). Nhưng bản thân chim cánh cụt vẫn chưa có trên biểu đồ. Điều này là do chúng ta chưa diễn đạt, trong mã của mình, cách biểu diễn các quan sát từ data frame trên biểu đồ.
Để làm điều đó, chúng ta cần định nghĩa một geom: đối tượng đồ họa mà biểu đồ sử dụng để biểu diễn dữ liệu. Các geoms này được cung cấp trong ggplot2 với các function bắt đầu bằng geom_. Người ta thường mô tả biểu đồ bằng loại geom mà biểu đồ sử dụng. Ví dụ, biểu đồ column (bar chart) sử dụng geom column (geom_bar()), biểu đồ đường sử dụng geom đường (geom_line()), biểu đồ hộp (box plot) sử dụng geom hộp (geom_boxplot()), biểu đồ phân tán sử dụng geom điểm (geom_point()), và cứ thế tiếp tục.
Function geom_point() thêm một lớp điểm vào biểu đồ của bạn, tạo ra một biểu đồ phân tán. ggplot2 đi kèm với nhiều function geom, mỗi function thêm một loại lớp khác nhau vào biểu đồ. Bạn sẽ học rất nhiều geom trong suốt cuốn sách, đặc biệt trong Chương 9.
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point()
#> Warning: Removed 2 rows containing missing values or values outside the scale range
#> (`geom_point()`).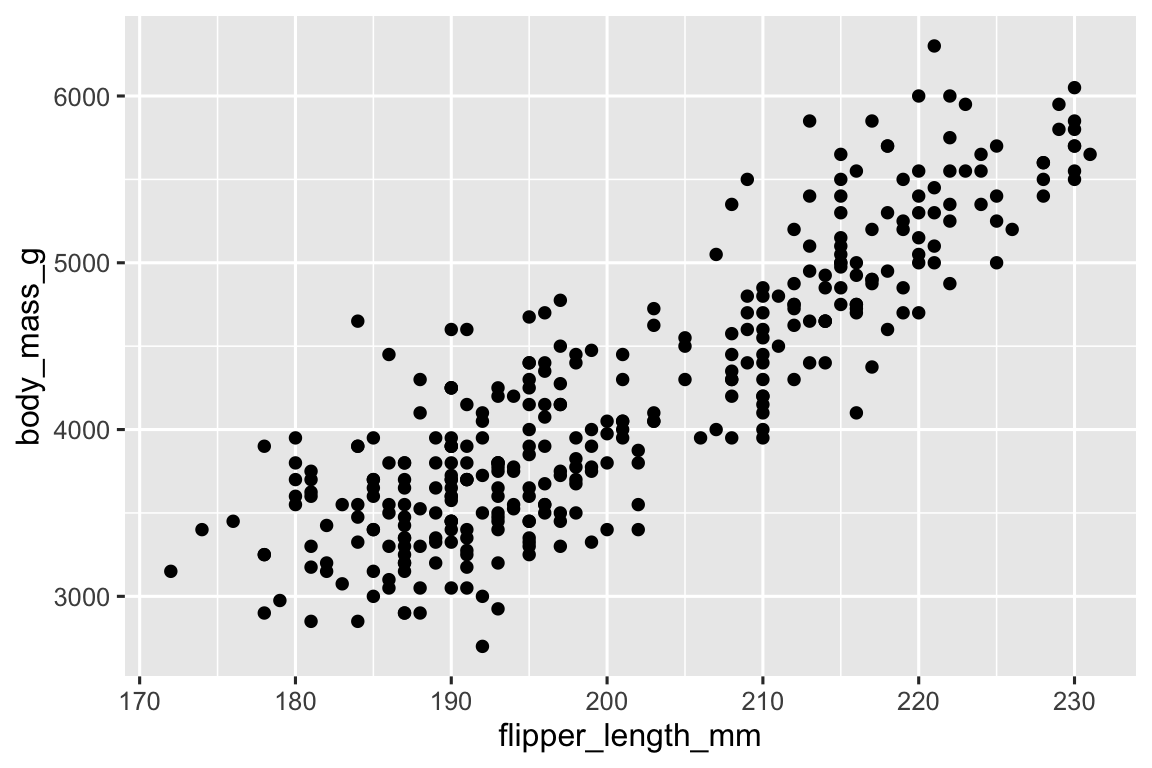
Bây giờ chúng ta có thứ gì đó trông giống như những gì chúng ta nghĩ về “biểu đồ phân tán”. Nó chưa khớp với biểu đồ “mục tiêu cuối cùng” của chúng ta, nhưng sử dụng biểu đồ này chúng ta có thể bắt đầu trả lời câu hỏi đã thúc đẩy việc khám phá của chúng ta: “Mối quan hệ giữa chiều dài chân chèo và khối lượng cơ thể trông như thế nào?” Mối quan hệ có vẻ là dương (khi chiều dài chân chèo tăng, khối lượng cơ thể cũng tăng), khá tuyến tính (các điểm tụ quanh một đường thẳng thay vì một đường cong), và mạnh vừa phải (không có quá nhiều phân tán xung quanh đường đó). Chim cánh cụt có chân chèo dài hơn thường lớn hơn về khối lượng cơ thể.
Trước khi thêm nhiều lớp hơn vào biểu đồ này, hãy dừng lại một chút và xem lại thông báo cảnh báo mà chúng ta nhận được:
Removed 2 rows containing missing values (
geom_point()).
Chúng ta thấy thông báo này vì có hai con chim cánh cụt trong bộ dữ liệu của chúng ta có giá trị khối lượng cơ thể và/hoặc chiều dài chân chèo bị thiếu và ggplot2 không có cách nào biểu diễn chúng trên biểu đồ nếu thiếu cả hai giá trị này. Giống như R, ggplot2 tuân theo triết lý rằng các giá trị bị thiếu không bao giờ nên biến mất một cách âm thầm. Loại cảnh báo này có lẽ là một trong những loại cảnh báo phổ biến nhất mà bạn sẽ thấy khi làm việc với dữ liệu thực – giá trị bị thiếu là một vấn đề rất phổ biến và bạn sẽ tìm hiểu thêm về chúng trong suốt cuốn sách, đặc biệt trong Chương 18. Đối với các biểu đồ còn lại trong chương này, chúng ta sẽ tắt cảnh báo này để nó không được in kèm với mỗi biểu đồ chúng ta tạo.
1.2.4 Thêm thuộc tính đồ họa và lớp
Biểu đồ phân tán rất hữu ích để hiển thị mối quan hệ giữa hai biến số (numerical), nhưng luôn là một ý tưởng tốt để hoài nghi về bất kỳ mối quan hệ rõ ràng nào giữa hai biến và tự hỏi liệu có các biến khác giải thích hoặc thay đổi bản chất của mối quan hệ rõ ràng này không. Ví dụ, mối quan hệ giữa chiều dài chân chèo và khối lượng cơ thể có khác nhau theo loài không? Hãy đưa loài vào biểu đồ của chúng ta và xem liệu điều này có tiết lộ thêm thông tin chi tiết nào về mối quan hệ rõ ràng giữa các biến này không. Chúng ta sẽ làm điều này bằng cách biểu diễn loài bằng các điểm có màu khác nhau.
Để đạt được điều này, chúng ta cần thay đổi thuộc tính đồ họa hay geom? Nếu bạn đoán “trong mapping thuộc tính đồ họa, bên trong aes()”, bạn đang bắt đầu nắm bắt được cách tạo visualization dữ liệu với ggplot2! Và nếu không, đừng lo. Trong suốt cuốn sách, bạn sẽ tạo thêm nhiều ggplot và có nhiều cơ hội hơn để kiểm tra trực giác của mình khi tạo chúng.
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g, color = species)
) +
geom_point()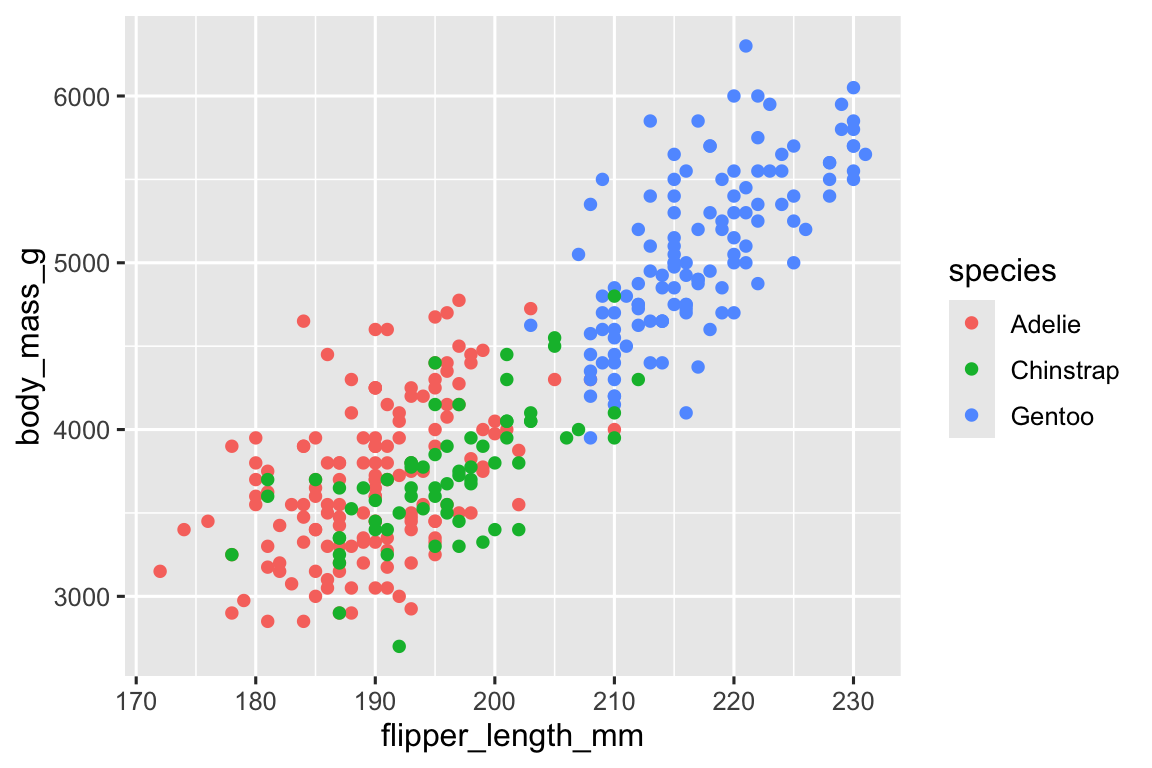
Khi một biến phân loại (categorical) được mapping đến một thuộc tính đồ họa, ggplot2 sẽ tự động gán một giá trị duy nhất của thuộc tính đồ họa đó (ở đây là một màu duy nhất) cho mỗi mức duy nhất của biến (mỗi loài trong ba loài), một quá trình được gọi là chia tỷ lệ (scaling). ggplot2 cũng sẽ thêm một chú giải giải thích giá trị nào tương ứng với mức nào.
Bây giờ hãy thêm một lớp nữa: một đường cong trơn hiển thị mối quan hệ giữa khối lượng cơ thể và chiều dài chân chèo. Trước khi bạn tiếp tục, hãy quay lại mã ở trên, và nghĩ xem chúng ta có thể thêm điều này vào biểu đồ hiện có như thế nào.
Vì đây là một geom mới biểu diễn dữ liệu của chúng ta, chúng ta sẽ thêm một geom mới như một lớp trên geom điểm của chúng ta: geom_smooth(). Và chúng ta sẽ chỉ định rằng chúng ta muốn vẽ đường khớp tốt nhất dựa trên mô hình tuyến tính (linear model) với method = "lm".
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g, color = species)
) +
geom_point() +
geom_smooth(method = "lm")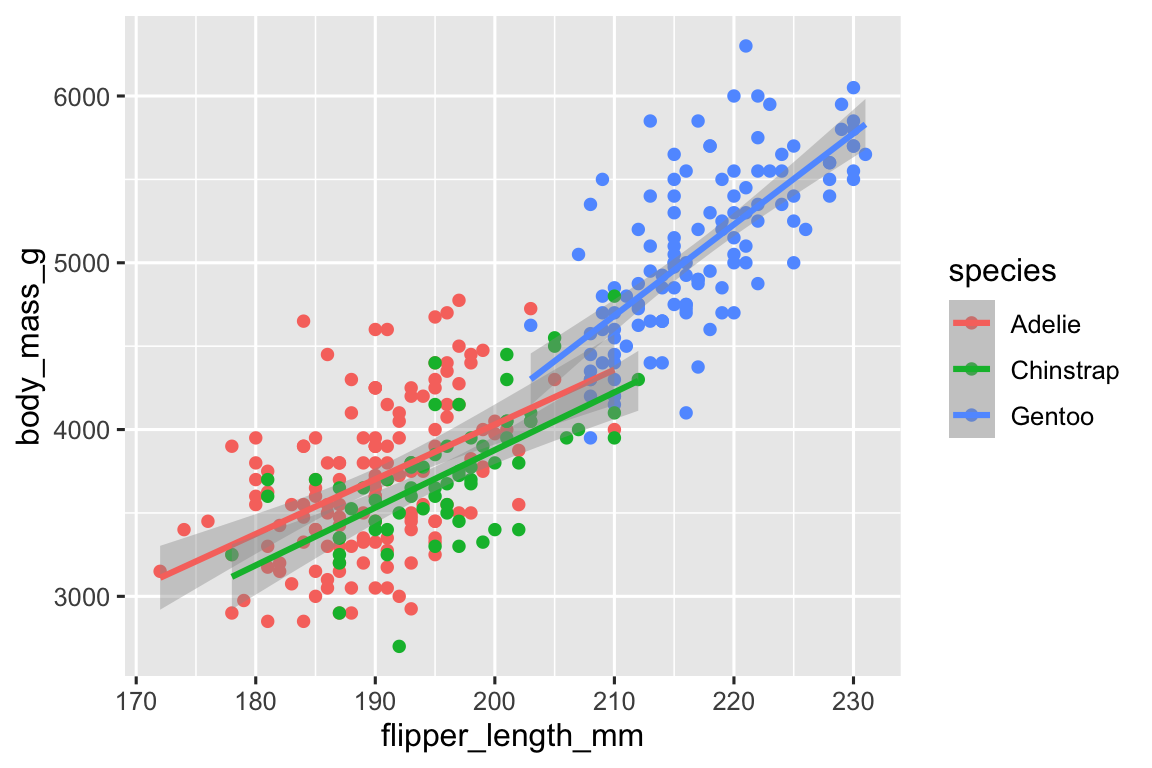
Chúng ta đã thêm thành công các đường, nhưng biểu đồ này không giống biểu đồ từ Phần 1.2.2, vốn chỉ có một đường cho toàn bộ tập dữ liệu thay vì các đường riêng biệt cho mỗi loài chim cánh cụt.
Khi các mapping thuộc tính đồ họa được định nghĩa trong ggplot(), ở mức toàn cục, chúng được truyền xuống mỗi lớp geom tiếp theo của biểu đồ. Tuy nhiên, mỗi function geom trong ggplot2 cũng có thể nhận một argument mapping, cho phép mapping thuộc tính đồ họa ở mức cục bộ được thêm vào những mapping kế thừa từ mức toàn cục. Vì chúng ta muốn các điểm được tô màu dựa trên loài nhưng không muốn các đường được tách riêng cho chúng, chúng ta nên chỉ định color = species chỉ cho geom_point().
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point(mapping = aes(color = species)) +
geom_smooth(method = "lm")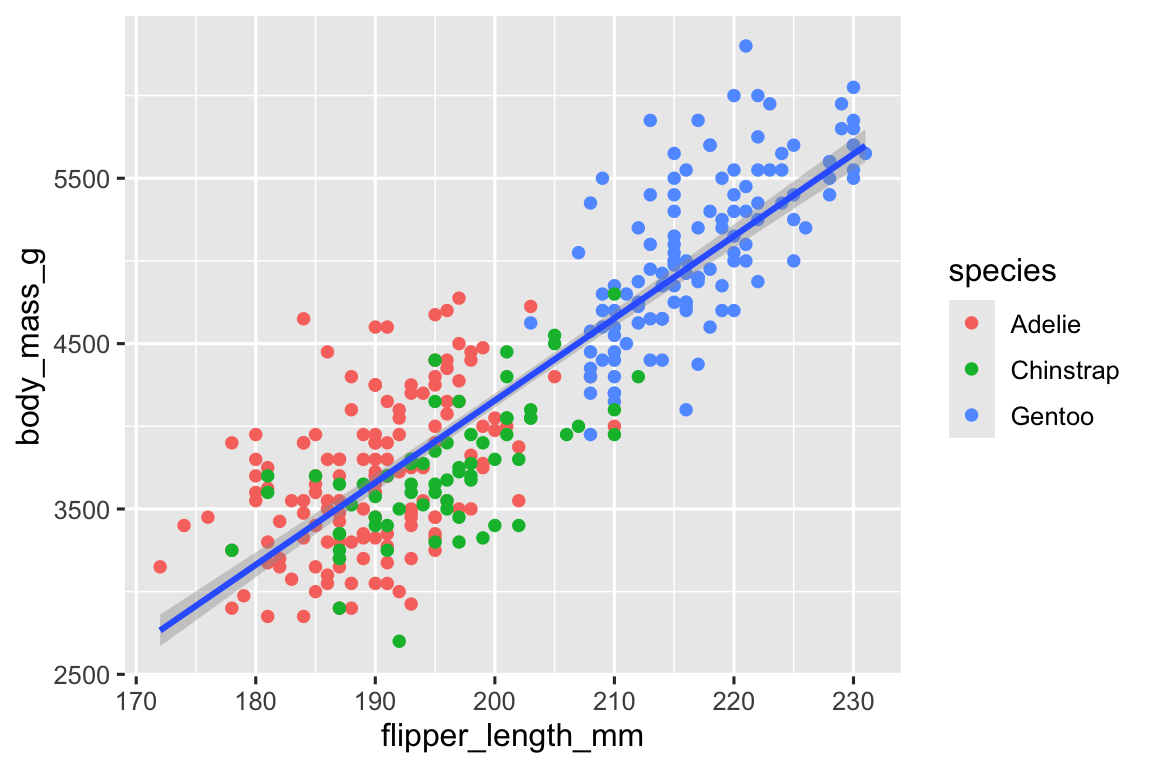
Tuyệt vời! Chúng ta có thứ gì đó trông rất giống mục tiêu cuối cùng của chúng ta, mặc dù nó chưa hoàn hảo. Chúng ta vẫn cần sử dụng các hình dạng khác nhau cho mỗi loài chim cánh cụt và cải thiện nhãn.
Nói chung, không phải là ý tưởng tốt khi biểu diễn thông tin chỉ bằng màu sắc trên biểu đồ, vì mọi người nhận biết màu sắc khác nhau do mù màu hoặc các khác biệt về thị lực màu khác. Do đó, ngoài màu sắc, chúng ta cũng có thể mapping species đến thuộc tính đồ họa shape.
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point(mapping = aes(color = species, shape = species)) +
geom_smooth(method = "lm")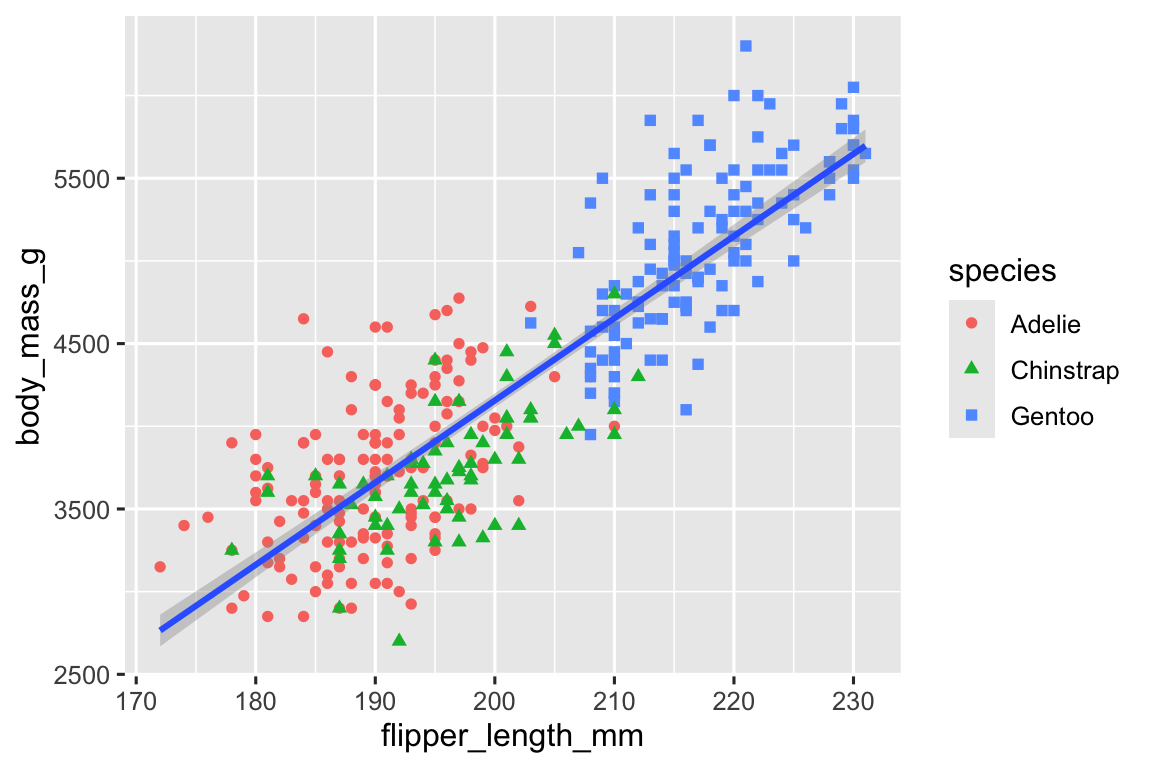
Lưu ý rằng chú giải cũng tự động được cập nhật để phản ánh các hình dạng khác nhau của các điểm.
Và cuối cùng, chúng ta có thể cải thiện nhãn của biểu đồ bằng function labs() trong một lớp mới. Một số argument của labs() có thể tự giải thích: title thêm tiêu đề và subtitle thêm phụ đề cho biểu đồ. Các argument khác khớp với các mapping thuộc tính đồ họa, x là nhãn trục x, y là nhãn trục y, và color và shape định nghĩa nhãn cho chú giải. Ngoài ra, chúng ta có thể cải thiện bảng màu để an toàn cho người mù màu với function scale_color_colorblind() từ package ggthemes.
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point(aes(color = species, shape = species)) +
geom_smooth(method = "lm") +
labs(
title = "Body mass and flipper length",
subtitle = "Dimensions for Adelie, Chinstrap, and Gentoo Penguins",
x = "Flipper length (mm)", y = "Body mass (g)",
color = "Species", shape = "Species"
) +
scale_color_colorblind()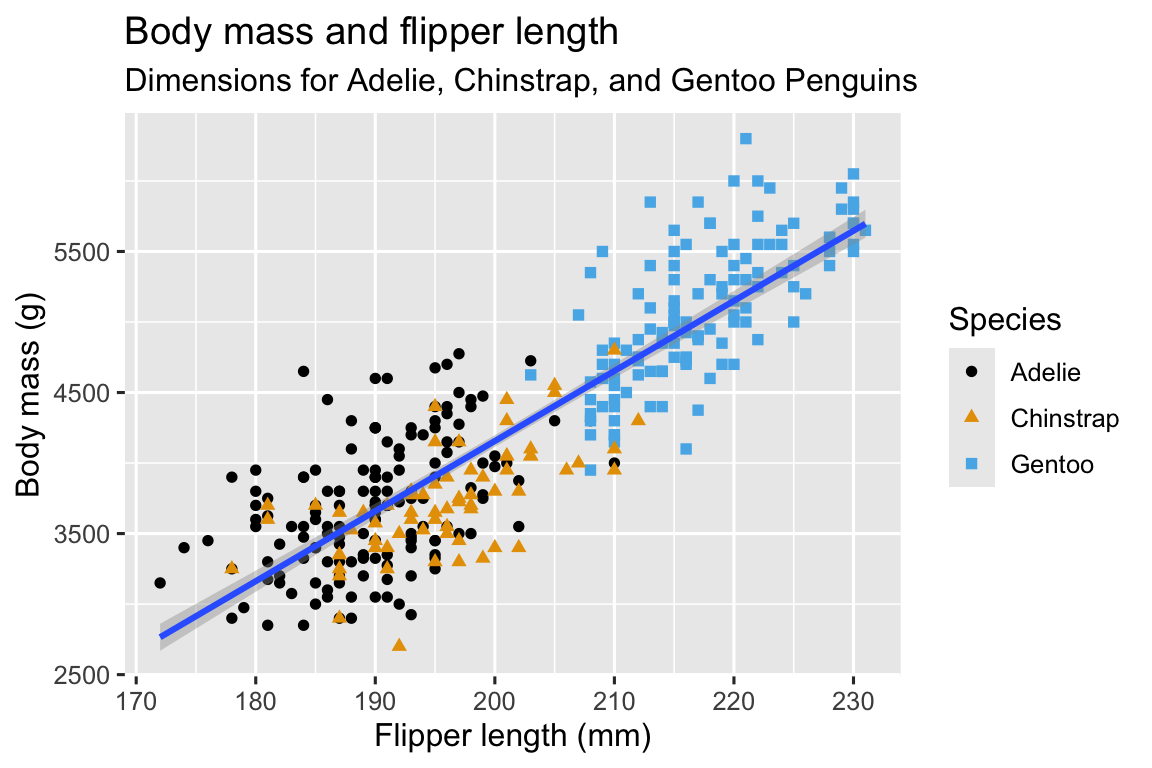
Cuối cùng chúng ta đã có một biểu đồ khớp hoàn hảo với “mục tiêu cuối cùng” của chúng ta!
1.2.5 Bài tập
penguinscó bao nhiêu hàng? Bao nhiêu cột?Biến
bill_depth_mmtrong data framepenguinsmô tả điều gì? Đọc trợ giúp cho?penguinsđể tìm hiểu.Tạo một biểu đồ phân tán của
bill_depth_mmtheobill_length_mm. Nghĩa là, tạo biểu đồ phân tán vớibill_depth_mmtrên trục y vàbill_length_mmtrên trục x. Mô tả mối quan hệ giữa hai biến này.Điều gì xảy ra nếu bạn tạo biểu đồ phân tán của
speciestheobill_depth_mm? Loại geom nào có thể là lựa chọn tốt hơn?-
Tại sao đoạn mã sau đây gây ra lỗi và bạn sẽ sửa nó như thế nào?
ggplot(data = penguins) + geom_point() Đối số
na.rmlàm gì tronggeom_point()? Giá trị mặc định của argument là gì? Tạo một biểu đồ phân tán mà bạn sử dụng thành công argument này được đặt thànhTRUE.Thêm comment sau vào biểu đồ bạn đã tạo trong bài tập trước: “Data come from the palmerpenguins package.” Gợi ý: Xem tài liệu của
labs().-
Tái tạo biểu đồ trực quan sau đây.
bill_depth_mmnên được mapping đến thuộc tính đồ họa nào? Và nó nên được mapping ở mức toàn cục hay mức geom?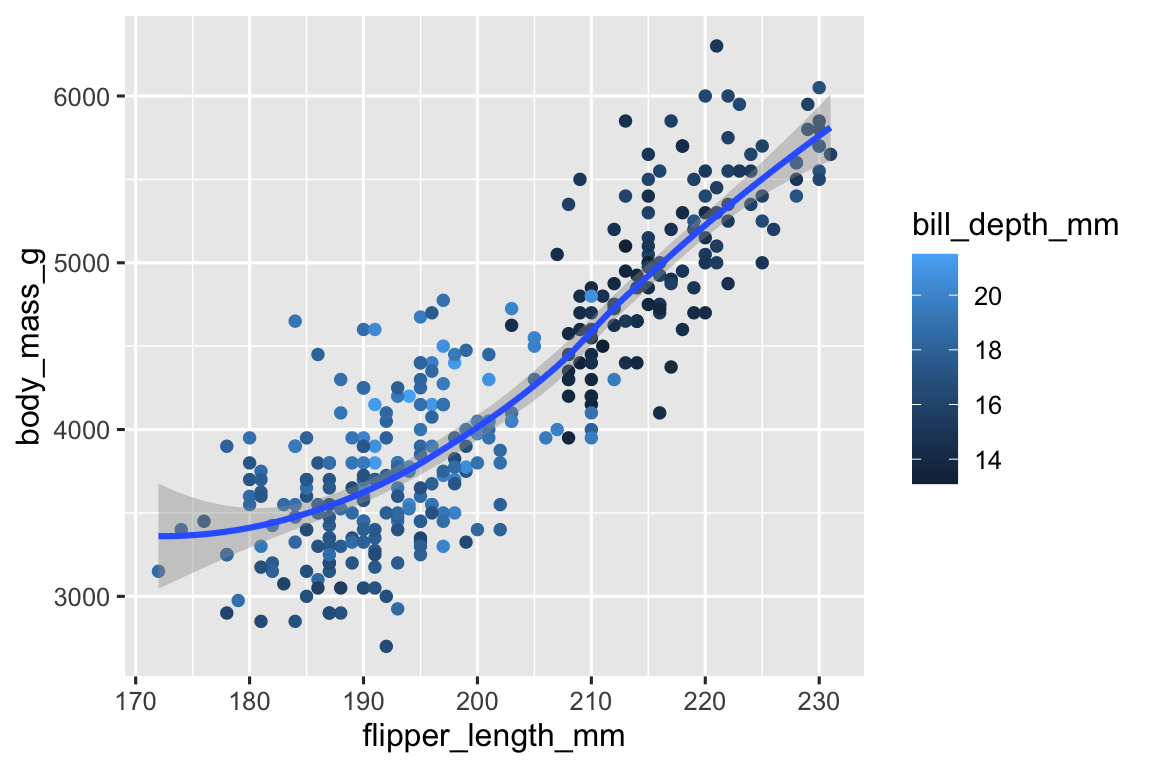
-
Chạy đoạn mã này trong đầu và dự đoán kết quả sẽ trông như thế nào. Sau đó, chạy mã trong R và kiểm tra dự đoán của bạn.
ggplot( data = penguins, mapping = aes(x = flipper_length_mm, y = body_mass_g, color = island) ) + geom_point() + geom_smooth(se = FALSE) -
Hai biểu đồ này sẽ trông khác nhau không? Tại sao/tại sao không?
ggplot( data = penguins, mapping = aes(x = flipper_length_mm, y = body_mass_g) ) + geom_point() + geom_smooth() ggplot() + geom_point( data = penguins, mapping = aes(x = flipper_length_mm, y = body_mass_g) ) + geom_smooth( data = penguins, mapping = aes(x = flipper_length_mm, y = body_mass_g) )
1.3 Các lệnh gọi ggplot2
Khi chúng ta tiến xa hơn khỏi các phần giới thiệu này, chúng ta sẽ chuyển sang cách biểu đạt mã ggplot2 ngắn gọn hơn. Cho đến nay chúng ta đã rất tường minh, điều này hữu ích khi bạn đang học:
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point()Thông thường, một hoặc hai argument đầu tiên của một function quan trọng đến mức bạn nên thuộc lòng chúng. Hai argument đầu tiên của ggplot() là data và mapping, trong phần còn lại của cuốn sách, chúng ta sẽ không cung cấp tên của chúng. Điều này tiết kiệm gõ phím, và bằng cách giảm lượng văn bản thừa, giúp dễ thấy hơn điều gì khác biệt giữa các biểu đồ. Đó là một mối quan tâm lập trình thực sự quan trọng mà chúng ta sẽ quay lại trong Chương 25.
Viết lại biểu đồ trước đó ngắn gọn hơn sẽ cho:
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point()Trong tương lai, bạn cũng sẽ tìm hiểu về pipe, |>, cho phép bạn tạo biểu đồ đó với:
penguins |>
ggplot(aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point()1.4 Trực quan hóa phân phối
Cách bạn visualization phân phối của một biến phụ thuộc vào loại biến: phân loại hay số.
1.4.1 Biến phân loại
Một biến là phân loại (categorical) nếu nó chỉ có thể nhận một trong một tập hợp nhỏ các giá trị. Để kiểm tra phân phối của một biến phân loại, bạn có thể sử dụng biểu đồ column (bar chart). Chiều cao của các thanh hiển thị có bao nhiêu quan sát xảy ra với mỗi giá trị x.
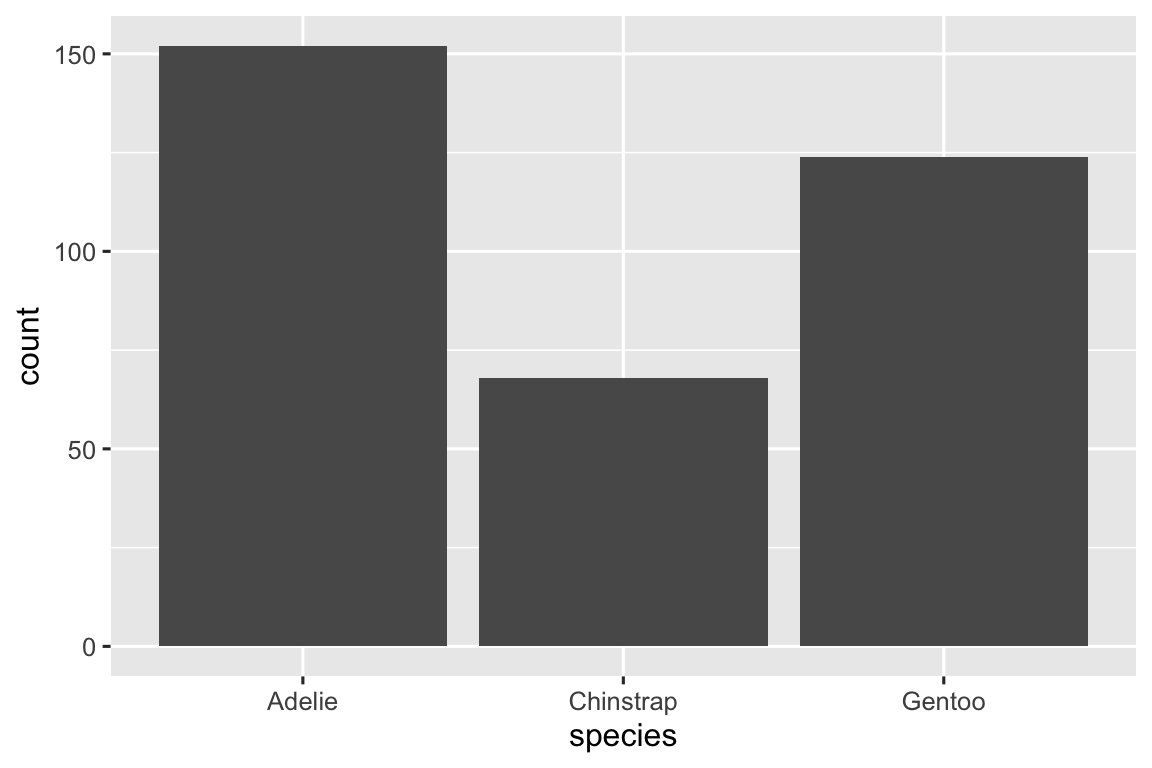
Trong biểu đồ column của các biến phân loại với các mức không có thứ tự, như species của chim cánh cụt ở trên, thường nên sắp xếp lại các thanh dựa trên tần suất của chúng. Làm như vậy đòi hỏi phải chuyển đổi biến thành một factor (cách R xử lý dữ liệu phân loại) và sau đó sắp xếp lại các mức của factor đó.
ggplot(penguins, aes(x = fct_infreq(species))) +
geom_bar()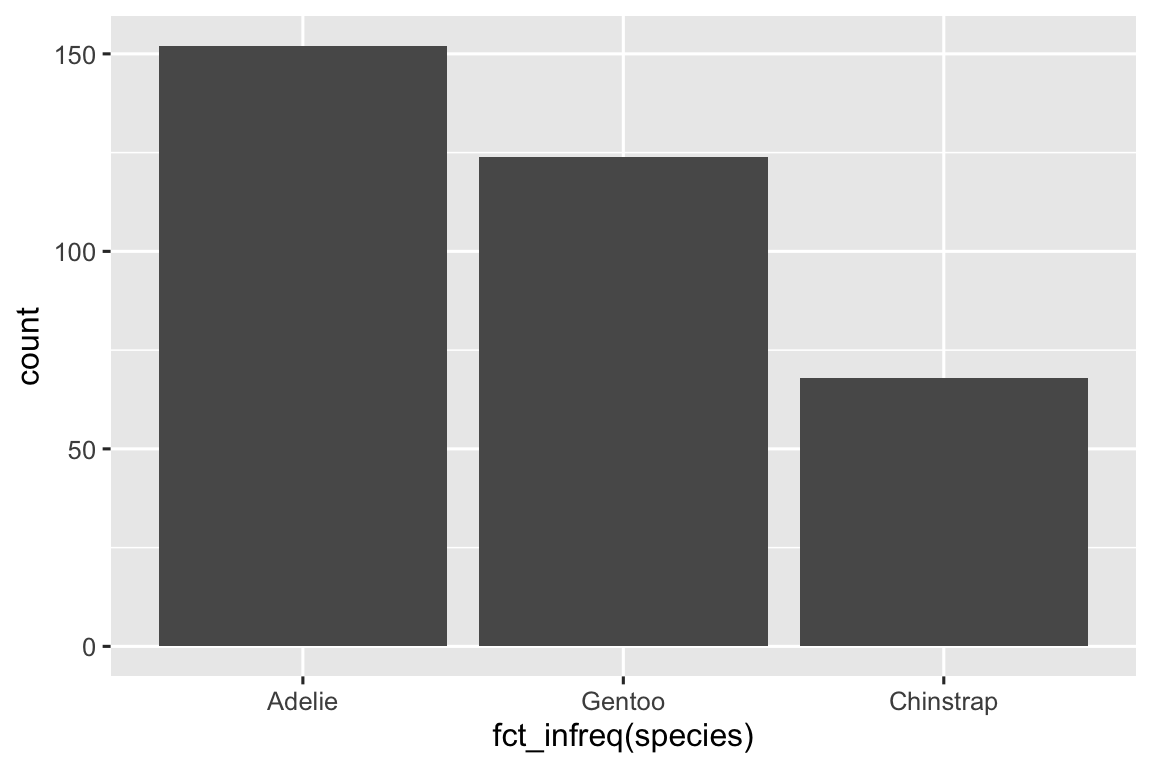
Bạn sẽ tìm hiểu thêm về factor và các function xử lý factor (như fct_infreq() được hiển thị ở trên) trong Chương 16.
1.4.2 Biến số
Một biến là số (numerical) (hay định lượng) nếu nó có thể nhận nhiều giá trị số, và việc cộng, trừ, hoặc lấy trung bình với các giá trị đó là có ý nghĩa. Biến số có thể liên tục hoặc rời rạc.
Một cách visualization thường được sử dụng cho phân phối của biến liên tục là biểu đồ tần suất (histogram).
ggplot(penguins, aes(x = body_mass_g)) +
geom_histogram(binwidth = 200)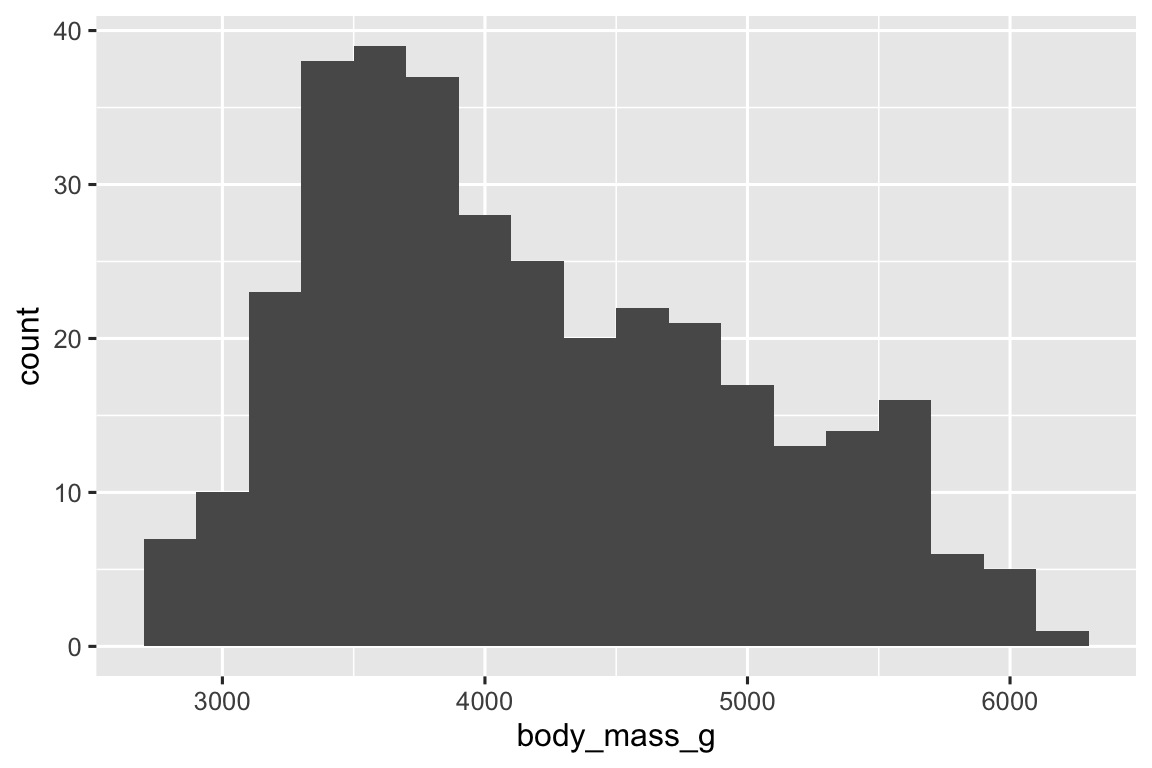
Biểu đồ tần suất chia trục x thành các khoảng (bin) cách đều nhau và sau đó sử dụng chiều cao của thanh để hiển thị số lượng quan sát rơi vào mỗi khoảng. Trong đồ thị trên, thanh cao nhất cho thấy 39 quan sát có giá trị body_mass_g từ 3.500 đến 3.700 gam, là các cạnh trái và phải của thanh.
Bạn có thể đặt chiều rộng của các khoảng trong biểu đồ tần suất với argument binwidth, được đo bằng đơn vị của biến x. Bạn nên luôn thử nghiệm nhiều binwidth khác nhau khi làm việc với biểu đồ tần suất, vì các binwidth khác nhau có thể tiết lộ các mẫu khác nhau. Trong các biểu đồ bên dưới, binwidth 20 quá hẹp, dẫn đến quá nhiều thanh, khiến khó xác định hình dạng của phân phối. Tương tự, binwidth 2.000 quá cao, dẫn đến tất cả dữ liệu được gộp vào chỉ ba thanh, và cũng khiến khó xác định hình dạng của phân phối. Binwidth 200 cung cấp sự cân bằng hợp lý.
ggplot(penguins, aes(x = body_mass_g)) +
geom_histogram(binwidth = 20)
ggplot(penguins, aes(x = body_mass_g)) +
geom_histogram(binwidth = 2000)
Một cách visualization thay thế cho phân phối của biến số là biểu đồ mật độ (density plot). Biểu đồ mật độ là phiên bản được làm mịn của biểu đồ tần suất và là một lựa chọn thay thế thực tế, đặc biệt cho dữ liệu liên tục đến từ một phân phối trơn cơ bản. Chúng ta sẽ không đi vào cách geom_density() ước lượng mật độ (bạn có thể đọc thêm về điều đó trong tài liệu của hàm), nhưng hãy giải thích cách đường cong mật độ được vẽ bằng một phép so sánh. Hãy tưởng tượng một biểu đồ tần suất làm từ các khối gỗ. Sau đó, tưởng tượng rằng bạn thả một sợi mì spaghetti đã nấu chín lên trên nó. Hình dạng mà sợi mì sẽ tạo khi phủ trên các khối có thể được coi là hình dạng của đường cong mật độ. Nó hiển thị ít chi tiết hơn biểu đồ tần suất nhưng có thể giúp dễ dàng nắm bắt nhanh hình dạng của phân phối, đặc biệt liên quan đến các đỉnh và độ lệch.
ggplot(penguins, aes(x = body_mass_g)) +
geom_density()
#> Warning: Removed 2 rows containing non-finite outside the scale range
#> (`stat_density()`).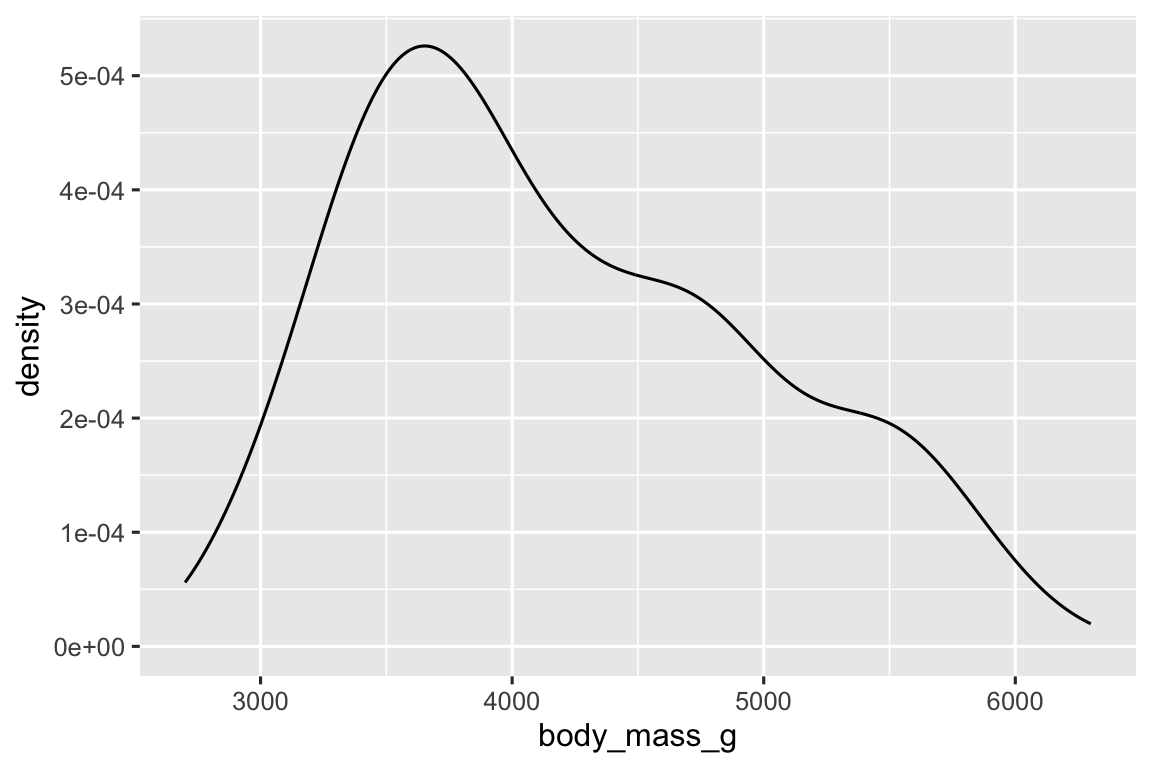
1.4.3 Bài tập
Tạo biểu đồ column của
speciestrongpenguins, trong đó bạn gánspeciescho thuộc tính đồ họay. Biểu đồ này khác như thế nào?-
Hai biểu đồ sau đây khác nhau như thế nào? Thuộc tính thẩm mỹ nào,
colorhayfill, hữu ích hơn cho việc thay đổi màu sắc của các thanh? Đối số
binstronggeom_histogram()làm gì?Tạo biểu đồ tần suất của biến
carattrong bộ dữ liệudiamondscó sẵn khi bạn tải package tidyverse. Thử nghiệm với các binwidth khác nhau. Binwidth nào tiết lộ các mẫu thú vị nhất?
1.5 Trực quan hóa mối quan hệ
Để visualization một mối quan hệ, chúng ta cần có ít nhất hai biến được mapping đến các thuộc tính đồ họa của biểu đồ. Trong các phần tiếp theo, bạn sẽ tìm hiểu về các biểu đồ thường được sử dụng để visualization mối quan hệ giữa hai hoặc nhiều biến và các geom được sử dụng để tạo chúng.
1.5.1 Một biến số và một biến phân loại
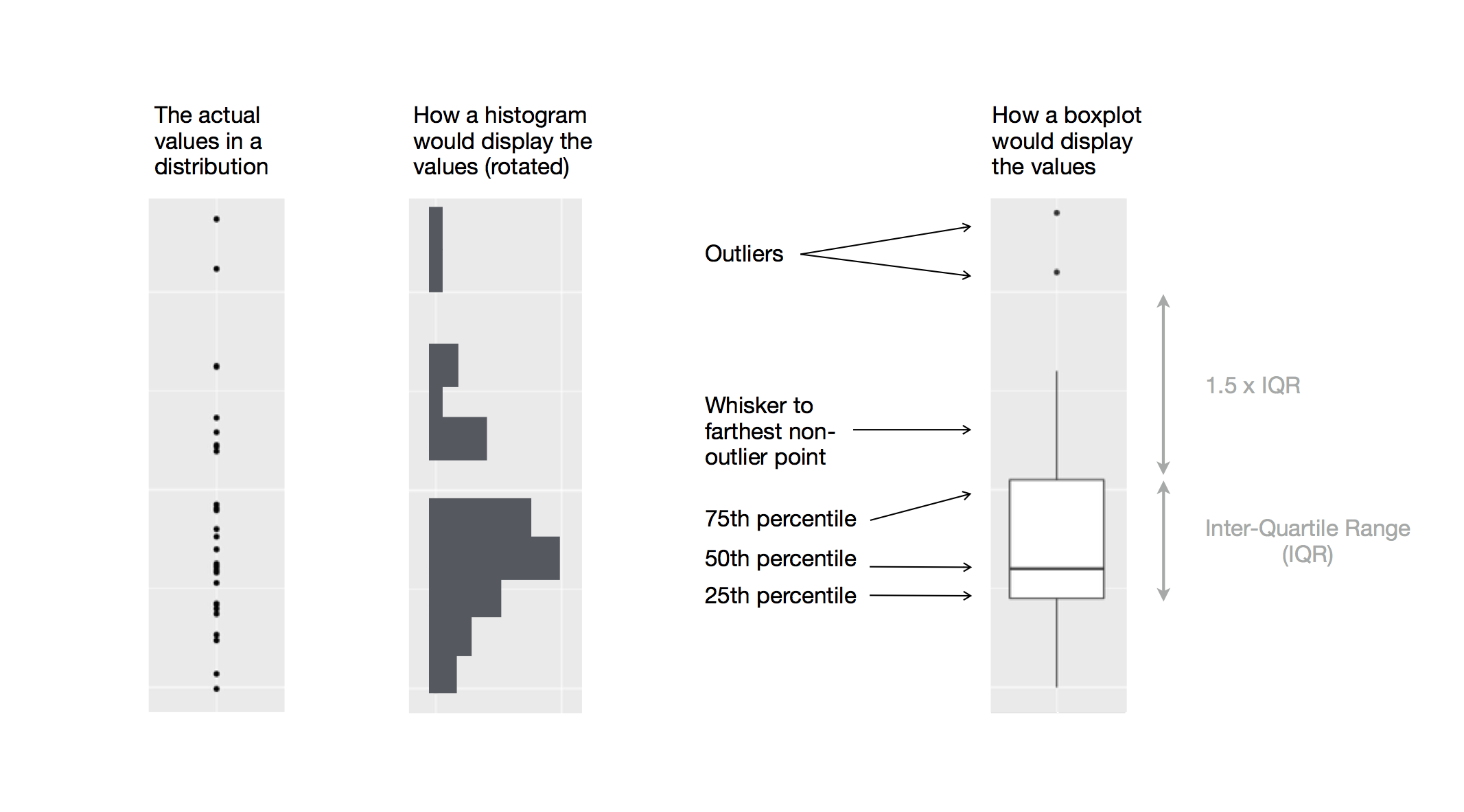
Để visualization mối quan hệ giữa một biến số và một biến phân loại, chúng ta có thể sử dụng biểu đồ hộp (box plot) song song. Biểu đồ hộp là một loại ký hiệu trực quan rút gọn cho các thước đo vị trí (phân vị) mô tả một phân phối. Nó cũng hữu ích để xác định các giá trị ngoại lai tiềm năng. Như được hiển thị trong Hình 1.1, mỗi biểu đồ hộp bao gồm:
Một hộp chỉ ra phạm vi của nửa giữa dữ liệu, một khoảng cách được gọi là khoảng tứ phân vị (interquartile range, IQR), kéo dài từ phân vị thứ 25 đến phân vị thứ 75 của phân phối. Ở giữa hộp là một đường hiển thị trung vị (median), tức phân vị thứ 50 của phân phối. Ba đường này cho bạn cảm nhận về độ phân tán của phân phối và liệu phân phối có đối xứng quanh trung vị hay lệch về một phía.
Các điểm trực quan hiển thị các quan sát nằm cách xa hơn 1,5 lần IQR từ mỗi cạnh của hộp. Các điểm ngoại lai này là bất thường nên được vẽ riêng lẻ.
Một đường (hoặc râu) kéo dài từ mỗi đầu của hộp đến điểm không phải ngoại lai xa nhất trong phân phối.
Hãy xem xét phân phối khối lượng cơ thể theo loài bằng geom_boxplot():
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_boxplot()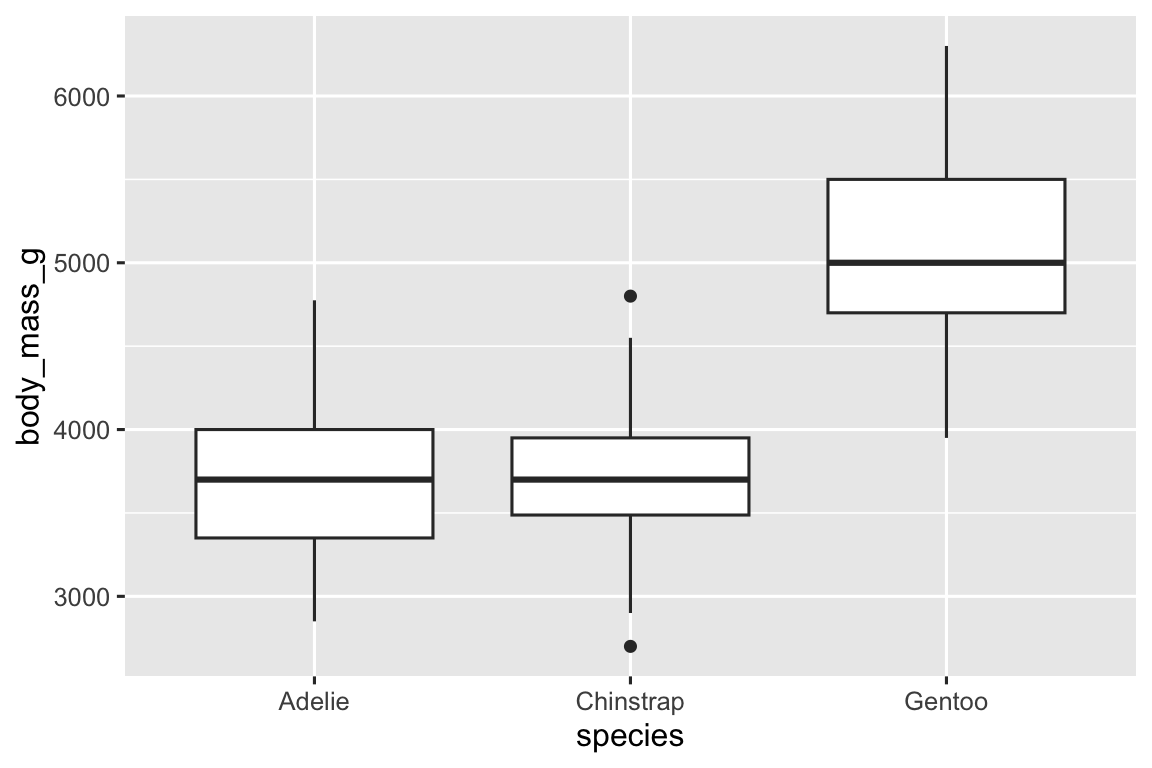
Ngoài ra, chúng ta có thể tạo biểu đồ mật độ với geom_density().
ggplot(penguins, aes(x = body_mass_g, color = species)) +
geom_density(linewidth = 0.75)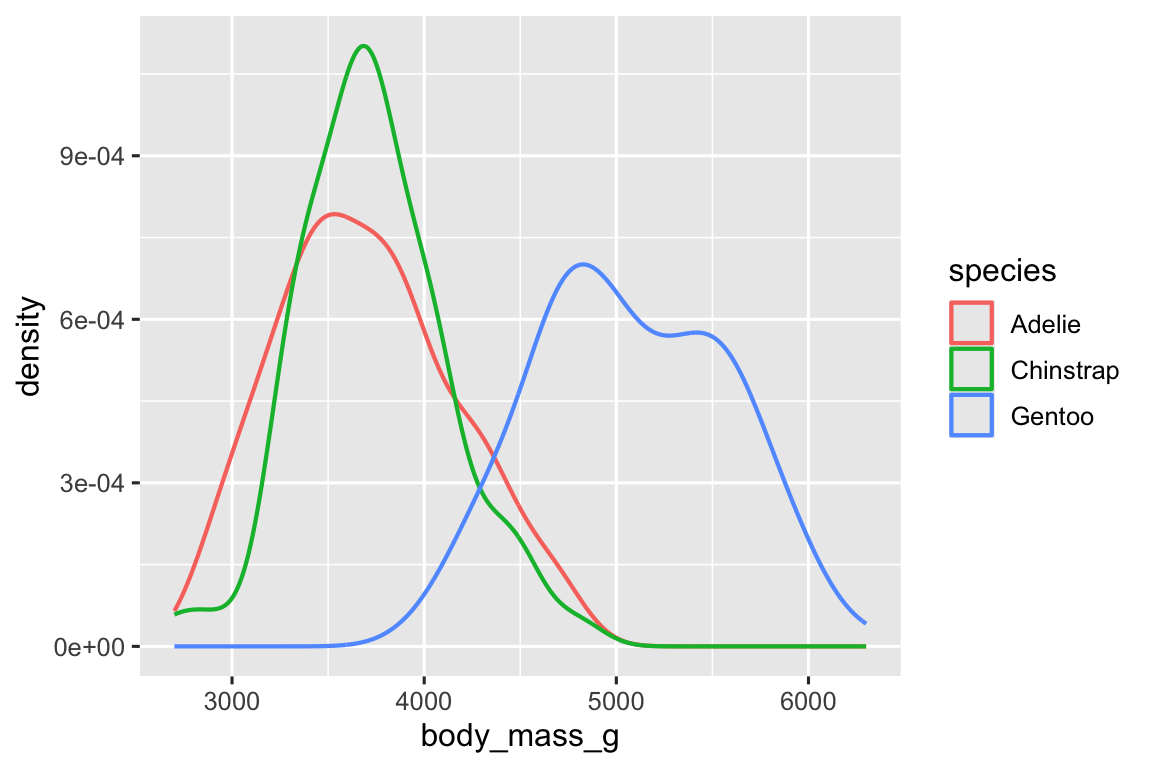
Chúng ta cũng đã tùy chỉnh độ dày của các đường bằng argument linewidth để làm cho chúng nổi bật hơn một chút trên nền.
Thêm vào đó, chúng ta có thể mapping species đến cả thuộc tính đồ họa color và fill và sử dụng thuộc tính đồ họa alpha để thêm độ trong suốt cho các đường cong mật độ được tô màu. Thuộc tính thẩm mỹ này nhận giá trị từ 0 (hoàn toàn trong suốt) đến 1 (hoàn toàn mờ đục). Trong biểu đồ sau, nó được đặt thành 0,5.
ggplot(penguins, aes(x = body_mass_g, color = species, fill = species)) +
geom_density(alpha = 0.5)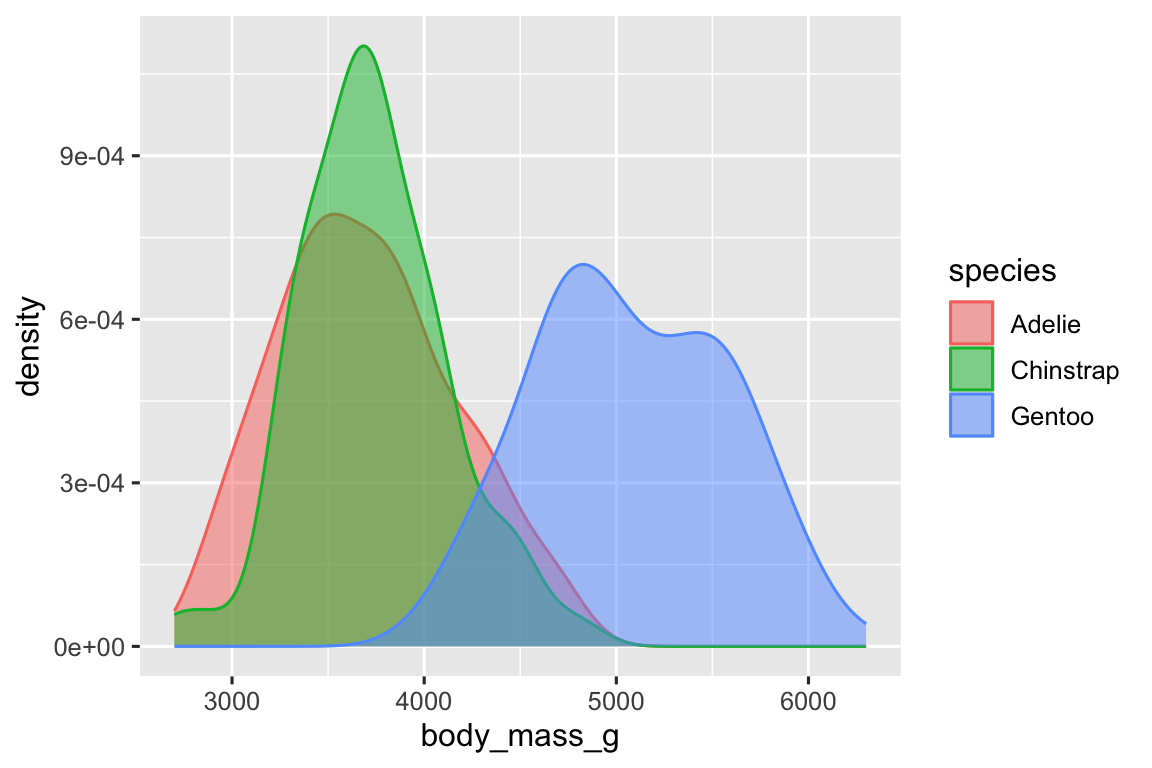
Lưu ý thuật ngữ chúng ta đã sử dụng ở đây:
- Chúng ta mapping biến đến thuộc tính đồ họa nếu chúng ta muốn thuộc tính trực quan được biểu diễn bởi thuộc tính đồ họa đó thay đổi dựa trên giá trị của biến đó.
- Ngược lại, chúng ta đặt giá trị của thuộc tính đồ họa.
1.5.2 Hai biến phân loại
Chúng ta có thể sử dụng biểu đồ column xếp chồng để visualization mối quan hệ giữa hai biến phân loại. Ví dụ, hai biểu đồ column xếp chồng sau đều hiển thị mối quan hệ giữa island và species, hoặc cụ thể hơn, visualization phân phối của species trong mỗi đảo.
Biểu đồ đầu tiên hiển thị tần suất của mỗi loài chim cánh cụt trên mỗi đảo. Biểu đồ tần suất cho thấy có số lượng Adelie bằng nhau trên mỗi đảo. Nhưng chúng ta không có cảm nhận tốt về tỷ lệ phần trăm cân bằng trong mỗi đảo.
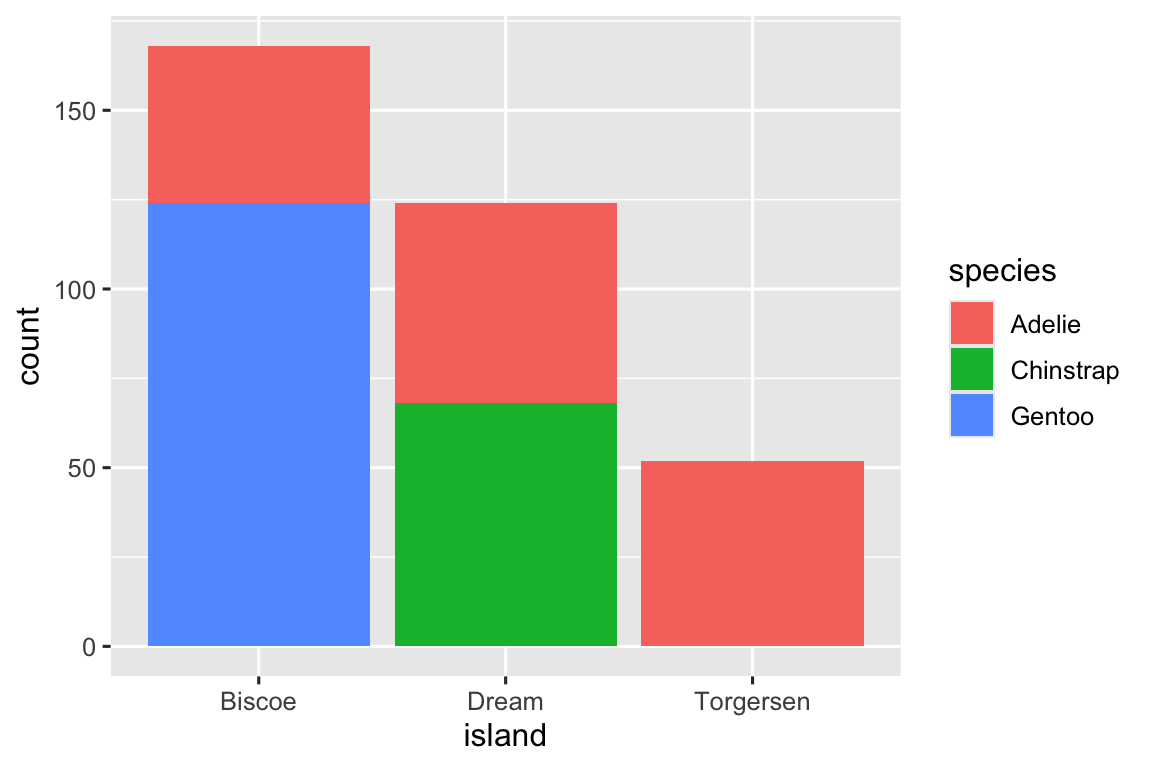
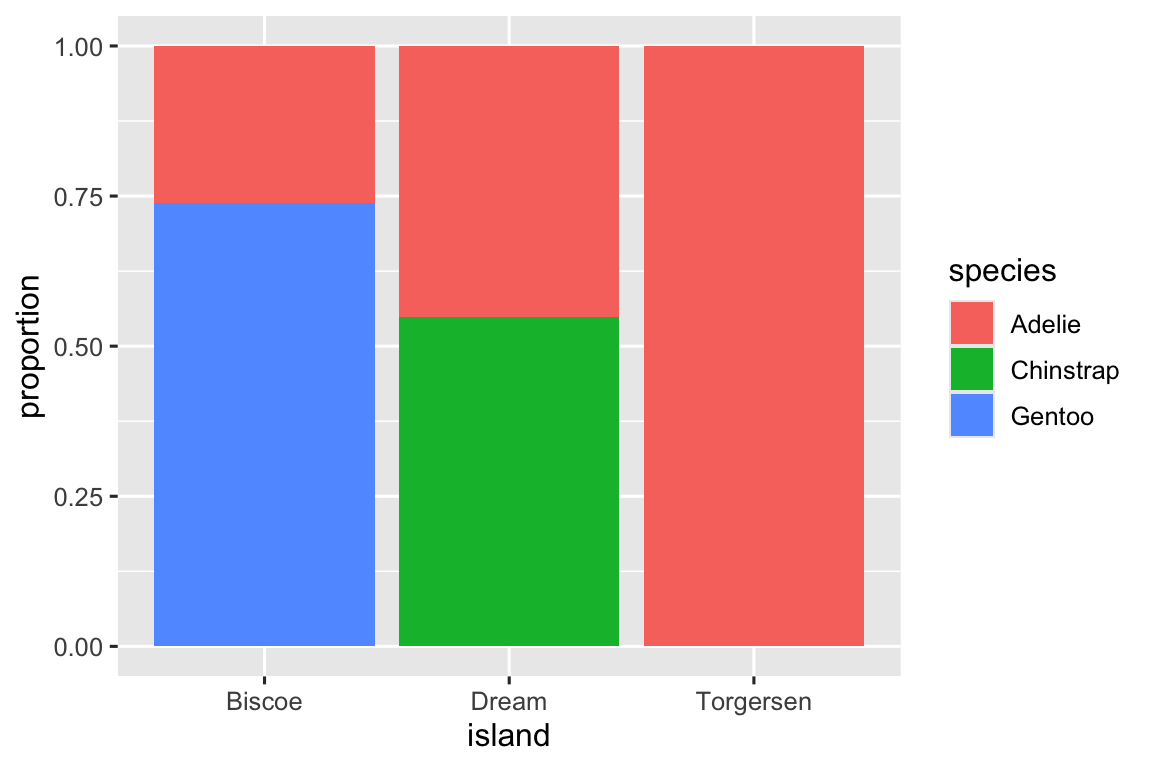
Biểu đồ thứ hai, biểu đồ tần suất tương đối được tạo bằng cách đặt position = "fill" trong geom, hữu ích hơn để so sánh phân phối loài giữa các đảo vì nó không bị ảnh hưởng bởi số lượng chim cánh cụt không đều giữa các đảo. Sử dụng biểu đồ này, chúng ta có thể thấy rằng chim cánh cụt Gentoo đều sống trên đảo Biscoe và chiếm khoảng 75% chim cánh cụt trên đảo đó, Chinstrap đều sống trên đảo Dream và chiếm khoảng 50% chim cánh cụt trên đảo đó, và Adelie sống trên cả ba đảo và chiếm toàn bộ chim cánh cụt trên Torgersen.
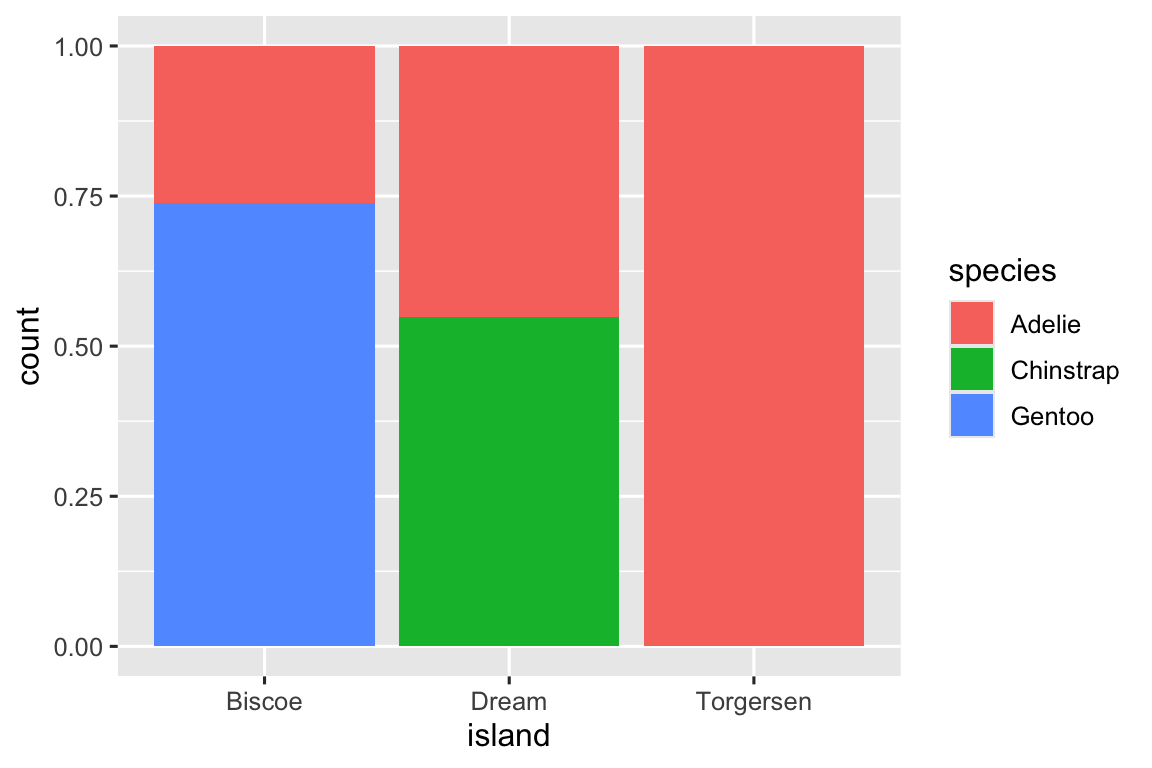
Trong việc tạo các biểu đồ column này, chúng ta mapping biến sẽ được tách thành các thanh đến thuộc tính đồ họa x, và biến sẽ thay đổi màu sắc bên trong các thanh đến thuộc tính đồ họa fill. Thật không may, ggplot2 gắn nhãn trục y là "count" theo mặc định, nhưng đây là điều chúng ta có thể ghi đè bằng cách thêm một lớp labs() trong đó chúng ta chỉ định nhãn trục y là "proportion".
1.5.3 Hai biến số
Cho đến nay bạn đã tìm hiểu về biểu đồ phân tán (tạo bằng geom_point()) và đường cong trơn (tạo bằng geom_smooth()) để visualization mối quan hệ giữa hai biến số. Biểu đồ phân tán có lẽ là biểu đồ được sử dụng phổ biến nhất để visualization mối quan hệ giữa hai biến số.
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point()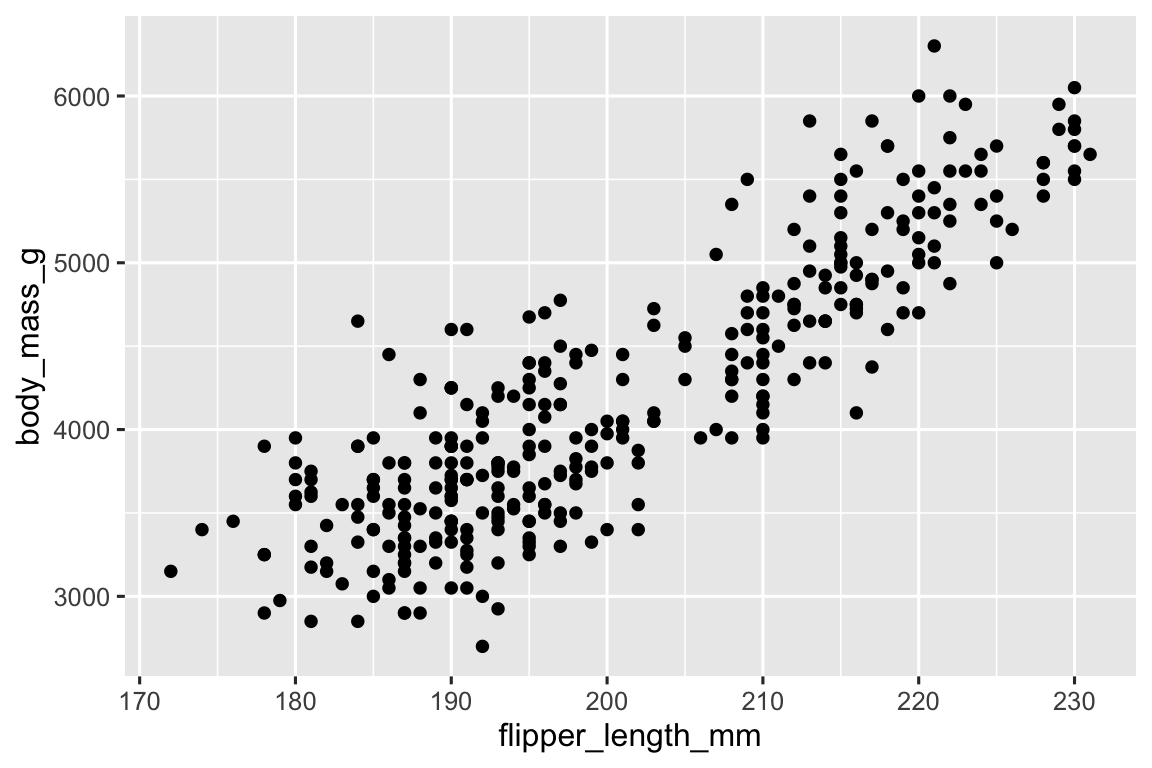
1.5.4 Ba biến trở lên
Như chúng ta đã thấy trong Phần 1.2.4, chúng ta có thể đưa thêm biến vào biểu đồ bằng cách mapping chúng đến các thuộc tính đồ họa bổ sung. Ví dụ, trong biểu đồ phân tán sau, màu sắc của các điểm biểu diễn loài và hình dạng của các điểm biểu diễn đảo.
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = island))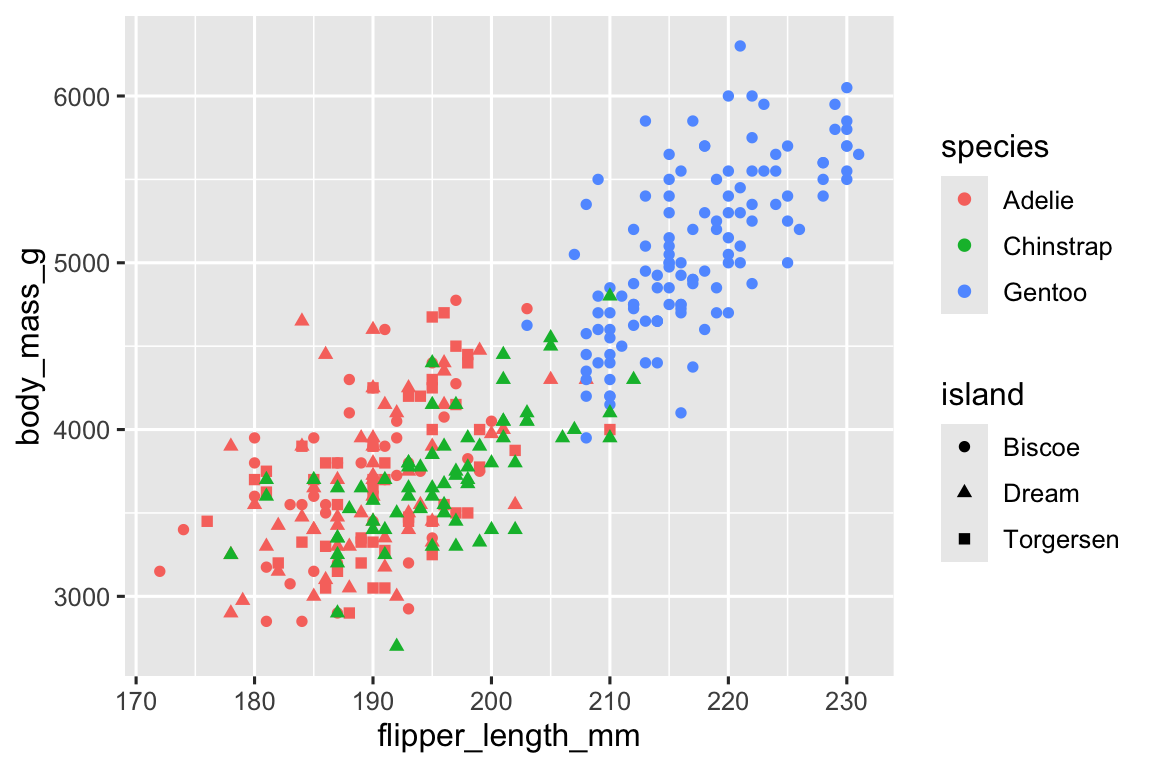
Tuy nhiên, thêm quá nhiều mapping thuộc tính đồ họa vào biểu đồ khiến nó lộn xộn và khó hiểu. Một cách khác, đặc biệt hữu ích cho biến phân loại, là chia biểu đồ thành các facet, các biểu đồ con mà mỗi cái hiển thị một tập hợp con của dữ liệu.
Để chia biểu đồ theo một biến, sử dụng facet_wrap(). Đối số đầu tiên của facet_wrap() là một công thức (formula)3, mà bạn tạo với ~ theo sau bởi tên biến. Biến mà bạn truyền cho facet_wrap() nên là biến phân loại.
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = species)) +
facet_wrap(~island)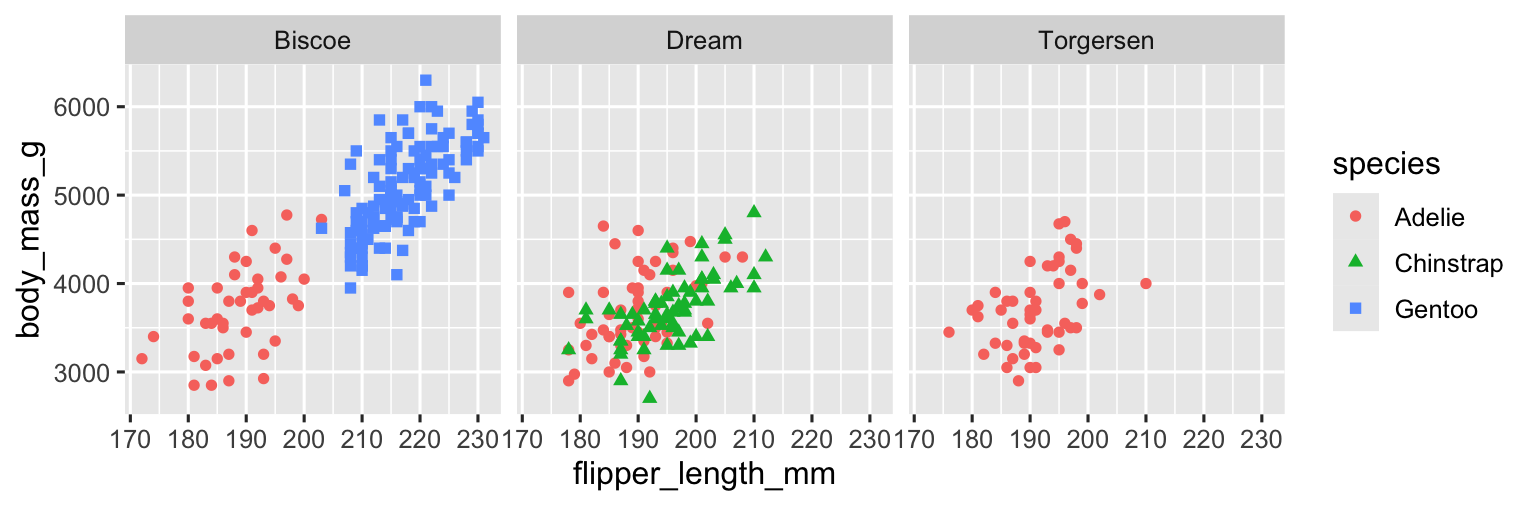
Bạn sẽ tìm hiểu về nhiều geom khác để visualization phân phối của biến và mối quan hệ giữa chúng trong Chương 9.
1.5.5 Bài tập
Khung dữ liệu
mpgđược đóng gói cùng package ggplot2 chứa 234 quan sát được thu thập bởi Cơ quan Bảo vệ Môi trường Hoa Kỳ trên 38 mẫu xe. Biến nào trongmpglà phân loại? Biến nào là số? (Gợi ý: Gõ?mpgđể đọc tài liệu cho bộ dữ liệu.) Làm thế nào bạn có thể thấy thông tin này khi chạympg?Tạo biểu đồ phân tán của
hwytheodisplsử dụng data framempg. Tiếp theo, mapping một biến số thứ ba đếncolor, sau đósize, rồi cảcolorvàsize, rồishape. Các thuộc tính đồ họa này hoạt động khác nhau như thế nào đối với biến phân loại so với biến số?Trong biểu đồ phân tán của
hwytheodispl, điều gì xảy ra nếu bạn mapping một biến thứ ba đếnlinewidth?Điều gì xảy ra nếu bạn mapping cùng một biến đến nhiều thuộc tính đồ họa?
Tạo biểu đồ phân tán của
bill_depth_mmtheobill_length_mmvà tô màu các điểm theospecies. Việc tô màu theo loài tiết lộ điều gì về mối quan hệ giữa hai biến này? Còn facet theospeciesthì sao?-
Tại sao đoạn mã sau đây tạo ra hai chú giải riêng biệt? Bạn sẽ sửa nó như thế nào để kết hợp hai chú giải?
ggplot( data = penguins, mapping = aes( x = bill_length_mm, y = bill_depth_mm, color = species, shape = species ) ) + geom_point() + labs(color = "Species") -
Tạo hai biểu đồ column xếp chồng sau. Câu hỏi nào bạn có thể trả lời với biểu đồ thứ nhất? Câu hỏi nào bạn có thể trả lời với biểu đồ thứ hai?
1.6 Lưu biểu đồ của bạn
Sau khi bạn đã tạo một biểu đồ, bạn có thể muốn đưa nó ra khỏi R bằng cách lưu nó dưới dạng hình ảnh mà bạn có thể sử dụng ở nơi khác. Đó là công việc của ggsave(), function sẽ lưu biểu đồ được tạo gần nhất vào ổ đĩa:
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point()
ggsave(filename = "penguin-plot.png")Điều này sẽ lưu biểu đồ vào thư mục làm việc của bạn, một khái niệm mà bạn sẽ tìm hiểu thêm trong Chương 6.
Nếu bạn không chỉ định width và height, chúng sẽ được lấy từ kích thước của thiết bị vẽ hiện tại. Để mã có thể tái tạo, bạn sẽ muốn chỉ định chúng. Bạn có thể tìm hiểu thêm về ggsave() trong tài liệu.
Tuy nhiên, nói chung, chúng tôi khuyên bạn nên tổng hợp các báo cáo cuối cùng bằng Quarto, một hệ thống biên soạn có thể tái tạo cho phép bạn xen kẽ mã và văn xuôi và tự động đưa biểu đồ vào bài viết của bạn. Bạn sẽ tìm hiểu thêm về Quarto trong Chương 28.
1.6.1 Bài tập
-
Chạy các dòng mã sau. Biểu đồ nào trong hai biểu đồ được lưu thành
mpg-plot.png? Tại sao? Bạn cần thay đổi gì trong mã ở trên để lưu biểu đồ dưới dạng PDF thay vì PNG? Làm thế nào bạn có thể tìm ra những loại tệp hình ảnh nào hoạt động trong
ggsave()?
1.7 Các vấn đề thường gặp
Khi bạn bắt đầu chạy mã R, bạn có thể sẽ gặp vấn đề. Đừng lo – điều này xảy ra với tất cả mọi người. Chúng tôi đều đã viết mã R trong nhiều năm, nhưng mỗi ngày chúng tôi vẫn viết mã không hoạt động ngay lần thử đầu tiên!
Bắt đầu bằng cách so sánh cẩn thận mã bạn đang chạy với mã trong sách. R cực kỳ khó tính, và một ký tự đặt sai chỗ có thể tạo ra tất cả sự khác biệt. Đảm bảo rằng mỗi ( được ghép với một ) và mỗi " được ghép với một " khác. Đôi khi bạn chạy mã và không có gì xảy ra. Kiểm tra bên trái console của bạn: nếu nó là +, nghĩa là R cho rằng bạn chưa gõ xong một biểu thức hoàn chỉnh và nó đang chờ bạn hoàn thành. Trong trường hợp này, thường dễ dàng bắt đầu lại từ đầu bằng cách nhấn ESCAPE để hủy xử lý lệnh hiện tại.
Một vấn đề phổ biến khi tạo đồ họa ggplot2 là đặt + sai chỗ: nó phải ở cuối dòng, không phải đầu dòng. Nói cách khác, hãy đảm bảo bạn không vô tình viết mã như thế này:
ggplot(data = mpg)
+ geom_point(mapping = aes(x = displ, y = hwy))Nếu bạn vẫn bị kẹt, hãy thử phần trợ giúp. Bạn có thể nhận trợ giúp về bất kỳ function R nào bằng cách chạy ?function_name trong console, hoặc bôi đen tên function và nhấn F1 trong RStudio. Đừng lo nếu phần trợ giúp có vẻ không hữu ích lắm - thay vào đó hãy cuộn xuống phần ví dụ và tìm mã khớp với những gì bạn đang cố làm.
Nếu điều đó không giúp ích, hãy đọc kỹ thông báo lỗi. Đôi khi câu trả lời sẽ ẩn trong đó! Nhưng khi bạn mới làm quen với R, ngay cả khi câu trả lời nằm trong thông báo lỗi, bạn có thể chưa biết cách hiểu nó. Một công cụ tuyệt vời khác là Google: hãy thử tìm kiếm thông báo lỗi trên Google, vì có khả năng ai đó đã gặp cùng vấn đề, và đã được giúp đỡ trực tuyến.
1.8 Tóm tắt
Trong chương này, bạn đã học những kiến thức cơ bản về visualization dữ liệu với ggplot2. Chúng ta bắt đầu với ý tưởng cơ bản làm nền tảng cho ggplot2: một visualization là một mapping từ các biến trong dữ liệu của bạn đến các thuộc tính đồ họa như vị trí, màu sắc, kích thước và hình dạng. Sau đó, bạn đã học về việc tăng độ phức tạp và cải thiện cách trình bày biểu đồ theo từng lớp. Bạn cũng đã học về các biểu đồ thường được sử dụng để visualization phân phối của một biến đơn lẻ cũng như visualization mối quan hệ giữa hai hoặc nhiều biến, bằng cách tận dụng các mapping thuộc tính đồ họa bổ sung và/hoặc chia biểu đồ thành các biểu đồ nhỏ sử dụng facet.
Chúng ta sẽ sử dụng visualization iterate đi iterate lại trong suốt cuốn sách này, giới thiệu các kỹ thuật mới khi cần thiết cũng như đi sâu hơn vào việc tạo visualization với ggplot2 trong Chương 9 đến Chương 11.
Với kiến thức cơ bản về visualization trong tay, trong chương tiếp theo chúng ta sẽ chuyển hướng một chút và đưa ra một số lời khuyên thực tế về workflow. Chúng tôi xen kẽ lời khuyên về workflow với các công cụ khoa học dữ liệu trong phần này của cuốn sách vì nó sẽ giúp bạn duy trì tổ chức khi viết ngày càng nhiều mã R.
Bạn có thể loại bỏ thông báo đó và buộc việc giải quyết xung đột xảy ra theo yêu cầu bằng cách sử dụng package conflicted, điều này trở nên quan trọng hơn khi bạn tải nhiều package hơn. Bạn có thể tìm hiểu thêm về conflicted tại https://conflicted.r-lib.org.↩︎
Horst AM, Hill AP, Gorman KB (2020). palmerpenguins: Palmer Archipelago (Antarctica) penguin data. R package version 0.1.0. https://allisonhorst.github.io/palmerpenguins/. doi: 10.5281/zenodo.3960218.↩︎
Ở đây “formula” là tên của thứ được tạo bởi
~, không phải từ đồng nghĩa với “phương trình”.↩︎